
Building a Recommendation System Using Memgraph
Introduction
“How would you rate this movie/book/restaurant?” is one of the most commonly asked questions when visiting online websites while browsing for additional info on said topic. Most systems ask for a numerical value or star rating. Rating in that way takes a subjective approach, and, from time to time, products with lower ratings fall back never to be found again in search bars. But not all lower rated things are bad, aren’t they? People’s preferences matter, and an old Latin saying says that you don’t discuss someone’s taste.
This article aims to build a more objective recommendation system with Memgraph and Cypher query language by using characteristics as the base for recommendations.
Recommendation Systems
Many recommendation systems use rating systems as a base to recommend certain products. One of the most popular methods for recommendations is collaborative filtering. It is a method that automatically predicts a user's interest in the product by using ratings of other users. In one of our tutorials, we've shown how to implement this method using Memgraph, but we will take a more straightforward yet equally effective approach in this post.
The approach we are taking here is much simpler than complicated math hidden behind collaborative filtering. We will see how we can use Memgraph and Cypher queries to build a recommendation system based on characteristics of the product (in this case, games).
Like with movies or books, people have preferences for games. When browsing through your favorite game launcher, you see a list of characteristics that can filter throughout the available games. So, with that in mind, our graph can be divided into two parts: nodes that represent games themselves and nodes that represent characteristics we’re going to filter through. Some of the characteristics we can follow are developer and publisher company, genres, price range, year of release, reviews, etc. Some game launchers, like Steam, give a descriptive review rather than a numerical one. Even though we could assign a numerical value to each review, this article aims to show how to build a recommendation system without it. Edges of the graph represent relationships between a game and a certain characteristic. Each relationship has an assigned property relevance to show that some edges are more important than the others. The graph structure can be seen in the picture below.
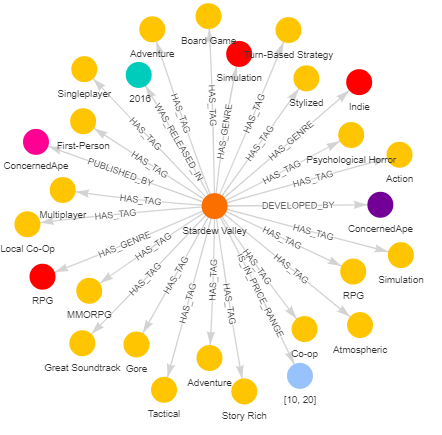
Using Cypher to Query the Database
To start, let’s find out what games we have in our database using a simple query.
MATCH (g:Game) RETURN g
The output should look like this:
As a result, we got a bunch of nodes scattered around the canvas. Let’s take a trendy and award-winning game, Stardew Valley, and see in which year was it released:
MATCH p=(g:Game {name :"Stardew Valley"})-[:WAS_RELEASED_IN]-(y:Year)
RETURN p
The output should be:
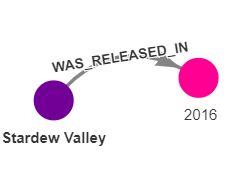
Stardew Valley is an award-winning game and many game developers took inspiration from it to make their games. Let’s see 15 games with similar genres as Stardew Valley:
MATCH (g:Game {name: "Stardew Valley"})-[:HAS_GENRE]->(ge:Genre)<-[:HAS_GENRE]-(n:Game)
WITH n, COUNT(*) as commonGenres
RETURN n ORDER BY commonGenres DESC LIMIT 15
The output for this query looks like this:
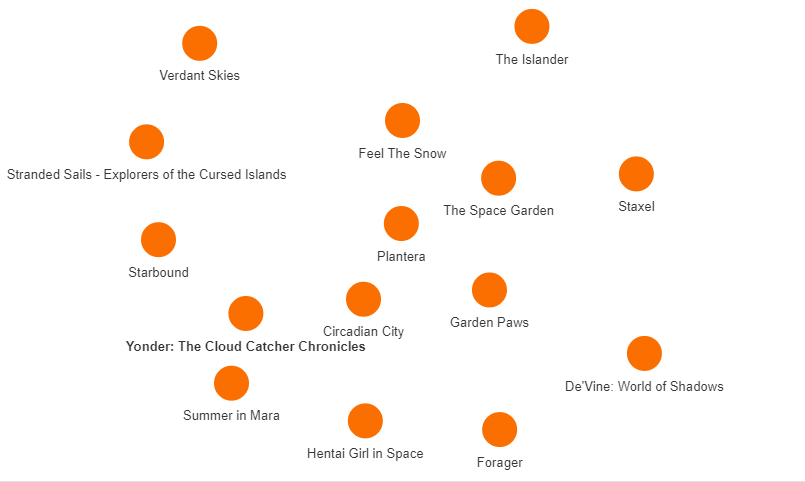
Now we have identified 15 games that are similar to Stardew Valley by their genres. We see a game named Forager in the picture. Let’s say we want to learn more about the game and see how similar it is to Stardew Valley. We can achieve that by running the following query:
MATCH p= ((g:Game)-[:HAS_TAG]-(n:Tag))
WHERE g.name = "Stardew Valley" OR g.name = "Forager"
RETURN p
The result should look like this:
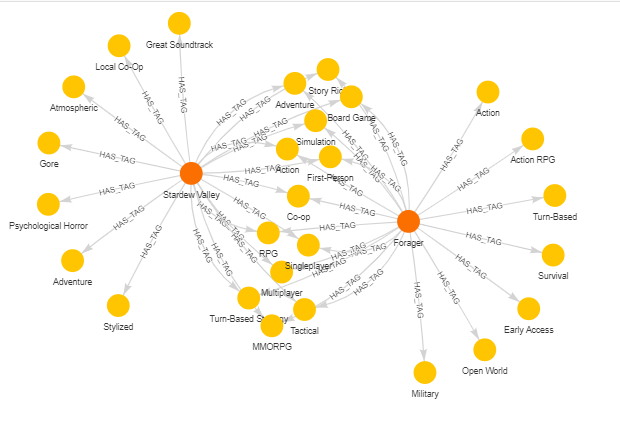
Nodes in the middle represent tags that are shared between two games. We can see that these two subgraphs have many nodes in common, so the probability that people who like Stardew Valley will like Forager as well is relatively high.
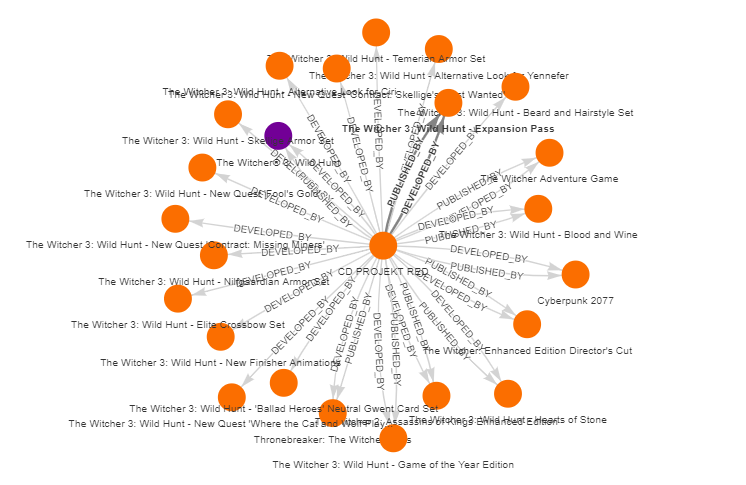
If we look at the graph structure for Stardew Valley, we can see its genre is indie. Indie games are usually developed and published in small studios, which don’t produce many games. To check what games are developed and published by a larger company, for example the European company CD Projekt Red, we will run the next query:
MATCH path=(c:Company)-[d:DEVELOPED_BY]->(g:Game)<-[p:PUBLISHED_BY]-(c2:Company)
WHERE c.name = "CD PROJEKT RED"
RETURN path
Yielding in the following result:
Graph Algorithms
While building our graph, we introduced a property on edges, relevance. Using that property, we can run queries that utilize edge properties and find out relationships between characteristics themselves.
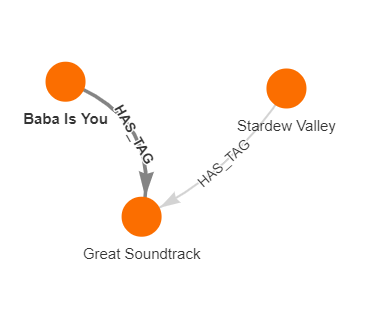
When I look up any game on Steam game launcher, I can see if this game is relevant to me and why, based on the games I’ve played or just have in my Library. One of the games I would like to buy is Baba Is You, an indie puzzle game. When I look over its Steam page and check its relevance to me, I can see that this game is similar to Stardew Valley.

Instead of finding out all of the similarities between those two games, let’s see the shortest path from Baba Is You and Stardew Valley:
MATCH path=(g1: Game {name :"Baba Is You"})-[*bfs]-(g2:Game {name: "Stardew Valley"})
RETURN path
The output should look like this:
Let’s try to find out how CD Projekt Red is related to another big company in the gaming industry, Electronic Arts. We can achieve that by using the Breadth-First Search (BFS) algorithm and the following query:
MATCH path=(c1: Company {name :"CD PROJEKT RED"})-[* bfs]-(g2:Company {name: "Electronic Arts"})
RETURN path
With the output looking like:
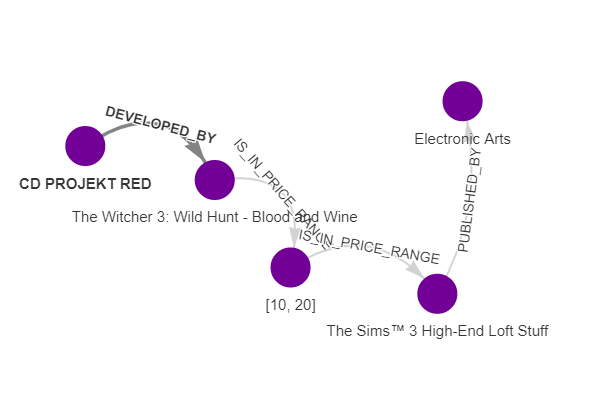
This result shows a path between two companies using the least amount of nodes. If we want to find the most relevant path, we need to use Dijkstra’s algorithm and modify our query:
MATCH path=(c1: Company {name :"CD PROJEKT RED"})-[*wShortest (e, n | e.relevance) total_weight]-(g2:Company {name: "Electronic Arts"})
RETURN path
The result of the query should look like this:
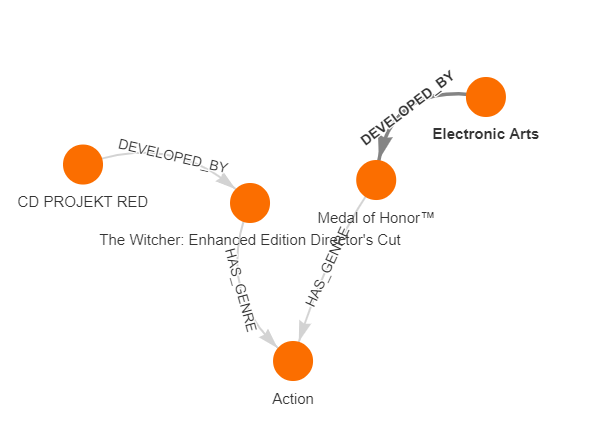
Comparing the two results, we see different paths - the first graph is using the Price_Range characteristic and the second one is using the Genre characteristic. The query above can be easily modified to find how two games are related using more relevant edges.
Conclusion
As shown above, building an objective recommendation system is possible and fairly easy to achieve. To increase the credibility of a system like that, it is important to use as detailed data as possible. This system can be easily expanded by introducing a different relevance system or using a descriptive review method to determine the game’s position in the graph. Also, different graph algorithms can be used. That gives us a lot of potential for expansion.