Using Schema Functions to Model Your Data in Memgraph
In the realm of databases, understanding the structure of your data is important for efficient and effective query execution. Memgraph, a high-performance graph database, offers schema-related queries and procedures, allowing users to gain insights into the schema. This blog post will cover the Memgraph's schema features, exploring queries and procedures designed to provide valuable information about node labels and relationship types.
Graph Schema
In Memgraph, a schema is a diagram that maps the relationship between nodes that are part of the database. The schema includes entities, which become nodes in the database, and the relationships between them.
Before diving into schema-related queries, start Memgraph with the --storage-enable-schema-metadata configuration flag set to True. This flag activates a specialized cache, enhancing the storage and retrieval of metadata associated with the database schema.
docker run -p 7687:7687 -p 7444:7444 -p 3000:3000 -e MEMGRAPH="--bolt-port=7687 --storage-enable-schema-metadata=true" memgraph/memgraph-platform
In this blog, we’ll explore the following dataset:
CREATE (:Country {name: 'Germany', language: 'German', continent: 'Europe'});
CREATE (:Country {name: 'France', language: 'French', continent: 'Europe'});
MATCH (c1),(c2) WHERE c1.name= 'Germany' AND c2.name = 'France'
CREATE (c2)<-[:WORKING_IN {date_of_start: 2014}]-(p:Person {name: 'John'})-
[:LIVING_IN {date_of_start: 2014}]->(c1);
MATCH (c1),(c2) WHERE c1.name= 'Germany' AND c2.name = 'France'
