
Simplify Data Retrieval with Memgraph’s Vector Search
What is Vector Search?
Have you ever struggled to find what you’re looking for because you couldn’t pinpoint the right words? Traditional keyword-based search often falls short when you know the concept but not the exact terms. Imagine remembering a function or a vague description but being left empty-handed because your search terms didn’t quite hit the mark.
This is where vector search comes in. Instead of matching exact terms, vector search uses numerical representations called vector embeddings to capture the meaning of unstructured data—text, images, videos, or audio. By comparing these embeddings, vector search retrieves results based on similarity rather than exact matches.
For example:
- Searching for semantically related documents.
- Finding visually similar images in a database.
- Matching contextually relevant content in vast datasets.
At its core, vector search uses Approximate Nearest Neighbor (ANN) algorithms to deliver faster, more meaningful answers. By transcending the limitations of keywords, it revolutionizes how we interact with and retrieve data.
Why Combine Vector Search with Graph Databases?
Graphs are all about relationships, and vector search is all about similarity. Combine them, and you get a search engine on steroids—one that understands what your data is about and how it’s connected.
Here’s why:
- Graph context + semantic search. Graph databases excel at capturing relationships, while vector search enables similarity-based matching. Together, they allow a single query to evaluate semantic meaning and connections.
- Simplified architecture. Instead of maintaining separate systems for vector search and graph databases, Memgraph enables these capabilities within a single platform. This reduces operational complexity and ensures consistent data handling.
When would you care about combining these two?
- Recommendation engines. Matching users with what they need based on their behavior and the context of their interactions.
- Fraud detection. Spotting unusual patterns in data while understanding the relational context—because fraud rarely happens in isolation.
- Knowledge graphs. Linking semantically similar concepts to help researchers or teams uncover insights they didn’t even know they were looking for.
Vector Search Inside Memgraph
Recognizing the powerful synergy between vector search and graph databases, Memgraph has integrated vector search capabilities into its core functionality. It now features native vector search capabilities powered by USearch, a high-performance C++ library implementing the Hierarchical Navigable Small World (HNSW) index structure.
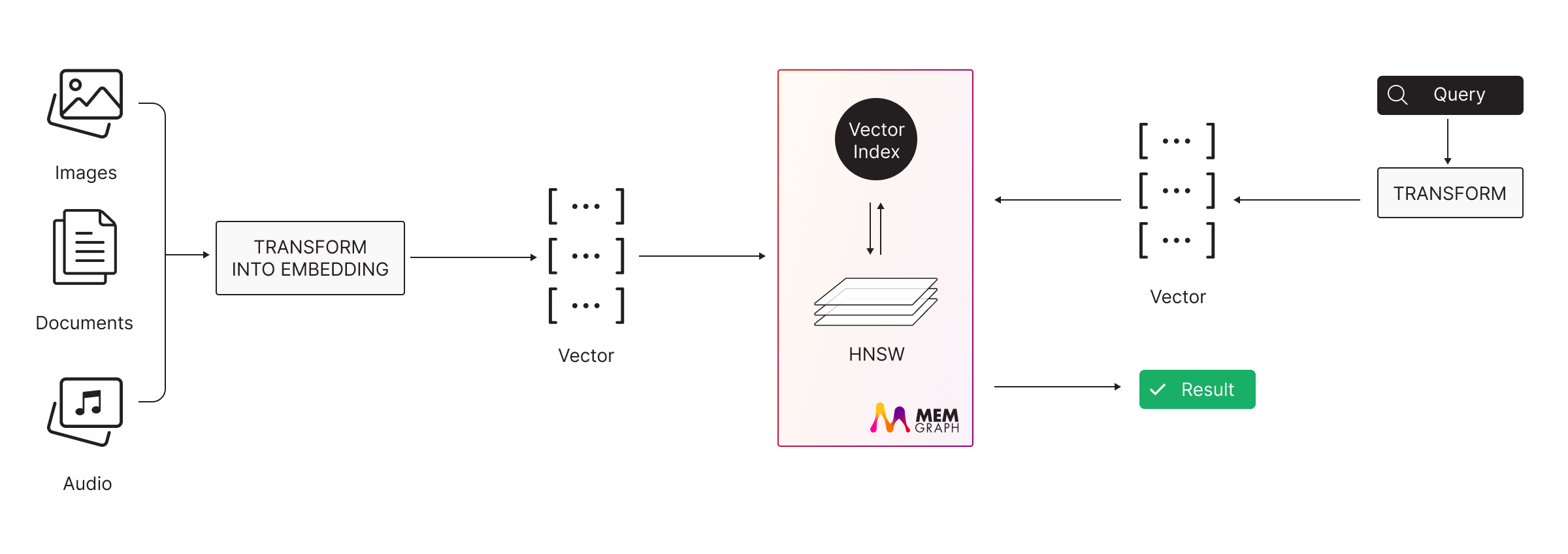
But adding vector search wasn’t just about integrating a library—it required tackling key challenges to maintain durability, replication, multi-tenancy, and transactional integrity.
Vector Index and Transactions
Database ACID transactions are fundamental to ensuring data integrity in multi-user environments. They provide different isolation levels that determine how and when changes made by one transaction become visible to other transactions. While traditional database operations benefit from strict isolation levels, vector search presents unique challenges that require a different approach.
Vector search prioritizes speed and similarity accuracy over strict transactional consistency. Implementing traditional isolation levels for vector indices would require additional data structures and synchronization mechanisms, leading to:
- Significant performance degradation,
- Increased memory overhead,
- Complexity in managing concurrent operations.
To address these challenges, Memgraph implements a READ_UNCOMMITTED isolation level specifically for vector indices. This design choice means:
- Vector index operations are immediately visible to all transactions,
- CRUD(Create, Read, Update, and Delete) operations maintain high performance,
- Memory efficiency is persevered by avoiding storing additional transactional metadata for the vector index. Instead, it primarily stores vertex pointers, reducing memory overhead.
Understanding READ_UNCOMMITTED in Vector Index Context
READ_UNCOMMITTED represents the most permissive isolation level in database systems. In Memgraph's implementation, while the main database can operate at any isolation level, the vector index specifically operates at READ_UNCOMMITTED. This design maintains all transactional guarantees at the database level - only the vector index operations use this relaxed isolation level, ensuring the database's ACID properties remain intact for all other operations. This means:
- Changes to the vector index are immediately visible to other transactions,
- Higher throughput for read operations,
- Optimal performance for similarity searches.
This architectural decision particularly benefits applications requiring:
- High-frequency similarity searches,
- Real-time vector index updates,
- Efficient memory utilization.
The trade-off between strict isolation and performance makes sense for vector search operations, where approximate nearest neighbor searches are inherently probabilistic, and absolute consistency is less critical than search effectiveness and speed.
How To Use Vector Search with Memgraph
To get started with vector search in Memgraph, you’ll need to enable and configure the feature, create vector indices, and query them for similar results. Detailed instructions and examples are available in the Memgraph docs—Vector search.
Example: Finding Similar Movies with Vector Search
We used Memgraph to analyze movie plot similarities from the Wikipedia MoviePlots dataset to showcase how vector search works. We could find contextually similar movies by converting plot descriptions into vector embeddings using the SentenceTransformer Python library.
For instance, searching for “A thief who steals corporate secrets through dream-sharing technology” correctly identified Inception, followed by Interstellar and The Dark Knight as other close matches.
Want to learn how we set it up? Check out the full tutorial: Building a Movie Similarity Search Engine with Vector Search in Memgraph.
If you’re are looking to build GraphRAG with Memgraph, check out other genAI-related features on Memgraph docs (GraphRAG with Memgraph).
Memgraph Academy
If you are new to the GraphRAG scene, check out a few short and easy-to-follow lessons from our subject matter experts. For free. Start with: