
Synchronize Data Between Memgraph Graph Database and Elasticsearch
Almost every company today has some kind of database as a single source of truth. Graph databases proved to be useful in almost every industry you know about. They excel in the modeling process since the graph model can naturally map business scenarios that involve interconnected data. Elasticsearch is a flexible, text-processing tool that is used primarily for full-text searching and indexing.
Although some naive text-searching solutions could be built with a graph database like Memgraph, Elasticsearch is better at offering fine-grained searching capabilities specific to text processing. A lot of people have decided to use both systems, but the problem is how to keep them in sync. In MAGE 1.6 we introduce a module that enables developers to serialize Memgraph into Elasticsearch instance using basic authentication. This blog will show you how the model was built and how to use it.
Approaches to syncing
Using Elasticsearch and Memgraph as two completely separated entities and storing the same data in an unrelated fashion is very complicated because it duplicates all processes and operations needed for synchronisation. It is also extremely cumbersome because if some update operation passes successfully on one platform but fails on the other, you are left with an inconsistent state in the system.
To consider Memgraph and Elasticsearch synced, a couple of requirements need to be met. All existing data in the database needs to be indexed and new data should be incrementally indexed the moment it is inserted into the database.
Many options could be used for meeting these requirements:
- Logstash is a server-side data processing system that allows parsing data from more than 200 sources and sending it to Elasticsearch. It also comes with an API with which you can develop a plug-in for parsing data from any custom application you could think of.
- Although not yet supported within Memgraph, Change Data Capture (CDC) would enable capturing changes made on a graph in a transaction and sending them to the ES index.
However, there is one more thing that we should really think about when syncing Memgraph and Elasticsearch and that is expandability. The challenge is to build a solution that will need the minimum amount of change when a new method is required. That is why we decided to use Memgraph’s Pythonic capabilities and create a new query module that uses Elasticsearch’s API inside Memgraph’s graph library MAGE.
If there comes a time when a new method is needed, a few lines can be easily added with custom processing logic in Python without (re)starting any processes. A subtle performance degradation might be noticed because of the cost imposed by using the communication over the network, but Elasticsearch offers many parameters that can be tweaked when indexing new documents, such as max_chunk_bytes, chunk_size and the number of threads when documents are indexed in parallel.
Connecting to Elasticsearch and indexing the database
To test the sync, we installed Elasticsearch and Memgraph Platform. When Elasticsearch is first started, if the authentication is enabled, the username, password, path to the certificate file and the instance URL will be printed out. This information needs to be stored securely since it’s needed for connecting to the Elasticsearch instance.
From the Dataset section of Memgraph Lab, we uploaded the Karate dataset and inserted 34 nodes and 78 edges into the database. Since the dataset is small, the testing will be extremely fast.
The following query connects Memgraph with a local or production-ready Elasticsearch instance:
CALL elastic_search_serialization.connect("https://localhost:9200", "~/elasticsearch-8.4.3/config/certs/http_ca.crt", <ELASTIC_USER>, <ELASTIC_PASSWORD>) YIELD *;Once successfully connected, Memgraph will provide an output similar to the one below:
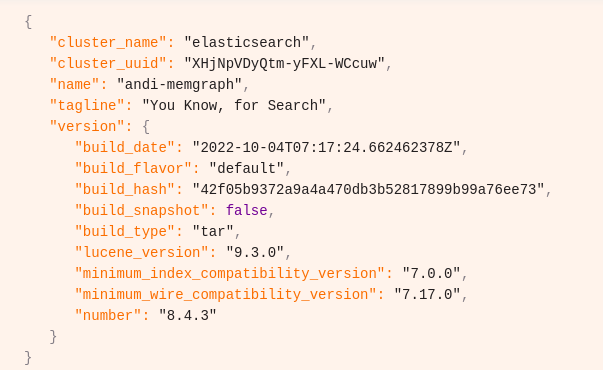
Now, we can create an index to serialize nodes or relationships into documents. It seems the best option is to create two indexes, one for nodes and another for relationships.
