
Announcing GQLAlchemy 1.2 - Developing Python Applications With Graph Databases
Have you ever heard of SQLAlchemy? Well, we are developing something similarly awesome. The main difference is that GQLAlchemy isn't used with relational databases but with graph databases, starting with Memgraph. We are a long way from achieving the same level of awesomeness as SQLAlchemy, but we are slowly moving in the right direction.
GQLAlchemy allows you to interact with your graph database without having to use the Cypher query language. Because it's an OGM (Object Graph Mapper), you can use Python to import and query the data, save parts of your data to an on-disk database, enforce a graph schema, and much more.
The new release, GQLAlchemy 1.2, includes two new features and a ton of bug fixes and quality of life improvements. Don't feel like reading? You can also watch a short demo where we went over the most important features found in this update.

New features:
- Table data importer: A module for importing data from Amazon S3, Azure Blob and local storage.
- Memgraph instance runner: A module for starting, stopping and managing Memgraph instances using Python.
Important bug fixes and improvements:
- Fixed label inheritance.
- Added
where_not(),and_not(),or_not()andxor_not()methods. - Improved order_by() method from query builder by changing its argument types.
- Added an option to create a label index.
- Added batch save methods for saving nodes (
save_nodes()) and saving relationships (save_relationships()). - Added
load_csv()andxor_where()methods to the query builder.
If you want to check out all the fixes and improvements, take a look at the changelog.
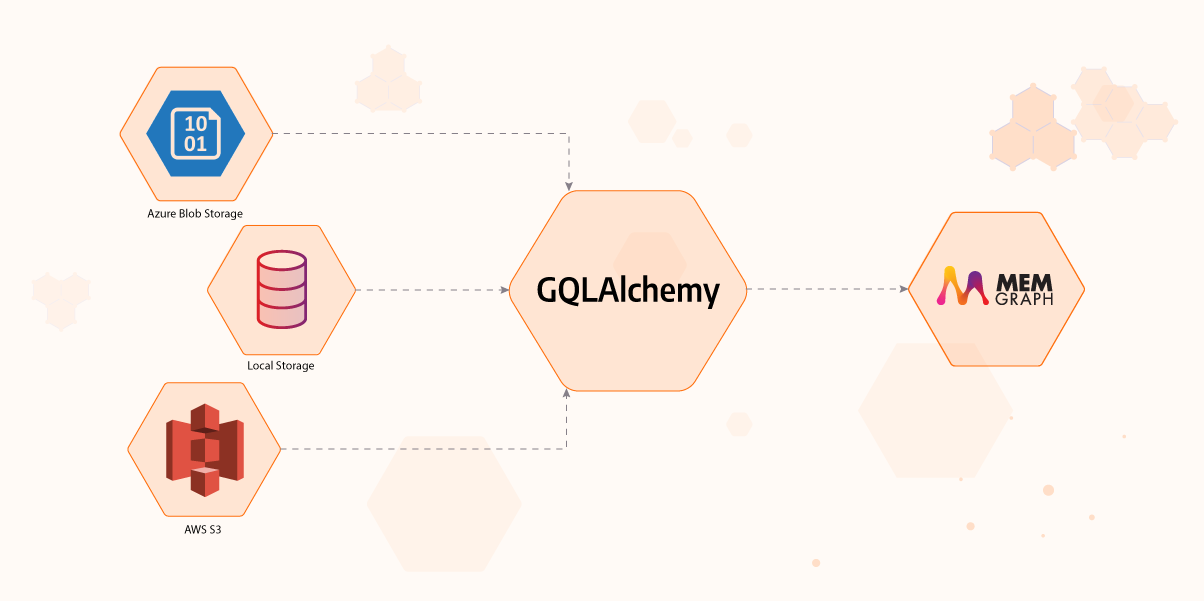
Import data from Azure Blob, AWS S3 or local storage
Currently, we support reading of CSV, Parquet, ORC and IPC/Feather/Arrow file formats via the PyArrow package. You can import data into your graph database directly from sources like Amazon S3, Azure Blob storage and local storage. It's also possible to extend the importer with different data sources and file formats. If you end up implementing your own importer, why not make a [pull request](Currently, we support reading of CSV, Parquet, ORC and IPC/Feather/Arrow file formats via the PyArrow package.) and the feature to the next GQLAlchemy release?
