algo
The algo module provides users with a powerful set of graph algorithms, enabling users to perform complex graph-based operations and computations, such as graph traversal, edge detection, and more.
| Trait | Value |
|---|---|
| Module type | algorithm |
| Implementation | C++ |
| Graph direction | directed/undirected |
| Edge weights | weighted/unweighted |
| Parallelism | sequential |
Procedures
You can execute this algorithm on graph projections, subgraphs or portions of the graph.
all_simple_paths()
The procedure returns every simple path (one which does not visit the same node
twice) from start_node to end_node satisfying the given relationship
filters.
Input:
subgraph: Graph(OPTIONAL) ➡ A specific subgraph, which is an object of type Graph returned by theproject()function, on which the algorithm is run. If subgraph is not specified, the algorithm is computed on the entire graph by default.start_node: Node➡ The first node of the returned path.end_node: Node➡ The final node of the returned path.relationship_types: List[String]➡ A list of relationship filters, explained below.max_length: int➡ Max path length.
Output:
path: Path➡ A path which satisfies the given conditions.
Relationship filters:
Relationship filters are described in the table below:
| Option | Explanation |
|---|---|
TYPE | The path will expand with either outgoing or incoming relationships of this type. |
<TYPE | The path will expand with incoming relationships of this type. |
TYPE> | The path will expand with outgoing relationships of this type. |
<TYPE> | The path will expand if both incoming and outgoing relationship of this type exists between the same two nodes. |
> | The path will expand with all outgoing relationships. |
< | The path will expand will all incoming relationships. |
Usage:
Create a graph using the following queries:
CREATE (n1:Node1), (n2:Node2), (n3:Node3), (n4:Node4), (n5:Node5), (n6:Node6)
CREATE (n1)-[r1:CONNECTED]->(n2), (n2)-[r2:CONNECTED]->(n3), (n3)-[r3:CONNECTED]->(n4), (n4)-[r4:CONNECTED]->(n5), (n5)-[r5:CONNECTED]->(n6), (n1)-[r6:CONNECTED]->(n3), (n4)-[r7:CONNECTED]->(n6), (n2)-[r8:CONNECTED]->(n1), (n3)-[r9:CONNECTED]->(n2);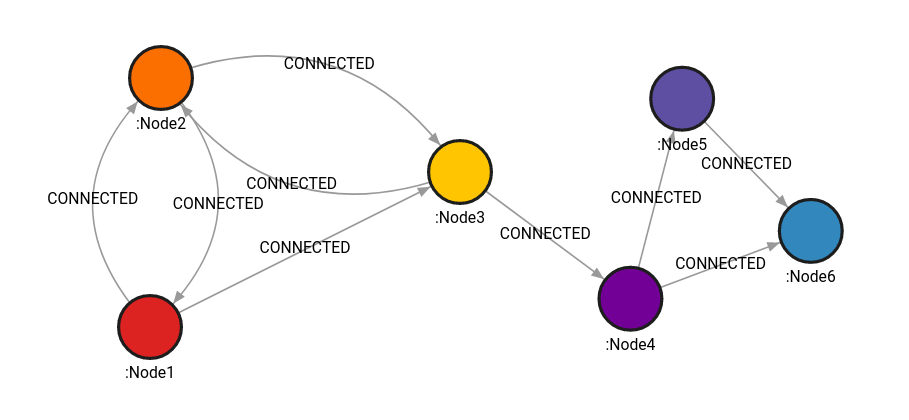
Query which returns all simple paths of maximum length 2 between Node1 and Node3:
MATCH (n:Node1) MATCH (m:Node3)
CALL algo.all_simple_paths(n, m, [], 2)
YIELD path AS result RETURN result;Results:
The procedure will return 4 paths of length 2 and 1 path of length 1 as follows:
{"nodes":[{"id":18,"labels":["Node1"],"properties":{},"type":"node"},{"id":19,"labels":["Node2"],"properties":{},"type":"node"},{"id":20,"labels":["Node3"],"properties":{},"type":"node"}],"relationships":[{"id":32,"start":19,"end":18,"label":"CONNECTED","properties":{},"type":"relationship"},{"id":33,"start":20,"end":19,"label":"CONNECTED","properties":{},"type":"relationship"}],"type":"path"},
{"nodes":[{"id":18,"labels":["Node1"],"properties":{},"type":"node"},{"id":19,"labels":["Node2"],"properties":{},"type":"node"},{"id":20,"labels":["Node3"],"properties":{},"type":"node"}],"relationships":[{"id":32,"start":19,"end":18,"label":"CONNECTED","properties":{},"type":"relationship"},{"id":26,"start":19,"end":20,"label":"CONNECTED","properties":{},"type":"relationship"}],"type":"path"},
{"nodes":[{"id":18,"labels":["Node1"],"properties":{},"type":"node"},{"id":19,"labels":["Node2"],"properties":{},"type":"node"},{"id":20,"labels":["Node3"],"properties":{},"type":"node"}],"relationships":[{"id":25,"start":18,"end":19,"label":"CONNECTED","properties":{},"type":"relationship"},{"id":33,"start":20,"end":19,"label":"CONNECTED","properties":{},"type":"relationship"}],"type":"path"},
{"nodes":[{"id":18,"labels":["Node1"],"properties":{},"type":"node"},{"id":19,"labels":["Node2"],"properties":{},"type":"node"},{"id":20,"labels":["Node3"],"properties":{},"type":"node"}],"relationships":[{"id":25,"start":18,"end":19,"label":"CONNECTED","properties":{},"type":"relationship"},{"id":26,"start":19,"end":20,"label":"CONNECTED","properties":{},"type":"relationship"}],"type":"path"},
{"nodes":[{"id":18,"labels":["Node1"],"properties":{},"type":"node"},{"id":20,"labels":["Node3"],"properties":{},"type":"node"}],"relationships":[{"id":30,"start":18,"end":20,"label":"CONNECTED","properties":{},"type":"relationship"}],"type":"path"}cover()
The procedure returns relationships between every two nodes in the list, including any self-referencing relationships.
