
4 Reasons Why Graph Tech Is Great for Knowledge Graphs
Over time companies have acquired a large amount of data by logging every single change and observation and storing it in data lakes and data warehouses. All this data is gathered with the idea of helping the company move in the right direction.
But making the gathered data useful is not an easy job because it’s too diverse, dispersed, and stored at different volumes. Just imagine how many business insights and opportunities were lost by companies failing to make sense of this complex mess of meaningless, siloed data and content.
But if a layer of semantic metadata is created on top of interconnected data, the enterprise gains a uniform and consistent view of the context of its data. The knowledge that was once scattered across different systems and stakeholders is now interlinked in a knowledge graph.
So companies are learning that it is not only enough to gather and store data, it’s equally important to have an adequate system capable of driving decisions in the right direction. Such a system should be able to connect data points, understand how the whole business system is connected, and, more importantly, reach conclusions. And graph databases are most likely the only technology capable of organizing dispersed and unconnected data to create new knowledge.
It is possible to connect data in other databases and systems, i.e., relational databases can join data using keys, but they soon become inadequate when facing demands such as uncovering new insights, the causality of data, and drawing predictions, mainly due to performance issues regarding real-time data manipulation and updates.
Being able to connect data means little if the new information is provided when it’s no longer relevant. Graph databases can explore connections and infer new ones in real-time and dynamically without the struggle of joining multiple tables and calculating valuable results for hours.
For that reason, graph databases are a great technology not only for connecting data but for modifying and analyzing it efficiently.
Performance is also hidden in graph databases
As mentioned, relational databases can be used to find connections between data, but due to their performance, a company is bound to benefit more from a graph database. This is evident in an example, such as exploring how one change in data impacts the rest of the business. In a relational database, the impact is stored within a table, storing dependencies in a row like this:
| Changed | Impact |
|---|---|
| A | B |
Depending on how deep dependencies need to be explored, multiple tables need to be joined.
If there is one table storing dependencies (D) the cost of doing nested JOIN operation would be O(|D| ** 2), where |D| is the cardinality of dependencies only for the first layer of dependencies. With graph databases, going through dependencies doesn’t require any table joining since dependencies between items are already present in the graph in the form of relationships. Complexity with graph databases is O(1). Once a node is found, the dependency is also easy to track in constant time.
Test it yourself - try to find out if changes to the C entity will affect the L entity using the dependency table and then the graph. The relational database system will struggle just the same as you do.
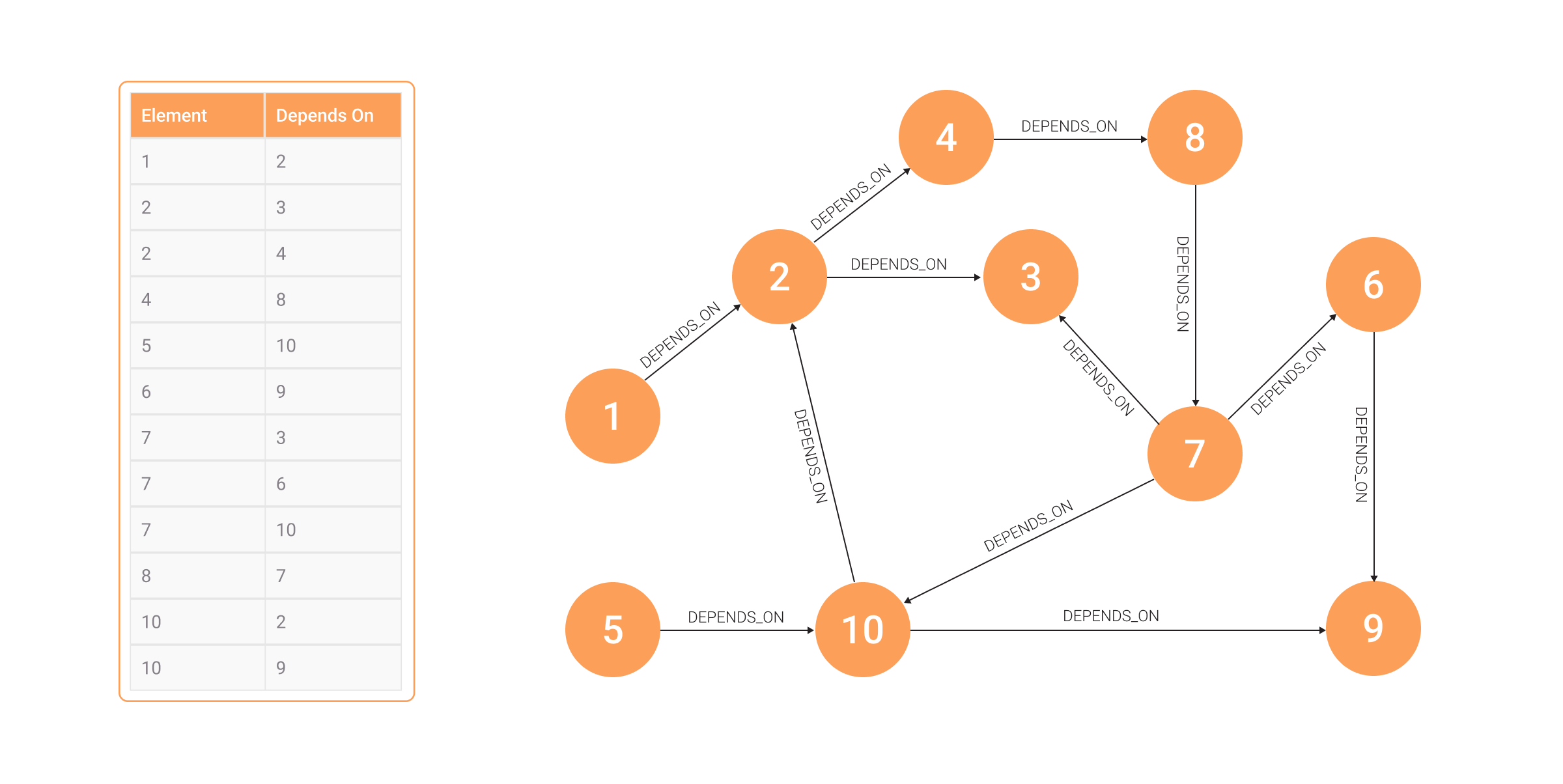
This kind of dependency is exactly what car manufacturers have to be aware of and do an analysis of. How will a missing car part impact the overall business? When you need a lot of parts to assemble a product (somewhere around 30 0000 pieces in one car), supply chain challenges, like the one during the COVID-19 pandemic, can seriously affect your business.
If a part of the combustion engine or battery is unavailable from a usual supplier, there might be another supplier or manufacturer that could deliver it.
This problem might be solvable with a CSV file, Google and a phone to call another supplier, But what if the new supplier doesn’t have a 100% identical part, and installing a slightly different part impacts 15 other parts, which impact 100 others? That part is hard and slow to do with just a paper and a relational database. If you are in a meeting and exploring certain options, you probably don’t have 3-5 business days for the relational database to deliver optimal solutions. But when you use graph databases, resolving such dependencies is smooth sailing. And on top of this performant tool, knowledge graphs bring an additional layer of semantic meaning that enables software to be aware of the many data stitched together and provide new conclusions and infer new knowledge.
To conclude, graph databases not only provide new insights, but they also do it quickly and effortlessly. The use of knowledge graphs with graph databases offers several benefits, including the ability to explore data easily using index-free adjacency, the ability to adapt to changing models, improved scalability, and the ability to use dynamic algorithms. These advantages will be discussed in more detail in the following chapters.
1. Data exploration
Data exploration is the main part of gaining new knowledge. One form of data exploration is exploring dependencies by finding certain patterns in the data or the most dependent nodes. Both findings can be made by using Memgraph Platform ecosystem. Patterns are found by pattern-matching queries, while dependents are found with centrality measures and other similar algorithms, such as betweenness centrality.
Here is an example of a pattern trying to find dependencies:
MATCH (m:Part)-[:DEPENDS_ON *]->(n:Part {name:”chip”})
RETURN m;
Traversing from one node to another is the most important ability of the graph database and concept, which enables running both pattern-matching queries and graph analytics algorithms. Traversing is possible due to index-free adjacency implemented in the database core, which allows the fast exploration of relationships between nodes. In Memgraph, all nodes and relationships are located directly in RAM, so the action actually boils down to direct hops in memory, called pointer hopping.
By performing pointer hopping, a direct walk of memory, graph databases look up adjacent nodes in a graph. This is the fastest way for computers to look at relationships. Let’s consider the dependency graph from the car manufacturers' example. It certainly has a combustion engine node. The graph database holds direct physical RAM addresses of all the other neighboring nodes in the graph, in this case, the address to the parts on which the combustion engine depends, like rotors, turbine blades, and the nodes that depend on the combustion engine as well (which is probably the whole graph).
