
Migrate from Postgres to Memgraph in Just 15 Minutes with ChatGPT
In database management, quality migration processes can significantly streamline development workflows. it’s about efficiency and adaptability.
Memgraph reduced the development time for a database migration module—listen to this—from PostgreSQL to Memgraph in 15 minutes!
By doing this, I believe we’ve demonstrated our commitment to principles of efficiency and adaptability.
In this blog post, I’ll discuss how we’ve used artificial intelligence, specifically ChatGPT, to generate a complete migration module by autonomously analyzing our existing manually written modules.
Background: Optimization Through Experience
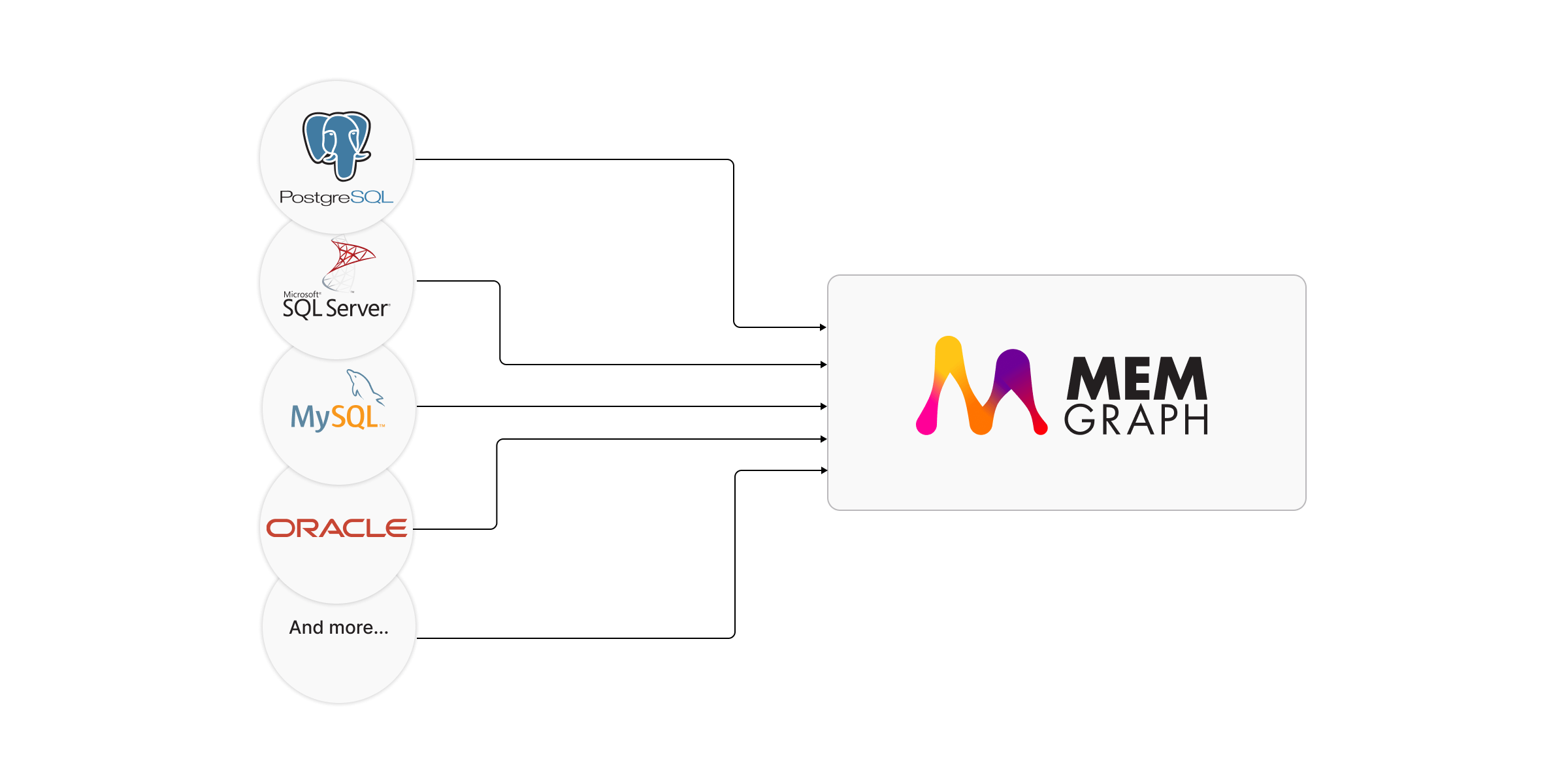
Previously, our team manually developed migration modules for various databases such as OracleDB, MySQL, and SQLServer. While these projects were ultimately successful, they were highly time-intensive and often resulted in delays for crucial integrations.
Each new database system introduced a steep learning curve, primarily due to two significant challenges:
- Familiarization with drivers: Each new source system required time to understand and implement the correct drivers, a process that could significantly extend development timelines.
- Best practices and maintenance: Initial unfamiliarity with best practices around these drivers often led to complex and maintenance-heavy code.
These experiences underscored the need for a more streamlined and efficient approach to developing migration modules.
Innovating with AI
To streamline the creation of migration modules, we integrated AI, specifically ChatGPT, into our development process. ChatGPT analyzed our existing codebases to generate a fully functional migration module for PostgreSQL autonomously.
Here’s how we implemented this AI-driven approach.
Implementation: ChatGPT at Work
The core of the PostgreSQL migration module generated by ChatGPT includes:
from psycopg2 import connect
import threading
from decimal import Decimal
import json
import mgp
# PostgreSQL dictionary to store connections and cursors by thread
postgres_dict = {}
def init_migrate_postgresql(
table_or_sql: str,
config: mgp.Map,
config_path: str = "",
params: mgp.Nullable[mgp.Any] = None,
):
global postgres_dict
if params:
_check_params_type(params, (list, tuple))
else:
params = []
if len(config_path) > 0:
config = _combine_config(config=config, config_path=config_path)
if _query_is_table(table_or_sql):
table_or_sql = f"SELECT * FROM {table_or_sql};"
if threading.get_native_id not in postgres_dict:
postgres_dict[threading.get_native_id] = {}
if Constants.CURSOR not in postgres_dict[threading.get_native_id]:
postgres_dict[threading.get_native_id][Constants.CURSOR] = None
if postgres_dict[threading.get_native_id][Constants.CURSOR] is None:
connection = psycopg2.connect(**config)
cursor = connection.cursor()
cursor.execute(table_or_sql, params)
postgres_dict[threading.get_native_id][Constants.CONNECTION] = connection
postgres_dict[threading.get_native_id][Constants.CURSOR] = cursor
postgres_dict[threading.get_native_id][Constants.COLUMN_NAMES] = [
column.name for column in cursor.description
]
def postgresql(
table_or_sql: str,
config: mgp.Map,
config_path: str = "",
params: mgp.Nullable[mgp.Any] = None,
) -> mgp.Record(row=mgp.Map):
global postgres_dict
cursor = postgres_dict[threading.get_native_id][Constants.CURSOR]
column_names = postgres_dict[threading.get_native_id][Constants.COLUMN_NAMES]
rows = cursor.fetchmany(Constants.BATCH_SIZE)
return [mgp.Record(row=_name_row_cells(row, column_names)) for row in rows]
def cleanup_migrate_postgresql():
global postgres_dict
if postgres_dict[threading.get_native_id][Constants.CURSOR]:
postgres_dict[threading.get_native_id][Constants.CURSOR] = None
postgres_dict[threading.get_native_id][Constants.CONNECTION].close()
postgres_dict[threading.get_native_id][Constants.CONNECTION].commit()
postgres_dict[threading.get_native_id][Constants.CONNECTION] = None
postgres_dict[threading.get_native_id][Constants.COLUMN_NAMES] = None
mgp.add_batch_read_proc(postgresql, init_migrate_postgresql, cleanup_migrate_postgresql)This code snippet highlights how the module initializes, manages, and cleans up database connections using thread-specific storage, crucial for handling concurrent migrations efficiently.
Impact and Technical Advancements
Improved Migration Capabilities
The successful deployment of the PostgreSQL module has significantly broadened our migration capabilities. This efficiency allows us to support a wider array of source systems rapidly, enhancing the versatility of our migration tools.
Enabling Complex Use Cases
With the new module, Memgraph's capability to ingest diverse datasets has dramatically increased. Users can now transition data into Memgraph’s graph-based structure swiftly, unlocking potential for a wider range of use cases involving complex data relationships and real-time insights.
CALL migrate.postgresql('example_table', {user:'memgraph', password:'password', host:'localhost', database:'demo_db'})
YIELD row
RETURN row
LIMIT 5000;This integration not only simplifies the migration process but also boosts the utility of Memgraph, enabling users to tap into graph-based analytics and knowledge discovery directly from their migrated data.
Conclusion
This development in PostgreSQL migration using AI represents a significant enhancement in our database integration technology.
By reducing the module development time to 15 minutes, we are now better positioned to accommodate diverse data migration needs efficiently.
This project not only illustrates our commitment to innovative database solutions but also sets a benchmark for future advancements in the field of database migration and management.