
How Much Money Will You Spend on Hosting a Database
Each modern application needs an appropriate database that has basic datastore capabilities or strong analytical capabilities. There is a variety of options to choose from, and choosing a database can be a complex adventure. Just start with the proprietary or open-source choice, and things get very messy. But, after screening several database options and their features, you will probably narrow it down to a few possible candidates for your databases. No matter what databases are on your shortlist, open-source or proprietary, there are always some costs attached to running that database system. At some point in decision-making, the cost will be one of the most important factors when deciding between your options. The issue is that approximating the true future cost of owning a database can be hard.
The cost can come from various sources, such as licensing, training, features included, support, and hosting of the database etc. Each mentioned cost is important and should be considered independently because it can differ from vendor to vendor. But, it’s the accumulation of those costs that form the cost of ownership. One cost is often overlooked - hosting. And it can differ tremendously from database to database.
The cost of hosting a database is always present and constant, if you are renting a full VMs and the data volume is not growing rapidly. Since hosting costs are usually paid in shorter time frames, for example on a monthly basis, they can add up to noticeable sums over time. Understanding the cost of ownership and hosting costs, in particular, can give you a full view of the database cost.
If you have highly interconnected and recursive data and you want to do analytics on it, you will have to find an appropriate graph database. In this blog post, we will compare the hosting costs of running Memgraph and Neo4j graph databases.
Memgraph and Neo4j are compatible databases. Both use Bolt protocol and Cypher for queries, which means you can easily switch your infrastructure between them. Both vendors have free community and paid enterprise editions of the database. There are some differences between editions, for example Memgraph community edition has a replication for high availability, while Neo4j community does not. To understand difrences in hostings costs, let’s see how community editions compare head-to-head.
Approximate the cost of hosting a database
When engineers start to think about the cost of ownership of database systems and compare vendors, they usually focus on server resource usage. Engineers like to keep track of each CPU cycle, megabyte spent here and there, and overall database performance. Hence, the important metrics are CPU time, RAM, Network and disk storage. Network and disk storage can also contribute cost, but in this blog post we will be talking about small to medium datasets in which case these two parameters play a minor role.
CPU time is the cost of running computations on the database. Since you will probably rent a full cloud virtual machine just for your database, CPU time will not matter too much. But overall database performance will be important since performance can limit your use case. To combat database inefficiency and higher load, you will have to increase CPU count or CPU power. Performance of each database was already discussed in the Memgraph vs. Neo4j: A Performance Comparison.
RAM usage is what can considerably shape the overall price of an instance. In general, you want to use as less CPU and RAM as possible since their high usage can generate a lot of costs. Let’s assume that you have an unspecified-sized dataset at the moment, and you need to host Memgraph and Neo4j on the most popular cloud VM vendor, AWS.
Amazon AWS EC2 T3 instances have a balance of computing, memory, and network resources for a broad spectrum of general purpose workloads, including large-scale micro-services, small and medium databases and business-critical applications. There are also other types of instances available on AWS that have different purposes, such as CPU-optimized, memory-optimized, and storage-optimized, that can fit your use case even better, but T3 instances have been chosen for demonstration purposes since they are quite general.
