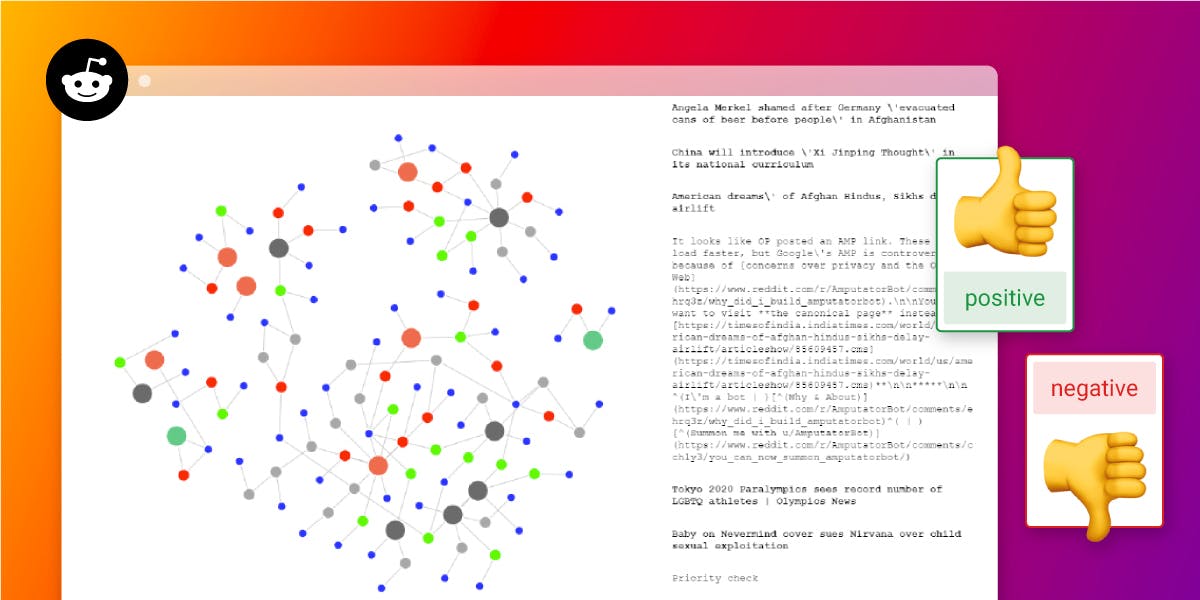
Visualizing and Analyzing Reddit in Real-Time With Kafka and Memgraph
We recently held a company-wide hackathon where we challenged each other to build compelling, useful applications using a streaming data source, Kafka, Memgraph, and a Web Application backend. First up, visualizing and performing sentiment analysis on Reddit posts in real-time.
Our team spent Hackathon week building a graph application on top of streaming Reddit data. If you want to jump right to the code, check out the GitHub repo, and if you want to learn more about it, join our Discord Community Chat!
The Data Source
We knew that we wanted to experiment wtih some sentiment analysis algorithms on the graph we created -- and the real-time requirement meant that we needed something with a good amount of text. Something where there might be feelings involved. Sound familiar? Reddit is a resource we all know and use so it seemed like a great fit.
The Data Model
First, we defined the data model. We wanted to keep it as simple as possible.
There are three kinds of nodes in the graph:
SUBMISSION: A Reddit post that contains the propertiestitle,body,created_at,id,url, andsentiment. Thesentimentproperty denotes if the sentiment of the submission is positive, negative, or neutral.COMMENT: Similarly like theSUBMISSIONnodes, comments contain the propertiesbody,created_at,id, andsentiment.REDDITOR: This node contains information about the user who posted the submission or comment. The only properties areidandname.
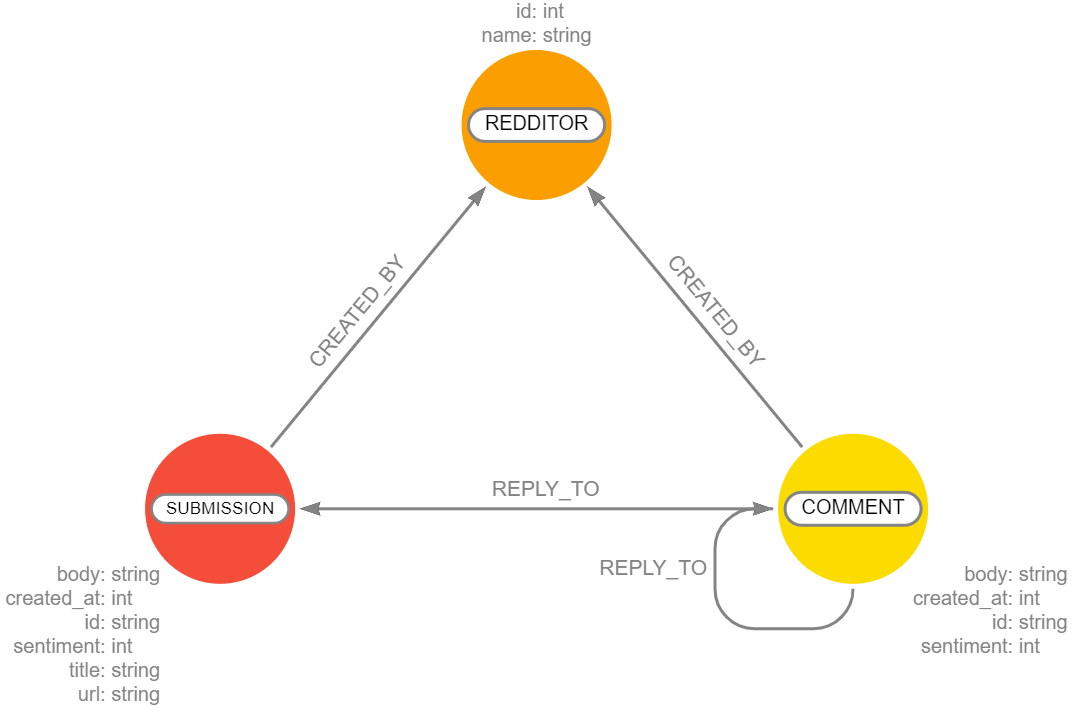
Here's how to understand these relationships:
- A
SUBMISSIONnode isCREATED_BYaREDDITOR - A
COMMENTnode isCREATED_BYaREDDITOR - A
COMMENTcan be: - aREPLY_TOanotherCOMMENTOR - aREPLY_TOaSUBMISSION.
And that's all!
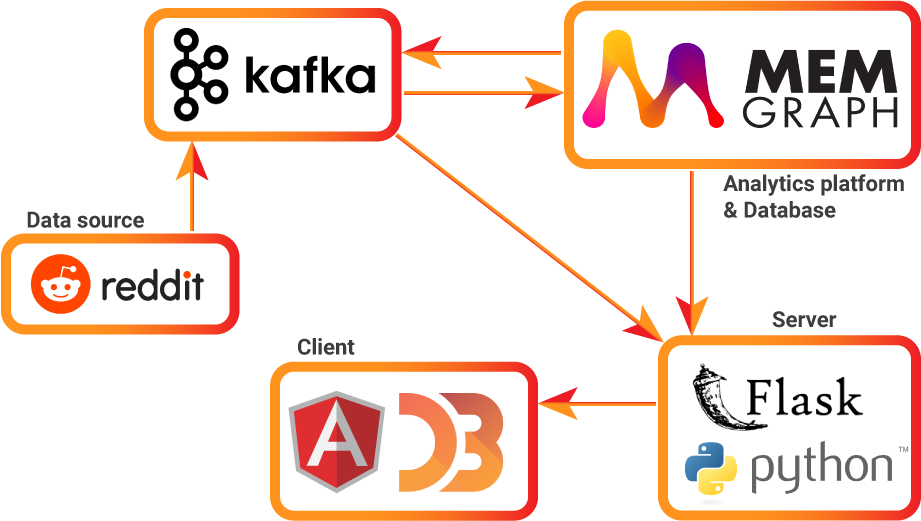
The Full App Architecture
Our app consists of five main services:
reddit-stream: This Python script connects to the Reddit API using the PRAW library, retrieves new posts, and sends them to the Kafka cluster.kafka: A Kafka cluster consisting of four topics. There are two consumers (one is inmemgraphand the other is in thebackend-app) and three producers (inmemgraph,backend-appandreddit-stream).memgraph: The graph analytics platform that stores the incoming Reddit data from Kafka and performs sentiment analysis for each comment and submission.backend-app: A Flask server that consumes the Kafka stream and sends it via WebSocket to thefrontend-app.frontend-app: An Angular app that visualizes the Reddit network with the D3.js library.
