
How to Analyze a Streaming Dataset of Movie Ratings Using Custom Query Modules?
Have you ever wondered what the best-rated movies are? I bet you did many times on those free and rainy weekends. The solution is simple, you can always Google it and quickly get some best-rated movies, but what’s the fun in that? And on top of that, those results may be a few weeks old. One of the reasons we created Awesome Data Stream, a data streams website, is to make things dynamic and real-time. There, you can find all the details about the MovieLens dataset used in this blog post.
Data coming from these streams can be run through Memgraph, which you can set up using the new Memgraph Cloud or by running a local instance of Memgraph DB. The latest version of Memgraph Lab, an application you can use to query and visualize data, has a new feature that guides you through the process of connecting to streams. All the information necessary to connect to a stream is available on the Awesome Data Stream website. If these tools spark your interest, feel free to browse through the Cloud documentation or check out the guide on how to connect to streams using Memgraph Lab. If you are a true movie fan, watch the video tutorial that goes through both of these processes.
This blog will explore the MovieLens streaming dataset to get the best-rated movies and maybe a few of those movies you don’t want to waste your weekend on. It will also showcase the use of the PageRank algorithm to find out what are the most popular movies so you can be prepared for the next social gathering and be on top of your movie-watching game.
Checking the setup
Assuming you are successfully running your Memgraph instance, you’ve connected to it with Memgraph Lab or mgconsole, and the database is ingesting the MovieLens data stream, run the following Cypher query to be sure everything is connected and running smoothly (in Memgraph Lab, switch to Query Execution):
MATCH (u:User)-[r:RATED]-(m:Movie)
RETURN u, r, m LIMIT 100;
If everything is set up correctly, you should see 100 movie ratings, and in Lab you can switch between graph results and data results returned by the query as seen in the image below. Let’s leave Cypher queries a bit and move on to writing a custom query module in Python.
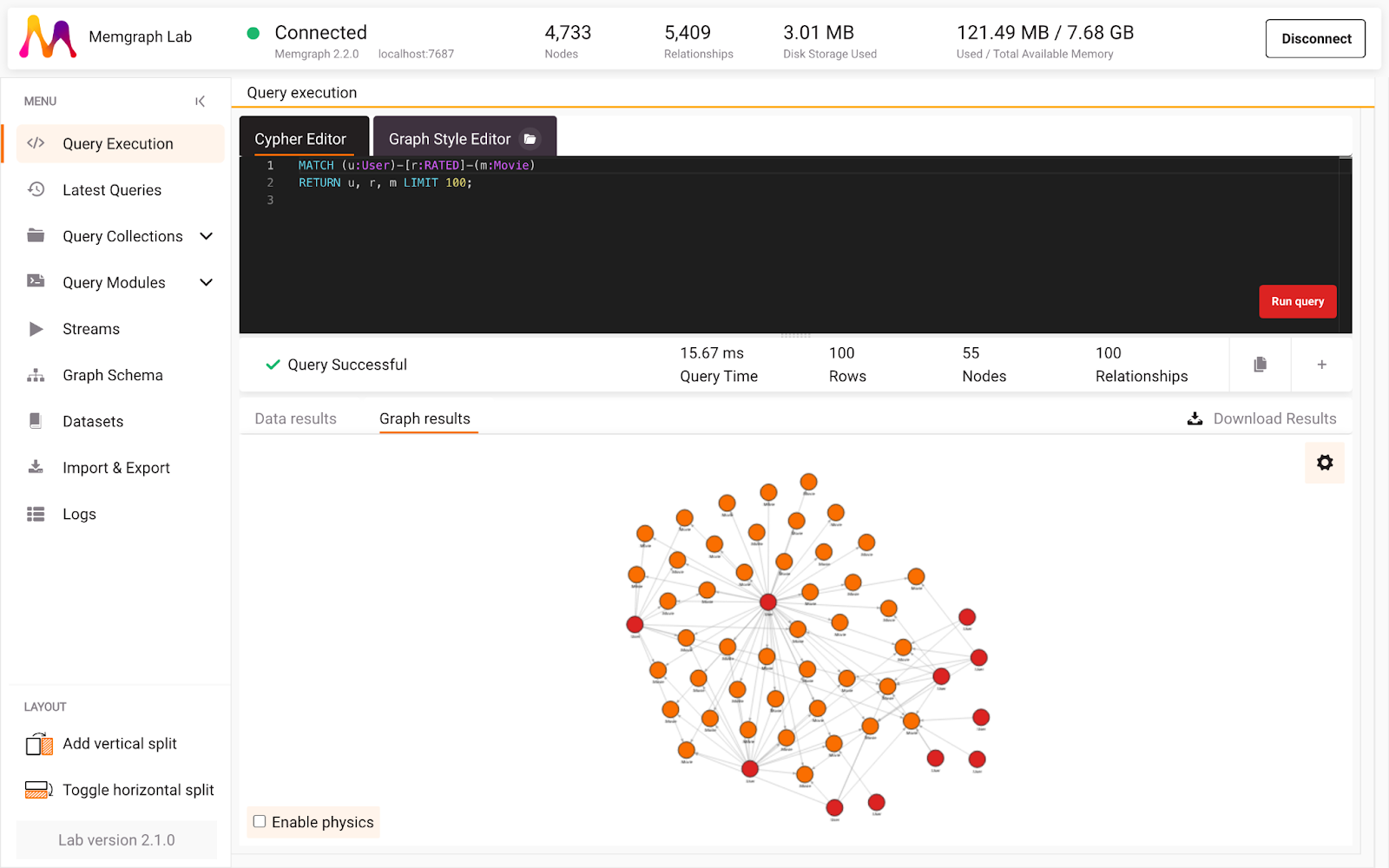
Fresh and Clean Dataset
Custom query modules enable you to write Python code to extend the Cypher query language and explore graphs even more efficiently. The new version of Memgraph Lab supports writing custom query modules directly in Lab. You can also write your query modules locally, so be sure to check Memgraph’s reference guide on query modules for any questions left unanswered by this blog.
In Memgraph Lab, select Query Modules in the left side menu, create + New module give it a name, such as movielens_demo:
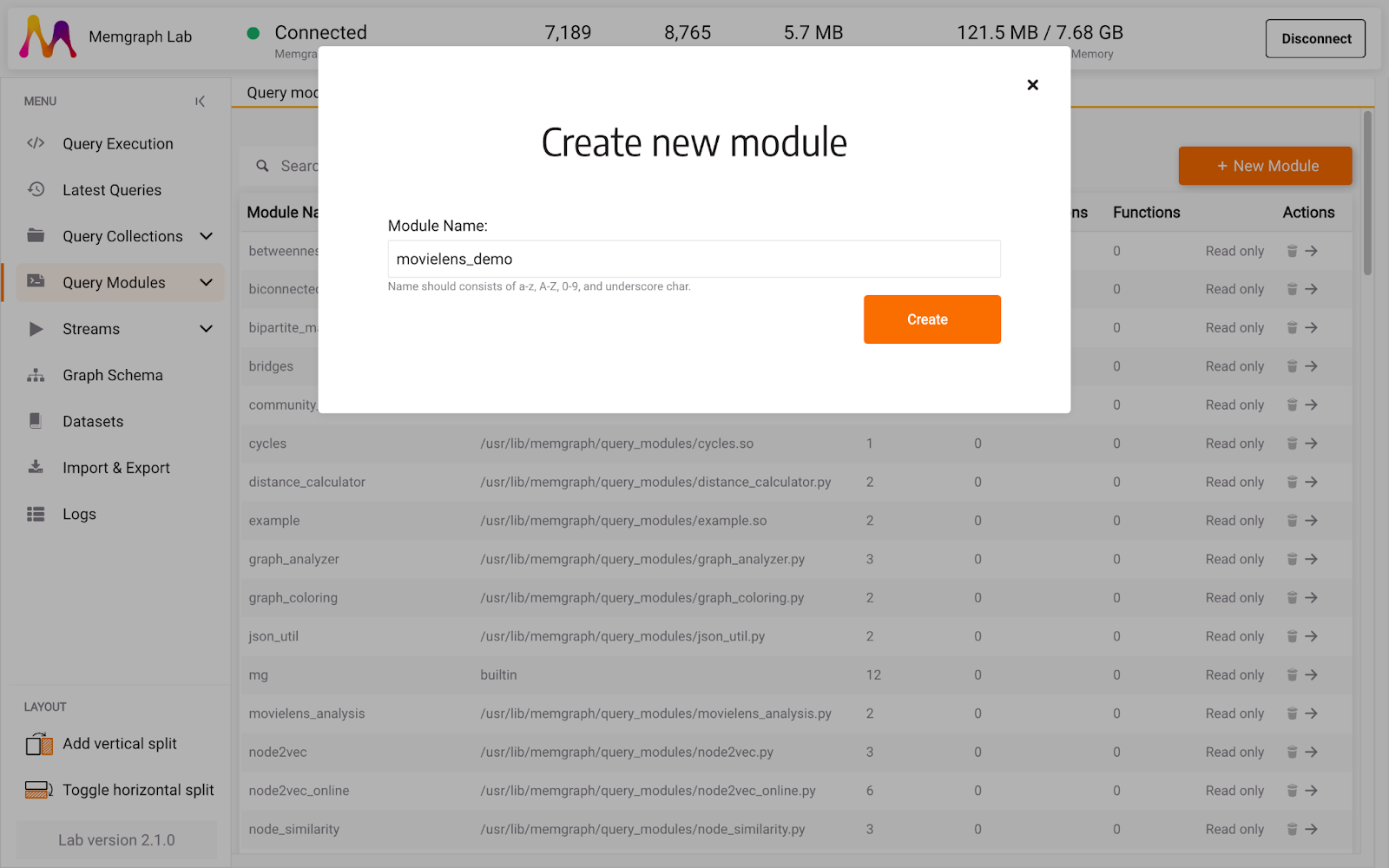
After creating a new query module, a query module editing section will open. You can notice that by default, there is some sample Python code written there. Most of the code is helpful comments and links to guides. Feel free to explore everything, but let’s start with a clean slate in this blog.
As you can see on Awesome Data Stream website, Movielens graph data model is quite simple. There are User, Movie and Genre nodes. Users are rating Movies and there is a RATED relationship between the User and the Movie node. There is also OF_GENRE relationship between the Movie and the Genre node.
To find the best-rated movie, you have to get all movie ratings and calculate the average rating score of every movie in the dataset. After each movie has a rating, the best 5, 10, or 15 movies are easily extracted. It really depends on how much time you have over the weekend.
The issue here is that the dataset is constantly changing because data is streamed in real-time. That’s why the movie average rating score has to be updated with every new streamed rating.
This can be achieved by writing a custom query module in Python:
import mgp
@mgp.write_proc
def new_rating(
context: mgp.ProcCtx,
rating: mgp.Edge
) -> mgp.Record(Rating = mgp.Nullable[mgp.Edge],
Movie = mgp.Nullable[mgp.Vertex]):
if rating.type.name == "RATED":
movie = rating.to_vertex
movie_rating = rating.properties.get("rating")
rating_sum = movie.properties.get("rating_sum")
if rating_sum == None:
movie.properties.set("rating_sum", movie_rating)
movie.properties.set("num_of_ratings", 1)
else:
current_rating = rating_sum + movie_rating
movie.properties.set("rating_sum", current_rating)
movie.properties.set("num_of_ratings", movie.properties.get("num_of_ratings") + 1)
return mgp.Record(Rating=rating, Movie=movie)
return mgp.Record(Rating=None, Movie=None)
This query module takes user input rating scores and updates Movie nodes with properties num_of_ratings that define how many users have rated the movie and rating_sum, the total sum of ratings. To calculate the average movie score the total sum of ratings must be divided by the number of ratings.