Let's assume you predict running your database for three years on this infrastructure, after which you will probably need to scale up. This would be the on-demand cost of running the instances for a three full-year rent, at the time of writing:
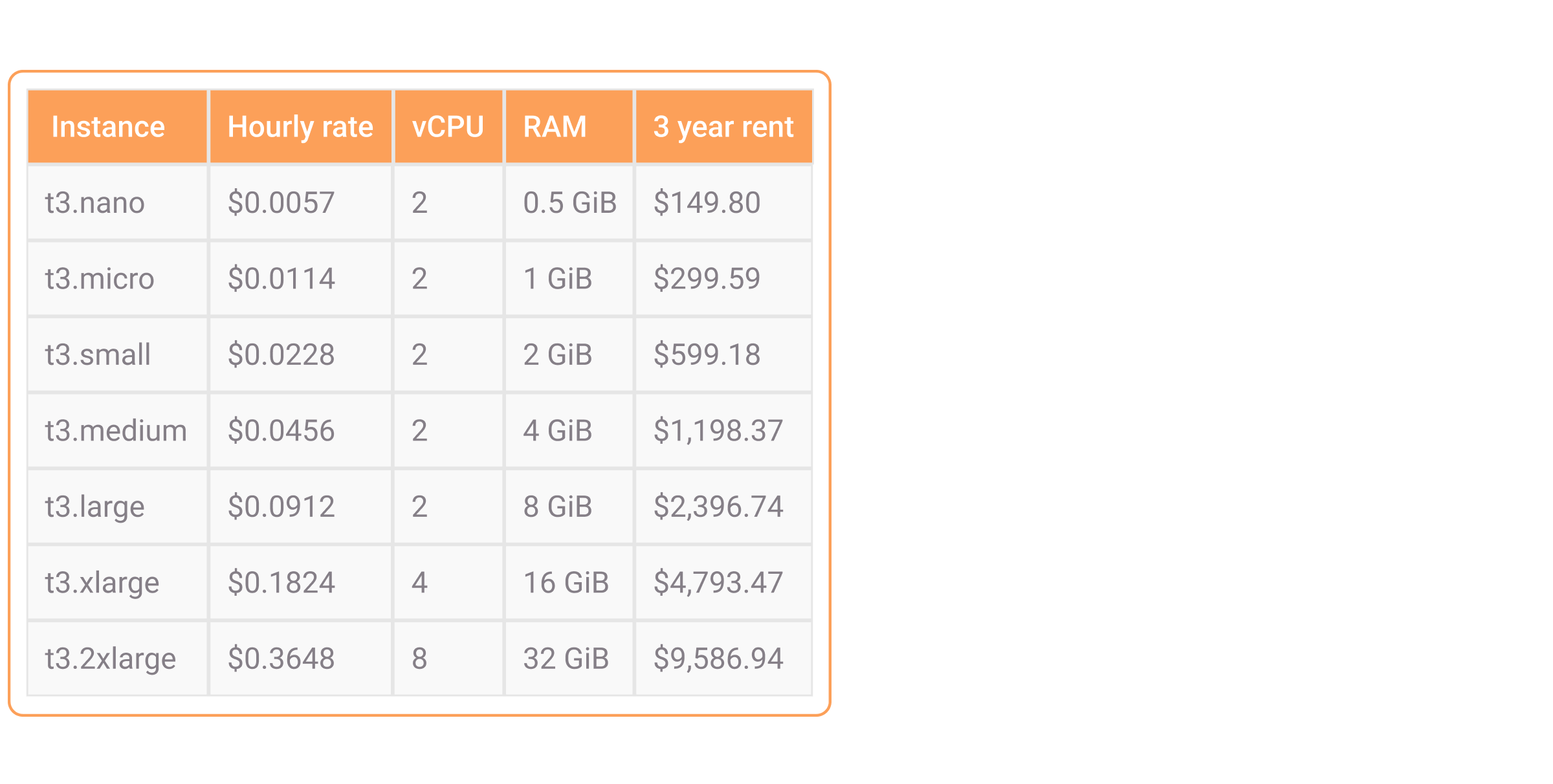
Keep in mind, that AWS offer reservations, which can half the stated renting prices, but this is just an aproximation of the costs. When choosing between Memgraph and Neo4j, their memory usage is what will define how large the instance needs to be and how much money you will need to spend in the end.
Differences between Memgraph and Neo4j memory architecture
Before going into differences in memory usage, it is important to understand how both systems operate. Since Neo4j and Memgraph are architecturally different systems, they use memory quite differently.
Memgraph is a native C++ database and stores all data in RAM memory. No data is stored on the disk, and all queries are executed on the data in RAM. Memgraph supports persistency, which means that if the server loses power, data present in Memgraph at the moment before the crash will not be lost. Persistency is achieved with periodic snapshots saved as a backup on disk. By design, Memgraph is better equipped to execute real-time computations that need to be executed in the shortest possible timeframe.But for this very reason, Memgraph is limited by the available RAM of your machine. If your dataset doesn’t fit in RAM, you can’t use Memgraph. That’s why it’s important to calculate the approximate size of your dataset beforehand and find out how to control memory.
Neo4j story is a bit more complex since it’s JVM based. JVM performs all RAM allocation, and JVM overhead comes with Neo4j as standard. Since Neo4j is contained in JVM, understanding complete memory usage is not as straightforward as with Memgraph. On top of that, Neo4j stores all the data on disk, but it is also loading data in RAM as a cache. This means queries can use both data from RAM and disk. Querying the data from RAM will lead to faster performance while querying the data from disk will lead to performance degradation.
The memory storage available for caching is defined by the page cache property in the Neo4j configuration. It gives you the ability to define how much graph data can be stored in RAM. Neo4j is not limited by total RAM, but rather by total disk storage, but a drop in the Neo4j’s performance without the RAM would be noticeable.
To improve performance, Neo4j will try to load as much data as possible to the RAM cache, performing the so-called warm-up process.The documentation recommends giving 90% of the instance available memory to the page cache. That is an optimization from the Neo4j side that will help improve the overall performance of Neo4j.
Even though there are many differences between on-disk and in-memory storage, the choice primarily depends on your use case and your requirements.
Benchmark shines light on hosting costs
Now that you know that memory usage is an important factor for hosting costs and how both Memgraph and Neo4j work with memory, how do you actually decide which database to chose? The best option would be the one that uses less memory, thus enables you to use smaller instance. To find out memory measurements, we have executed workloads on the database containing the Slovenian social network, Pokec available in three different sizes, small, medium, and large:
- small - 10,000 vertices, 121,716 edges
- medium - 100,000 vertices, 1,768,515 edges
- large - 1,632,803 vertices, 30,622,564 edges
As the sizes of the datasets in production enviroments vary from few thousands to trillions of nodes and edges, these datasets are all on the smaller, as they are used for demonstration purposes. In the Memgraph storage engine, the small dataset takes approximately 40 MB of RAM, the medium 400MB of RAM, and the large dataset takes approximately 4GB of RAM.
Memory is tracked during importing of the dataset from the CYPHERL file and the execution of two queries. While the workloads are executing on a Linux machine, the script samples the total Memgraph and Neo4j RSS usage every 50 milliseconds and tracks the memory usage
Keep in mind that the workloads were run with the out-of-the-box community version of Neo4j and Memgraph, databases weren’t additionally configured.
The two executed queries are K-hop query and an aggregation query. The expansion or K-hop queries are among the most interesting queries in any graph analytical workload. Expansion queries start from the target node and return all the connected nodes that are a defined number of hops away. It is an analytical query that is fairly cheap to execute and used a lot:
MATCH (s:User {id: $id})-->(n:User) RETURN n.idThe aggregation query is very memory intensive. It needs to match all the nodes in the database and get the minimum, maximum and average values of a certain node property.
MATCH (n) RETURN min(n.age), max(n.age), avg(n.age)So how did Memgraph and Neo4j do on performing these tasks? If you are presuming that, because Memgraph is an in-memory graph database, it must use more RAM than Neo4j, an on-disk graph database, you will be surprised.
The graph below shows memory usage during the execution of an expansion 1 query on a small dataset. The identical query was run 10.000 times on 12 concurrent clients.
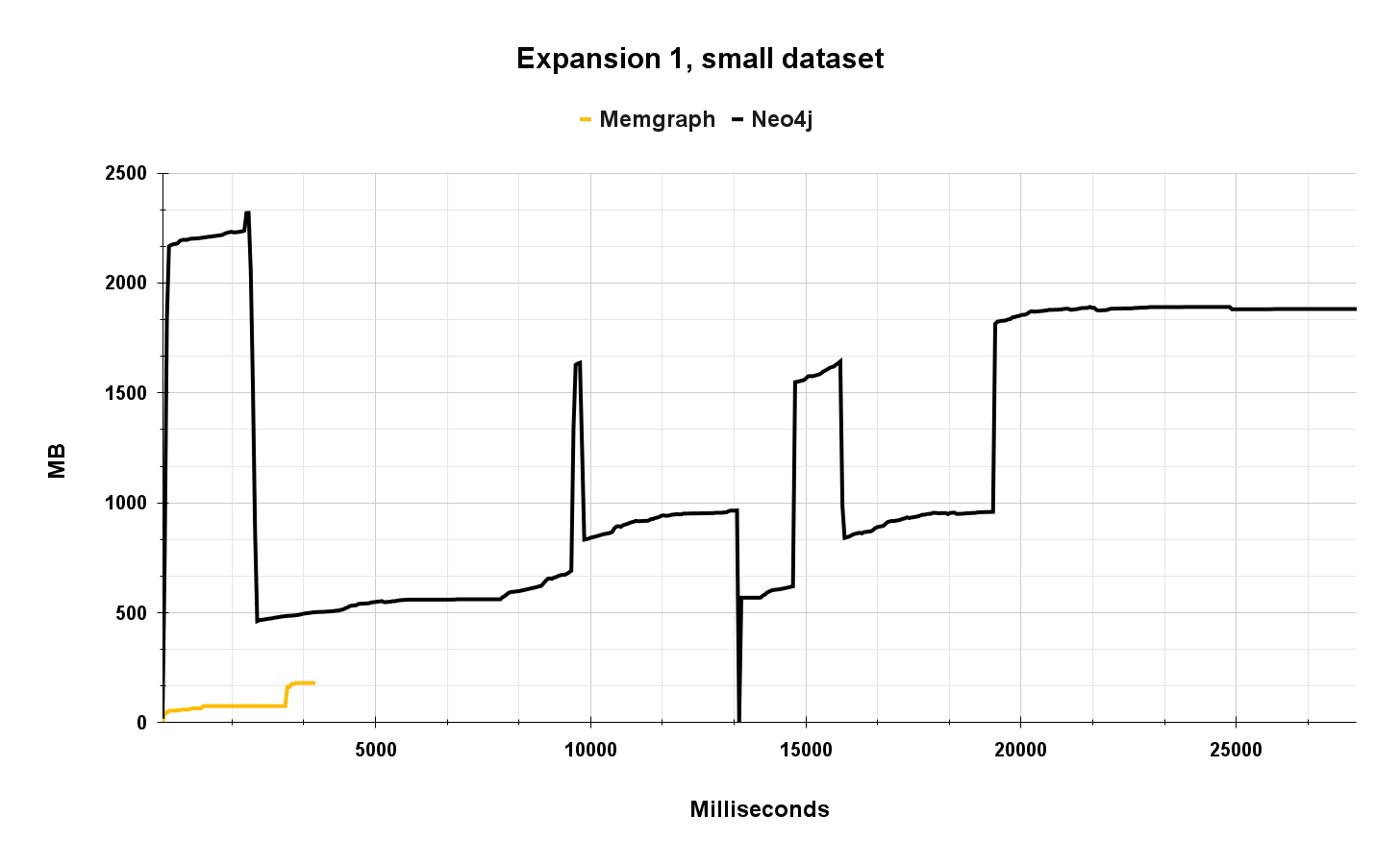
As you can see from the line chart, Memgraph executed these 10.000 queries much faster, and with less memory. As Memgraph executed this workload in just a fraction of the time, compared to Neo4j, the linechart is not the best way to visualize the data.