Kafka Configuration
The cluster has four topics in total:
comments: When a new comment is posted to the subreddit, thereddit-streamservice sends it to this topic.submissions: When a new submission is posted to the subreddit, thereddit-streamservice sends it to this topic.created_objects: Used for newly created objects in Memgraph. A trigger is activated whenever a newSUBMISSIONorCOMMENTnode is created.node_deleter: We only want to retain Reddit data in Memgraph for a certain amount of time. This topic receives a timestamp that indicates what data to delete.
Processing Incoming Streaming Data
You can create native streams in Memgraph that can be connected to Kafka topics. When messages arrive on these streams, Memgraph allows you to specify functions to call with this data. This allows for the creation of sophisticated transformation methods in incoming data: this is the key to turning streaming data into a live graph.
Here is an example transformation method that receives a Reddit submission from the Kafka topic submissions and creates a
new SUBMISSION node in Memgraph as well as a REDDITOR node if the user
doesn't already exist.
@mgp.transformation
def submissions(messages: mgp.Messages
) -> mgp.Record(query=str, parameters=mgp.Nullable[mgp.Map]):
result_queries = []
for i in range(messages.total_messages()):
message = messages.message_at(i)
submission_info = json.loads(message.payload().decode('utf8'))
result_queries.append(
mgp.Record(
query=("CALL sentiment_analyzer.run($title) YIELD sentiment "
"CREATE (s:SUBMISSION {id: $id, title: $title, body: $body, url: $url, created_at: $created_at, sentiment: sentiment}) "
"MERGE (r:REDDITOR {id: $redditor_id, name: $redditor_name}) "
"CREATE (s)-[:CREATED_BY]->(r)"),
parameters={
"title": submission_info["title"],
"body": submission_info["body"],
"url": submission_info["url"],
"created_at": submission_info["created_at"],
"id": submission_info["id"],
"redditor_id": submission_info["redditor"]["id"],
"redditor_name": submission_info["redditor"]["name"]}))
return result_queriesAnother interesting transformation is the node_deleter() which receives a
timestamp from the Kafka topic node_deleter. The transformation executes a
Cypher query in the database that deletes every submission and comment that has
a created_at property older than the received timestamp. This is what the
query looks like:
...
query=("MATCH (n) "
"WHERE n.created_at < $delete_limit OR degree(n) == 0 "
"DETACH DELETE n"),
parameters={'delete_limit': delete_info['timestamp']}
...Connecting The Backend
The backend server is implemented in Python using Flask. A Kafka consumer regularly checks for new messages and sends them via WebSocket to all connected clients. There is only one scenario where the server queries Memgraph directly. That's because we want to visualize a few submissions and comments right after a user opens our app, we can't wait for them to be posted on the subreddit.
The API Endpoints
The web application contains the following endpoints:
/testGET
This is just a testing endpoint to see if the WebSocket connection is up and running. If you don't see anything in the Angular client (on localhost:4200) then check this endpoint to make sure that messages are actually arriving./api/graphGET
This endpoint returns 10 nodes from Memgraph so they can be visualized. Why is this necessary? Because otherwise, there wouldn't be any rendered nodes in the app when it's started. If the subreddit isn't active, you could be looking at a blank screen for quite some time./connectWEBSOCKET
This is where the client can connect to the WebSocket and receive live updates of new submissions and comments.
Conclusion
The idea behind the hackathon was to see how easy it would be to take off the shelf components and wire them together to create a graph on top of incoming streaming data. It's a testament to the excellent Open Source ecosystem that it was actually quite easy!
If we had more time, we would probably spend time thinking about more advanced algorithms like community detection, calculating the PageRank or betweenness centrality, performing online link prediction, etc. on the data.
If this sounds cool to you, check out the GitHub repo, and let us know what you think in our Discord Community Chat!.