
Efficient Threat Detection in Cybersecurity with Memgraph
The number of security vulnerabilities in code is increasing daily. We all remember the devastating consequences of the exposed vulnerability on Log4j, which affected a large number of systems all around the world. Not all vulnerabilities are as harmful as that one. However, new code is prone to bugs and can easily be exploited by smart malicious attackers so extra attention should be paid to security when designing new features.
In this article, we’ll use Memgaph to analyze malicious behaviors in PyPI packages, find out how to track and record any potential harmful points in projects, and prevent cyber threats from happening.
Grouping and addressing security vulnerabilities
To minimize risk of security threats inside systems, an initiative under the name of CVE (Common Vulnerabilities and Exposures) provides a comprehensive list of all known vulnerabilities. The initiative tries hard to cooperate with as many partners as possible to link all the threats together and be a source of truth about whether some code snippets, packages, or features in a programming language are safe or not. Since 1999 CVE exposures have increased to 192 000, and the number is still growing, helping the community make safer systems.
The exposure list can be used to develop software that analyzes CVE exposures and warns users about potential threats in their code. Some GitHub-offered software, like Dependabot, notifies users when a new version of a package is available, so they can update their code with up-to-date dependency versions.
However, some versions (like new major or minor versions) might contain overlooks that can be exploited as vulnerabilities to harm your software. In the chapters below, we have built a simple software that can performantly analyze your code dependencies and notify you about potential threats in the system.
Combining CVE vulnerabilities with Python dependency tree
While building the solution, we decided to stick to Python projects only, as Python is one of the most extensively used languages. However, the solution can be extended with other languages as well.
The CVE vulnerabilities contain information about
- CVE ID
- CVE description
- References to the CVE
- CVE status (Reported, Assigned, Solved…)
- And many more…
With the help of the rich description field, which contains information such as whether the vulnerability is a part of the PyPI package manager, the package name, and affected versions, we could easily extract and use this information as a tool to link dependencies of the Python packages with known vulnerabilities.
Creating a dependency tree is an intuitive job in graph databases like Memgraph. It resembles a directed acyclic graph (DAG) traversed to find any specific dependencies or interactions with other entities in the database.
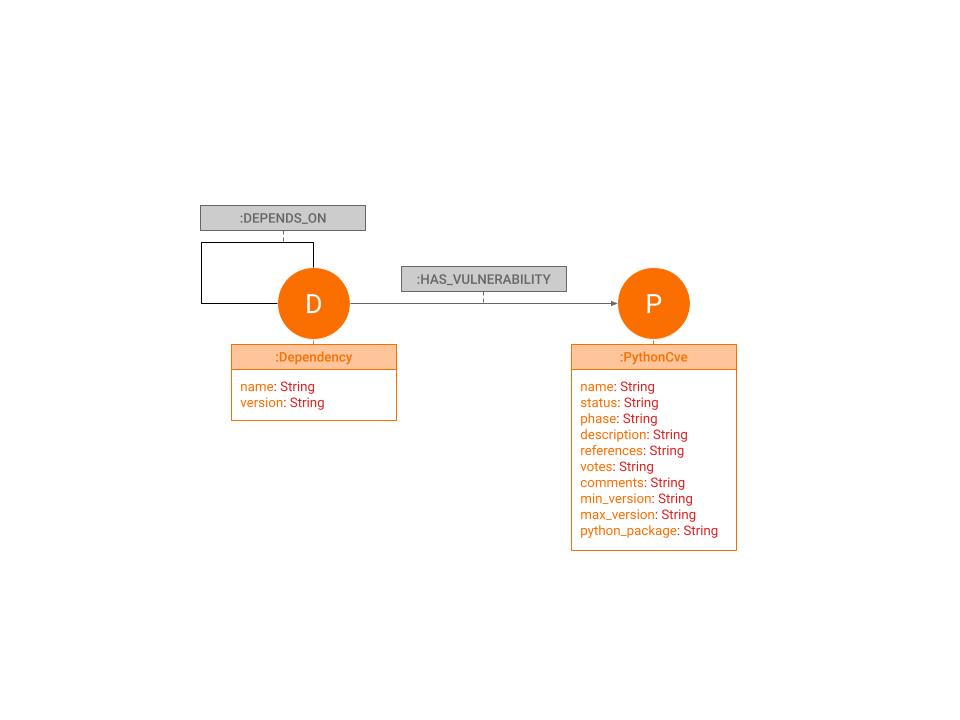
Graph model
The image below shows the graph model used in the solution. The Dependency node denotes a Python package that can be found on PyPI. It can have additional sub-dependencies of the same label connected with the relationship DEPENDS_ON. Valuable properties on this node are the name (to traverse a specific package) and version (to see what version is used by a dependency in our project).
The second label in our graph is the exposed Python package vulnerabilities or PythonCve. Suppose a certain PythonCve has a link to a specific Python dependency. In that case, they can be linked with an additional Cypher query (the main query language of Memgraph and several other graph databases). The relationship which connects a dependency with a vulnerability is named HAS_VULNERABILITY
Querying and inspecting possible security threats
Use the query below to get a list of known Python package vulnerabilities. Memgraph Lab can show all the vulnerabilities as nodes.
MATCH (n:PythonCve) RETURN n;
After successfully inserting project dependencies into Memgraph, the dependency tree is listed with a path traversal using the BFS (breadth-first search) algorithm. The query below iterates through all the dependencies from a root one called gqlalchemy, which is our own Object Graph Mapper (OGM).
MATCH p=(n:Dependency {name: “gqlalchemy”})-[r *bfs]->(m:Dependency) RETURN p;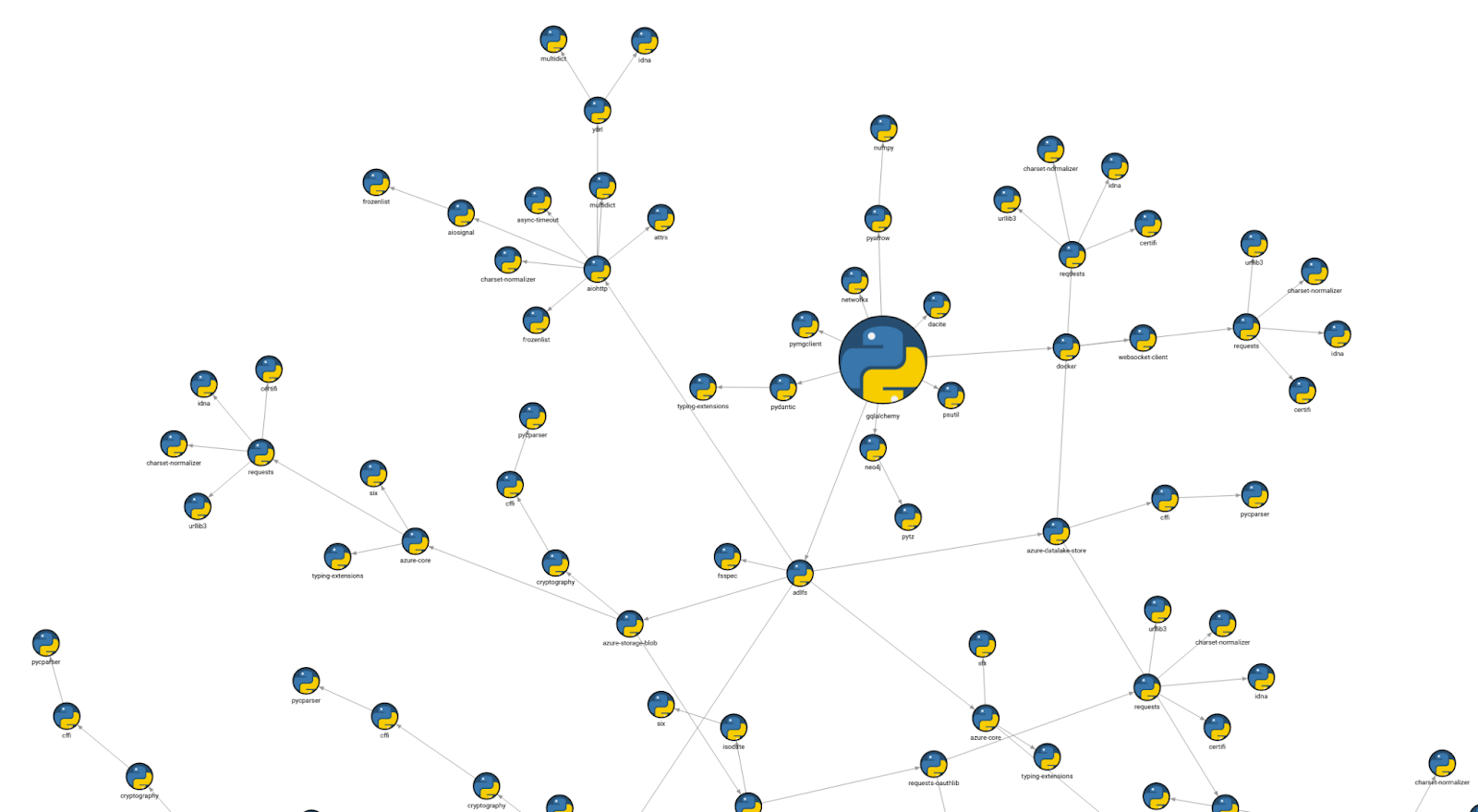
For the sake of the example, we have also inserted a fictional code project called vulnerable-gqlalchemy. Let’s inspect its dependencies.
