
Announcing Memgraph 1.0!
Already used by everyone from solo developers to Fortune 500 enterprises, Memgraph 1.0 is now publicly available and production-ready. We’ve come a long way since writing the first line of code in summer 2016 and we’re proud to bring you what we believe to be a graph database that will make it easy for developers and data scientists to build and productionize high-performance graph applications.
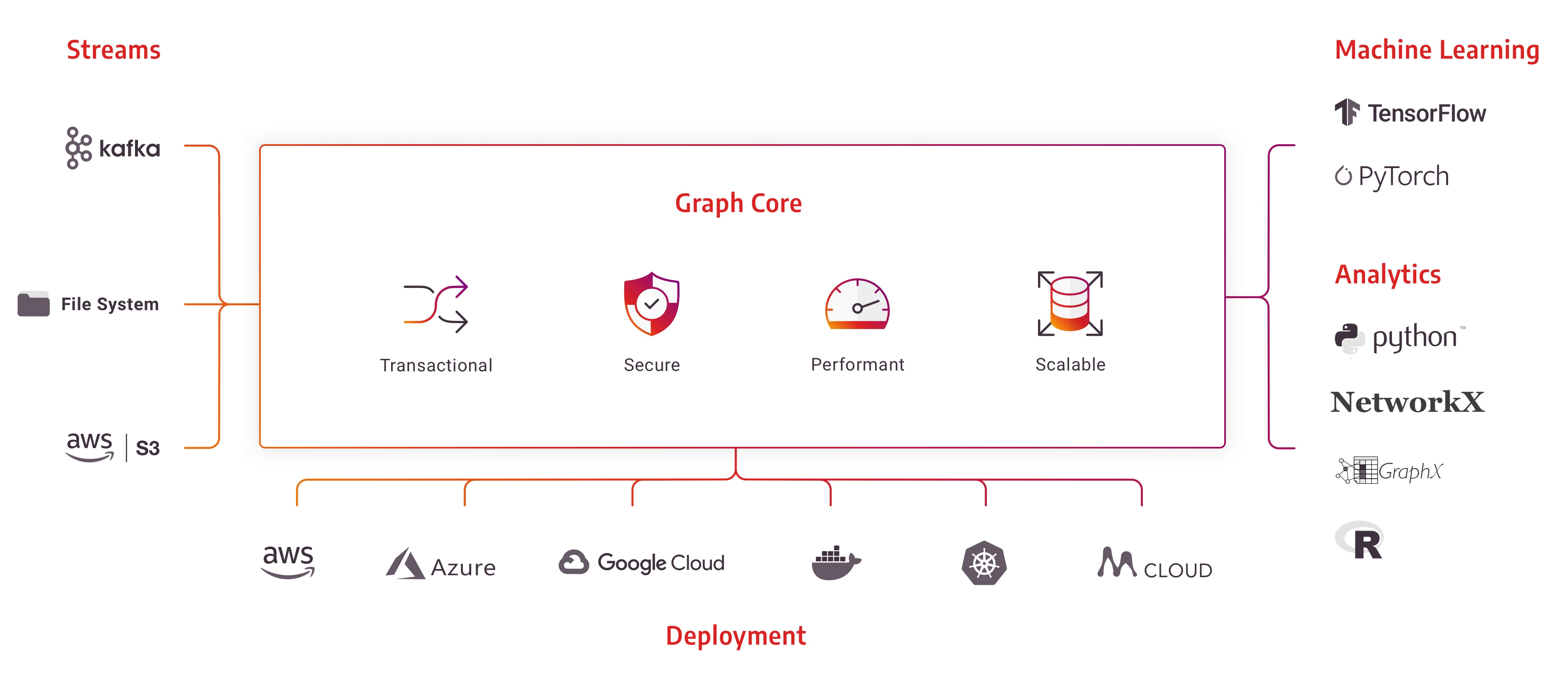
A Brief Introduction to Memgraph
We started this journey with the belief that there was a need for a graph database that could deliver three critical capabilities:
- Predictable high-performance on both simple graph traversals (typically transactional operations) and advanced graph algorithms (typically analytical operations) within a single system.
- An integrated ecosystem that would allow data scientists to easily leverage existing data science and machine learning tools to build graph-powered applications with minimum friction.
- Broad compatibility with existing and future software development tools and languages to help developers build, deploy, and maintain their applications without hassle.