Input:
-
subgraph: Graph(OPTIONAL) ➡ A specific subgraph, which is an object of type Graph returned by theproject()function, on which the algorithm is run. If subgraph is not specified, the algorithm is computed on the entire graph by default. -
nodes: List[Node]➡ A list of all the input nodes.
Output:
rel: Relationship➡ A separate record is created for each relationship between nodes, and a relationship is returned.
Usage:
Create a graph using the following query:
CREATE (d:Dog)-[s:SELF_REL]->(d), (d)-[l:LOVES]->(h:Human), (h)-[li:LIVES_IN]->(ho:House);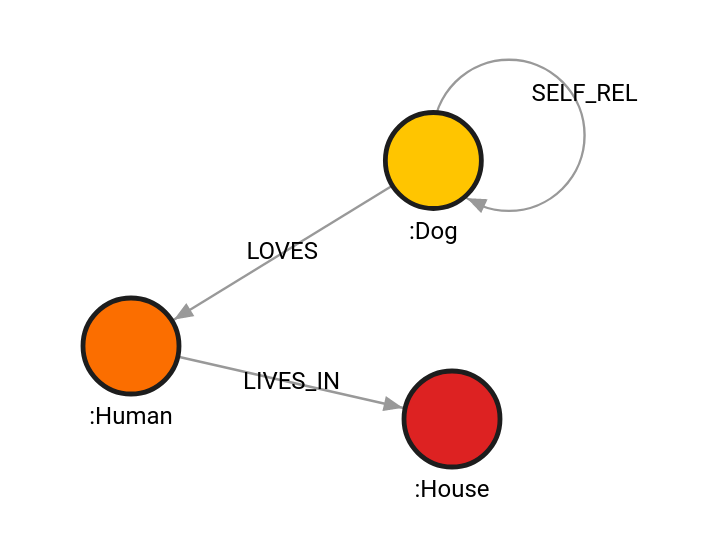
Retrieve relationships between nodes:
MATCH (d:Dog),(ho:House),(h:Human)
CALL algo.cover([d, ho, h]) YIELD rel
RETURN startNode(rel), rel, endNode(rel);Relationships between every two nodes from the input list, including the self-referencing relationship:
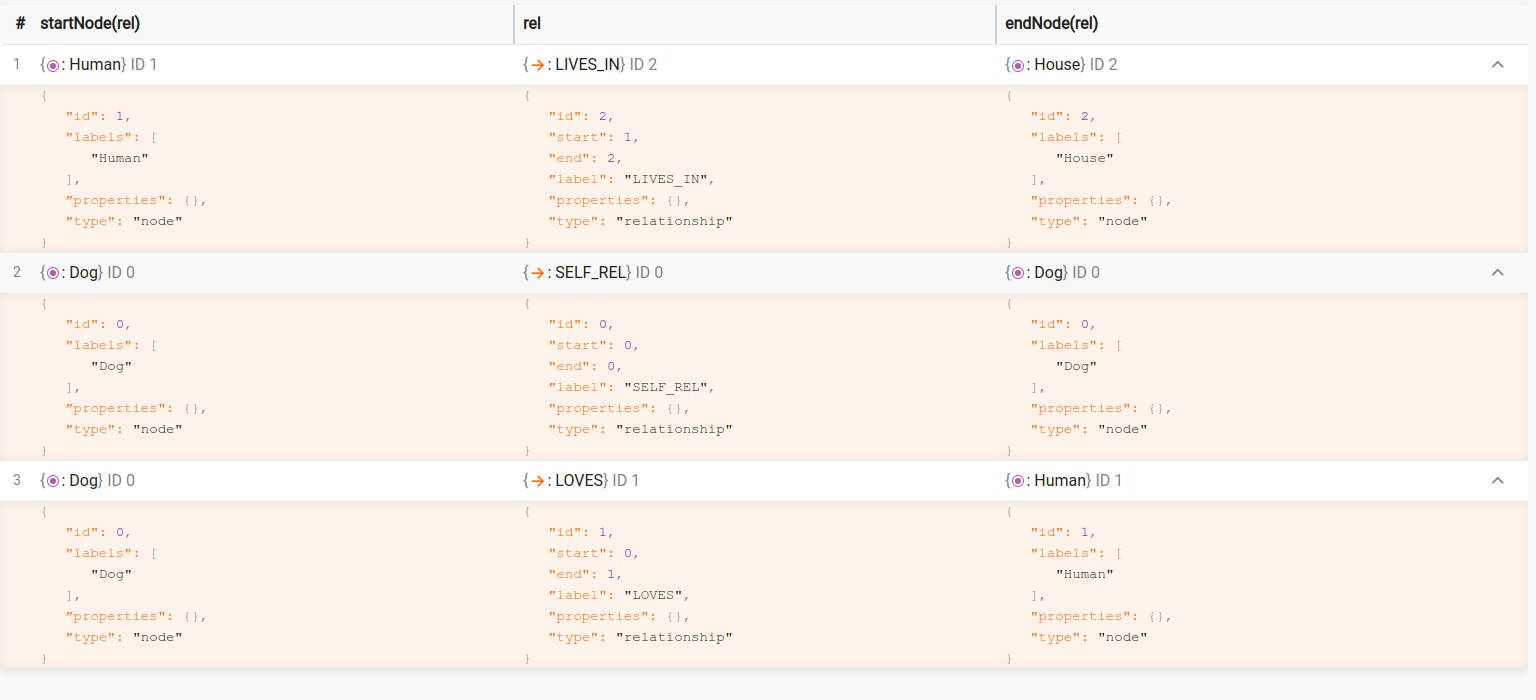
astar()
Runs the A * search algorithm between the start and target node.
Supports either Numeric or Duration data types for distance and heuristic properties.
The default heuristic works with the assumption that the nodes in the graph represent geospatial points and that they have defined properties for latitude and longitude. In that case, the heuristic for each node is haversine distance between the current node and the target node on Earth, and is returned in kilometers.
In case you don’t want to use geospatial types, or you want a custom heuristic, check the supported configuration below.
Input:
subgraph: Graph(OPTIONAL) ➡ A specific subgraph, which is an object of type Graph returned by theproject()function, on which the algorithm is run. If subgraph is not specified, the algorithm is computed on the entire graph by default.start: Node➡ The starting node.target: Node➡ The target node.config: Map➡ The configuration map.
Output:
path: Path➡ The resulting shortest path calculated by the algorithm.weight: float➡ The weight of the shortest path.
Configuration:
To enable the configuration of the procedure, pass the config parameter with
desired values, for example: CALL algo.astar(startNode,targetNode, {configuration_name: configuration_value}).
