
Disabling multi-version concurrency control for faster import: Analytics mode
Memgraph is fully ACID compliant - as every database should be. Atomicity, consistency, isolation, and complete durability - everything is there. The catch is, when you are importing data into an empty Memgraph instance, there is a small chance you'll run any analytics queries at the same time, especially because there is no data yet. The only thing on your mind at that moment is how to get new data inside the database as fast as possible.
Also, by default, due to isolation levels, it isn't even possible to run analytical queries simultaneously with import. Other transactions will not see changes to the data until the transaction responsible for importing data is not committed. This default Memgraph’s operational storage mode is called IN_MEMORY_TRANSACTIONAL.
From version 2.7, Memgraph supports another storage mode called IN_MEMORY_ANALYTICAL. It enables you to work on data inside a database without ACID compliance. You may wonder why you would want that and what the benefit is. The thing is, to support full ACID compliance, Memgraph follows an idea of under buffers called delta objects covered in the Fast Serializable Multiversion Concurrency Control for Main-Memory Database Systems research paper. When you understand how multiversion concurrency control works in Memgraph, you will also understand why it can prevent you from importing your data faster.
Multi-version concurrency control: The solution or the problem
The first concept that allows Memgraph to keep the multiversion concurrency control is that only one transaction can change one object at a time. The second concept is that all changes are directly stored in place. And the last concept is the creation of delta objects. Every time there is a change inside a transaction, one delta object is stored. Thanks to delta objects, it's possible to revert to the older version of the database if a transaction fails.
Furthermore, by using deltas, other transactions have the feeling of isolation. They operate as though they are the only transaction in the system. For example, when a t1 transaction starts executing, all changes made by other transactions during t1’s lifetime won’t be seen from t2’s point of view. All because Memgraph is using delta objects. Information stored inside a delta object makes it possible to undo a change and go back to the state of the object which existed when the transaction started executing.
In Memgraph, delta objects are stored inside the transaction as an std::list. You may wonder why they are not stored inside the vertex or edge object, especially because deltas are used to get the transaction's correct state of the vertex or edge. Furthermore, if you want to get the correct state of a specific vertex or edge, traversing through all created deltas, for example, for all vertices and edges inside transactions, is not efficient.
Also, each vertex or edge contains a pointer to its latest change which is stored inside the transaction’s std::list. All changes corresponding to one vertex or edge are linked together.
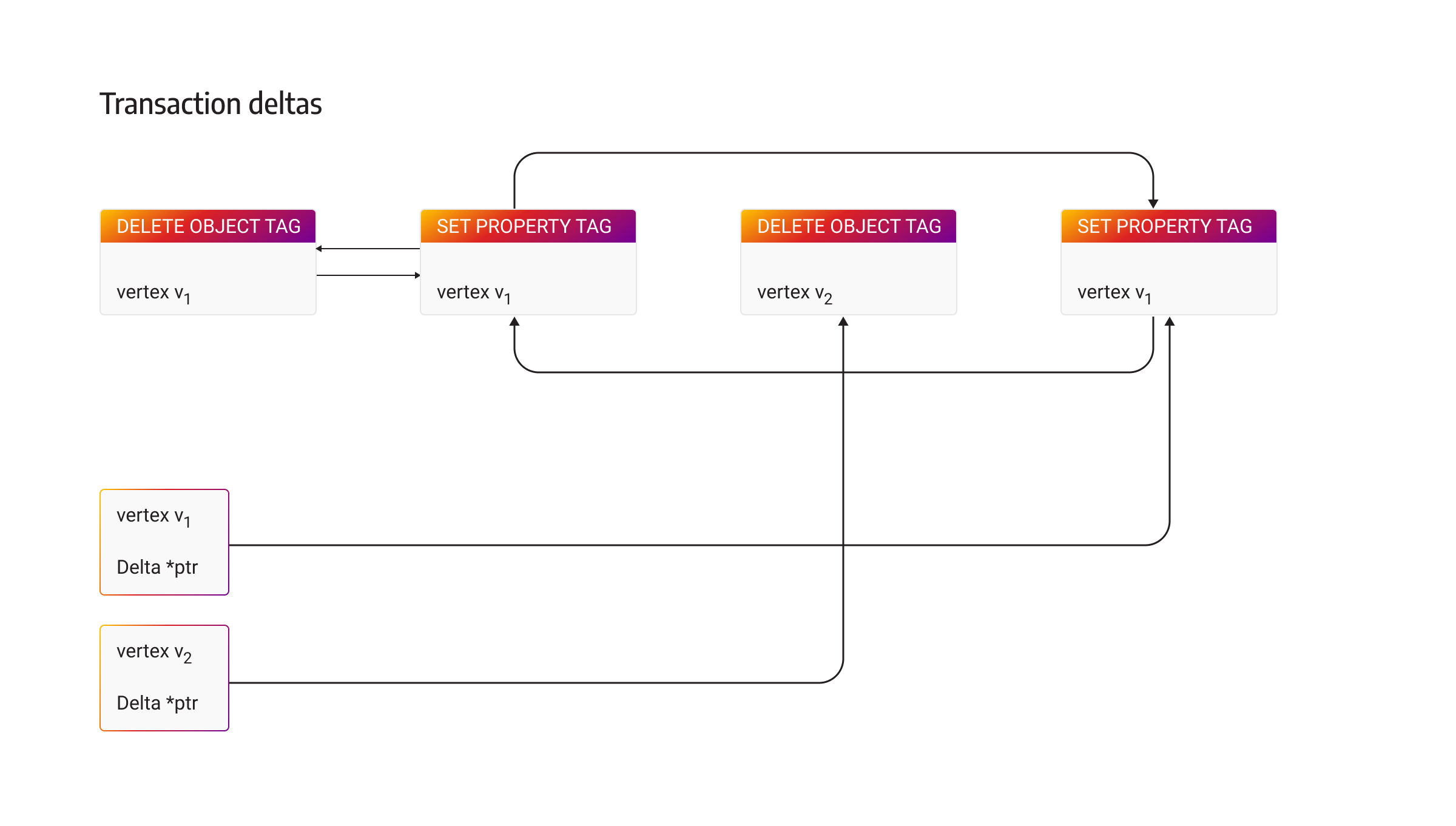
The query using the LOAD CSV clause imports a lot of data in one transaction. From Memgraph’s point of view, these all represent changes that need to be registered inside the transaction’s std::list of delta objects. Registering all those changes, which isn't actually crucial during data import, creates a lot of memory overhead.
What happens when you try to import a lot of data?
The answer is: Memgraph starts creating a lot of deltas. Let's say a dataset has 1M vertices and 5M edges. Each vertex has 3 properties, and each edge has 1 property. Just counting delta objects would create a lot of memory overhead. We can count exactly how much:
_1 000 000 _ 104B (1 delta for each vertex for vertex creation) +1 000 000 _ 104B _ 3 (3 deltas for each node for each property creation) +5 000 000 _ 104B _ 3 (1 delta for edge creation, 1 delta for ingoing edge of vertex, 1 for outgoing edge) +5 000 000 _ 104B _ 1 (1 delta for each edge for edge property creation)*
= 2 496 000 000 bytes ~= 2.5GB
That is 2.5 GB of RAM consumed by the server during a transaction to import 1M vertices and 5M edges. It would be great if that memory usage made sense and was useful. But during the import process, it's not even possible to do any analytics as the data isn't even imported yet.
Deltas don’t just consume memory but also slow down performance. Consider the following query:
LOAD CSV from ..edges.csv as row
MATCH (n:row[0]) (m:row[1]) CREATE (n)-[]->(m)
While edges are being created, a lot of deltas on vertices are being created as well. These deltas, from another transaction's point of view, represent a way to undo the creation of edges. What also happens is that every time a transaction does an operation with vertex, it needs to traverse through all its deltas in order to get the state present at the start of the transaction.
But as the transaction is creating edges, it is guaranteed that it can see its own changes, and it doesn't need to traverse through the delta chain each time a new edge is created. That is why the system can work in a different storage mode, IN_MEMORY_ANALYTICAL, which will import data faster as it doesn't create any deltas.
Memgraph's Discord user xhoms created a beautiful chart of how the ratio of the number of edges to the number of vertices impacts import speed.
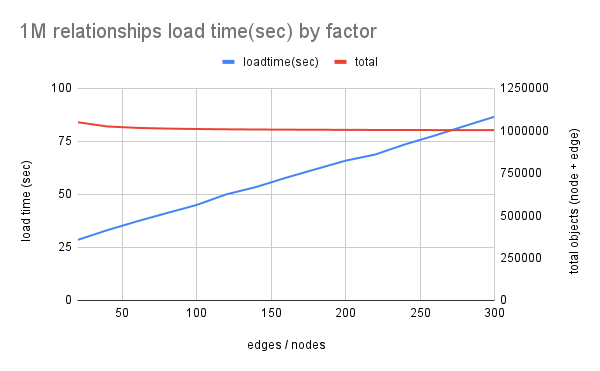
The example below shows the increase in speed and decrease in memory consumption on a bigger dataset:
In the transactional mode:
- 35 000 nodes - 0.1 s
- 5 000 000 edge - 4 minutes 27 s (267s)
- 6GB of RAM
In the analytics mode:
- 35 000 nodes - 0.1 s
- 5 000 000 edge - 25 s
- 1GB of RAM
Turning off the multi-version concurrency control for analytics mode
When the analytics mode was being implemented, there were a few things that needed to be taken into consideration.
To switch the storage mode from transactional to analytical, the user needs to run the following query:
STORAGE MODE IN_MEMORY_{ANALYTICAL|TRANSACTIONAL};
But what if other transactions are active when the user runs the query to switch from one mode to another? Also, what if one user ran a query, and the transaction is about to start executing, and some other user wants to change the storage mode?
The issue in the first case is that Memgraph can’t allow some transactions to create delta objects and not allow it to others because that would lead to a partial isolation level. One transaction may start before switching modes, but it's not doing any modifications at the time.
Once the user requests a mode switching, the new transaction starts in the IN_MEMORY_ANALYTICAL mode. If the new transaction starts doing modifications without producing deltas, and after that, the transaction that started before switching storage modes wants to read, from that "read" transaction's point of view, the state of Memgraph changed in terms of two commands. That is why all transactions are either operating in IN_MEMORY_ANALYTICAL storage mode or in IN_MEMORY_TRANSACTIONAL storage mode.
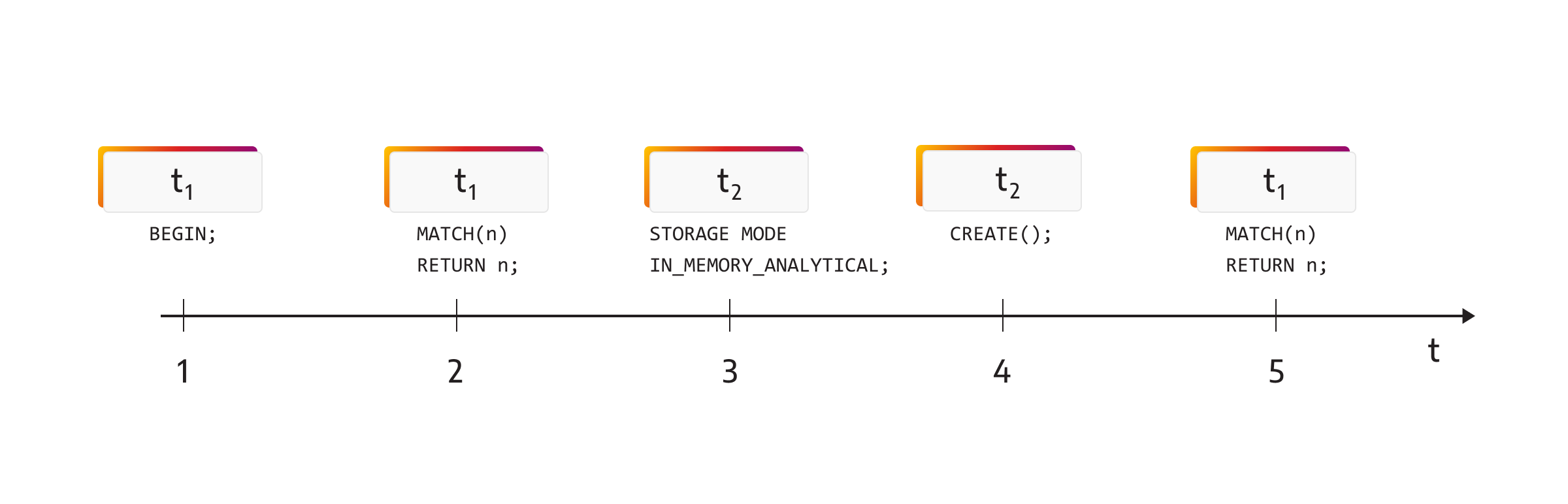
To avoid issues, a transaction to change the storage mode needs to wait for all other transactions to finish. During the mode change, there can’t be any other transaction in the system. Also, if one transaction is about to begin at the same time as the other is about to change the storage mode, depending on the race between these two, whichever acquires global lock on the system first, will start first.
Since deltas provide isolation, atomicity, consistency, and durability, and deltas are not created in the analytical mode, all of these concepts are also impacted. The only trace of ACID guarantees are manually created database snapshots, performance and memory consumption during import are not the only use case where Memgraph is now much faster.
Before, when Memgraph was running only in the transactional mode, multiple transactions could not insert an edge on the same node. Now multiple transactions can modify the same object, i.e., insert edges, add properties, etc.
The analytical mode also covers the case when two different threads want to insert an edge on the same vertex, at the same time. When a transaction wants to modify the vertex, it first needs to acquire a lock on vertex modification. Transactions then modify the same vertex one by one. Now, this change means that if you imported all vertices, multiple transactions can import edges from different files at once, thus importing data much faster.
What about durability?
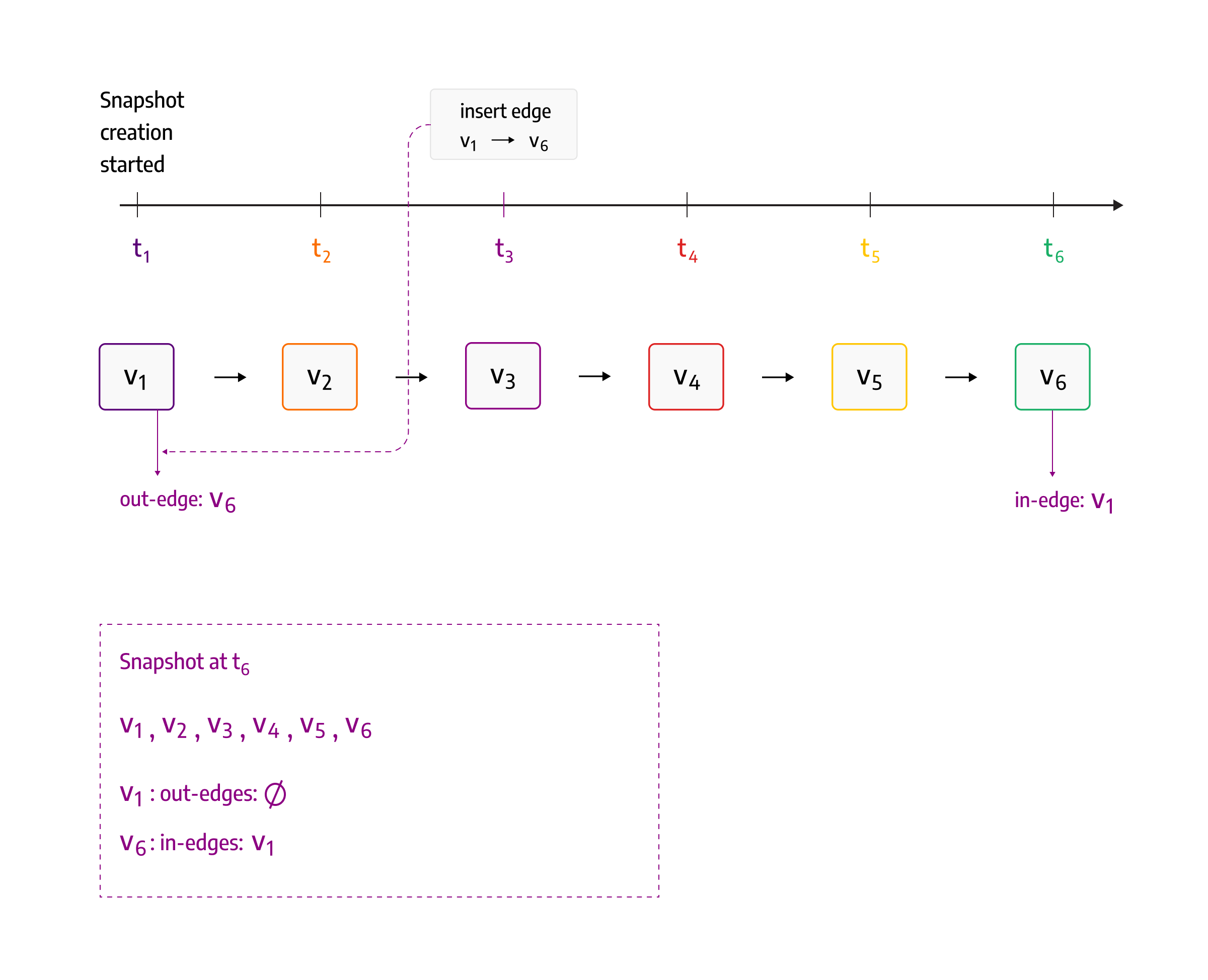
Without delta objects, there are no write-ahead logs. The user can manually create snapshots. During snapshot creation, there can’t be any other active transactions. The problem with supporting other active transactions is the possibility that during snapshot creation, a new edge gets inserted, and for one vertex, there is a missing outgoing edge, but for others, ingoing edges exist.
That problem is hard to detect. That is why we decided to enable snapshots but disable other transactions for reads or writes. Since snapshots require locking the whole system and preventing it from doing anything, periodic snapshots are disabled. In the image below, you can see how the problem can happen if you can insert data while the snapshot is being created. As snapshot creation is processing vertices one by one, it could happen that after vertex v1 gets processed and before v6 gets processed, there is a new edge inserted between v1 and v6. This creates a problem as the snapshot will have an incorrect state that v1 doesn't have the outgoing edge to v6.
Replication is also disabled in the IN_MEMORY_ANALYTICAL mode as the replication mode also requires delta objects which are not created.
On the other hand, it is very possible to switch the mode back and forth and do periodic snapshots in the IN_MEMORY_TRANSACTIONAL mode. And during that time, other transactions can do read operations on the system. Once the database starts working in the IN_MEMORY_TRANSACTIONAL mode, it is recommended to do a snapshot to compensate for missing write-ahead logs.
Conclusion
Memgraph can now operate in one of two different storage modes. Importing data and getting it into Memgraph as fast as possible is one of our top priorities. With the IN_MEMORY_ANALYTICAL mode, users can now import data from CSV files and batch import much faster than before.
As importing is usually done using CSV files, the analytics mode makes it faster and easier. In our next blog post, we will walk you through the other improvements on LOAD CSV and how profiling helped us implement them.
Implementing analytics mode was quite interesting as a lot of concepts inside Memgraph are correlated, and one change impacts a lot of other things in the system. The analytical storage mode should provide users with better performance and less memory consumption without suffering any problems.