With this in mind, we build Memgraph. A high-performance, Cypher compatible graph database management system purposely engineered with the unique capability of supporting both transactional and analytical workloads. Built from the ground-up leveraging an in-memory first, durable, and redundant architecture, and a C/C++ implementation, Memgraph delivers low latency, high-throughput and maximum concurrency on industry-standard hardware.
Query Language
Memgraph supports the Cypher query language through the openCypher project and is one of its major contributors and supporters. We have extended it to feature algorithms such as Breadth-First Search and Weighted Shortest Path.
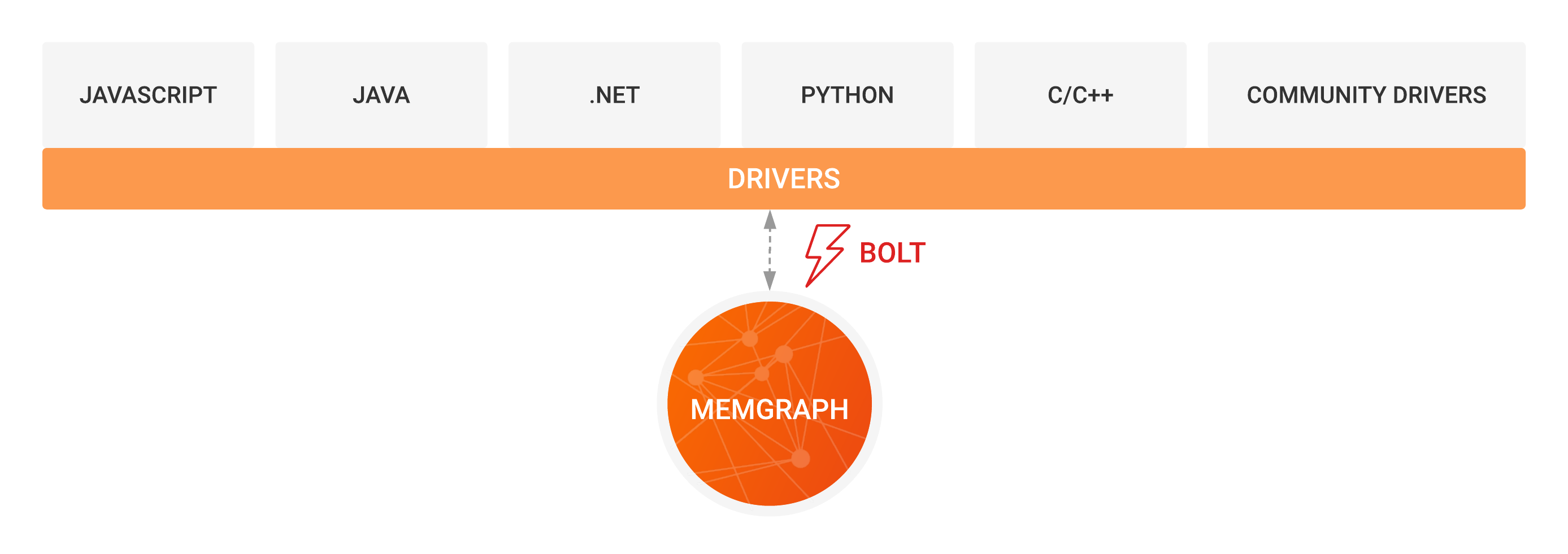
Neo4j Compatibility
Memgraph is wire compatible with Neo4j through the Bolt protocol and thus benefits from current and future compatibility with existing graph applications, tools and client libraries developed for major programming languages. Furthermore, Memgraph also offers a high-performance C/C++ Bolt client for when you want to squeeze every bit of performance.
Storage and Concurrency
Memgraph offers full support for ACID transaction semantics and achieves high throughput by using highly concurrent, and sometimes even lock-free, data structures and multi-version concurrency control (MVCC). As a result, writes never block reads and vice versa. Traditional databases manage concurrency with global locks, which results in some processes blocking others until they complete and release the lock. Memgraph’s implementation of MVCC provides a snapshot isolation level which offers better performance than serializability, and avoids most concurrency anomalies.
Additionally, Memgraph uses a highly concurrent skip list for indexing purposes. Skip lists represent an efficient technique for searching and manipulating data, delivering concurrency and performance benefits over other graph databases and disk-based databases, which use B-Trees to store every index.