As some configuration values are obligatory, they have a default value.
distance_prop: string, default = distance- The name of the relationships’ distance property.latitude_name: string, default = lat- The name of the nodes’ latitude property, needed for the heuristic calculation.longitude_name: string, default = lon- The name of the nodes’ longitude property, needed for the heuristic calculation.heuristic_name: string- The name of the custom heuristic property. For example, if you don’t want to use the provided heuristic, you can always define and use a custom heuristic node property. If theheuristic_nameis set to a certain value, the default heuristic is ignored.whitelisted_labels: List[string]- A list of whitelisted labels through which the algorithm will search for the path. For example, by settingwhitelisted_labels: ["City", "Village"]the algorithm will consider only nodes labeledCityorVillage.blacklisted_labels: List[string]- A list of blacklisted labels, which will be ignored by the algorithm when searching for a path. For example, by settingblacklisted_labels: ["City", "Village"]the algorithm will ignore nodes labeledCityorVillage.relationships_filter: List[string]- A list used for filtering relationships. If the list is empty, the algorithm will search for the path through all possible relationships. If the list isn’t empty, the algorithm will search for the path only through the listed relationships. There are three possible ways to define a relationship inside the filter:<REL_NAME>- Only the incoming relationships with the defined name will be considered by the algorithm.REL_NAME>- Only the outgoing relationships with the defined name will be considered by the algorithm.REL_NAME- Both outgoing and incoming relationships with the defined name will be considered by the algorithm.
duration: bool, default = false- Iftrue, means that the distance and heuristic properties are of aDurationdata type. If they are not, but thedurationconfig is specified astrue, an exception is thrown. Also, if this config istrue, theweightoutput will be returned asint, representing the duration in microseconds.unweighted: bool, default = false- Iftrue, the algorithm will ignore the weights, using only heuristics, not distances between nodes. The path weight will still be returned, but all distances will be of the same value 10.epsilon: double, default = 1.0- If an admissible heuristic has been provided, or if the default heuristic is used, you can choose to use the Bounded relaxation property of A *, and multiply the heuristic byepsilonvalue. This will result in a faster algorithm, with a solution at mostepsilontimes worse than the base algorithm.
Usage
The following section demonstrates the following usages of the procedure:
- default usage
- relationship filtering
- blacklisting
- unweighted graph
- custom longitude and latitude names
- custom heuristics
- duration instead of distance.
Graph creation
Use the following queries to create a graph with five City nodes, and four MO nodes. Each node has a defined latitude and longitude properties.
The nodes are connected with ROAD and RIVER type of relationships. Each relationship has a defined distance property.
CREATE (c1:City1 {lat: -1, lon: -1}), (c2:City2 {lat: 1, lon: -11}),
(c3:City3 {lat: 1, lon: 1}), (c4:City4 {lat: -1, lon: 1}), (c5:City5 {lat: 0, lon: 0}),
(m1:MO1 {lat: -0.5, lon: -0.5}), (m2:MO2 {lat: 0.5, lon: -0.5}),
(m3:MO3 {lat: 0.5, lon: 0.5}) ,(m4:MO4 {lat: -0.5, lon: 0.5}),
(c1)-[r1:ROAD {distance: 300}]->(c2),
(c2)-[r2:ROAD {distance: 300}]->(c3),
(c4)-[r3:ROAD {distance: 280}]->(c3),
(c4)-[r4:ROAD {distance: 310}]->(c1),
(c1)-[r5:RIVER {distance: 90}]->(m1),
(c2)-[r6:ROAD {distance: 90}]->(m2),
(c3)-[r7:ROAD {distance: 85}]->(m3),
(c4)-[r8:ROAD {distance: 100}]->(m4),
(m1)-[r9:RIVER {distance: 140}]->(m4),
(m4)-[r10:RIVER {distance: 145}]->(m3),
(m3)-[r11:RIVER {distance: 130}]->(m2),
(m2)-[r12:RIVER {distance: 125}]->(m1),
(m2)-[r13:ROAD {distance: 90}]->(c5),