It is interesting to see how Neo4j memory usage is rising and falling due to the JVM and workload execution, because JVM is trying to allocate optimal amount of memory during the execution. It is important to note that Neo4j is not using all of the memory to execute this workload, meaning that JVM is over-allocating memory for future use, which is usual behavior for JVM-based applications. Due to it, it’s harder to interpret actual memory usage, and Neo4j didn’t ease the process as well.
The graph below shows memory usage during the execution of 10.000 aggregation queries on a small dataset.
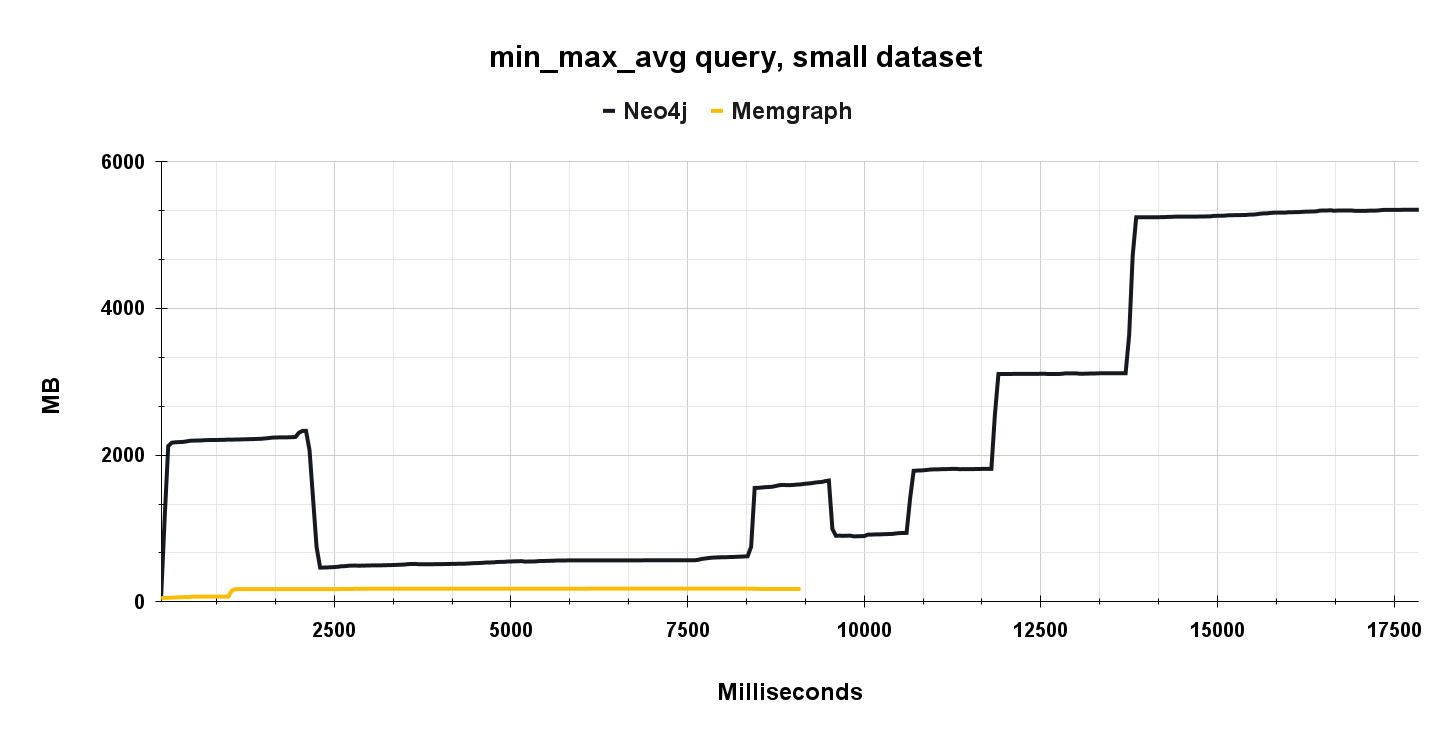
Notice how Memgraph’s memory usage is fairly constant at 300 MB during the entire workload execution, while Neo4j’s memory usage is again using various amounts of memory during the run. Again, JVM allocates extra memory while executing the queries, and in the end, it settles around 5.3 GB.
Neo4j memory usage can be decreased to use RAM for JVM and some extra RAM for other components like transactions, query caching, etc. But as it turns out, the costs of this modification is performance and stability degradation. During testing, we experimented a bit with Neo4j memory usage configurations and limited Neo4j memory usage a bit more aggressively, which resulted in several crashes. The ability to fine-tune a database is great for configuring software into perfect condition, but it can increase engineering costs, since you need to invest engineering time to properly understand the system and fine tune the database configuration. Memgraph is fully self-manageable, which is shown by the constant memory usage.
Overall, Neo4j consumes more memory than Memgraph while executing workloads on the small dataset, which is expected for JVM based system, but this can change with the scale of the dataset. To understand the worst-case scenario of operating the database on AWS instances, peak memory usage should be considered. Peak memory usage will show the amount of RAM the instance should use in the worst case scenario.
Here are peak memory usages for the small dataset:
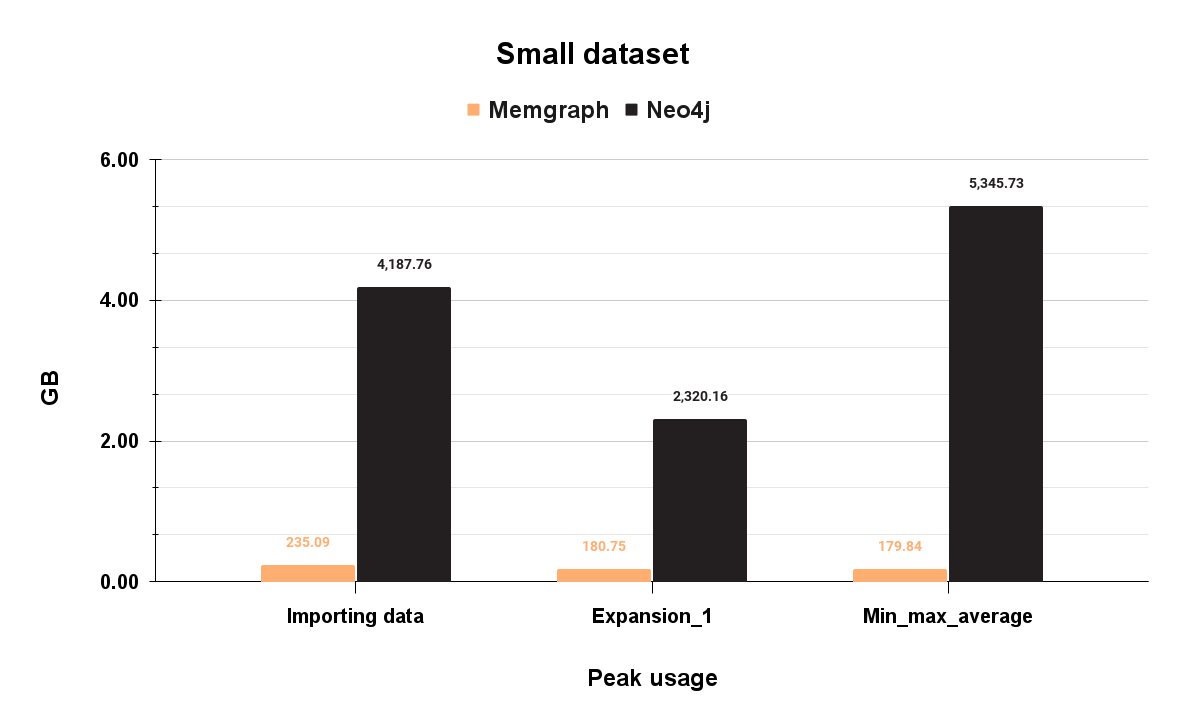
Memgraph peak memory usage is 235 MB during data import, while Neo4j is 5 345 MB during aggregation queries.
In this particular case, Memgraph could potentially fit on the t3.nano instance, but that would be a very thigh squeeze, and the instance could be used only for the database, no other software could be run on the instance. This means Memgraph fits on a t3.micro which costs $299 for a three-year rent. Neo4j, on the other hand, could fit on a t3.large which costs $2.369 for a three-year rent. That is a difference of $2.070 dollars for a three-year rent
Let’s see what happens on a medium-sized dataset:
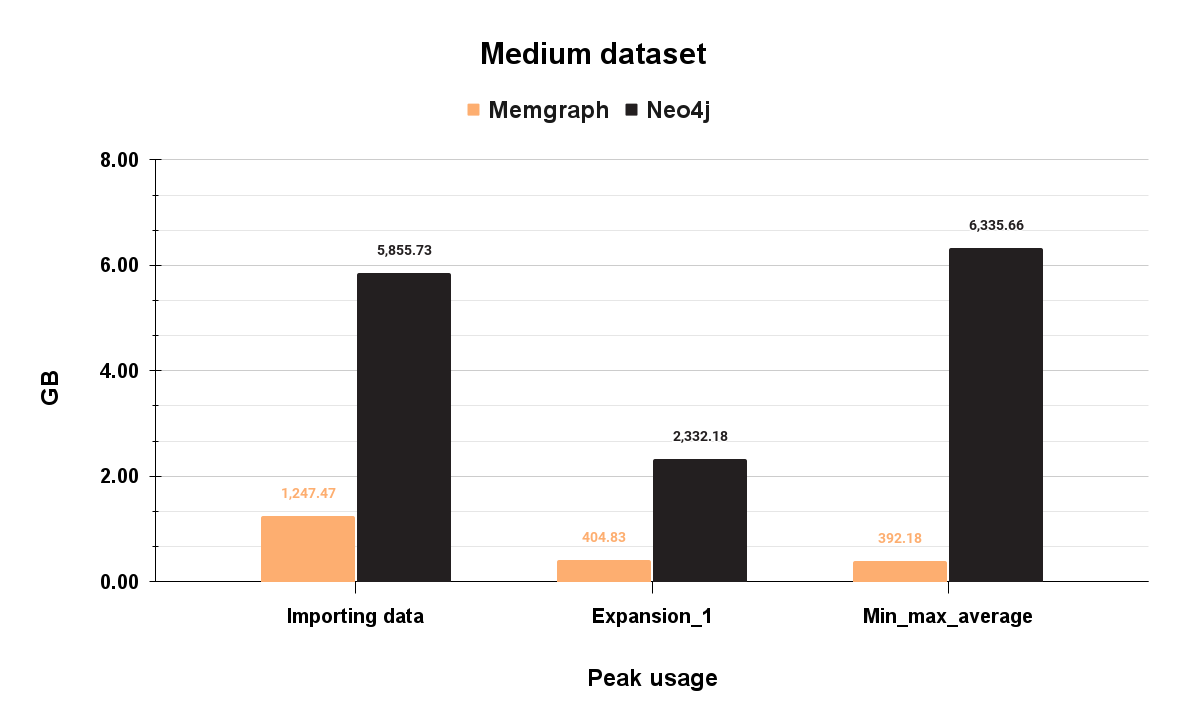
In this case, Memgraph's peak memory usage is 1.2 GB during data import, while Neo4j is 6.3 GB during aggregation queries. Relative to these peak values, Memgraph could fit on a t3.small which costs 599$ for a three-year rent. Neo4j, on the other hand, could fit on a t3.large which costs 2.369$ for a three-year rent. That is a difference of 1.770$ dollars for a three-year rent.