CREATE (c1)<-[:WORKING_IN {date_of_start: 2014}]-(p:Person {name: 'Harry'})-[:LIVING_IN {date_of_start: 2013}]->(c2);
MATCH (n)-[r]->(m) RETURN n,r,m;
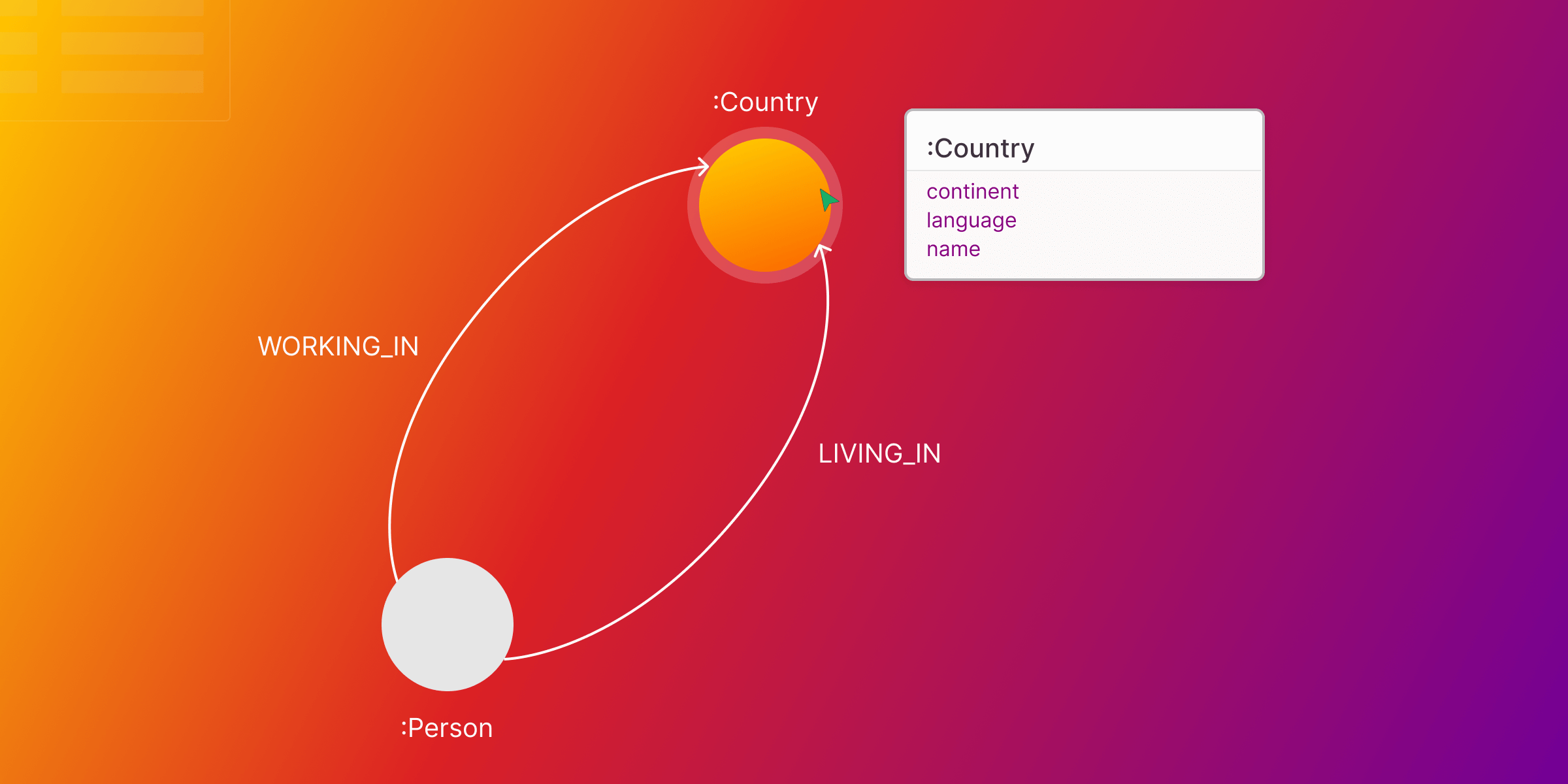
For a closer look at your database's current data model, you can generate a graph schema in Memgraph Lab that will show all the node types and relationships between them.
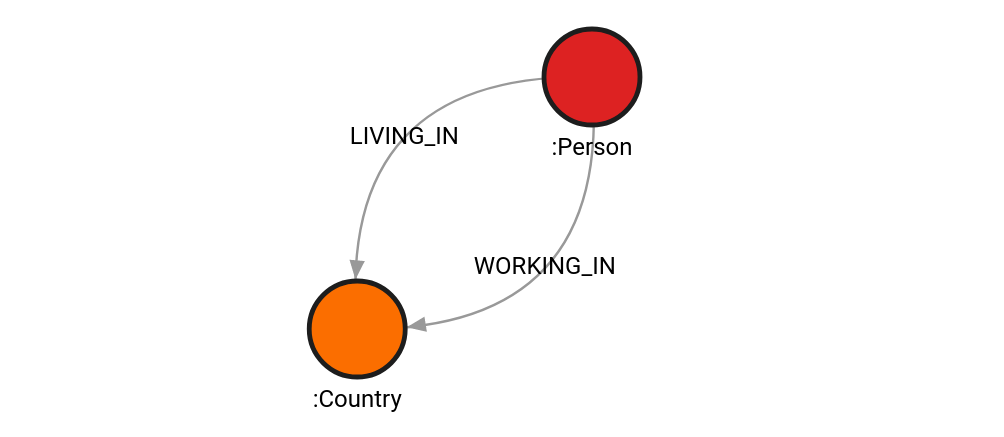
You can retrieve insights into the structure of your data. Node labels, associated properties, relationship types – it's all within reach. For instance, executing the SHOW NODE_LABELS INFO; query provides a list of node labels of current or past node labels:

Similarly, SHOW EDGE_TYPES INFO; provides a list of current or past relationship types:

Now, let's explore the procedures, firstly focusing on the schema.node_type_properties(). This procedure is a powerful tool for obtaining schema information about nodes and their properties within the graph. It can be called by executing the following query:
CALL schema.node_type_properties()
YIELD nodeType, nodeLabels, mandatory, propertyName, propertyTypes;

The output of this procedure includes:
nodeType: a string that represents concatenated node labels separated by a colon.nodeLabels: a list of strings, providing a collection of node labels.mandatory: a boolean value, returning True if a specific node label is associated with only one property and False otherwise.propertyName: a string revealing the property's name linked to the node.propertyTypes: a string indicating the property type, offering additional insights into the node's characteristics.
