Transformations Python API
This is the additional API documentation for mgp.py which contains
definitions of the public Transformation Python API provided by Memgraph. At the
core, this is a wrapper around the C API. This source file can
be found in the Memgraph installation directory, under python_support. On the
standard Debian installation, this will be under
/usr/lib/memgraph/python_support.
NOTE: This part of the documentation is still under development. An updated version will soon be available.
For an example how to implement transformation modules in Python with Memgraph Lab, check out this tutorial.
Below, you can find transformation examples of different format messages such as JSON, Avro and Protobuf.
mgp.transformation(func)
Transformation modules in Python have to follow certain rules in order to work:
- The transformation module is a Python function
- The function has to be decorated with a @mgp.transformation decorator
- The function can have 1 or 2 arguments
- one of type
mgp.Messages(required) - one of type
mgp.TransCtx(optional)
- The function has to return an
mgp.Recordin the following form:
mgp.Record(query=str, parameters=mgp.Nullable[mgp.Map])- the return type can also be an iterable of
mgp.Records, but not a generator
Examples
import mgp
@mgp.transformation
def transformation(context: mgp.TransCtx,
messages: mgp.Messages
) -> mgp.Record(query=str, parameters=mgp.Nullable[mgp.Map]):
result_queries = []
for i in range(messages.total_messages()):
message = messages.message_at(i)
payload_as_str = message.payload().decode("utf-8")
result_queries.append(mgp.Record(
query=f"CREATE (n:MESSAGE {{timestamp: '{message.timestamp()}', payload: '{payload_as_str}', topic: '{message.topic_name()}'}})",
parameters=None))
return result_queriesThis transformation extracts the interesting members of each mgp.Message and
stores them in query Record, which wraps a CREATE clause with all the
interesting members (timestamp, payload, etc.) and an empty parameter list.
Any errors can be reported by raising an Exception.
class mgp.Message(message)
Bases: object
Represents a single message. You shouldn’t store a Message globally.
is_valid()
Returns true if the underlying mgp.message object is valid and can be
accessed.
payload()
Returns the payload of the message. Raises an InvalidMessageError if
is_valid() is false.
topic_name()
Returns the topic name of the underlying mgp.message. Raises an
InvalidMessageError if is_valid() is false.
key()
Returns the key of the underlying mgp.message as bytes. Raises an
InvalidMessageError if is_valid() is false.
timestamp()
Returns the timestamp of the underlying mgp.message. Raises an
InvalidMessageError if is_valid() is false.
class mgp.Messages(messages)
Bases: object
Represents a list of messages passed to a transformation. You shouldn’t store
messages globally .
is_valid()
Returns true if the underlying mgp.messages object is valid and can be
accessed.
total_messages()
Returns the number of mgp.messages contained. Raises InvalidMessagesError if
is_valid() is false.
message_at(id)
Returns the underlying mgp.message at index id. Raises
InvalidMessagesError if is_valid() is false.
class mgp.TransCtx(graph)
Bases: object
Context of a transformation being executed.
Access to a TransCtx is only valid during a single execution of a
transformation. You shouldn’t store a TransCtx globally.
graph()
Raise InvalidContextError if context is invalid.
is_valid()
Returns true if the context is valid and can be accessed.
Transformation examples of different format messages
If you are using Kafka or Redpanda, below are transformation examples of messages in the most common formats:
Once the transformation procedures have been written, the module needs to be loaded into Memgraph.
JSON
JSON (JavaScript Object Notation) is an open standard file format and data interchange format that uses human-readable text to store and transmit data objects consisting of attribute-value pairs and arrays (or other serializable values). It is a common data format with a diverse range of functionality in data interchange, including communication of web applications with servers.
