
Utilizing Parallel Processing in Database Recovery
The in-memory nature of Memgraph gives you a plethora of advantages against other database management systems in terms of performance. You do not need to issue expensive IO operations to copy your data into main memory and only after which you could do some operations on it. The data you are interested in querying is already in your server's main memory. On the flip side, memory is a form of volatile storage. All it takes is an outage, and the data that is stored solely in memory would be wiped. You would end up with lost data upon a system crash. In order to avoid nuisances like this and system crashes, Memgraph provides you with the well-described, battle-tested process of database recovery.
What is recovery?
Recovery is the action or process of regaining possession or control over something stolen or lost. In this specific case of database recovery, it means restoring your database to the correct and consistent state it was in before the system crash. In other words, recovery refers to the restore operation of data that was lost from your memory upon the process itself being killed. This begs the question as to how does one restore something that was lost. To put it simply, it was never lost in the first place.

Memgraph takes periodic snapshots of your data and saves it into non-volatile storage. If the process stops for any given reason, you still have all your data saved in the snapshots folder which is located at var/lib/memgraph/snapshots by default but you can change that by using the appropriate flag --data-directory. When you start the Memgraph instance again, it will look for any valid snapshots in the above-mentioned folder, and start recreating the database in memory, based on the latest valid snapshot it could find. It is important to mention here, that snapshot creation is configurable through the flags:
-
--storage-recover-on-startup -
--storage-snapshot-interval-sec -
--storage-snapshot-on-exit -
--storage-snapshot-retention-count
You can find an extended description here. As you can see the user has plenty of choices to configure the database recovery-related options however there is one slight issue.
What is the issue?
If you have a huge dataset you would like to recover after a system crash, it might take a long time to have your data back into its original form, which is a bit inconvenient. You already had to go through the unpleasantries of restarting your instance while crossing your fingers and hoping that the latest snapshot includes the previously bulk-imported updates to your graph and Atropos did not cut your update's thread of life too short. Speaking of threads, in order to speed up the database recovery process, they could be utilized better.
Multithreading is a powerful tool provided by modern computer architectures with multi-core processors. It allows you to run separate threads of executions that are operating independently from one another, hence, parallel processing. While it sounds like a great tool — which it is — it really is a double-edged sword.
If you want to use multiple threads to update and read the same resource without the proper tools, that means you are wandering into the territory of race conditions. This is strikingly apparent in the case of database management systems. If you consider that all a database does on a high level is provide you with the ability to create, read, update, and delete data, then you can easily imagine a situation where two or more users would like to update or extend the stored data concurrently. This is exactly the same setting that we encounter while trying to recover the graph from multiple threads based on the snapshot files, only instead of users, the recovery threads are trying to keep pushing data into the graph.
Luckily for us, the way Memgraph stores the graph data internally is by using an almost lock-free skip list implementation. This means that the concurrent access is handled by the internal data structure, and from the point of view of the individual recovery threads, all we have to concentrate on is to push the data into the skip list: we do not have to be concerned about concurrent access-related race conditions.
How do we profit from parallel processing?
As mentioned before, from the thread's perspective, the only important thing is to get a hold of some data and push it into the internal data structures to recreate the graph. There is one trivial caveat here however which has to be mentioned. You have to be careful so that the individual threads do not overlap with each other. The snapshot file has every information needed in order to restore the graph but you need to define some boundaries so a given recovery thread does not try to restore elements that it is not responsible for. Otherwise, you could end up with scenarios where two or more worker threads are attempting to recreate the same vertex, which is just wasted work.
Inspecting benefits with a top-down approach
The changes that have been made would be the easiest to explain in a top-down approach, so let's inspect what has been changed in terms of configuration options. As you might notice, three new flags have been introduced:
-
--storage-items-per-batch -
--storage-recovery-thread-count -
--storage-parallel-index-recovery
Let's start with the first one, '--storage-items-per-batch'. Contrary to the other two, this flag is used when creating a snapshot, not when reading it as part of the database recovery process. The flag determines the number of items per batch, meaning that you are configuring the snapshot file, so it can indicate clear borders between sections of data. In other words, this flag gives you a way to pre-configure the boundaries of the subsections of data you would like to recover, so the recovery threads just have to take ownership of these individual segments when restoring the graph. The way this partitioning is done under the hood is that a dozen of offsets are stored within the snapshot file. For example, there is an offset stored to the edges, one to the vertices, and one also to the offsets. What was needed to add in the multithreading process were two additional offsets and their corresponding data to the snapshot files. One offset for the section (that describes the dimensions of the vertex batches), and one for the edge batches. The exact size of the dimensions is computed based on this flag and the given size of your graph.