Starting and managing Memgraph instances directly in Python
We added a new module called instance_runner and it allows you to start, stop and check Memgraph instances from your Python code with GQLAlchemy.
Instead of opening a new terminal and starting Memgraph or writing a Python or bash script that will do that for you, just use the instance_runner.
It's possible to start Memgraph instances either from binary files (Memgraph installed on Linux or built from source) or using Docker. Here is a preview of how to start a Memgraph instance with Docker, run a query and return results:
from gqlalchemy.instance_runner MemgraphInstanceDocker
memgraph_instance = MemgraphInstanceDocker()
memgraph = memgraph_instance.start_and_connect()
print(memgraph.execute_and_fetch("RETURN "Memgraph is running" AS result"))[0]["result"])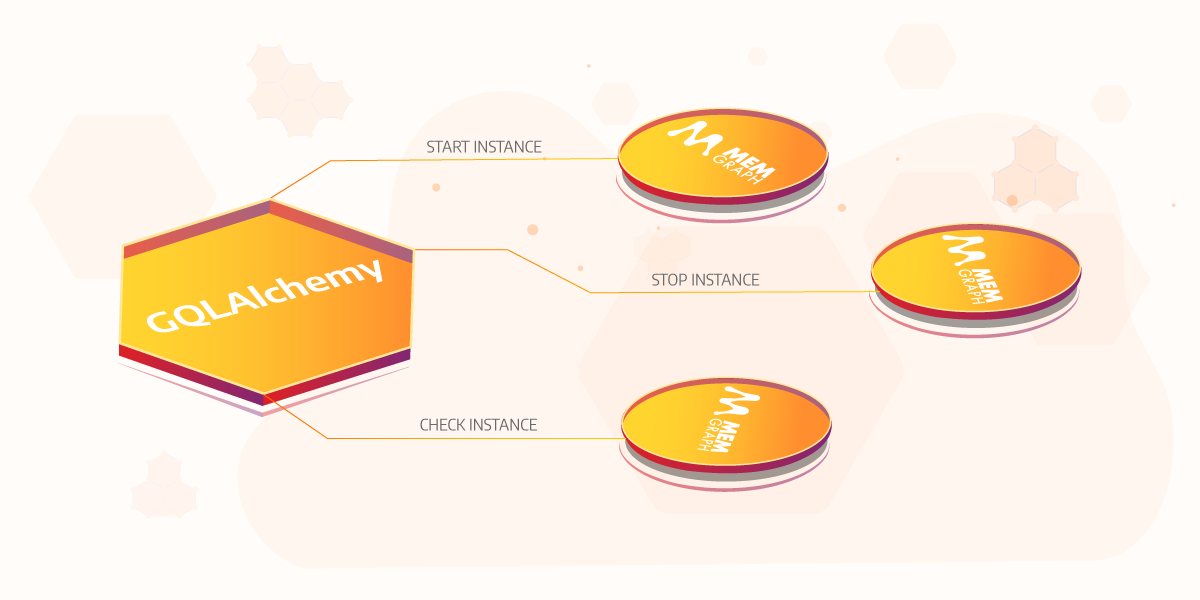
What's next
This release may be over, but we have already started developing features for the next one. If you have any suggestions or requests, why not drop us an issue on GitHub?
Maybe you also have an idea of what we could implement next. Join our Discord server and share your thoughts.
Stay tuned for the next release, and in the meantime: pip install gqlalchemy.
Happy coding!