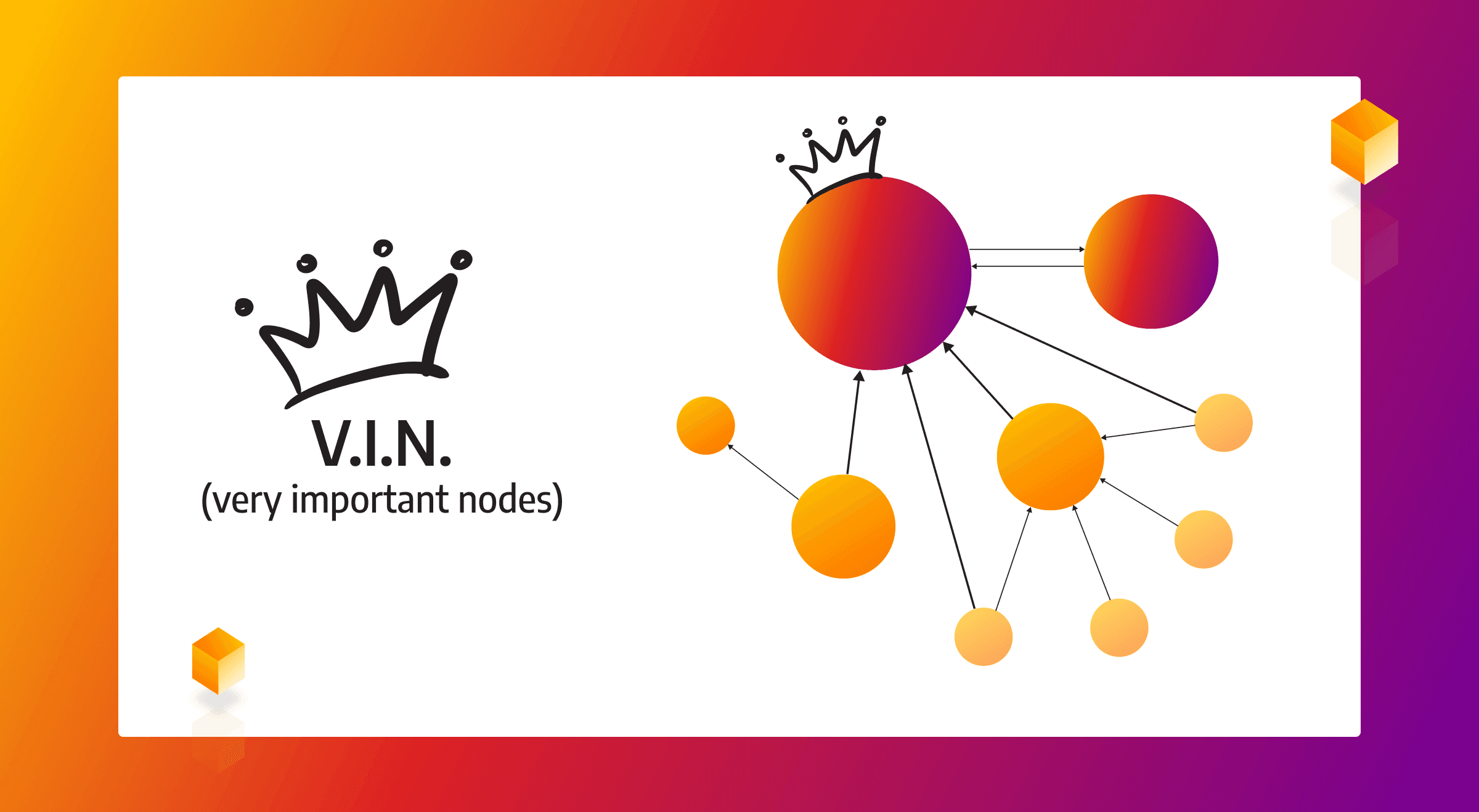
PageRank Algorithm for Graph Databases
The most interesting and famous application of PageRank is certainly one that actually sparked its creation. Google search engine founders Larry Page and Sergey Brin needed an algorithm to rank web pages and provide users with the best possible search engine results for a particular page.