The --storage-recovery-thread-count flag determines the number of threads you would like to provide for the purposes of the database recovery. Based on the above-mentioned two flags, you are aware of three things:
- The snapshot file contains all the information needed to recover the data.
- The snapshot file contains certain boundaries of the subsections in the data needed to be recovered.
- The number of worker threads specified by the user to use for the purpose of recovery.
Partitioning work between threads
With this information in our possession, everything is known in order to recover the graph with the use of parallel processing. The data is organized into chunks of equal size (Not always equal size, since it can not be guaranteed that the number of elements in a graph will always be evenly divisible by the number specified by --storage-items-per-batch), and it is also known how many chunks there are. The identification of certain chunks is done strictly by increasing the unsigned integer starting from 0. Based on this number a chunk can be assigned once and only once to one and only one worker thread. This is ensured by representing this batch id through a std::atomic<uint64_t> variable which every worker thread tries to atomically load and increment, upon trying to request a segment to recover.
That way, if there are two or more worker threads competing for the next processable segment of data, it ensures that only one of them will obtain the ID associated with a specific batch. The recovery is done from the worker thread's perspective when the obtained number from the atomic counter is greater than or equal to the number of chunks. This described method of recovery is done subsequently for edges and vertices.
The third flag, --storage-parallel-index-recovery is a boolean flag that describes if the recreation of the previously existing indices can be done with the use of parallel processing. The process itself works much like the one described above, and it is set to false by default.
Performance benefits
As it was mentioned above, parallel processing is a double-edged sword . Depending on the size and shape of your data, the question "How much additional acceleration can parallel processing enhanced recovery provide?" might be replaceable with "Can parallel processing enhanced execution speed up recovery?" If you are trying to recover a relatively small-sized graph, the benefits of parallel processing enhanced execution will likely be unnoticeable for your use case. That being said, if you are trying to recover a huge graph, the value yielded by using multiple threads of execution can give you a lot of performance boost.
Take a look at this specific example below:
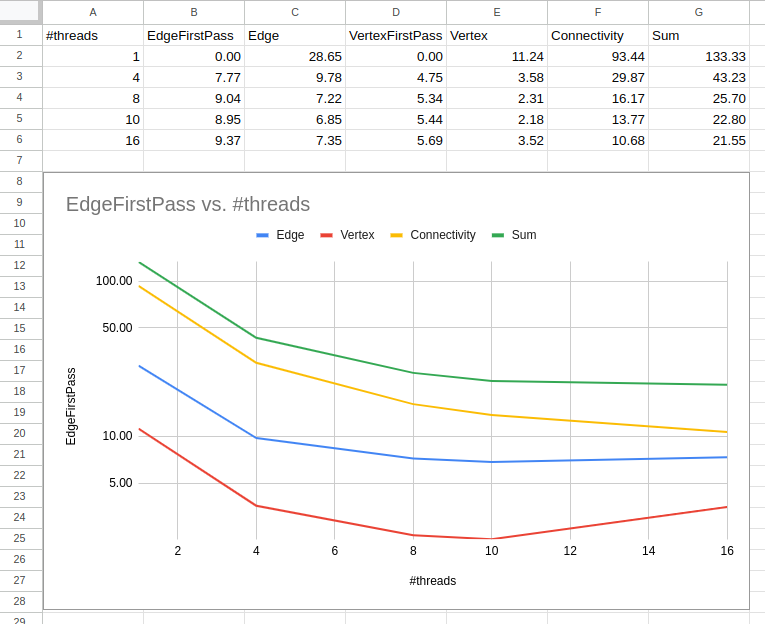
You can see that executing recovery with the use of parallel processing can yield speedups of up to 6x. To expand on what is being shown:
-
#threadsis the number of threads used in the recovery process. -
EdgeFirstPassis the time it took to initialize the recovery process for edges. -
Edgeis the time it took to recover the edges. -
VertexFirstPassis the time it took to initialize the recovery process for vertices. -
Vertexis the time it took to recover the vertices. -
Connectivityis the time it took to initialize the vertices to store references to its connected edges. -
Sumis the sum of the elapsed time given by each stage.
Sum up
Recovery is the process of restoring your data to its original form after an unwanted crash and it can take a while to recover all your data. Utilizing your system's offered resources more efficiently and acquiring more threads of executions to do the work for you can significantly speed up your recovery process.
In this blog post, we explored the nuisances of dealing with recovery, how modern computer architectures can be utilized to better serve the needs of the user in the case of recovery, and how Memgraph specifically deals with this issue. With this information in your possession, you have gained a basic understanding of what happens when you decide to recover your data using the parallel processing capabilities provided by the above-mentioned flags. We hope this post will enable you to pick the best recovery method based on the properties of your graph.