
LLM Limitations: Why Can’t You Query Your Enterprise Knowledge with Just an LLM?
Large Language Models (LLMs) like ChatGPT and GPT-4 are incredible tools. They can write essays, generate code, and even hold surprisingly coherent conversations. But if you’ve ever thought, “Can I use this to query all my company’s data?”—the short answer is: not really.
Here’s why relying solely on an LLM for enterprise knowledge querying doesn’t work and what you can do about it.
LLMs Are Generalists, Not Specialists
Think of LLMs like the ultimate trivia champion. They’ve read tons of books, articles, and online discussions, so they know a lot about everything. But when it comes to your company’s proprietary data—sales reports, technical documentation, or customer feedback—they’re clueless.
Why?
- They weren’t trained on your data. LLMs like GPT are trained on publicly available information, not your internal documents.
- They lack context. Even if you try to feed your enterprise data into the LLM, it doesn’t “remember” it or fully grasp its importance.
Key Limitations of LLMs for Enterprise Knowledge
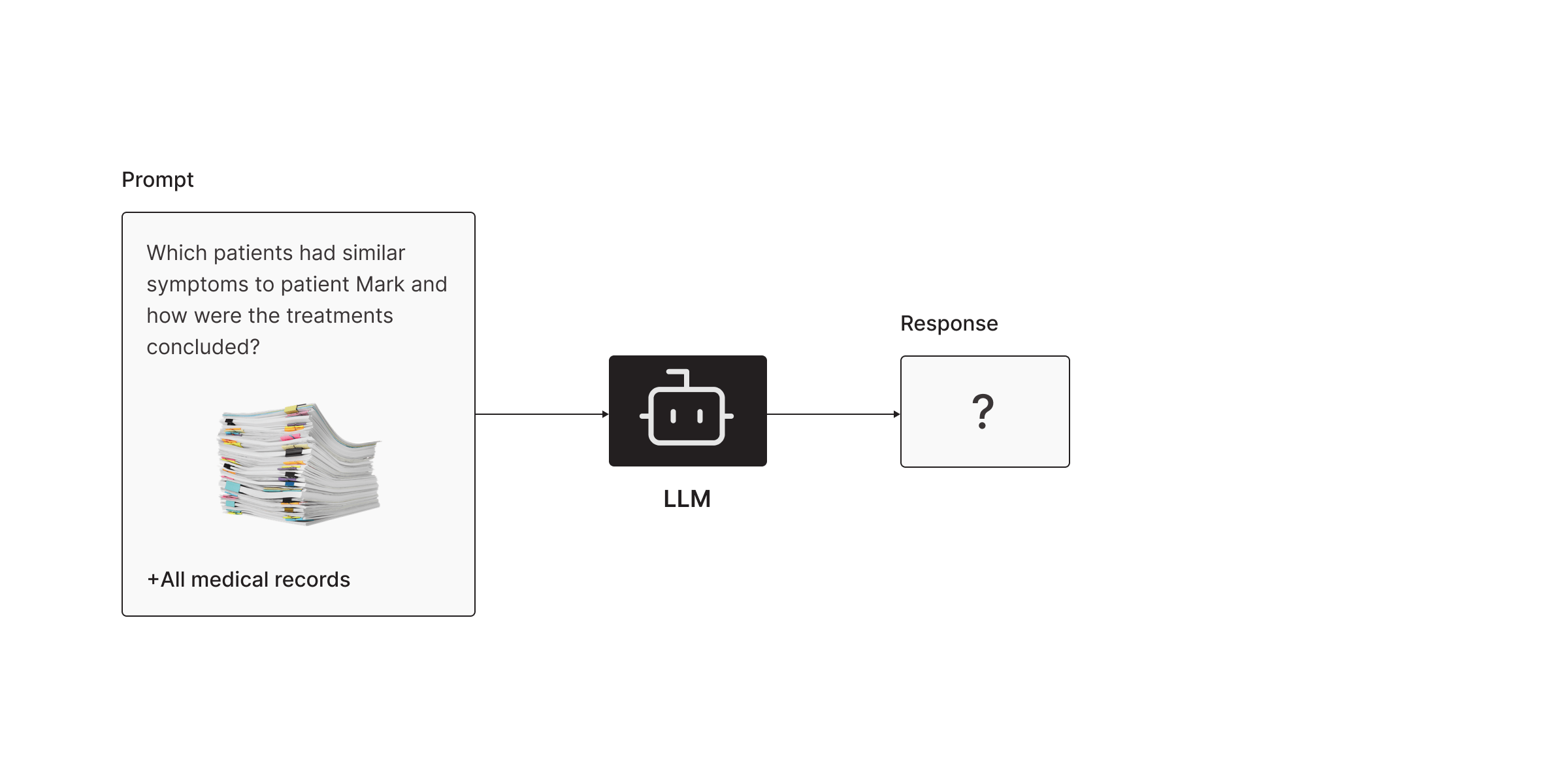
1. The Context Window Is a Brick Wall
LLMs can only handle a limited amount of text at a time, known as the context window. For example, GPT-4 has a token limit of 8,000 tokens (around 6,000 words). Even with newer models that boast expanded context windows, there’s still a cap.