(m3)-[r14:RIVER {distance: 100}]->(c5)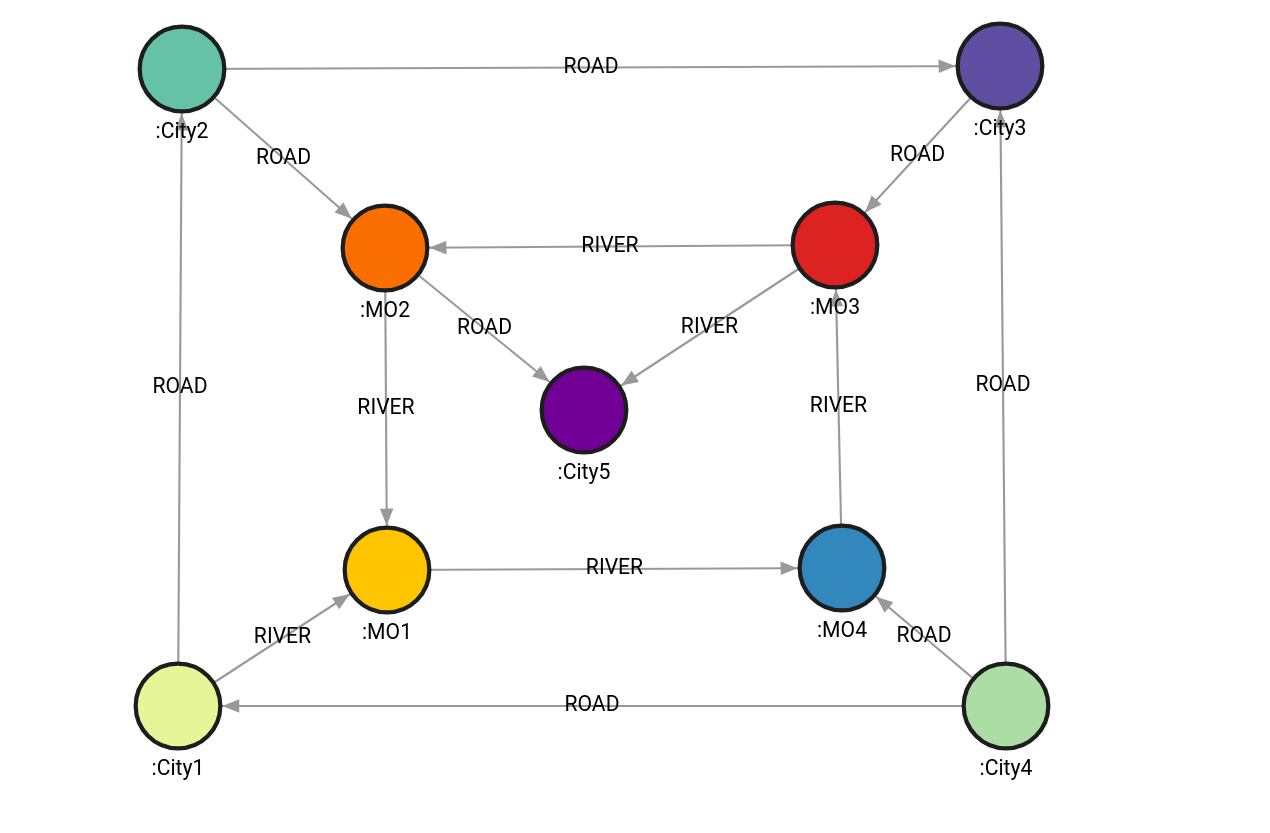
Default usage
Since the distance property is named distance, and latitude and longitude properties are named lat and lon, a config map is unnecessary, and the algorithm can be run without it.
MATCH (c1:City1), (c5:City5)
CALL algo.astar(c1,c5, {}) YIELD path, weight
RETURN path, weight;Result:
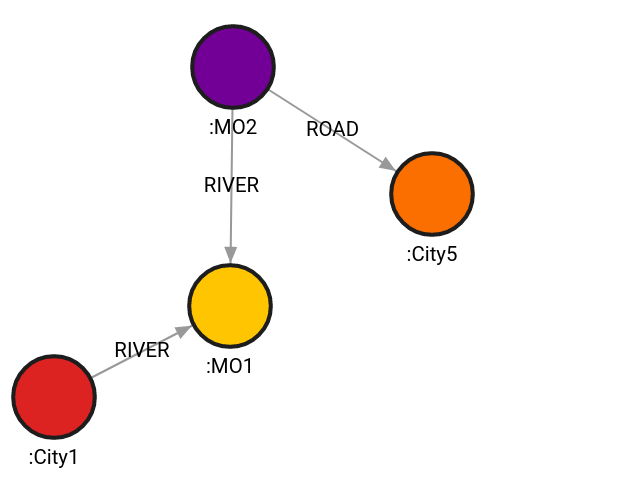
+----------------------------+
| weight |
+----------------------------+
| 305 |
+----------------------------+Usage with relationship filtering
The following query will find the path by considering only the outgoing relationships of type RIVER:
MATCH (c1:City1), (c5:City5 )
CALL algo.astar(c1,c5, {relationships_filter:["RIVER>"]})
YIELD path, weight
RETURN path, weight;Result:
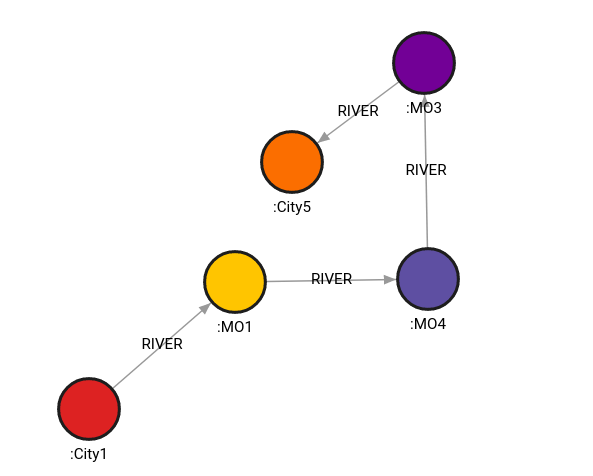
+----------------------------+
| weight |
+----------------------------+
| 475 |
+----------------------------+Usage with blacklisting
The following query will find the path by ignoring nodes labeled MO1, MO2, MO3:
MATCH (c1:City1), (c5:City5)
CALL algo.astar(c1,c5, {blacklisted_labels: ["MO1", "MO2","MO4"]})
YIELD path, weight
RETURN path, weight;Result:
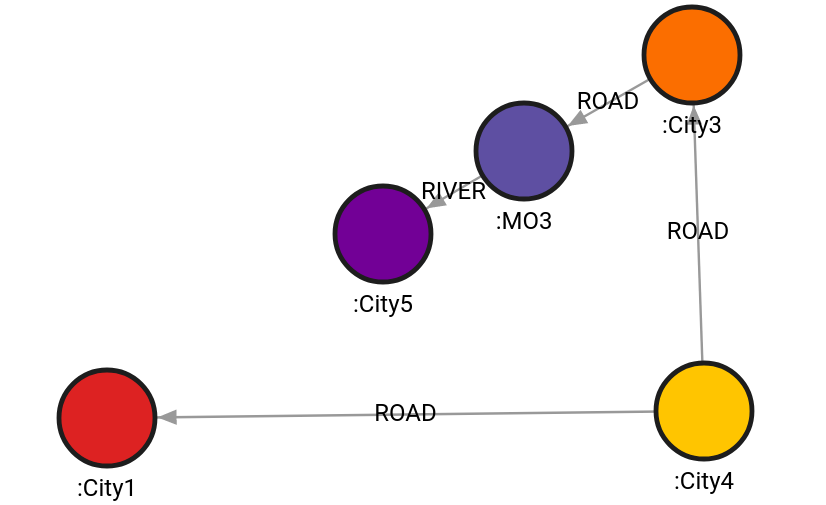
+----------------------------+
| weight |
+----------------------------+
| 775 |
+----------------------------+Usage with unweigthed
In this case, the algorithm will ignore the distance property, and treat every relationship as having a distance of 10.
MATCH (c1:City1), (c5:City5)
CALL algo.astar(c1,c5, {unweighted: true})
YIELD path, weight
RETURN path, weight;Result:
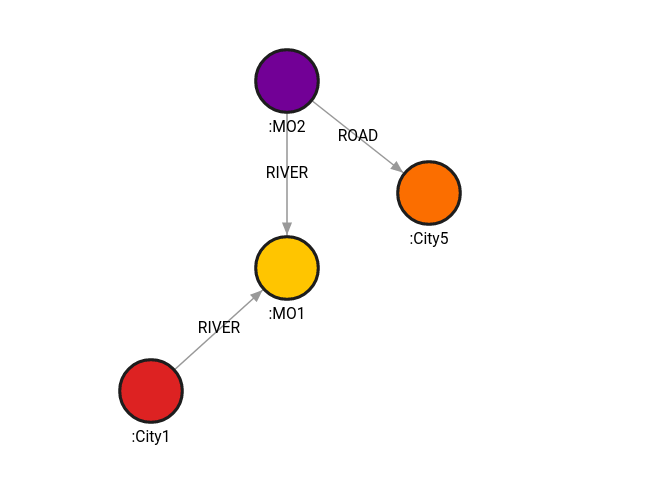
+----------------------------+
| weight |
+----------------------------+
| 30 |
+----------------------------+Custom latitude, longitude and distance name
Use the following queries to create a graph with five City nodes, and four MO nodes. Each node has defined latitude and longitude properties but with names the algorithm doesn’t consider as default names (lat and lon).
The nodes are connected with ROAD and RIVER type of relationships. Each relationship has a defined separation property.
CREATE
(c1:City1 {latitude: -1, longitude: -1}),
(c2:City2 {latitude: 1, longitude: -1}),
(c3:City3 {latitude: 1, longitude: 1}),
(c4:City4 {latitude: -1, longitude: 1}),
(c5:City5 {latitude: 0, longitude: 0}),
(m1:MO1 {latitude: -0.5, longitude: -0.5}),
(m2:MO2 {latitude: 0.5, longitude: -0.5}),
(m3:MO3 {latitude: 0.5, longitude: 0.5}),
(m4:MO4 {latitude: -0.5, longitude: 0.5}),
(c1)-[r1:ROAD {separation: 300}]->(c2),
(c2)-[r2:ROAD {separation: 300}]->(c3),
(c4)-[r3:ROAD {separation: 280}]->(c3),
(c4)-[r4:ROAD {separation: 310}]->(c1),
(c1)-[r5:RIVER {separation: 90}]->(m1),
(c2)-[r6:ROAD {separation: 90}]->(m2),
(c3)-[r7:ROAD {separation: 85}]->(m3),
(c4)-[r8:ROAD {separation: 100}]->(m4),
(m1)-[r9:RIVER {separation: 140}]->(m4),
(m4)-[r10:RIVER {separation: 145}]->(m3),
(m3)-[r11:RIVER {separation: 130}]->(m2),
(m2)-[r12:RIVER {separation: 125}]->(m1),
(m2)-[r13:ROAD {separation: 90}]->(c5),
(m3)-[r14:RIVER {separation: 100}]->(c5);Search the path by adjusting the procedure to use non-default names for longitude, latitude and distance:
MATCH (c1:City1 ), (c5:City5 )
CALL algo.astar(c1,c5, {distance_prop:"separation", latitude_name: "latitude", longitude_name:"longitude"})
YIELD path, weight
RETURN path, weight;Result:
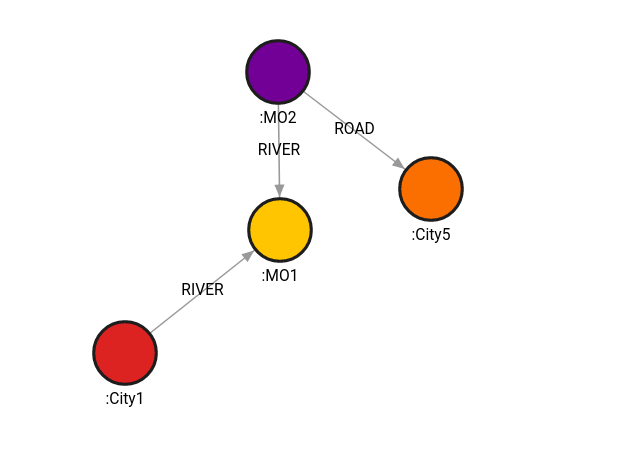
+----------------------------+
| weight |
+----------------------------+
| 305 |
+----------------------------+Usage with custom heuristic
Use the following queries to create a graph with five City nodes, and four MO nodes. Each node has manually calculated Haversine distance, saved under heur property.
The nodes are connected with ROAD and RIVER type of relationships. Each relationship has a defined distance property.
CREATE (c1:City1 {heur: 157.2}), (c2:City2 {heur: 157.2}), (c3:City3 {heur: 157.2}),
(c4:City4 {heur: 157.2}),
(c5:City5 {heur: 0}),
(m1:MO1 {heur: 78.62}), (m2:MO2 {heur: 78.62}),
(m3:MO3 {heur: 78.62}) ,(m4:MO4 {heur: 78.62}),
(c1)-[r1:ROAD {distance: 300}]->(c2),
(c2)-[r2:ROAD {distance: 300}]->(c3),
(c4)-[r3:ROAD {distance: 280}]->(c3),
(c4)-[r4:ROAD {distance: 310}]->(c1),
(c1)-[r5:RIVER {distance: 90}]->(m1),
(c2)-[r6:ROAD {distance: 90}]->(m2),
(c3)-[r7:ROAD {distance: 85}]->(m3),
(c4)-[r8:ROAD {distance: 100}]->(m4),
(m1)-[r9:RIVER {distance: 140}]->(m4),
(m4)-[r10:RIVER {distance: 145}]->(m3),
(m3)-[r11:RIVER {distance: 130}]->(m2),
(m2)-[r12:RIVER {distance: 125}]->(m1),
(m2)-[r13:ROAD {distance: 90}]->(c5),
(m3)-[r14:RIVER {distance: 100}]->(c5)As this graph isn’t using the default heuristic the config map must include the heuristic_name property.