Durability and High-Availability
Memgraph provides durability guarantees. A combination of periodic snapshotting and write-ahead logging (WAL), both synchronous (fsync before every commit) and asynchronous (periodic fsync) which ensures that data won’t be lost in the event of an underlying system failure.
Prior to version 1.0, Memgraph leveraged the RAFT consensus protocol to deliver high-available replication which worked great but had a few drawbacks on the performance side. Based on feedback from our users and clients, we have decided to switch supporting HA through streaming replication (similar to PostgreSQL) and automatic failover to ensure your application is always available while maintaining good performance. [Note: we’ll be releasing a detailed blog post describing how and why we picked this option]
Memgraph Lab
To help you visualize your graph data and optimize your queries, we have built Memgraph Lab, a lightweight and intuitive visual user interface for developers
With Memgraph Lab you can:
- Import your data.
- Visualize and explore your graph
- Profile and tune your queries for faster performance
- Visualize and optimize your graph schema.
You can read more about Memgraph Lab here and download it for free here.
Memgraph 1.0 Key Features
Our engineering team has been hard at work for the past three years to ensure that Memgraph maintains the highest standards in terms of performance, reliability, and ease of use. With a great deal of feedback from our users and clients, Memgraph 1.0 comes with the following key features:
- Optimized storage engine and reduced memory footprint – We overhauled our storage engine and rewritten it from scratch which resulted in a 1.4x to 14x reduction in RAM usage and an average 2x - 3x speedup for read and write queries. [Note: we will be releasing detailed benchmarks. Stay tuned!]
- Python Query Module – Users can now write imperative procedures and extend the existing feature set. The most performant way to implement procedures remains the Memgraph C Query Module API. However, for faster development and iterations we have released a Python Query Module API. By embedding a Python interpreter within the Memgraph process, data scientists can easily leverage libraries like NetworkX to analyze the data stored inside Memgraph.
- CSV import tool – If you are already familiar with the Neo4j import tools, then using the Memgraph import tool should be easy. The CSV import tool is fully compatible with the Neo4j CSV format. If you already have a pipeline set-up for Neo4j, you should be able to easily import data by using “mg_import_csv”.
- Tensorflow integration (Beta) – In another effort to make life easier for data scientists and machine learning developers, we have developed Memgraph to enable easier development and production serving of your machine learning models based on graph data by allowing you to query Memgraph directly from TensorFlow. The TensorFlow op wraps the high-performance Memgraph client for use with TensorFlow, allowing natural data transfer between Memgraph and TensorFlow.
Commercial Offerings: Memgraph Cloud and Memgraph Enterprise
You can download the Memgraph’s community version for free here. However, if you don’t want to manage your deployment or are looking for something to run in production on-prem, Memgraph Enterprise and Memgraph Cloud offer the additional features you need.
Memgraph Enterprise
Working at an enterprise-scale in production means that you have to ensure no downtime and robust security. This is why Memgraph Enterprise comes with high-availability replication and all the necessary security features including:
- Advanced password policies for users using basic authentication.
- Native authentication as well as support for LDAP, and Active Directory.
- Role-based access control for regular and privileged access to data.
- Data encryption in transit via TLS.
- Activity auditing.
Memgraph Cloud
We understand that not everyone is excited about running and managing their own database deployment. Sometimes, you just want to focus on developing your application and not worry about anything else. We are happy to announce that Memgraph Cloud is now generally available and offers a fully-managed, cloud-hosted graph database-as-a-service supported by the engineering team behind Memgraph. Memgraph Cloud comes with most production features available in Memgraph Enterprise and we’re in the process of adding the missing ones in the next few months.
You can compare our commercial offerings here and shoot us a message if you need any help.
We’re Just Getting Started
This 1.0 release is only the beginning for Memgraph, and we’re committed to bringing you a powerful, easy-to-use, and reliable graph database by continuing to expand our capabilities and keep you way ahead of the curve.
In the meantime, you can get started for free with Memgraph by downloading our community edition or try Memgraph Cloud. You can find our documentation here and if you have any questions or need any help you can post on our Discord server.
Although we run 24h continuous testing and take extreme care to test Memgraph in different environments, using different workloads and various simulated failure events, we are aware that there will always be expected and unexpected issues. This is why we would love to get your feedback and are committed to investing significant resources in making Memgraph more robust, performant, and user-friendly.