Memgraph, amps this feature by being completely in memory. This means that no time is lost by moving all data from disk to RAM, and the data exploration is done instantly.
In comparison, the primary design goal of relational databases is fast row-by-row access, the remainder of the COBOL times, a system that read data one card at a time and was designed to group all the fields in rows. Relational databases ended up inheriting the COBOL flat-file designs and retrofitted relationship lookups later, as an afterthought. The original design was not intended to infer new knowledge and find patterns between data relationship points.
Worse than that, each relational JOIN operation is a search that takes twice as long as the database doubles in size, meaning it results in O(log(n)) binary search operation. The more JOINs there are, the slower the search is. Relational databases excel at queries on small datasets with a uniform flat structure.
So graph databases are faster, but how fast are they? Expect a computer to hop between roughly a million nodes every second for each core it has on the server. If the server has 16 cores, the number rises to 16 million hops per second. For those with an NSA-scale budget, Cray Graph Engine with 8,192 cores is available that can do 12.8 billion (Giga) Traversal Edges Per Second (GTEPS) on the graph500 SSSP benchmarks.
2. Model adaptability
When a data model is inconsistent and demands frequent changes, using a graph database is certainly the way to go. Graph databases are more focused on the data itself rather than the schema structure, so they allow a degree of flexibility.
Moreover, a graph database is excellent for handling:
- additional attributes that will be added at a certain time in the future
- entities that don’t share the same attributes and
- flexible attribute types.
And knowledge graphs change often. Companies can start logging new data or integrate different sources. It doesn’t make sense to start from scratch if melding a different data silo is impossible because the new source doesn’t completely fit in the current schema. Graph databases can easily adapt to these changes.
If a company starts employing NLP to go through customer reviews, the NLP will produce entity recognition or metadata, important for inferring knowledge later on. This new metadata can be a property that only some nodes have. For example, data about how many times was in-ear mentioned in the description of headphones. This data can later help decide product properties. In both cases, the graph database schema is adaptable, meaning you can always add something new to the nodes or edges of the graph (new metadata), and furthermore, you can connect new information in terms of completely new nodes and relationship types without changing the whole schema.
Any new metadata causes havoc in relational databases. Due to their schema-based approach, a specific standard data structure and format for every data point in each table was created before any data was even saved in the database. That is why organizations struggle to store and manage certain available information in relational databases, as they have a rigid schema and cannot easily adapt it. To make even a minor change to the structure of the relational database would require an analysis of the entire architecture, making the maintenance extremely difficult.
3. Scalability
Scaling is more than just storing more data on one machine or distributing it on various machines. A system is scalable when the performance speed of executing queries remains acceptable even though the dataset is growing.
If a knowledge graph is created by melding various data sources, it can be challenging to store all the data in one machine. Graph databases solve that by using distributed systems.
Within distributed systems, the graph database knows the location of the data needed for graph traversal and sends the query to the query engine of each machine where the data is stored. When a request is processed, data is merged locally and in parallel, and afterward, results are sent to the client.
With this approach, the graph database operates almost as a single instance but can handle much more data. It is expected you will get 5x more read requests processed overall per second when you add 5x more servers, than it is possible with a single instance. Databases with implemented distributed systems allow for outstanding performance and scalability.
4. Dynamic algorithms to infer knowledge
With traditional graph algorithms, every time there is a change in the data, the whole system is analyzed to check whether the changes impacted the rest of the graph or created vulnerabilities. With dynamic algorithms, the analysis is also dynamic and can be limited only to a subset of the graph where the changes happened.
What does this mean for a knowledge graph using a graph database? Let’s say a company uses data lineage to provide transparency about data flows and feeds that information into its risk reporting. This process requires broad data governance. As data arrives into the system dynamically, the company must be able to recognize problems the moment they appear. That is exactly what dynamic algorithms are designed for - to track changes only to the part of the affected graph, without recalculating the complete graph, which can be as big as 10 million nodes and 100 million edges, discovering issues more quickly. As a result, the company can monitor its quality, discover errors and trace them to the source before any real damage is done.
Conclusion
When it comes to inferring knowledge from data sources, we saw that the time in which that knowledge is inferred is just as important. It would be foolish to say there is an easy way to gain new knowledge, as it wouldn’t be so valuable if that were the case, but graph databases were designed to take on that task by using mechanisms and processes people perform in their brains when learning - by matching patterns and connecting data points.
Relational databases are a construct built around the limitations of the technology available at the time they were designed in. By moving away from rigid hierarchies and unnecessary table joins, graph databases offer companies a competitive edge that will allow them to swipe their competition from the table.