5 Questions on Performance Benchmarks
Performance is one of the all-time hot topics in the database world! And as a set of activities that database administrators or developers use to test out the database or compare them against certain criteria, benchmarks often come in parallel with performance. This article is Memgraph’s take on both.
Previously we have published some benchmark runs on Memgraph, which has been well-received by the community and led to some comments from the wider graph database community. The feedback contained some great suggestions on how we can improve our benchmark methodology to make sure the results follow the standard procedures of the benchmarking council.
To offer the fairest comparison to other databases, we’ve taken those lessons into account and developed Benchgraph, where you can run benchmarks on your own workloads. The launch has been followed by a community call where our very own Marko Budiselić and Ante Javor answered some of the common questions asked by the community. To save you time, we’re repurposing the key topics discussed into a blog post. Without further ado, let’s jump in.
Industry-standard vs. vendor-specific benchmarks
“One of the things our community has brought up is sometimes vendors will build their benchmarks to perform really well on their own datasets and behaviors. Whereas industry-standard benchmarks built by councils or committees tend to be created to give a more fair comparison between different databases. What is Memgraph’s take on this feedback?”
![]()
Both industry-standard and vendor-specific benchmarks play important roles in assessing database performance, and their relevance to your project depends on your specific use case and priorities. In the graph database space, the Linked Data Benchmark Council, or LDBC, is a well-known industry-standard organization. LDBC defines specific workloads that serve as benchmarks to showcase performance.
Industry-standard benchmarks, including LDBC, typically take a generic approach to suffice various database vendors and support common workloads that any database should handle. And they provide a baseline for comparison across different systems. On the other hand, vendor-specific benchmarks take a more tailored approach based on specific use cases. For example, Memgraph’s Benchgraph focuses on vendor-specific benchmarks for tasks like variable traversals, read-write ratios, and their variations, allowing users to observe differences in execution within a specific vendor's database.
Industry-standard and vendor-specific benchmarks are equally important because users face different workload scenarios and have different data priorities.
How do read vs. write operations impact performance?
“Another point that our community has brought up is some of the databases will behave differently depending on the architectural implementation in different scenarios, and one of those scenarios could be things like how well you cash your queries, results, indexes, etc. So how does something like rights influence those when your cache has to be invalidated, or your index and memory isn't completely valid anymore? In other words, how does read vs. write impact performance?”
The impact of read-and-write operations on database performance relies heavily on the architecture of the database and the underlying system. When data is written, the associated cache needs to be invalidated, and the cost of this invalidation varies across different systems. In certain workloads, such as streaming, there may be a large number of writes occurring within a short time span, making cache invalidation quite expensive.
But cache performance is not only influenced by the act of caching itself but also by what is being cached. For example, caching can be highly beneficial for read-only workloads, but it can negatively impact query performance in write-intensive scenarios. At Memgraph, to thoroughly evaluate database performance, we test both read-heavy and write-heavy workloads, as well as combinations of the two.
So, the takeaway is when dealing with a high volume of updates per second, cache effectiveness decreases significantly. And if the maintenance cost of these caches is high, it can result in lower overall performance.
Long vs. short-running benchmarks
“Our community has also brought up the topic of comparing long vs. short runs. That, in a way, relates to the previous point of running up the database, indexes, etc. What has been Memgraph’s approach to this?”
Memgraph’s speed comes from its in-memory architecture. So, there is no need for lengthy warm-up periods or time-consuming benchmarks. Traditional long-running benchmarks allow for quite some time to cache queries, indexes, and other optimizations, which can showcase the best performance achievable by a database. On the other hand, short-running benchmarks, due to their limited duration, often highlight the worst performance potential. That is why these two types of benchmarks are like the two extremes, and your decision should depend on your project's specific requirements and priorities.
Tail latency vs. mean-values
“Cassandra is well known for having a bit of a garbage collection issue every once in a while, which means that suddenly queries can take seconds instead of milliseconds. And if you've got an application where response time matters, it can truly sour the experience for end users. So mean latency is important, but tail latency matters as well. What’s Memgraph’s opinion on this?”
When assessing performance, people typically rely on mean or median latency, as they are easily obtainable. However, to gain a comprehensive understanding of real-world scenarios, tail latency provides a much broader perspective. Imagine you can effectively plan and make informed decisions, considering the potential outliers and extreme cases rather than relying purely on the average query execution time. And this becomes particularly important when dealing with fast-changing or streaming data environments with high writes coming in.
Memgraph goes the extra mile by implementing three layers of garbage collection so that the system operates seamlessly and maintains a clean environment. So, overall, tail latency is just as crucial since it enables a deeper understanding of how garbage collection impacts the end-user experience.
Should you restart your database between runs?
“The final topic our community has brought up is whether you should restart your database servers between those runs.”
When using a database in production, it's common to set it up and run it for a long time without restarting unless there's a maintenance issue or failure. However, this approach can introduce challenges when conducting benchmarks, as different tests can potentially influence each other's results.
To ensure accurate performance evaluations, it's important to restart the database before each test. This way, you can simulate the worst-case scenario and avoid any bias in the results. In real production environments, there's no guarantee of the order in which tests or queries will be executed, making it even more crucial to restart the database between each test to capture a comprehensive range of performance scenarios.
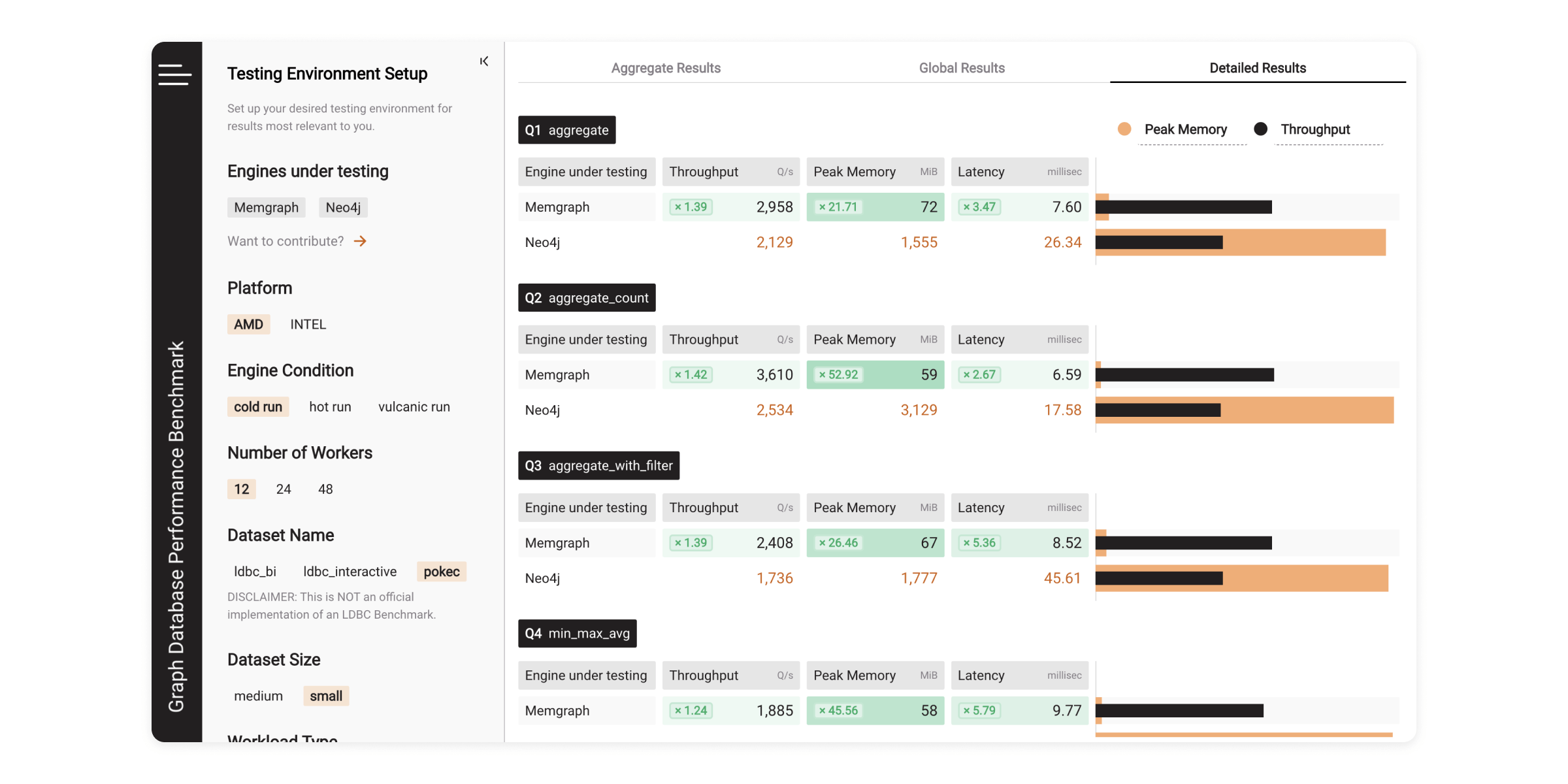
Bonus: How to run Benchgraph on your own workload?
Closing remarks
Have you already tested Benchgraph on your workload? We like receiving feedback from our community as it helps us improve and better serve our users. So, please, don’t hesitate to share your results on our Discord channel and tell us what you would love to see next!