On the other hand, the schema.rel_type_properties() is pivotal in providing schema information about relationships and their properties within the graph.
Calling this procedure looks like this:
CALL schema.rel_type_properties()
YIELD relType, mandatory, propertyName, propertyTypes;

Here's a breakdown of the output:
relType: a string representing the type of the relationship.mandatory: a boolean value that indicates whether a given relationship type is associated with only one property (True) or not (False).propertyName: a string disclosing the property's name linked to the relationship.propertyTypes: a string denoting the type of the property, offering insights into the characteristics of the relationship.
meta_util.schema() procedure
The schema() procedure returns a graph schema by providing a list of relationships connecting distinct nodes. In input, if include_properties is set to true, additional property information is incorporated into the graph schema, enabling the extraction of distinct node and relationship objects along with their counts.
Understanding the stored data involves recognizing the types of nodes and relationships within the database and their connections. Additionally, nodes and relationships may possess unique properties, emphasizing the importance of ensuring a specific number of graph objects have specific properties during data loading. The concept of property count for graph objects with particular properties becomes a valuable tool.
The output provides a list of distinct node objects along with their counts and, when include_properties is set to true, incorporating properties count within each node object. Additionally, it provides a list of unique relationship objects accompanied by their counts, with the option to include properties count within each relationship object when include_properties is true.
Example
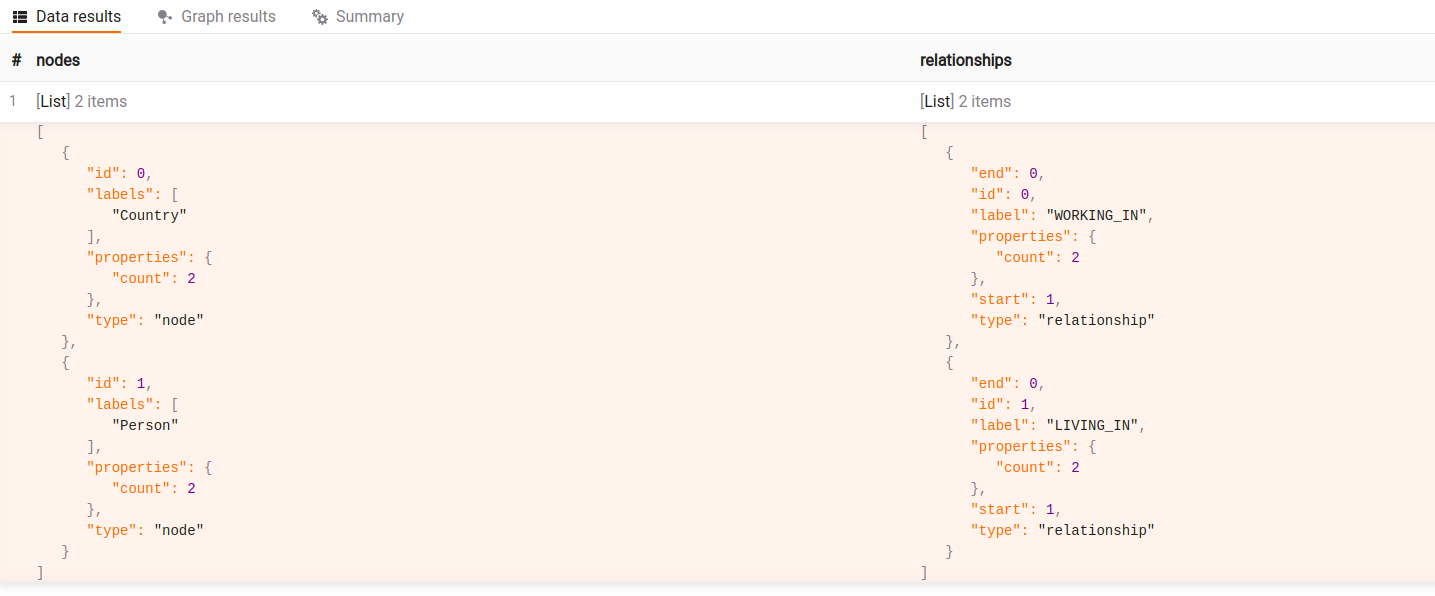
Get graph schema without properties count:
CALL meta_util.schema()
YIELD nodes, relationships
RETURN nodes, relationships;
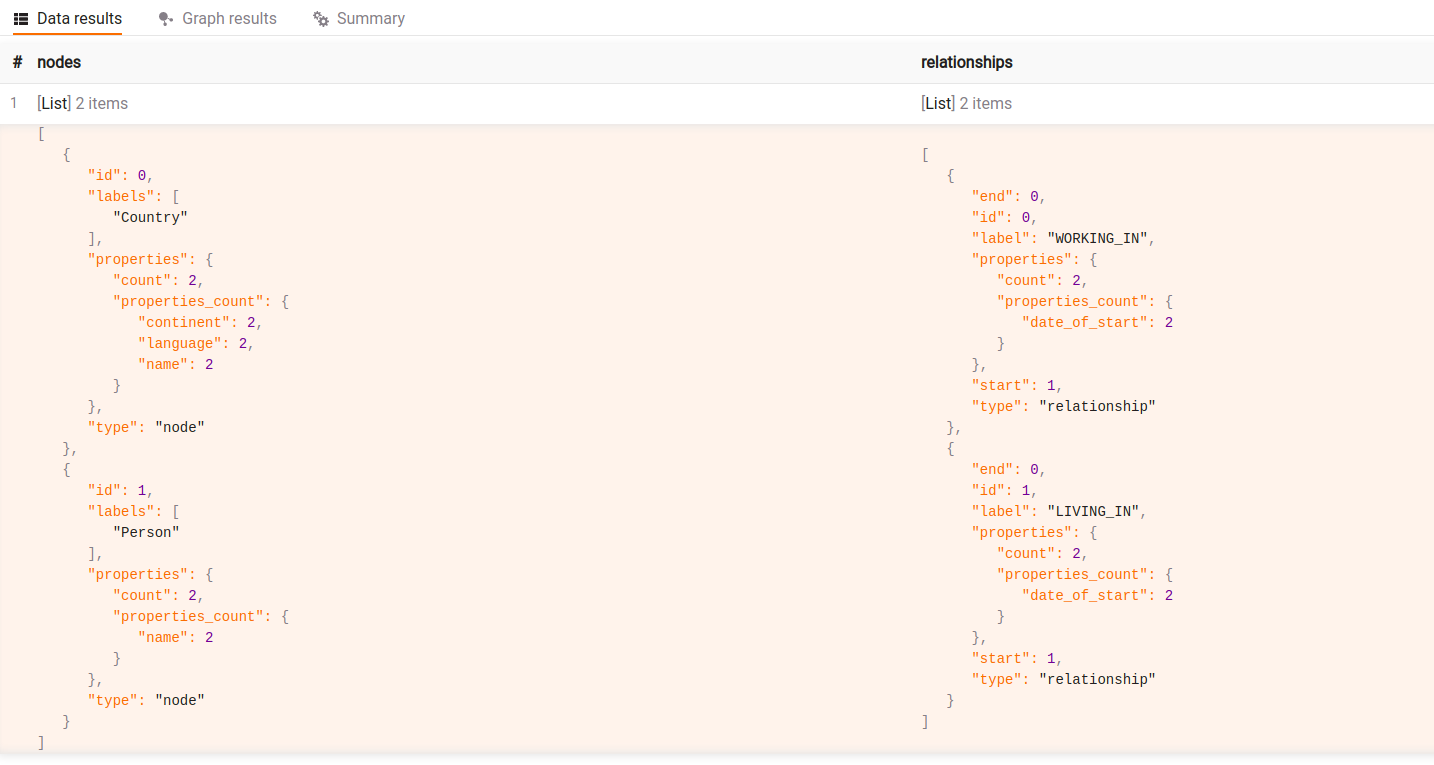
Get graph schema with properties count:
CALL meta_util.schema(true)
YIELD nodes, relationships
RETURN nodes, relationships;
llm_util.schema() procedure
This procedure, tailored for large language models (LLMs), is used to describe graphs, made initially for schema generation within LangChain—a framework for applications driven by language models.
Using the llm_util.schema() procedure, you can generate the graph database schema in a prompt-ready or raw format. The prompt-ready version optimizes language for LLM recognition, while the raw format provides comprehensive schema information.
Adjust the output_type parameter, by default as prompt_ready, to raw for a simplified version adaptable for prompts.
The output, presented as schema: mgp.Any, offers a prompt-ready graph schema or raw format information—providing flexibility for applications within LangChain and seamless interaction with language models.
Example
To get the prompt-ready graph schema, run the following query:
CALL llm_util.schema() YIELD schema RETURN schema;
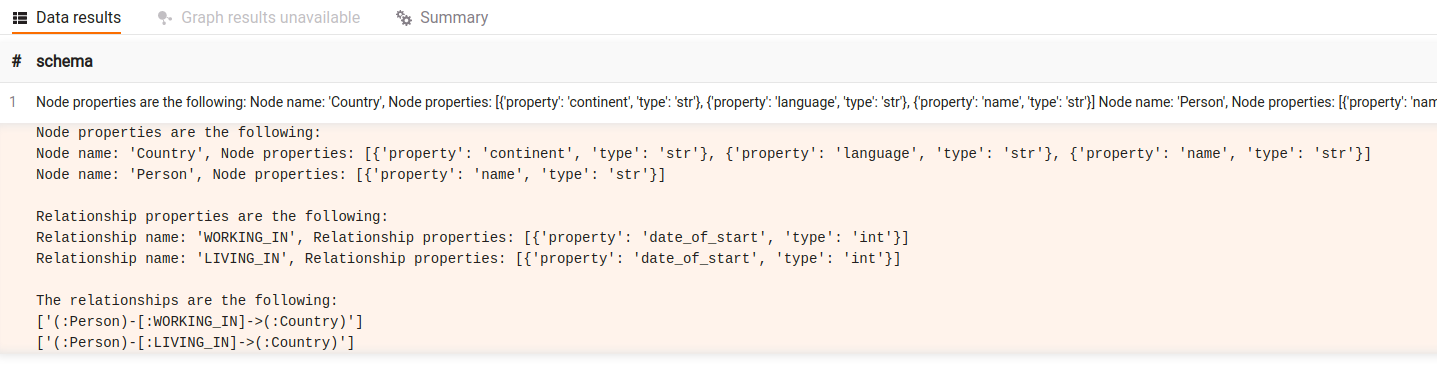
You can also get the raw graph schema by running the following query:
CALL llm_util.schema('raw') YIELD schema RETURN schema;
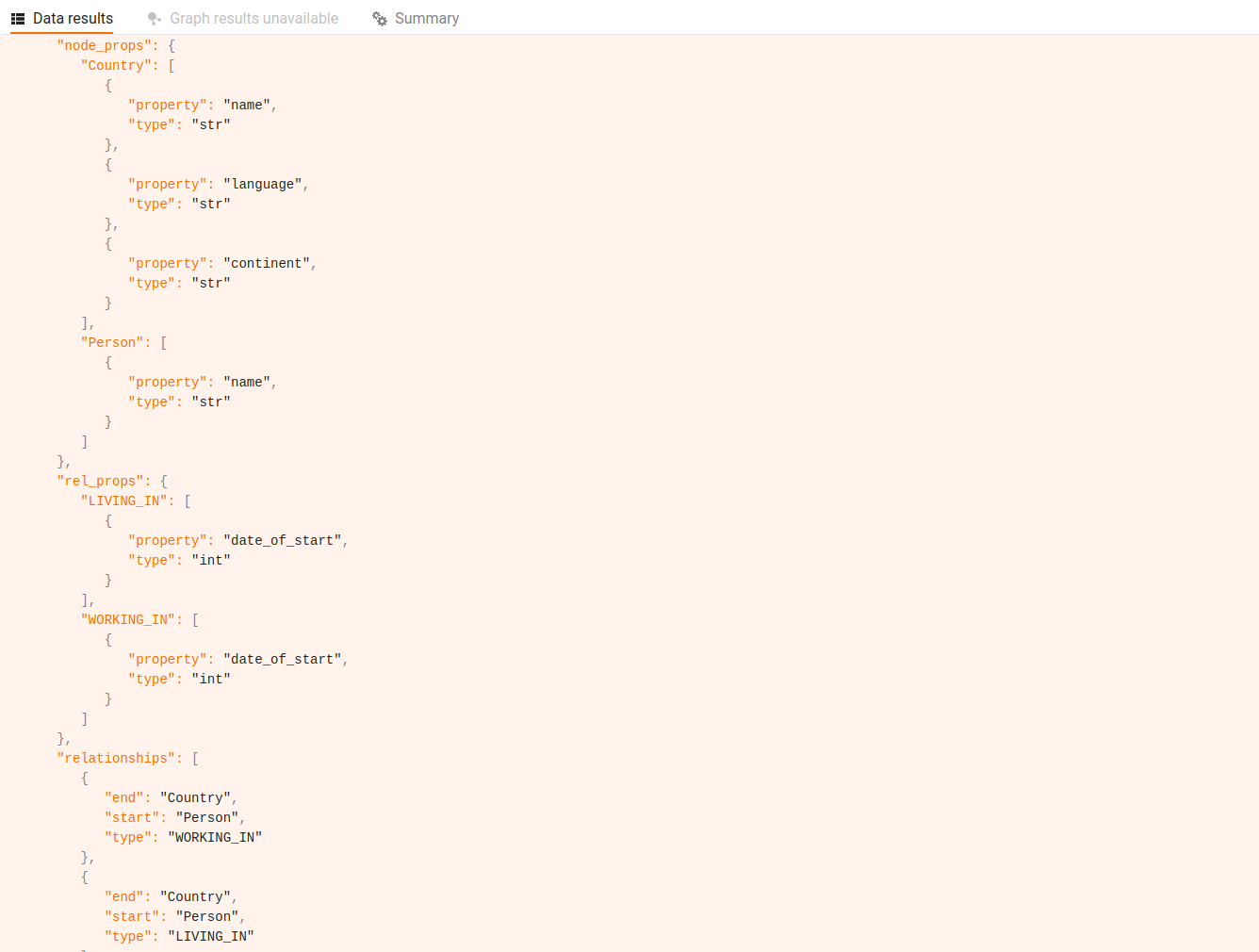
Takeaway
Memgraph simplifies database management with powerful schema-related tools, offering exploration of node and relationship details. The meta_util.schema() procedure provides a comprehensive view of the graph schema, while llm_util.schema() accommodates large language models with versatile prompt-ready and raw formats for efficient schema exploration and generation. Memgraph ensures a user-friendly experience, making data structure understanding and schema management straightforward.