To make sure this query is executed at the moment a new rating comes from the data stream, a trigger needs to be set up:
CREATE TRIGGER newMovieRating
ON CREATE BEFORE COMMIT EXECUTE
UNWIND createdEdges AS e
CALL movielens_demo.new_rating(e) YIELD *;
Now, as soon as a new edge is created, the custom query procedure will be triggered and it will update the Movie nodes.
Generally speaking, it is good practice to set up database triggers before data is loaded because triggers should be executed consistently on all data coming from the stream. This will ensure that data inside the database is consistent. To do so, just stop the stream, clean the database, prepare triggers, and start the stream again. But at the moment, we are having fun, so it isn’t necessary to do it.
Now that the dataset is updated in real-time, there are some cool insights you can uncover.
What to watch over the weekend?
When analyzing a movie dataset, the most obvious thing is to get the best-rated movies and check what to watch. Let’s add a query procedure that will do just that:
@mgp.read_proc
def best_rated_movies(
context: mgp.ProcCtx,
number_of_movies: int,
ratings_treshold: int
) -> mgp.Record(best_rated_movies = list):
q = PriorityQueue(maxsize=number_of_movies)
for movie in context.graph.vertices:
label, = movie.labels
if label.name == "Movie":
num_of_ratings = movie.properties.get("num_of_ratings")
title = movie.properties.get("title")
if num_of_ratings != None and num_of_ratings >= ratings_treshold:
rating = movie.properties.get("rating_sum")/num_of_ratings
if q.empty() or not q.full():
q.put((rating, title))
else:
top = q.get()
if top[0] > rating:
q.put(top)
else:
q.put((rating, title))
movies = list()
while not q.empty():
movies.append(q.get())
movies.reverse()
return mgp.Record(best_rated_movies=movies)
The query above will return the number of movies we passed to the function. Movies will be ordered by their average rating score from the best to the worst-rated one. For the movie to qualify as being the best-rated one, it must have more ratings than the given threshold. Movies with fewer ratings are not considered good candidates because movies could have a single rating with a score of 5 and be the best-rated movie ever.
So, what are the best-rated movies at the moment? You can get a list of movie titles and their average rating with the query below that returns the best ten movies with at least 20 ratings.
CALL movielens_demo.best_rated_movies(10, 20)
YIELD best_rated_movies
UNWIND best_rated_movies AS Movie
WITH Movie[0] AS Rating, Movie[1] as Title
RETURN Rating, Title
Here are the best rated movies so far and your weekend watching list:
| Rating | Title |
|---|---|
| 4.590909090909091 | Star Wars: Episode IV - A New Hope (1977) |
| 4.316666666666666 | Silence of the Lambs, The (1991) |
| 4.285714285714286 | Star Wars: Episode V - The Empire Strikes Back (1980) |
| 4.285714285714286 | Shawshank Redemption, The (1994) |
| 4.260869565217392 | Indiana Jones and the Raiders of the Lost Ark (1981) |
| 4.26 | Usual Suspects, The (1995) |
| 4.214285714285714 | Forrest Gump (1994) |
| 4.204545454545454 | Schindler's List (1993) |
| 4.173913043478261 | Fugitive, The (1993) |
| 4.159090909090909 | Aladdin (1992) |
This is an excellent list of movies and be sure to watch them if you haven’t already.
What not to watch over the weekend!
But let's move to the worst-rated movies and see what to avoid by updating the query module to get the worst-rated movies. You can reuse the query module for best-rated movies by copying it and pasting it below itself.
In the copy, start by changing the function name, return the parameter name and invert the rating value by multiplying it with -1 and viola. The priority queue will first remove better-scored movies because their values are lower. It is a small hack of Python PriorityQueue because it does not support max heap. If you want, you can turn the rating back to positive values.
@mgp.read_proc
def worst_rated_movies(
context: mgp.ProcCtx,
number_of_movies: int,
ratings_treshold: int
) -> mgp.Record(worst_rated_movies = list):
q = PriorityQueue(maxsize=number_of_movies)
for movie in context.graph.vertices:
label, = movie.labels
if label.name == "Movie":
num_of_ratings = movie.properties.get("num_of_ratings")
title = movie.properties.get("title")
if num_of_ratings != None and num_of_ratings >= ratings_treshold:
rating = movie.properties.get("rating_sum")/num_of_ratings
rating = rating * -1
if q.empty() or not q.full():
q.put((rating, title))
else:
top = q.get()
if top[0] > rating:
q.put(top)
else:
q.put((rating, title))
movies = list()
while not q.empty():
rating, title = q.get()
rating = abs(rating)
movies.append((rating, title))
movies.reverse()
return mgp.Record(worst_rated_movies=movies)
To call this query module, execute the following Cypher query:
CALL movielens_demo.worst_rated_movies(5, 8)
YIELD worst_rated_movies
UNWIND worst_rated_movies AS Movie
WITH Movie[0] AS Rating, Movie[1] as Title
RETURN Rating, Title
You should get a list of five movies that have eight or more ratings and they are the lowest. List of movies you should probably avoid:
| Rating | Title |
|---|---|
| 2.4444444444444446 | Ace Ventura: When Nature Calls (1995) |
| 2.625 | Judge Dredd (1995) |
| 2.6923076923076925 | Waterworld (1995) |
| 2.7 | Coneheads (1993) |
| 2.7142857142857144 | Mars Attacks! (1996) |
Let’s hope these movies are better than their ratings.
What most people watch over the weekend
Let’s take one more look at our dataset, but this time we will not focus on best or worst ratings. This time we will see what movies are the most popular by running the PageRank algorithm. The good thing is that PageRank is a part of MAGE, and if you are using Memgraph Cloud or Memgraph Platform, MAGE is already locked and loaded, and you don’t have to read or write a single line of code.
PageRank algorithm will return the importance of nodes in the dataset, or what nodes are often rated and the results do not correlate with the rating. Speaking in simpler terms, results contain the worst, average and best movies, which are ordered by popularity. There are also Genre nodes in the dataset, but they are filtered out in the query below. So, let’s see what are the most popular movies:
CALL pagerank.get()
YIELD *
WITH node, rank
WHERE node:Movie
RETURN node.title, rank
ORDER BY rank DESC
LIMIT 10
| Title | PageRank |
|---|---|
| Shawshank Redemption, The (1994) | 0.00010613417060062985 |
| Forrest Gump (1994) | 0.00009782825801569162 |
| Pulp Fiction (1994) | 0.00009487459163194607 |
| Silence of the Lambs, The (1991) | 0.00009484212555242494 |
| Batman (1989) | 0.00009455284227422577 |
| Apollo 13 (1995) | 0.00009338906081147127 |
| Usual Suspects, The (1995) | 0.00009251068351150643 |
| Braveheart (1995) | 0.0000920189534468074 |
| Schindler's List (1993) | 0.0000911798782181896 |
| Fugitive, The (1993) | 0.00009112653832655362 |
Conclusion
As you can see, in the end, there is a reason why some movies are consider evergreen masterpieces as they are beloved and popular among most.
This blog post showed you how to write query modules using Python API, set up a trigger for dynamic dataset updates, and use MAGE query modules. If at one point running the algorithm on your streaming dataset starts taking up too much time you are ready to step up your graph game with a dynamic PageRank algorithm available in MAGE, written specifically for streaming data because it doesn’t recompute the rank for each node, but only for those affected by the changes. Feel free to try it out. If you have any problems or want to discuss something related to this article, drop us a message on our Discord server.
If you have any issues or want to discuss something related to this article, drop us a message on our Discord server. If movies are not your cup of tea and you are more of a bookworm, check out another tutorial on how to get real-time book recommendations based on the Amazon book dataset.