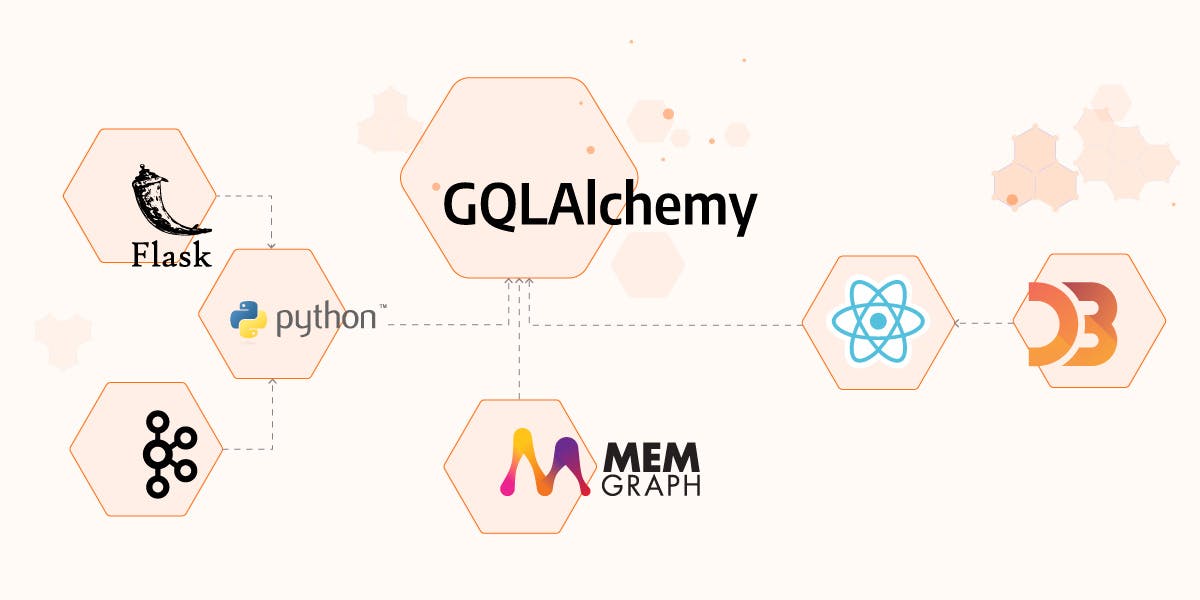
Building Robust Applications Using GQLAlchemy
While building the whole web application, you save the necessary data to the database and load it whenever needed. Fetching the data can be error-prone since there may be that one minor typo that will bug you. In this tutorial, you'll learn how to build a small part of the Twitch analytics app with the help of GQLAlchemy, an object graph mapper (OGM) that makes building graph-based apps much easier.
Backend implementation
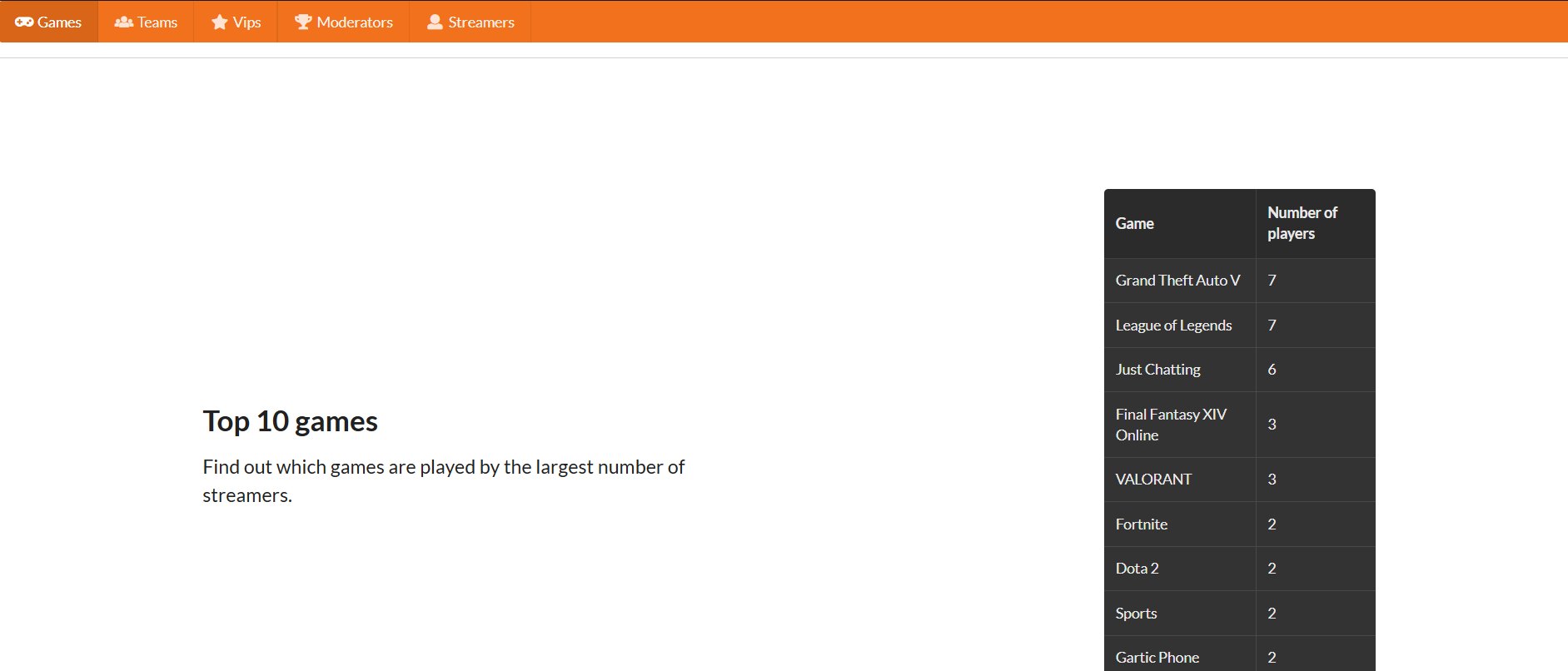
Through this tutorial, you are going to find the most popular game from the Twitch dataset. The data was retrieved from the Twitch API, and for this tutorial, you will just need the streamers.csv file. First, you have to define the necessary data classes in models.py:
from gqlalchemy import Node, Field, Relationship
from typing import Optional
from app import memgraph
class User(Node):
name: str = Field(index=True, exists=True, unique=True, db=memgraph)
class Stream(User):
name: Optional[str] = Field(
index=True, exists=True, unique=True, db=memgraph, label="User"
)
id: str = Field(index=True, exists=True, unique=True, db=memgraph)
url: Optional[str] = Field()
followers: Optional[int] = Field()
createdAt: Optional[str] = Field()
totalViewCount: Optional[int] = Field()
description: Optional[str] = Field()
class Game(Node):
name: str = Field(unique=True, db=memgraph)Next, you have to load the data from the CSV file:
def load_streams(path):
with open(path) as read_obj:
csv_reader = reader(read_obj)
header = next(csv_reader)
if header != None:
for row in csv_reader:
stream = models.Stream(
id=row[1],
name=row[3],
url=row[6],
followers=row[7],
createdAt=row[10],
totalViewCount=row[9],
description=row[8],
).save(memgraph)
game = models.Game(name=row[4]).save(memgraph)
plays_rel = models.Plays(
_start_node_id=stream._id, _end_node_id=game._id
).save(memgraph)You modeled objects using GQLAlchemy's Object Graph Mapper (OGM), which offers schema validation, so you can be sure that the data inside Memgraph will be accurate.
All loading methods can be found in twitch_data.py.
After the data is loaded, you can create an API endpoint for GET requests in app.py to find out which game is the most popular:
@app.route("/top-games/<num_of_games>", methods=["GET"])
@log_time
def get_top_games(num_of_games):
"""Get top num_of_games games by number of streamers who play them."""
try:
results = list(
Match()
.node("Stream", variable="s")
.to("PLAYS")
.node("Game", variable="g")
.return_({"g.name": "game_name", "count(s)": "num_of_players"})
.order_by("num_of_players DESC")
.limit(num_of_games)
.execute()
)
games_list = list()
players_list = list()
for result in results:
game_name = result["game_name"]
num_of_players = result["num_of_players"]
games_list.append(game_name)
players_list.append(num_of_players)
games = [{"name": game_name} for game_name in games_list]
players = [{"players": player_count} for player_count in players_list]
response = {"games": games, "players": players}
return Response(
response=dumps(response), status=200, mimetype="application/json"
)
except Exception as e:
log.info("Fetching top games went wrong.")
log.info(e)
return ("", 500)The query builder from GQLAlchemy was used to avoid writing Cypher queries and to notice if there are any errors before the query is executed in the database. The query above counts how many streamers play each game and then returns results in descending order. This is how the query builder construct looks when executed as a Cypher query in Memgraph:
- Query builder
Match()
.node("Stream", variable="s")
.to("PLAYS")
.node("Game", variable="g")
.return_({"g.name": "game_name", "count(s)": "num_of_players"})
.order_by("num_of_players DESC")
.limit(num_of_games)
.execute()- Cypher query
MATCH (s:Stream)-[:PLAYS]->(g:Game)
RETURN g.name AS game_name, count(s) AS num_of_players
ORDER BY num_of_players DESC LIMIT num_of_games;In this request, you can determine how many top games you want to fetch. The response you'll get in the frontend is JSON with games and players as keys.
Frontend implementation
In the end, let's show how you can visualize your results. The frontend is built with the help of Semantic UI React.
You have to create a component in which you're going to fetch the data from the backend. The most important part is the fetching, which you have to call immediately after a component is mounted, that is, in componentDidMount() method:
fetchData(number) {
fetch("/top-games/" + number)
.then((res) => res.json())
.then(
(result) => {
this.setState({
isLoaded: true,
games: result.games,
players: result.players,
});
},
(error) => {
this.setState({
isLoaded: true,
error,
});
}
);
this.setState({
numOfGames: number,
header: "Top " + number + " games",
});
}
componentDidMount() {
this.fetchData(this.state.numOfGames);
}Then you can render the results saved in games and players state variables however you want. If you need inspiration, check out the Games.js component.
Conclusion
Creating classes representing nodes and relationships in Python offers you more control of your data. GQLAlchemy enables you to easily communicate with the graph database using the technology stack you're already familiar with. If you have questions about GQLAlchemy's OGM or query builder, visit our Discord server and drop us a message. You can also share any project you come up with!