Let’s assume we have the following schemas coming out of three topics:
person = {
"id" : int,
"name": str,
"address" : str,
"mail": str,
}
company = {
"id" : int,
"name" : str,
"address" : str,
"mail": str,
}
works_at = {
"person_id" : int,
"company_id" : int,
"start_date" : date,
}The procedures within the Python transformation module that will transform the incoming data into Cypher query would look like this:
import mgp
import json
@mgp.transformation
def person_transformation(messages: mgp.Messages) -> mgp.Record(query = str, parameters=mgp.Nullable[mgp.Map]):
result_queries = []
for i in range(messages.total_messages()):
message = messages.message_at(i)
message_json = json.loads(message.payload())
result_queries.append(mgp.Record (
query=f'''MERGE (p:Person {{ id: ToInteger({message_json["id"]}), name: "{message_json["name"]}",
address: "{message_json["address"]}", mail: "{message_json["mail"]}" }})''' ,
parameters=None
))
return result_queries
@mgp.transformation
def company_transformation(messages: mgp.Messages) -> mgp.Record(query = str, parameters=mgp.Nullable[mgp.Map]):
result_queries = []
for i in range(messages.total_messages()):
message = messages.message_at(i)
message_json = json.loads(message.payload())
result_queries.append(mgp.Record (
query=f'''MERGE (c:Company {{ id: ToInteger({message_json["id"]}), name: "{message_json["name"]}",
address: "{message_json["address"]}", mail: "{message_json["mail"]}" }})''' ,
parameters=None
))
return result_queries
@mgp.transformation
def employees_transformation(messages: mgp.Messages) -> mgp.Record(query = str, parameters=mgp.Nullable[mgp.Map]):
result_queries = []
for i in range(messages.total_messages()):
message = messages.message_at(i)
message_json = json.loads(message.payload())
result_queries.append(mgp.Record (
query=f'''MATCH (p:Person ), (c:Company)
WHERE p.id = "{message_json["person_id"]}" AND c.id = "{message_json["company_id"]}"
MERGE (p)-[WORKS_AT: {{start_date: date({message_json["start_date"]})}}]->(c)''' ,
parameters=None
))
return result_queriesUpon creating three separate streams in Memgraph (one for each topic), and ingesting the data, the graph schema looks like this:
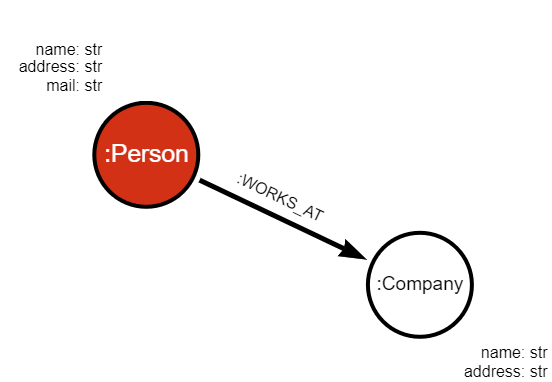
If you need help writing transformation modules, check out the tutorial on writing modules in Python, and an example of a C transformation procedure.
Avro
If you want to import your data in Memgraph using Apache Avro serialization, you need to know the Avro schema of your data. This is necessary for deserializing the data. Each schema contains a single schema definition, so there should be a separate schema for each data representation you want to import into Memgraph.
Avro data types will be flexibly mapped to the target schema, that is, Avro and openCypher types do not need to match exactly. Use the table below for data type mappings:
| Avro Data Type | Cypher Casting Function |
|---|---|
| bool | toBoolean |
| float | toFloat |
| int | toInteger |
Let’s assume we have the following schemas coming out of three topics:
profile_schema = """ {
"namespace": "example.avro",
"name": "Person",
"type": "record",
"fields": [
{"name": "id", "type": "int"},
{"name": "name", "type": "string"},
{"name": "address", "type": "string"}
{"name": "mail", "type": "string"},
]
}"""
company_schema = """{
"namespace": "example.avro",
"name": "Company",
"type": "record",
"fields": [
{"name": "id", "type": "int"},
{"name": "name", "type": "string"},
{"name": "address", "type": "string"}
{"name": "mail", "type": "string"},
]
} """
works_at_schema = """ {
"namespace": "example.avro",
"name": "Works_At",
"type": "record",
"fields": [
{"name": "person_id", "type": "int"},
{"name": "company_id", "type": "int"}
{"name": "start_date", "type": "date"}
]
}
"""Data received by the Memgraph consumer is a byte array and needs to be deserialized. The following method will deserialize data with the help of Confluent Kafka:
from confluent_kafka.schema_registry import SchemaRegistryClient
from confluent_kafka.schema_registry.avro import AvroDeserializer
def process_record_confluent(record: bytes, src: SchemaRegistryClient, schema: str):
deserializer = AvroDeserializer(schema_str=schema, schema_registry_client=src)
return deserializer(record, None) # returns dict
The procedures within the Python transformation module that will transform the incoming data into Cypher query would look like this:
import mgp
@mgp.transformation
def person_transformation(messages: mgp.Messages) -> mgp.Record(query = str, parameters=mgp.Nullable[mgp.Map]):
result_queries = []
for i in range(messages.total_messages()):
message_avro = messages.message_at(i)
msg_value = message_avro.payload()
message = process_record_confluent(msg_value, src= SchemaRegistryClient({'url': 'http://localhost:8081'}), schema=profile_schema)
result_queries.append(mgp.Record (
query=f'''MERGE (p:Person {{ id: ToInteger({message["id"]}), name: "{message["name"]}", address: "{message["address"]}", mail: "{message["mail"]}" }})''' ,
parameters=None