MATCH p=(n:Dependency {name: “vulnerable-gqlalchemy”})-[r *bfs]->(m:Dependency) RETURN p;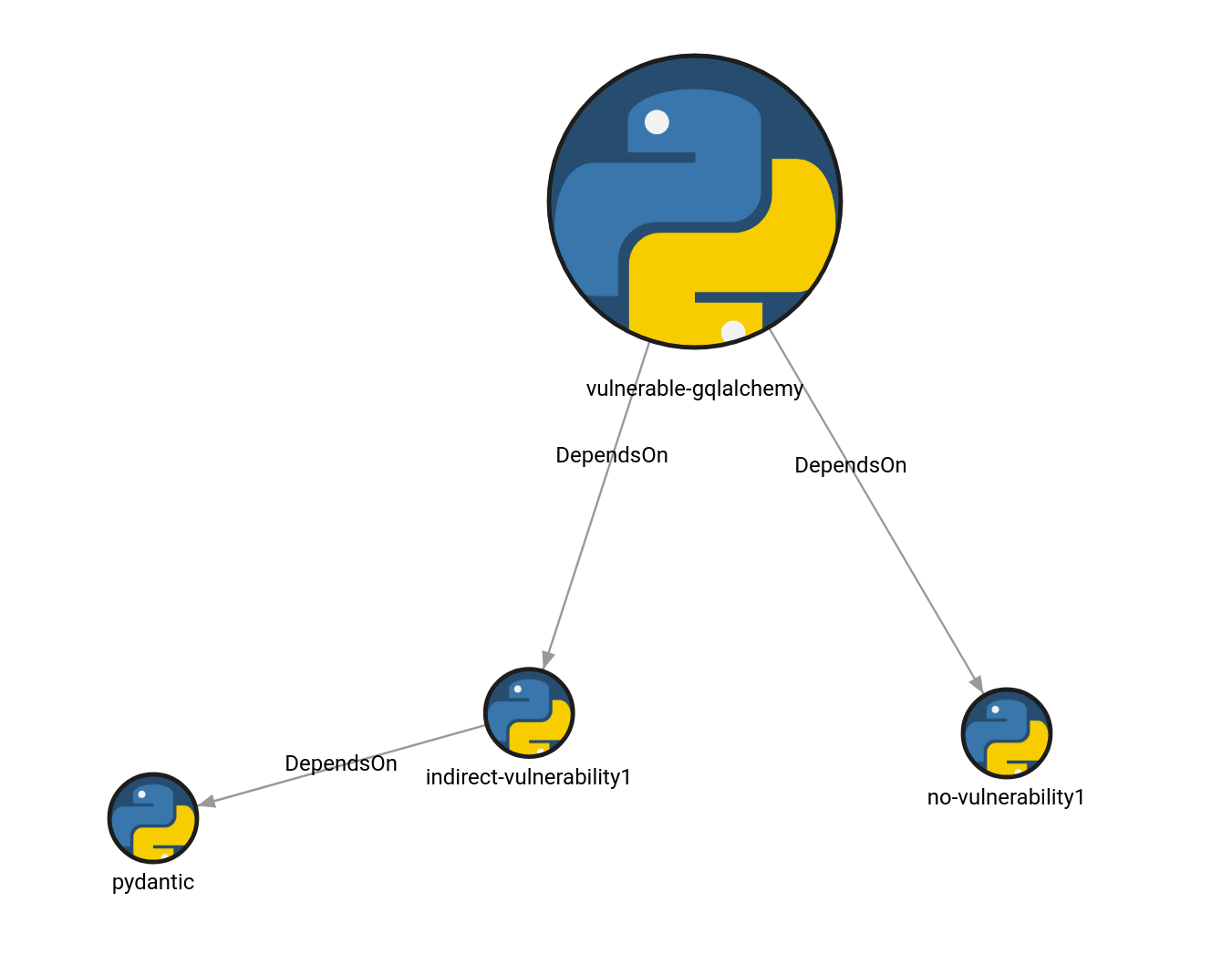
Inspecting dependencies isn’t enough to conclude if vulnerabilities exist. Nodes need to be connected to a known CVE to decide if there is a potential threat or not.
In the following query, the target label is omitted and the algorithms will traverse the network more broadly and discover possible PythonCve nodes connected with the HAS_VULNERABILITY relationship.
MATCH p=(n:Dependency {name: “vulnerable-gqlalchemy”})-[r *bfs]->(m) RETURN p;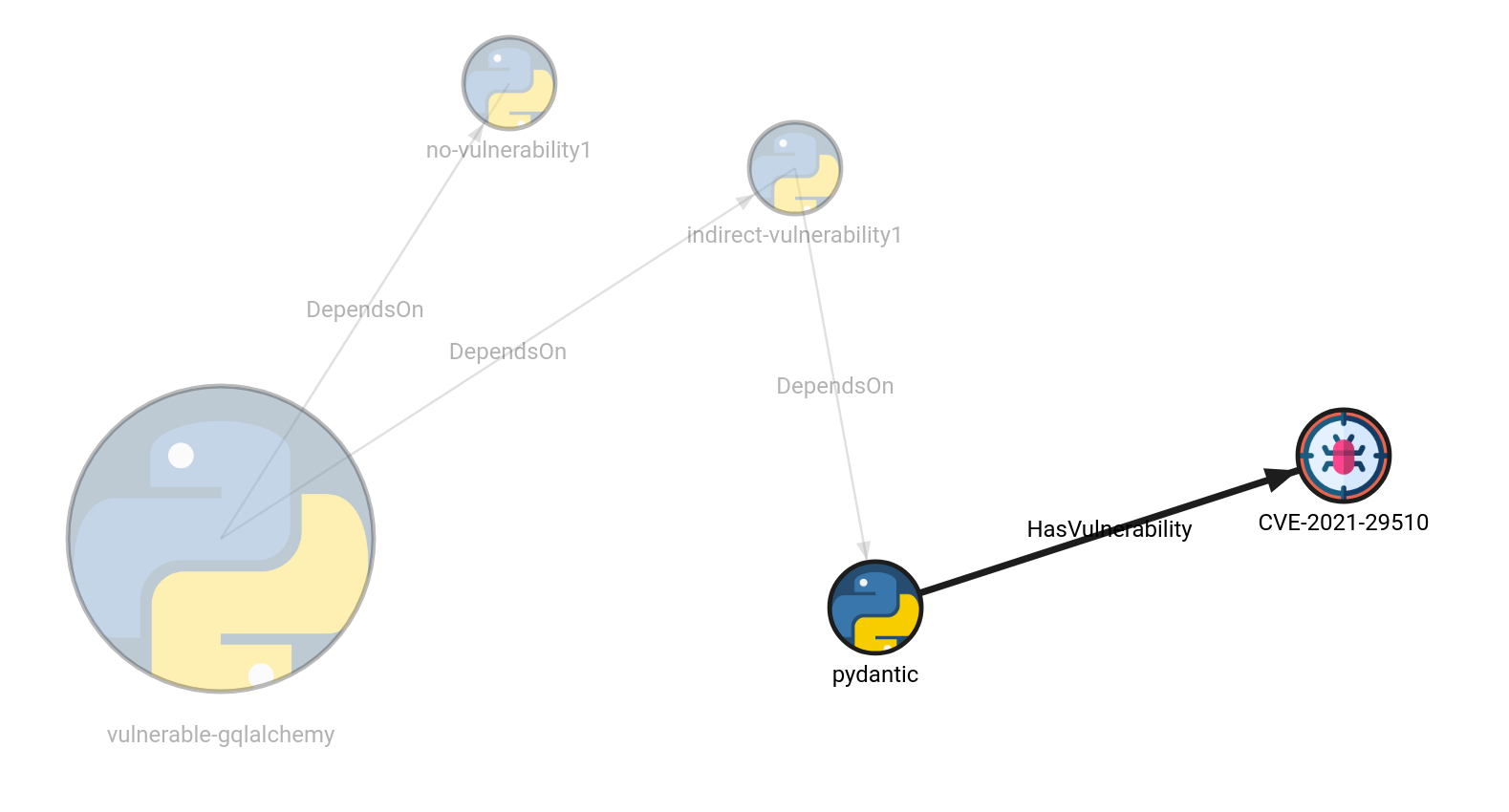
The analysis shows that a version of Python package called pydantic has a known vulnerability connected with the CVE of the ID CVE-2021-29510. After inspecting the Pydantic package, we also get the versions affected by the exploit (v1.8).
MATCH (n:PythonCve) WHERE toLower(n.python_package) = “pydantic” RETURN n.name, n.description, n.min_version, n.max_version;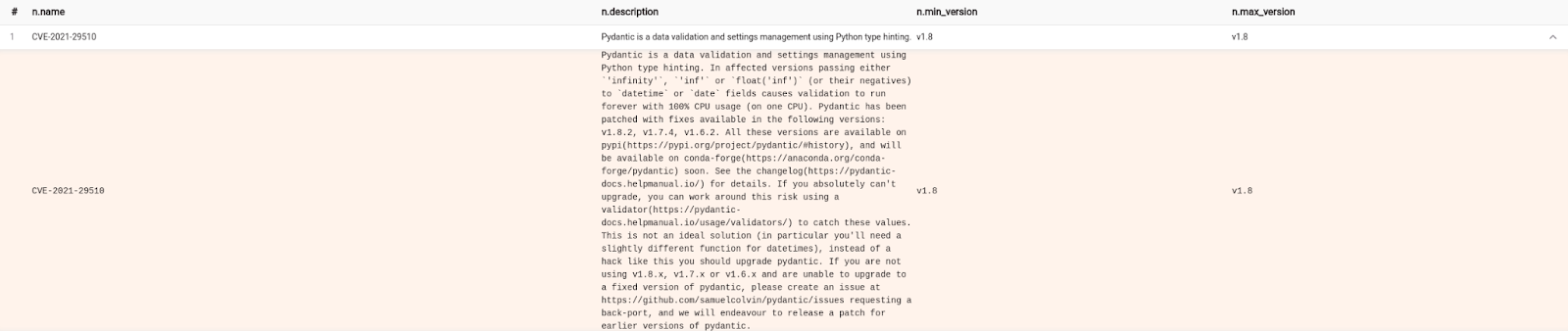
This set of queries has pinpointed a vulnerability issue in the code. If it’s due to outdated packages, it’s sometimes enough to update the package, and the vulnerability will be sanitized with the new patch.
Let’s see how the inspection would work against the real gqlalchemy package. Let’s check the version of the used Pydantic.
MATCH p=(n:Dependency {name: “gqlalchemy”})-[r *bfs]->(m:Dependency {name: “pydantic”}) RETURN p, n.version;
The version is v1.10.2. Hopefully, with fixed vulnerability issues!
The last query checks that gqlalchemy doesn’t have any CVEs tied to it. After running the query, we get 0 results, which proves that no dependencies or sub dependencies exist with a known vulnerability inside the gqlalchemy dependency tree.
MATCH p=(d:Dependency {name: “gqlalchemy”})-[r *bfs]->(c:PythonCve) RETURN p;Conclusion
On this simple example, we have seen how we can easily analyze data inside Memgraph for cybersecurity use cases, since most of the use cases from that area have a network-like representation of the data. The example looks simple, but enterprise code projects can have hundreds or thousands of dependencies, and it’s really difficult to track them all and be in touch with every information there is, only to realize from time to time that there can be a potential threat in the solution. Memgraph, with its ability to easily traverse the network, can discover it easily.