
How to Identify Essential Proteins Using Betweenness Centrality
The identification of essential proteins has become an important field of research in recent years. The correlation between essential proteins and disease genes has become crucial for disease diagnosis and treatment. Traditional biological experiments are often too expensive and time-consuming, which means that computational methods are becoming more crucial.
In this tutorial, we will utilize betweenness centrality for identifying essential proteins. For this task, we are using Memgraph, a graph analytics platform, which can perform complex graph analysis on all sorts of networks. Even though we will use betweenness centrality, other graph algorithms can also be applied to the protein-protein interaction network, such as other centrality measures or the PageRank algorithm.
We also created a simple web application that can help you visualize the network. Visit the GitHub repository to find out more.
Prerequisites
For this tutorial, you will need:
- a running Memgraph instance;
- the Memgraph Lab visual user interface.
The easiest way of installing both is to download the Memgraph Platform Docker image. Just install Docker and execute the following command to get everything up and running:
docker run -it -p 7687:7687 -p 3000:3000 memgraph/memgraph-platform
The command will search for the Memgraph Platform image locally, and if it can't be found, Docker will download it for you.
After the download finishes and Memgraph has been started, you can open Memgraph Lab in your browser at the address https://localhost:3000.
1. Building the Graph Data Model
The data we will use in this tutorial was created based on a Tissue-specific protein-protein interaction network [1]. This dataset contains specific protein-protein interaction networks for various human tissues.
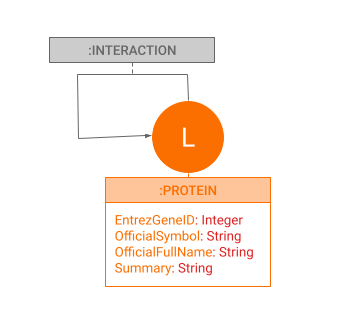
The nodes in the graph are all labeled PROTEIN and represent proteins found in human tissues. Entrez Gene is the gene-specific database at the National Center for Biotechnology Information (NCBI), and Entrez Gene ID is a unique identifier for a gene representing protein-specific instructions.
For this tutorial, we have expanded the existing data set with additional information scraped from NCBI so you can easily explore the protein networks. Each node has the properties:
- EntrezGeneID
- OfficialSymbol
- OfficialFullName
- Summary
Edges of the type INTERACTION represent tissue-specific physical interactions between proteins, and they don't include any properties.
2. Importing the Protein Network
Two files are available for each tissue, one containing descriptions of the protein in the selected tissue, the other listing all protein interactions. You can download the tissue-specific data used in this tutorial from here.
After you download and extract the CSV files, we need to copy them to the Docker container where Memgraph can access them.
1. First, find the Memgraph Platform CONTAINER_ID by running:
docker ps
2. Now, you can copy the files to the container with the docker cp command:
docker cp interactions_cochlea.csv CONTAINER_ID:/
docker cp interactions_cochlea_properties.csv.csv CONTAINER_ID:/
Don't forget to replace
CONTAINER_IDwith the actual id from the previous step.
3. The LOAD CSV clause enables you to load and use data from a CSV file of your choosing within a query. First, we are going to import the nodes. Run the following query in Memgraph Lab or mgconsole:
LOAD CSV FROM "/interactions_cochlea_properties.csv"
WITH HEADER DELIMITER "|" AS row
CREATE (n:PROTEIN
{EntrezGeneID: ToInteger(row.EntrezGeneID),
OfficialSymbol: row.OfficialSymbol,
OfficialFullName: row.OfficialFullName,
Summary: row.Summary}
);4. Now, we are going to create a database index to import the edges more efficiently:
CREATE INDEX ON :PROTEIN(EntrezGeneID);5. Finally, we can create the edges:
LOAD CSV FROM "/interactions_cochlea.csv"
WITH HEADER DELIMITER "|" AS row
MATCH (a:PROTEIN {EntrezGeneID: toInteger(row.EntrezGeneID1)}),
(b:PROTEIN {EntrezGeneID: toInteger(row.EntrezGeneID2)})
CREATE (a)-[e:INTERACTION]->(b);3. Identifying Essential Proteins with Betweenness Centrality
MAGE Graph Library
Memgraph Advanced Graph Extensions, or for short, MAGE, is an open-source graph library that contains implementations of standard and incremental graph algorithms. You can use any of the algorithms as well as implement your own.