))
return result_queries
@mgp.transformation
def company_transformation(messages: mgp.Messages) -> mgp.Record(query = str, parameters=mgp.Nullable[mgp.Map]):
result_queries = []
for i in range(messages.total_messages()):
message_avro = messages.message_at(i)
msg_value = message_avro.payload()
message = process_record_confluent(msg_value, src= SchemaRegistryClient({'url': 'http://localhost:8081'}), schema=profile_schema)
result_queries.append(mgp.Record (
query=f'''MERGE (c:COmpany {{ id: ToInteger({message["id"]}), name: "{message["name"]}", address: "{message["address"]}", mail: "{message["mail"]}" }})''' ,
parameters=None
))
return result_queries
@mgp.transformation
def company_transformation(messages: mgp.Messages) -> mgp.Record(query = str, parameters=mgp.Nullable[mgp.Map]):
result_queries = []
for i in range(messages.total_messages()):
message_avro = messages.message_at(i)
msg_value = message_avro.payload()
message = process_record_confluent(msg_value, src= SchemaRegistryClient({'url': 'http://localhost:8081'}), schema=profile_schema)
result_queries.append(mgp.Record (
query=f'''MATCH (p:Person ), (c:Company)
WHERE p.id = "{message["person_id"]}" AND c.id = "{message["company_id"]}"
MERGE (p)-[WORKS_AT: {{start_date: date({message["start_date"]})}}]->(c)''' ,
parameters=None
))
return result_queries
Upon creating three separate streams in Memgraph (one for each topic), and ingesting the data, the graph schema looks like this:
Protobuf
Similar to Apache Avro,
Protobuf is a method of
serializing structured data. A message format is defined in a .proto file, and
from it you can generate code in many languages, including Java, Python, C++,
C#, Go, and Ruby. Unlike Avro, Protobuf does not serialize schema with the
message. In order to deserialize the message, you need the schema in the
consumer. A benefit of working with Protobuf is the option to define multiple
messages in one .proto file.
Let’s assume we have the following schemas coming out of three topics:
syntax = "proto3";
message Person {
int64 id = 1;
string name = 2;
string address = 3;
string mail = 4;
}
message Company {
int64 id = 1;
string name = 2;
string address = 3;
string mail = 4;
}
message WorksAt {
int64 person_id = 1;
int64 company_id = 2;
string start_date = 3;
}
These schemas translate into the .proto file.
Before making your transformation script, it is necessary to generate
code
from the .proto file.
Data received by the Memgraph consumer is a byte array and needs to be deserialized. The following method will help you deserialize your data with the help of Confluent Kafka:
from confluent_kafka.schema_registry import SchemaRegistryClient
from confluent_kafka.schema_registry.protobuf import ProtobufDeserializer
import person_pb2 # proto file compiled into Python module
def process_record_protobuf(record: bytes, message_type: obj) -> dict:
deserializer = ProtobufDeserializer(message_type)
return deserializer(record, None)message_type corresponds to the message defined in .proto file. This method
should be added to the transformation module.
The procedures within the Python transformation module that will transform the incoming data into Cypher query would look like this:
import mgp
@mgp.transformation
def person_transformation(messages: mgp.Messages) -> mgp.Record(query = str, parameters=mgp.Nullable[mgp.Map]):
result_queries = []
for i in range(messages.total_messages()):
message_pb = messages.message_at(i)
msg_value = message_pb.payload()
message = process_record_protobuf(msg_value, person_pb2.Person)
result_queries.append(mgp.Record (
query=f'''MERGE (p:Person {{ id: ToInteger({message.id}), name: "{message.name}", address: "{message.address}", mail: "{message.mail}" }})''' ,
parameters=None
))
return result_queries
@mgp.transformation
def company_transformation(messages: mgp.Messages) -> mgp.Record(query = str, parameters=mgp.Nullable[mgp.Map]):
result_queries = []
for i in range(messages.total_messages()):
message_pb = messages.message_at(i)
msg_value = message_pb.payload()
message = process_record_protobuf(msg_value, person_pb2.Person)
result_queries.append(mgp.Record (
query=f'''MERGE (c:Company {{ id: ToInteger({message.id}), name: "{message.name}", address: "{message.address}", mail: "{message.mail}" }})''' ,
parameters=None
))
return result_queries
@mgp.transformation
def company_transformation(messages: mgp.Messages) -> mgp.Record(query = str, parameters=mgp.Nullable[mgp.Map]):
result_queries = []
for i in range(messages.total_messages()):
message_pb = messages.message_at(i)
msg_value = message_pb.payload()
message = process_record_protobuf(msg_value, person_pb2.Person)
result_queries.append(mgp.Record (
query=f'''MATCH (p:Person ), (c:Company)
WHERE p.id = "{message.person_id}" AND c.id = "{message.company_id}"
MERGE (p)-[WORKS_AT: {{start_date: date({message.start_date})}}]->(c)''' ,
parameters=None
))
return result_queriesUpon creating three separate streams in Memgraph (one for each topic), and ingesting the data, the graph schema looks like this: