Five Recommendation Algorithms No Recommendation Engine Is Whole Without
Have you ever noticed how online stores or streaming platforms suggest products or movies that seem tailored just for you? Well, you can thank recommendation engines for that! These nifty recommender systems use data, machine learning, and even natural language processing algorithms (for content-based recommender systems) to suggest items that you're likely to enjoy based on your past interactions. Plenty of companies today invest in building up their own recommender system to get ahead in a competitive environment: identify a connection between similar users considering the user feedback and reviews, as well as suggest services based on user preferences.
To truly make their mark in the market, companies need to have highly performant recommendation engines that analyze data from every angle as opposed to only a subset. A truly accurate and adaptable recommender system dissects those relationships to extract their significance, influence, and weight.
Collaborative filtering methods
Relationships are analyzed using recommendation algorithms. And the most widely used recommendation algorithm is collaborative filtering - a method for automatically predicting (filtering) user likes and dislikes by gathering preferences or taste information from other users (collaborating). The collaborative filtering method's core premise is that if two users have the same view on a certain subject, they are more likely to have it also on a different subject than two randomly selected people. In other words, collaborative filtering puts a lot of weight on user similarity by considering the user's past behavior and user-item interactions.
To illustrate, collaborative filtering recommender systems for product preferences forecasts which products a user will enjoy based on a partial list of the users' interests (reviews).

However, these collaborative filtering algorithms that connect two or three dots within data —although very popular — are no longer good enough. Developers spend a lot of time and resources researching algorithms that take into account all sorts of data that could influence somebody's purchase, such as their shopping habits, market trends, wishlist contents, recently viewed items, search history, reviews, platform activity, and many more.
Developing an algorithm to take so many variables into consideration isn't an easy task. Especially in relational databases where creating connections between tables is expensive even with as rudimentary algorithms as collaborative filtering.
Graph recommendation algorithms
But data stored in graph databases is already connected with rich relationships. Graph algorithms use those relationships between nodes to extract key information and combine them to give precise recommendations. That is precisely why most of the algorithms used for recommender systems have been designed especially for graphs. And the best thing is, the algorithms and their implementations are free to use. You only need to adjust them to your particular use case.
Some of the graph algorithms used in recommendation systems are breadth-first search (BFS), PageRank, community detection, and link prediction. And if the recommendation system you're building is time-sensitive, dynamic versions of algorithms become applicable.
Dynamic algorithms do not recalculate all the values in the graph, from the first to the last node, as the standard algorithms do. They only recalculate those values affected by the changes in the data, thus shortening the computation time and expenses.
Breadth-first search (BFS)
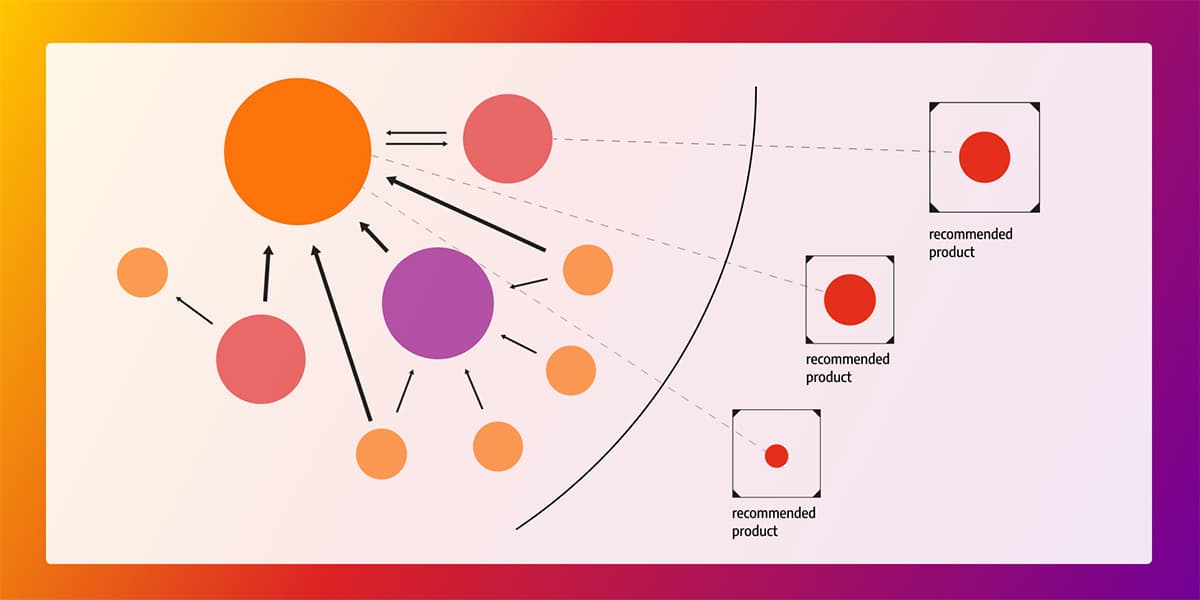
In recommendation engines, the breadth-first search can be used to find all the products the new user might be interested in buying based on what other people with a similar shopping history bought.
The algorithm is simple, it chooses a starting node and starts exploring all the nodes that are connected to it. Then, it moves the starting point to one of the explored nodes and finds all nodes that are connected to that node. Following that logic, it goes through all the connected nodes in a graph.
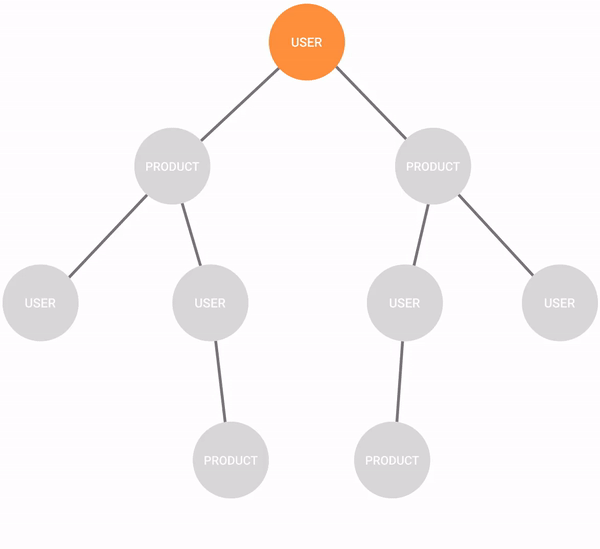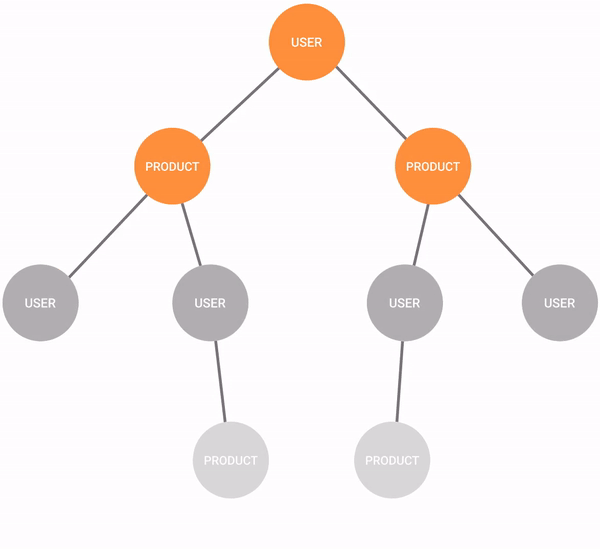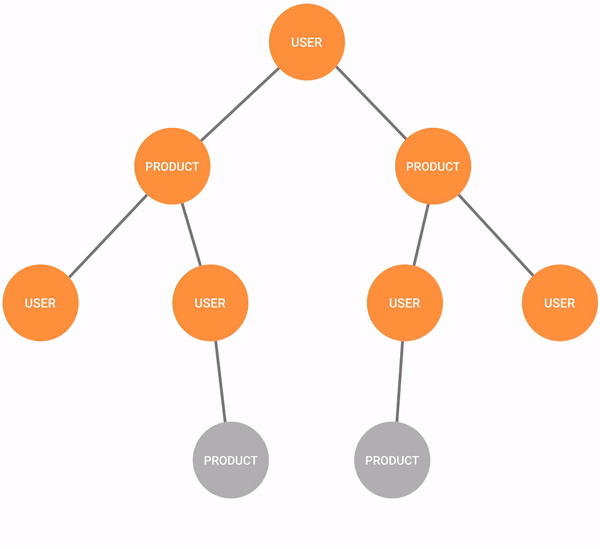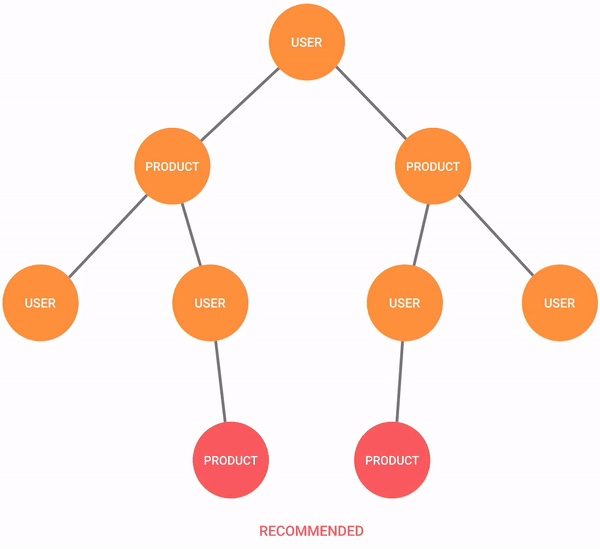
In recommendation engines, the algorithm would start with the user and find all the products the user bought. From those products, it would deepen the search to find all the users that bought those same products. Then, it would find all the other products those users bought which are not connected to the target user, meaning the user didn't buy those products.
Upon further filtering, defined by certain criteria in the history of the target user, products would be filtered out. For example, maybe the given user never bought or searched for any equipment for freshwater fishing, so it doesn't make sense to recommend those products. Maybe the user's preference is buying in bulk or when items are discounted. In the end, the recommender system recommends the items that the particular user might be most interested in buying.
PageRank
PageRank algorithm can be used to recommend the best fitting or currently trending product that the target user might be willing to purchase. The recommendation is based on the number of times this product was bought and how reliable the users were that bought or reviewed the product. A reliable user is a user with a valid shopping history and reviews. An unreliable user is a fake customer buying to pump up selling numbers of specific products to make them appear desirable.
The algorithm calculates the importance of each node by counting how many nodes are pointing to it and what their PageRank (PR) value is. There are a few methods to calculate the PR values, but the most common one is PageRank Power Iteration. PR values can be values between 0 and 1, and when all values on a graph are summed, the result is equal to 1. The essential premise of the algorithm is that the more important a node is, the more nodes will be connected to it.

In recommender systems, the PageRank algorithm can be utilized to detect the most trending products or find users who are the most influential (meaning things they buy are often bought by a lot of other users) and incorporate that result in the final recommendation.
Community detection algorithms
A recommender system benefits from analyzing how users interact. According to a user's behavior, they can identify customers with similar interests and behavior patterns and group them respectively. Once a group of users with similar buying habits is identified, recommendations can be targeted based on the groups they belong to and the habits of that group.
Detecting groups of people, or communities, is done by using community detection graph algorithms. Graph communities are groups of nodes where nodes inside of the group have denser and better connections between themselves than with other nodes in the graph.
The most used community detection graph algorithms are Girvan-Newman, Louivan, and Leiden. The Girvan-Newman algorithm detects communities by progressively removing edges from the original network. In each iteration, the edge with the highest edge betweenness — that is, the number of shortest paths between nodes that go through a specific edge — is removed. Once the stopping criteria are met, the engine is left with densely-connected communities.
Louvain and Leiden algorithms are similar, but the Leiden algorithm is an improved version of the Louvain algorithm. Both algorithms detect communities by trying to group nodes to optimize modularity — a measure that expresses the quality of the division of a graph into communities.
In the first iteration, each node is a community for itself, and the algorithm tries to merge communities together to improve modularity. The algorithm stops once the modularity cannot be further improved between two iterations.