Here’s the problem:
- Your enterprise data probably spans terabytes—way more than an LLM can store in their context window.
- Even if you chunk the data, the LLM can only “see” the part you’ve fed it in a single query.
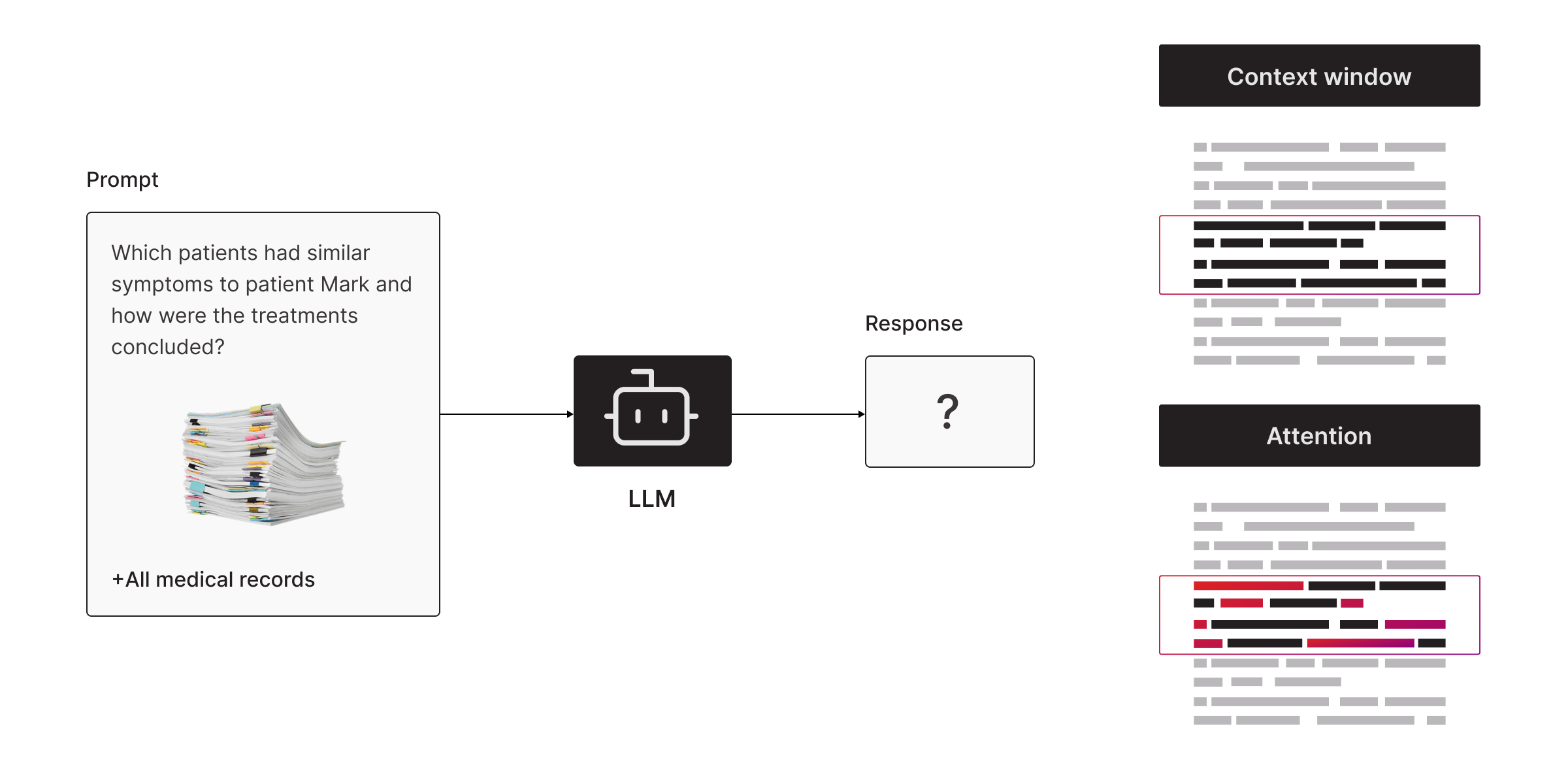
2. Attention Deficit Disorder
Within the context window, the LLM tries to identify the most important bits of information. But here’s the catch:
- Relevance is subjective. The LLM might grab onto the wrong details and miss what you actually care about.
- Prompt engineering is a guessing game. Crafting the perfect query to get a useful answer is more art than science—and not foolproof.
For enterprise scenarios, where precision matters, this kind of hit-or-miss approach isn’t ideal.
3. LLMs Lack Reasoning
LLMs don’t reason like humans. They generate responses by predicting the next word based on patterns in their training data. This works well for conversational tasks but falls short when:
- Deep reasoning is required. For example, understanding complex relationships between entities in your data.
- Fresh data is involved. LLMs can’t keep up with real-time changes in your enterprise knowledge.
4. Data Security and Privacy Concerns
Your enterprise data is sensitive. Feeding it into a cloud-based LLM like ChatGPT raises questions like:
Where does the data go? Is it stored? Who has access to it? Will the next version of ChatGPT be trained on it?
Many organizations avoid using public LLMs for proprietary knowledge due to these risks.
Why You Can’t Just “Train the LLM on My Data”
You might think, “Fine, I’ll just train the LLM on my data!” Great idea in theory, but in practice, it’s not that simple.
- Fine-tuning is expensive. You’ll need massive compute resources, like GPUs with loads of memory, and even then, it’s slow.
- It’s a moving target. If your data updates frequently, you’d have to retrain the model constantly.
- It requires expertise. Fine-tuning isn’t plug-and-play. You need deep knowledge of neural networks and hyperparameter tuning.
Watch: How to fine-tune an LLM? Getting started
The Solution: Augment LLMs with Context
To make LLMs work for enterprise knowledge, you need to give them superpowers. That’s where approaches like Retrieval-Augmented Generation (RAG) come in.
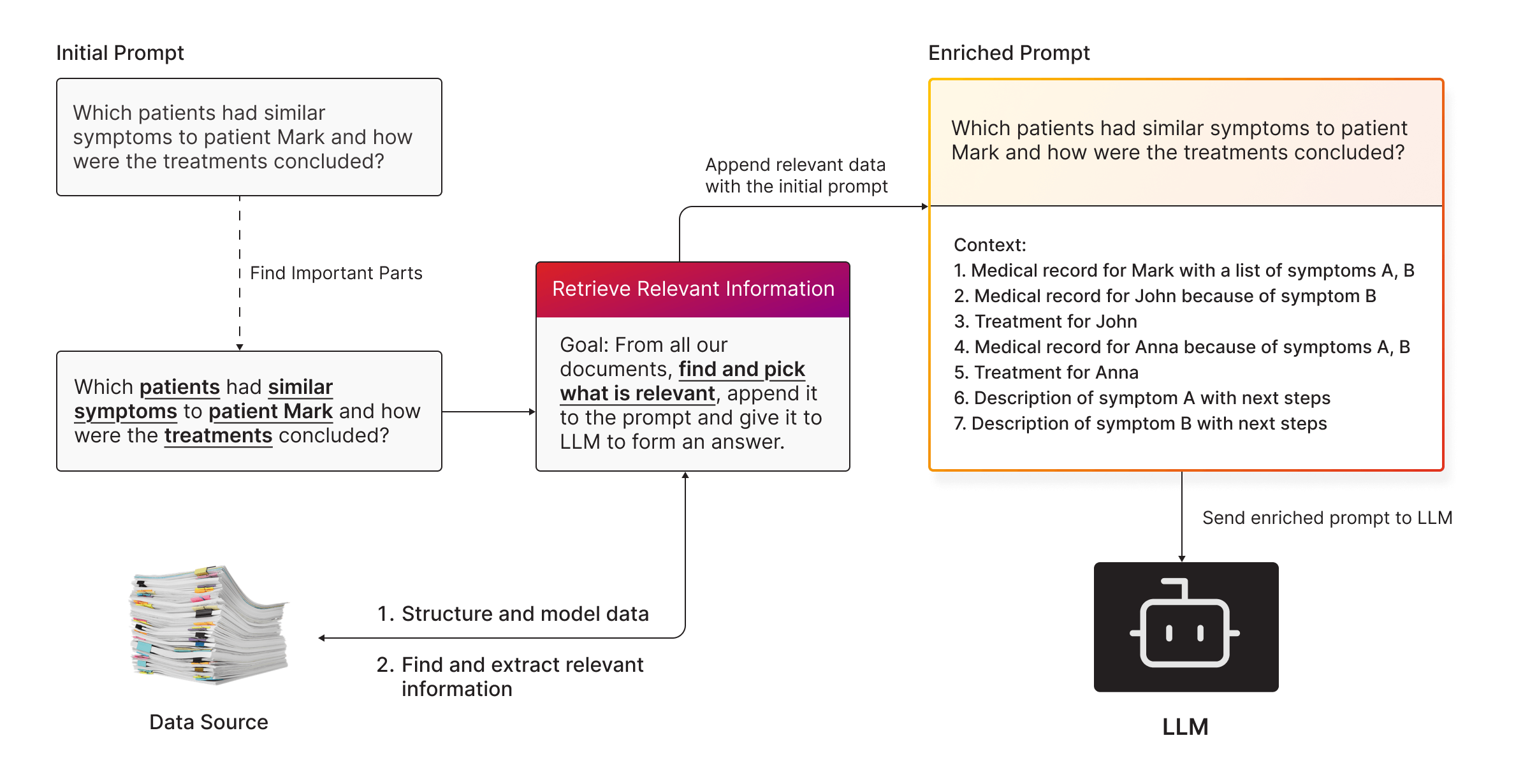
How RAG Solves the Problem
- Store your data somewhere accessible. Use a graph database, vector database, or another structured data store.
- Find what’s relevant. Search through your data and retrieve only the pieces related to the query.
- Feed it to the LLM. Append the retrieved data to your prompt for added context.
By combining LLMs with RAG, you get the best of both worlds:
- The conversational abilities of the LLM.
- The precision and specificity of your enterprise knowledge.
TL;DR
LLMs like ChatGPT are amazing at generating text but have critical limitations when it comes to querying enterprise knowledge:
- They don’t know your data.
- Their context window is small, in comparison to your data.
- They can’t reason like humans.
- Fine-tuning is expensive and impractical for dynamic data.
To overcome these challenges, you need systems like RAG to augment LLMs with context from your proprietary data. It’s not about replacing the LLM but making it smarter and more relevant to your needs.
Next time you ask, “Why can’t ChatGPT just know everything about my company?” you’ll know the answer. It wasn’t built for that—but with the right tools, you can make it work.
Continue our GraphRAG blog series: Fine-Tuning LLMs vs. RAG: How to Solve LLM Limitations.