Using the PageRank algorithm, each ranking page receives a boost from the number and importance of incoming links (other web pages that are linking to it). Pages with internal links and a higher page rank have a greater potential of increasing the ranking of the web page they link to.
What is the PageRank algorithm used for?
In graph database terminology, the PageRank algorithm is used to measure the importance of each node based on the number of incoming relationships and the rank of the related source nodes. What the PageRank algorithm actually outputs is a probability distribution that represents the likelihood of visiting any particular node by randomly traversing the graph.
So, it's basically a node popularity contest.
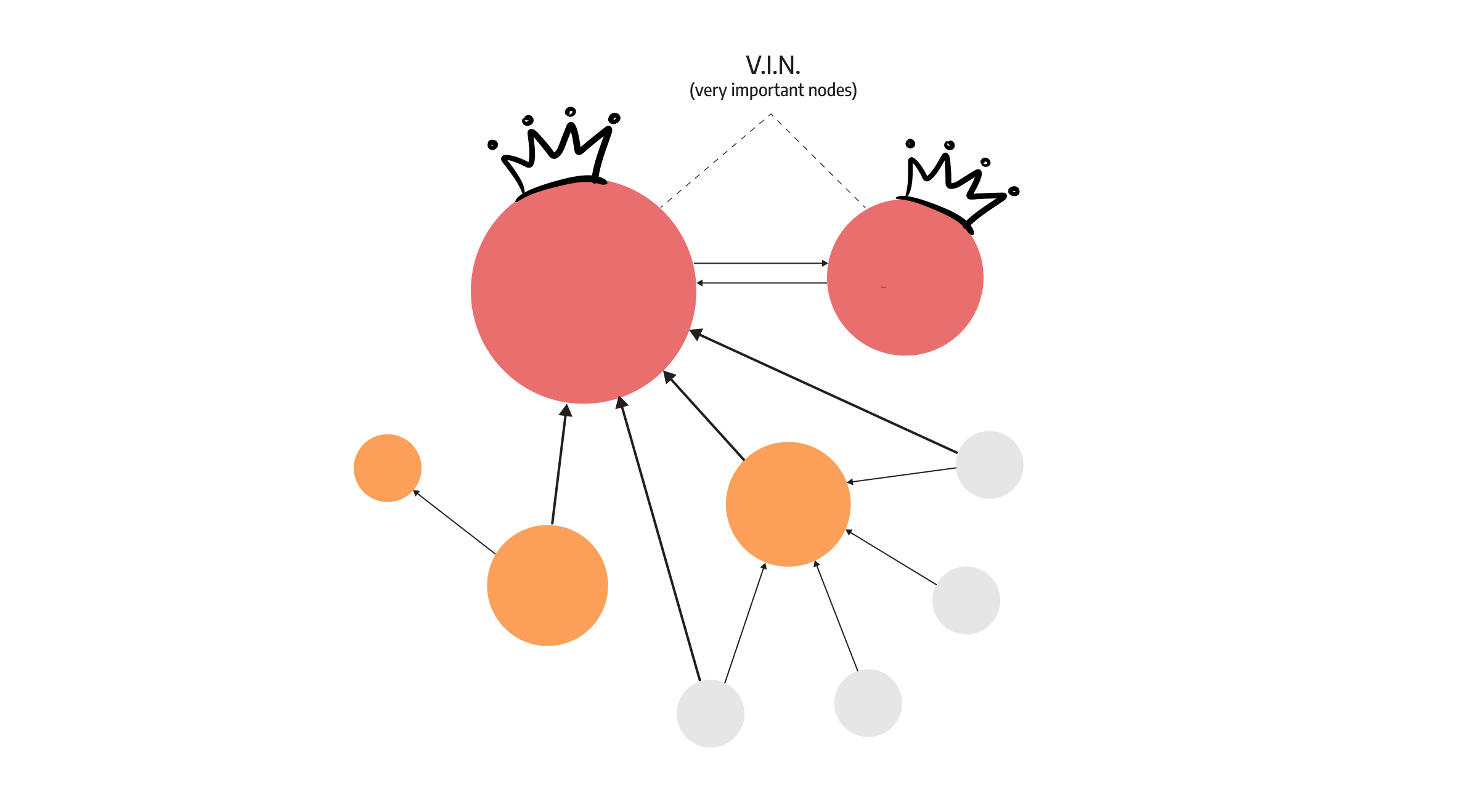
Personalized PageRank
A widely used type of PageRank is Personalized PageRank, which is extremely useful in recommendation systems. With Personalized PageRank, you can restrain the random walk by allowing it to start only from one of the nodes in a given set, and jump only to one of the nodes in a given set. This type of PageRank brings out central nodes from the perspective of that set of specific nodes. For example, Twitter uses Personalized PageRank to recommend who to follow online.
The animation below shows the results of PageRank on a simple network. A sequel of a well-liked movie will automatically be more popular than just a random new title because it already has an established fan base. In graph terms, the biggest node pointing to an adjacent node makes it more important.

Page rank can be used as a measure of influence for a variety of applications, not just for website pages and movie rankings.
PageRank algorithm applications
If a social network or a search engine is not the product you are developing, check out how you can utilize PageRank in various other use cases or knowledge graphs built to infer knowledge in these niches.
Recommendation engines
In recommendation and search engines, the PageRank algorithm can be utilized to recommend products that match the target user's preferences or are currently trending among all the other users. The algorithm considers the number of purchases and the reliability of the users who bought or reviewed the product.
A reliable user has a valid usage history and reviews, while unreliable users are fake customers whose purpose is to artificially inflate the metrics of certain products to make them appear more desirable.
Data lineage
Knowing the importance of documents in the data lineage graph has two important applications: impact analysis and system reliability.
In events of adding new data property, migration, or major updates, such as merging data sources after the acquisition, impact analysis can help assess the upstream and downstream impacts of such changes.
PageRank can also help identify high-impact nodes that are required to remain highly reliable because they are used in many other places throughout the organization.
Fraud detection
In fraud detection, PageRank can be used as an additional feature (input) to a machine learning algorithm to improve classification and reduce false positives.
Users who are involved in fraudulent transactions with shared cards are more likely to be fraudsters. So the node ranks involved in these particular transactions can be a piece of valuable information that can be used in machine learning models to predict and detect fraud among individuals that have connections with known fraudsters in the network.
Nodes can also be ranked based on how much money flows through each one to flag transactions that move much more money than what's average for a specific user.
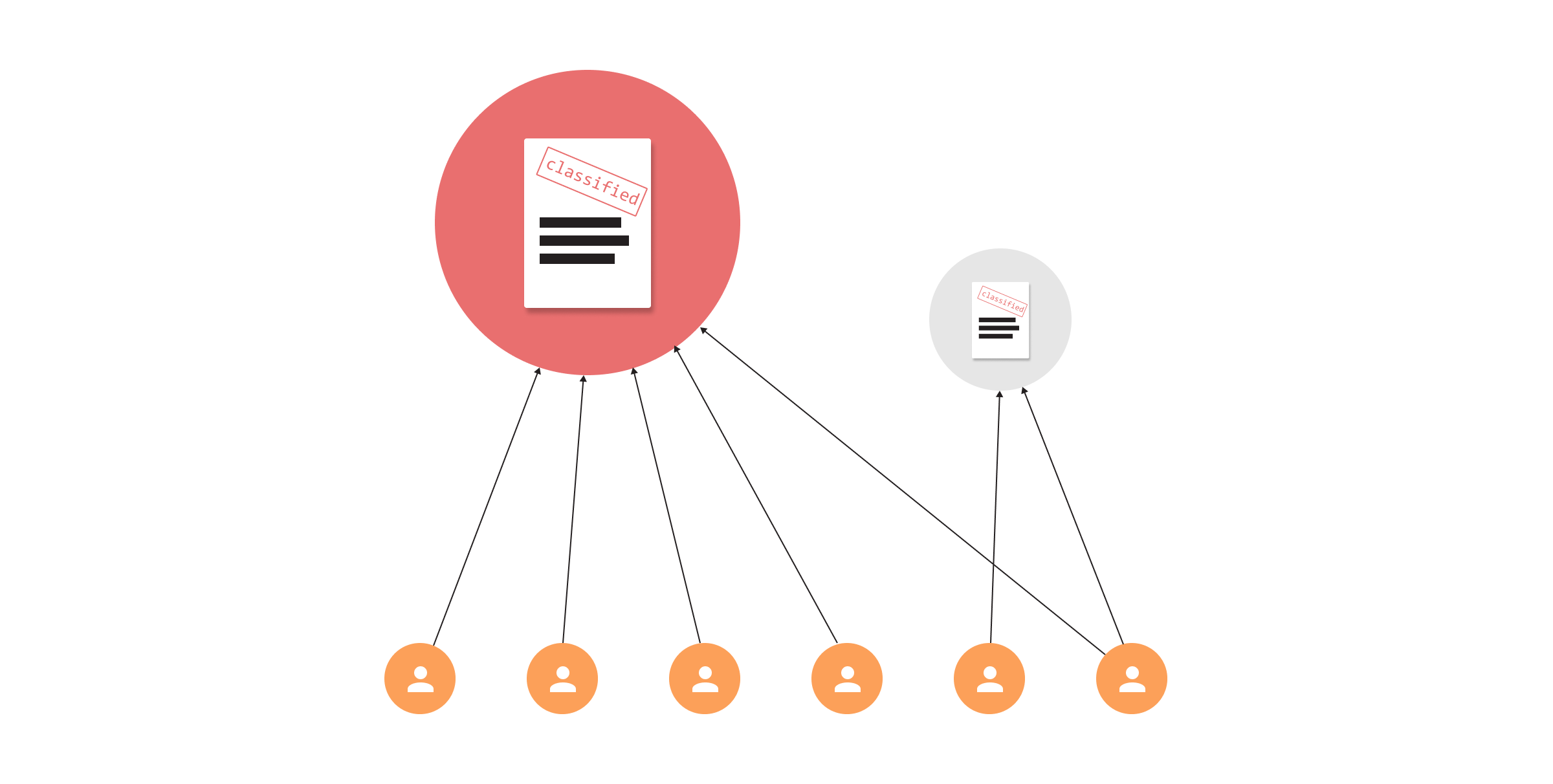
Identity and access management
While managing permission, it is important to restrict access to sensitive assets, as their exploitation could cause expensive damage to the company. In many systems, due to a lack of time and resources, high permissions are often given to people that don't actually need them.
A page rank algorithm can help identify which sensitive assets are accessible by many users to determine who, in fact, requires access and remove permissions for the rest of the users.
Network optimization
Critical infrastructures are systems that can be represented as a network of highly interdependent nodes and relationships. Due to their nature, failure in one node may result in a cascade of failures in other nodes. PageRank can help identify nodes likely to fail and if they would cascade to other nodes in the network.
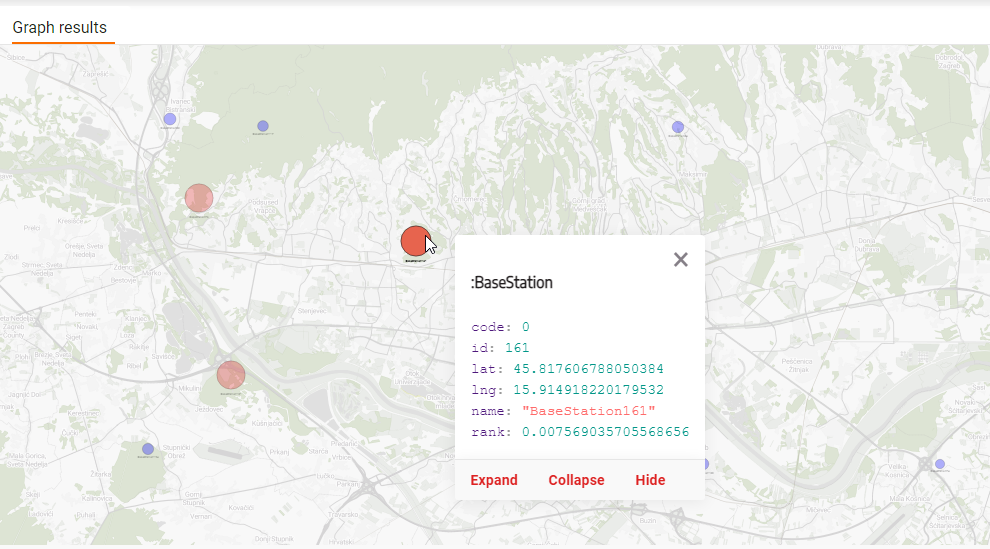
As energy infrastructure is also a network, using PageRank algorithm outputs to identify vulnerabilities in the topology is invaluable and can save time, money, and frustration for both companies and users.
Cyber security
As it is not feasible to remove absolutely every threat in the system. PageRank can help calculate probabilities of certain malignant events causing severe attacks. Just as PageRank's original purpose was to determine which sites will more probably be randomly clicked on due to all the other sites pointing at it, in the security system, it can be used to point out which attack will more probably be performed and consequences of which attacks will be more severe.
PageRank algorithm implementation in Memgraph
Memgraph has implemented PageRank using C++, which makes it ideal for use cases where performance is highly valuable. The graph needs to be directed, and the algorithm doesn't take relationships' weight into account.
Default arguments are the same as in the NetworkX PageRank implementation, so if you are a NetworkX user, it will be smooth sailing:
- max_iterations: integer (default = 100) ➡ The maximum number of iterations within the PageRank algorithm.
- damping_factor: double (default = 0.85) ➡ PageRanks damping factor. This is the probability of continuing the random walk from a random node within the graph.
- stop_epsilon: double (default = 1e-5) ➡ Value used to terminate the iterations of PageRank. If the change from one iteration to another is lower than
stop_epsilon, execution is stopped.
To call PageRank in Memgraph use the following query:
CALL pagerank.get()
YIELD node, rank
RETURN node, rank;You can try it out on Playground, in the Sandbox of the Europe gas pipelines dataset. Check the nodes with the highest value that could cause problems if they fail with the following query:
CALL pagerank.get()
YIELD node, rank
RETURN node, rank
ORDER BY node DESC;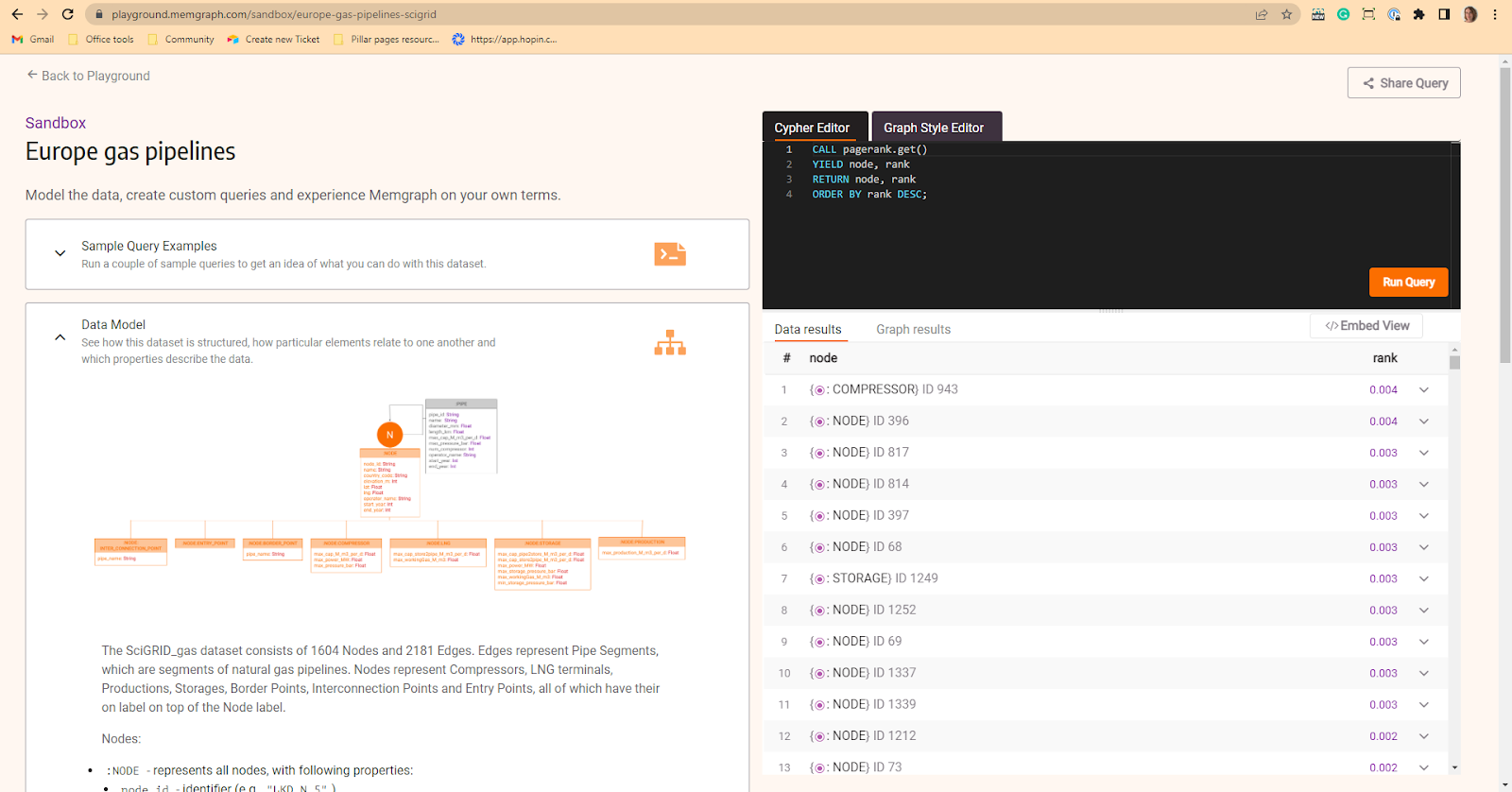
Running the PageRank algorithm on a subgraph
As with all the other algorithms in the MAGE open-source library, you can run PageRank only on a specific group of nodes with the project() function. Save the sub-graph in a variable, then provide it as a first argument of the algorithm:
MATCH p=(n:SpecificLabel)
WITH project(p) AS subgraph
CALL pagerank.get(subgraph)
YIELD node, rank
RETURN node, rank;If your application is highly time-sensitive and nodes and relationships are arriving in a short period of time, use the Dynamic PageRank which allows the preservation of the previously processed state. When entities are updated or new ones arrive in the graph, instead of restarting the algorithm over the whole graph, only the neighborhood objects of that arriving entity are processed at a constant time.
Final thoughts
PageRank is a mature graph algorithm that hasn't yet lost its relevance. Even more so, with the rise of graph database usage, it will surely find its place in many management systems. For more examples of using PageRank check Memgraph's blog posts on the same topic or explore more graph algorithms.
If you ever have any doubts about whether you are using PageRank correctly or you need help with implementing it into your use case, a welcoming community at Memgraph's Discord server will be more than happy to help you integrate graphs and algorithms into your system.