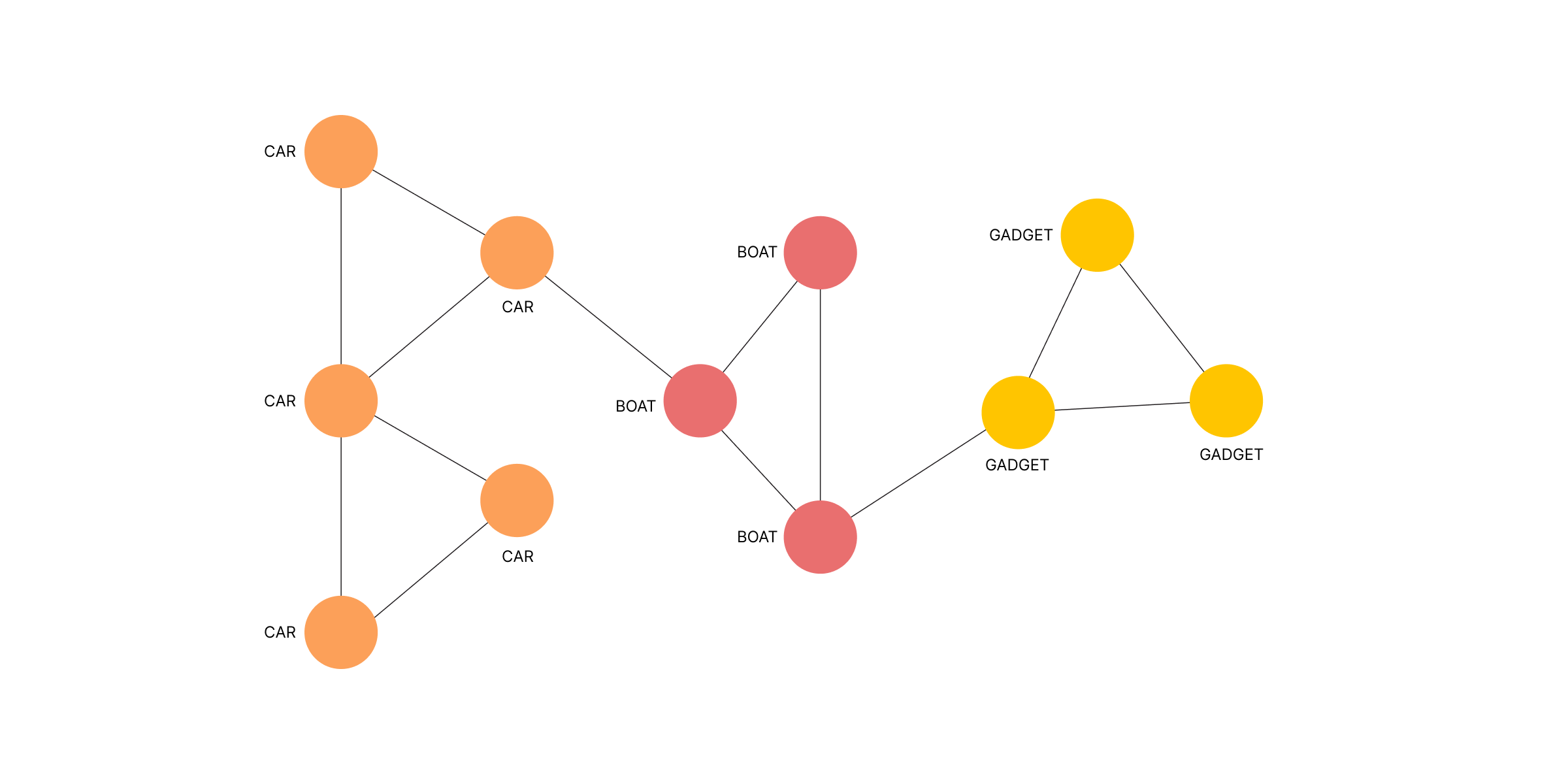
Any of these algorithms can be used in recommendation engines for detecting communities of users. A community can be a group of users that are buying products from the same categories or have similar buying habits/wishlists. Considering the community the customer belongs to, recommendations are given based on what others in the same community are buying.
Link prediction
Graph neural networks (GNNs) have become very popular in the last few years. Every node in a graph can have a feature vector (embedding), which essentially describes that node with a vector of numbers. In a standard neural network, the connection to others is regarded only as a node feature.
However, GNNs can leverage both content information (user and product node features) as well as graph structure (user-product relationships), meaning they also consider node features that are in the neighborhood of the targeted node.
In a recommender system, GNNs can be used for link prediction tasks. Link prediction requires the GNN model to predict the relationship between two given nodes or predict the target node (or source node) given a source node (or target node) and a labeled relationship.
That would mean that the GNN model within the recommender system would be given two nodes as input. One node represents a customer, and the other represents a product. Based on the current graph structure and features of those two nodes, the model predicts if the customer will buy this product or not. Typically, the GNN model learns more about and makes better recommendations to active users.
Dynamic algorithms
Data in recommender systems is constantly being created, deleted, and updated. And recommendation algorithms need to take into account every single change that happens out there to make the best recommendation.
Standard algorithms we mentioned above need to recalculate all the values from the very first node onto every or every few changes. This redundancy creates a bottleneck as it is very time-consuming and computationally expensive.
But graphs have a solution to this problem as well - dynamic graph algorithms. By introducing dynamic graph algorithms, computations are no longer executed on the entirety of the dataset. They compute the graph properties from the previous set of values.
Recommendation graph algorithms mentioned above, such as PageRank, Louvain, and Leiden, have their dynamic counterparts which can be used in dynamic streaming environments with some local changes. With the dynamic version of algorithms, recommendations become time-sensitive and adapt to changes instantly.
Key takeaways
The power behind any recommendation engine is the algorithms used to create recommendations. The most powerful recommendation algorithms are made especially for graph data. In this blog post, we covered more than five algorithms that calculate precise and effective recommendations. That's five more reasons why your recommendation engine should use a graph database instead of a relational one.
And if you are already using a graph database, but some of these algorithms still appear new to you, give them a try! They may impact your recommender system better than you would expect.