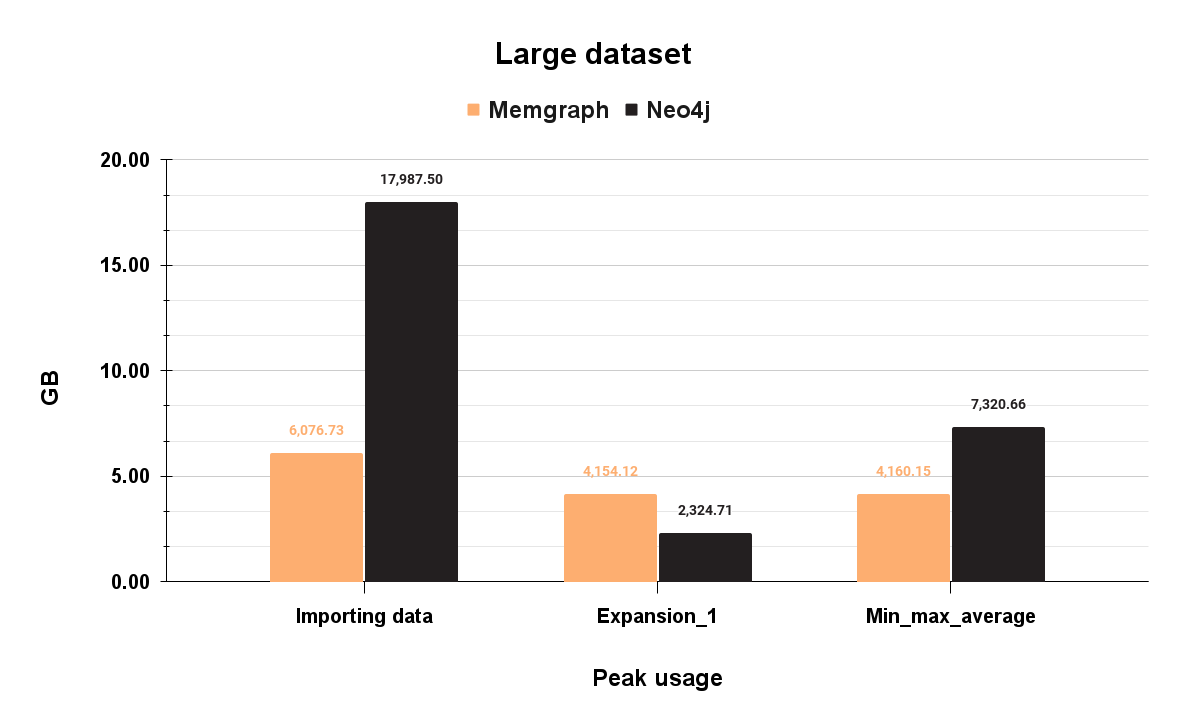
With the large dataset, Memgraph's peak memory usage is 6.07 GB during data import, while Neo4j is 17.9 GB, also on data import. The import process consists of many serial transactions, which is memory-wise stressful for both databases. In this particular case, Memgraph fits on a t3.large which costs 2.369$ for a three-year rent. Neo4j, on the other hand, could fit on a t3.2xlarge which costs 9,586$ for a three-year rent. That is a difference of 7.217$ for a three-year rent.
As you can see, in some situations Memgraph can be more memory efficent then Neo4j. By correlating peak memory usages to AWS instance pricing savings with Memgraph could be substantial. This depends of few factors, such as, dataset size, RAM restrictctios, performance goals, instance types etc.
Conclusion
Database hosting is an interesting cost in the total cost of ownership and it should be taken into consideration before deciding which database to choose. As you can see, Memgraph is a pretty stable database regarding memory usage, which could lead to potentially significant cost savings. On top of that, Memgraph is also faster, which can lead to a more responsive system overall.
We would love to see what type of application you want to develop with Memgraph. Take Memgraph for a test drive, check out our documentation to understand the nuts and bolts of how it works, or read more blogs to see a plethora of use cases using Memgraph. If you have any questions for our engineers or want to interact with other Memgraph users, join the Memgraph Community on Discord!