Before creating the actual Elasticsearch indexes, we also need to create a schema to properly serialize node and relationship properties into documents. We’ve used the following node and relationship schema.
The following two queries will create node and relational indexes inside Elasticsearch:
CALL elastic_search_serialization.create_index("mem_nodes_blog",
"/home/andi/Memgraph/code/nuix/node_index_path_schema.json",
{analyzer: "mem_analyzer", index_type: "vertex"}) YIELD *;CALL elastic_search_serialization.create_index("mem_edges_blog",
"/home/andi/Memgraph/code/nuix/edge_index_path_schema.json",
{analyzer: "mem_analyzer", index_type: "edge"}) YIELD *;The first parameter is the name of the created index while the second one specifies the path to the schema. With schema_parameters you can specify the analyzer you want to use, whether the index is intended to be used for nodes or relationships and the number of replicas and shards. Check out the docs for more info.
Memgraph returns the following result if the indexes are successfully created:
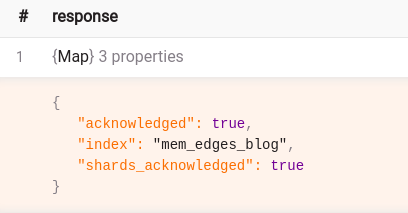
Now, it’s time to start indexing entities residing inside Memgraph with the following query:
CALL elastic_search_serialization.index_db("mem_nodes", "mem_edges", 4) YIELD * RETURN *;Number 4 specifies the number of threads on the Elasticsearch instance used to concurrently index the provided documents.
Once indexing is done, the output is the number of indexed nodes and relationships.
The only thing left to do is to find nodes and relationships of interest and query Memgraph about them. So as not to complicate, let’s fetch all the nodes we previously indexed.
CALL elastic_search_serialization.scan(“mem_nodes_blog”, "{/"query/": {/"match_all/": {}}} ") YIELD *;The above query returns a list of 34 results with properties serialized as specified in the schema:

Syncing with triggers
Now that we are sure entities are indexed in Elasticsearch, we can think about indexing data coming to Memgraph without reindexing the whole database. We need triggers because they enable us to execute a specific procedure upon some event. In our case, the event is the insertion of new nodes and relationships.
Let’s expand the example by creating a trigger that will in parallel index new nodes and relationships inserted into the database upon transaction commit:
CREATE TRIGGER elastic_search_create
ON CREATE AFTER COMMIT EXECUTE
CALL elastic_search_serialization.index(createdObjects, “mem_nodes_blog”, “mem_edges_blog”, 4) YIELD *;We can test the trigger by creating a new node, and connecting it to the existing user.
CREATE (:__mg_vertex__:`User` {__mg_id__: 111111, `name`: "memgraph", `id`: "blog"});MATCH (u), (v) WHERE u.name = “12” AND v.name = “memgraph” CREATE (u)-[:`FRIENDS_WITH` {test: “memgraph”}]->(v);The two created entities will automatically get indexed inside Elasticsearch:
CALL elastic_search_serialization.scan(“mem_nodes_blog”, "{/"query/": {/"match_all/": {}}} ") YIELD *;
CALL elastic_search_serialization.scan(“mem_edges_blog”, "{/"query/": {/"match_all/": {}}} ") YIELD *;
Memgraph can even handle multiple triggers with multiple Elasticsearch instances (essentially many-to-many connections).
Conclusion
In this blog post, we explained how to sync Memgraph with Elasticsearch using query modules and triggers and what are the benefits of having such a system.
You can find the implementation code on Memgraph’s GitHub, feel free to check it and leave comments, we will be more than happy to respond to them. We are also available on Discord for any questions. If you are interested what other novelties come with MAGE 1.6 be sure to check the MAGE changelog.