Betweenness centrality is included in MAGE, and the algorithm implementation is inspired by the Brandes algorithm.
Calculating the Betweenness Centrality of each Protein
1. We are going to create a Cypher query that will call the betweenness centrality algorithm for each node and store the results in the property BetweennessCentrality:
CALL betweenness_centrality.get(FALSE, TRUE)
YIELD node, betweenness_centrality
SET node.BetweennessCentrality = toFloat(betweenness_centrality);2. After we calculate the betweenness centrality for each node, we can sort them according to this value. The most important proteins in the tissue will have the highest centrality measure:
MATCH (node:PROTEIN)
RETURN node
ORDER BY node.BetweennessCentrality DESC;If you are running the query in Memgraph Lab, the results should be similar to the ones below:
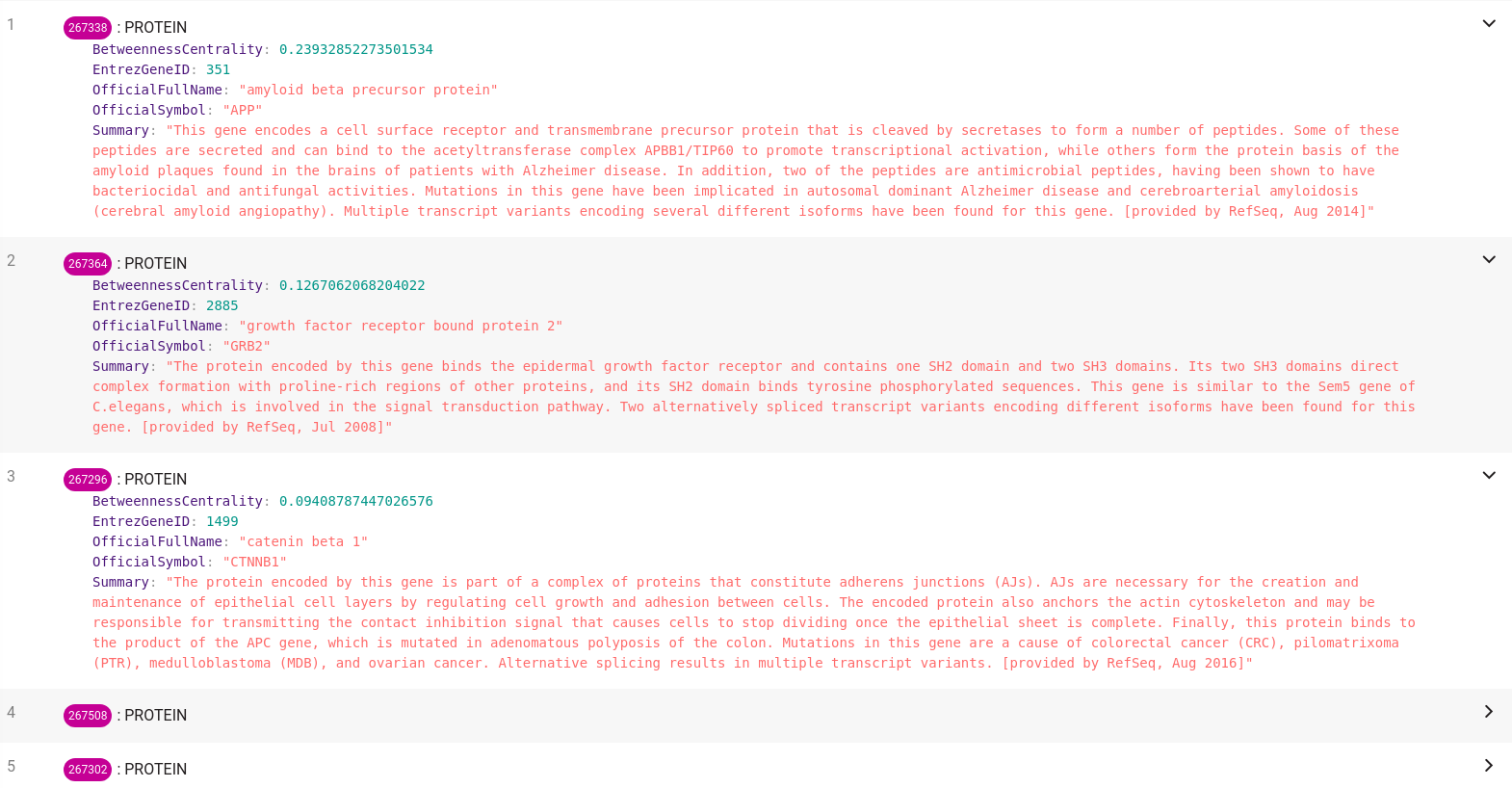
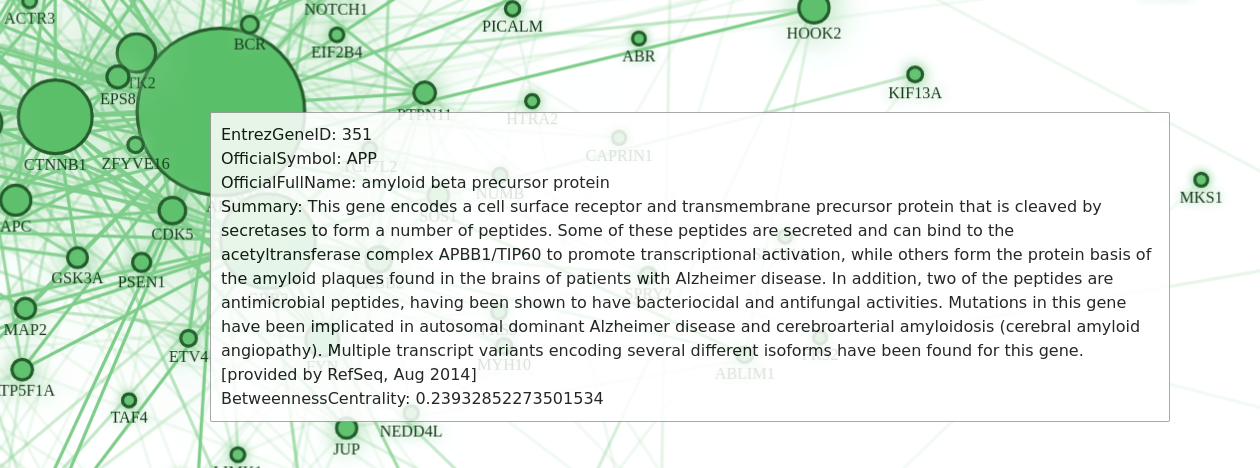
The results are pretty clear, the essential protein with the highest betweenness centrality in the Cochlea tissue is APP. There is a correlation between the APP protein and Alzheimer's disease, which could be interpreted as a connection between essential proteins and diseases in general. While this is a pretty big simplification, it's still an interesting network analysis experiment.
Conclusion
Because protein-protein interaction networks are very complex and highly connected structures, techniques from the field of graph theory are a perfect fit for the analysis and identification of essential proteins. Technology breakthroughs have made it much easier to utilize such methods rather than to perform resource-intensive experiments. While this tutorial post focused on a general betweenness centrality measure, it's also possible to use other algorithms such as PageRank.
We have also created a simple web application that can visualize these protein-protein interaction networks. Just follow the simple installation instructions, and you should end up with a simple yet powerful tool for analyzing protein interactions in human tissues.
References: [1]: Marinka Zitnik, & Jure Leskovec. (2018). BioSNAP Datasets: Stanford Biomedical Network Dataset Collection. http://snap.stanford.edu/biodata.