MATCH (c1:City1 ), (c5:City5 )
CALL algo.astar(c1,c5, {heuristic_name: "heur"})
YIELD path, weight
RETURN path, weight;Result:
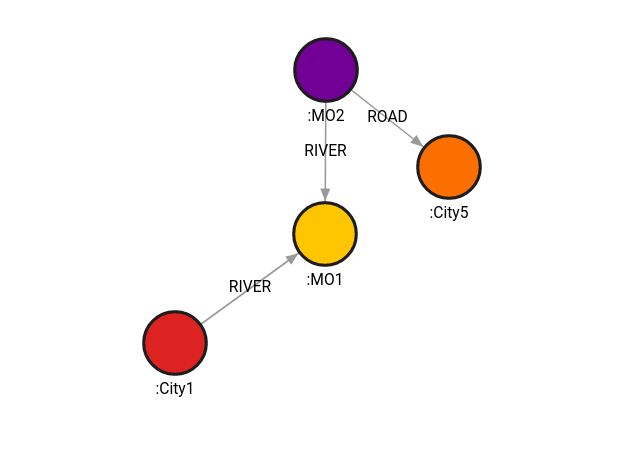
+----------------------------+
| weight |
+----------------------------+
| 305 |
+----------------------------+Usage with duration
Use the following queries to create a graph with five City nodes, and four MO nodes. Each node’s heur property is of type Duration.
The nodes are connected with ROAD and RIVER type of relationships. Each relationship has a defined distance property of type Duration.
CREATE (c1:City1 {heur: duration("PT1H30M")}), (c2:City2 {heur: duration("PT1H30M")}), (c3:City3 {heur: duration("PT1H30M")}),
(c4:City4 {heur: duration("PT1H30M")}),
(c5:City5 {heur: duration("PT0H")}),
(m1:MO1 {heur: duration("PT47M")}), (m2:MO2 {heur: duration("PT47M")}),
(m3:MO3 {heur: duration("PT47M")}) ,(m4:MO4 {heur: duration("PT47M")}),
(c1)-[r1:ROAD {distance: duration("PT3H")}]->(c2),
(c2)-[r2:ROAD {distance: duration("PT3H")}]->(c3),
(c4)-[r3:ROAD {distance: duration("PT2H48M")}]->(c3),
(c4)-[r4:ROAD {distance: duration("PT3H6M")}]->(c1),
(c1)-[r5:RIVER {distance: duration("PT54M")}]->(m1),
(c2)-[r6:ROAD {distance: duration("PT54M")}]->(m2),
(c3)-[r7:ROAD {distance: duration("PT51M")}]->(m3),
(c4)-[r8:ROAD {distance: duration("PT1H")}]->(m4),
(m1)-[r9:RIVER {distance: duration("PT1H24M")}]->(m4),
(m4)-[r10:RIVER {distance: duration("PT1H27M")}]->(m3),
(m3)-[r11:RIVER {distance: duration("PT1H18M")}]->(m2),
(m2)-[r12:RIVER {distance: duration("PT1H15M")}]->(m1),
(m2)-[r13:ROAD {distance: duration("PT54M")}]->(c5),
(m3)-[r14:RIVER {distance: duration("PT1H")}]->(c5)
As the node is not using the default names for the heuristic properties, and they, as well as distances, are of type Duration rather than the default Number data type, they need to be specified in the configuration map.
Also, the query searches for a path using only RIVER relationships, both incoming and outgoing.
alongside other properties.
MATCH (c1:City1 ), (c5:City5 )
CALL algo.astar(c1,c5, {heuristic_name: "heur", duration: true, relationships_filter: ["RIVER"]})
YIELD path, weight
RETURN path, weight;Result:
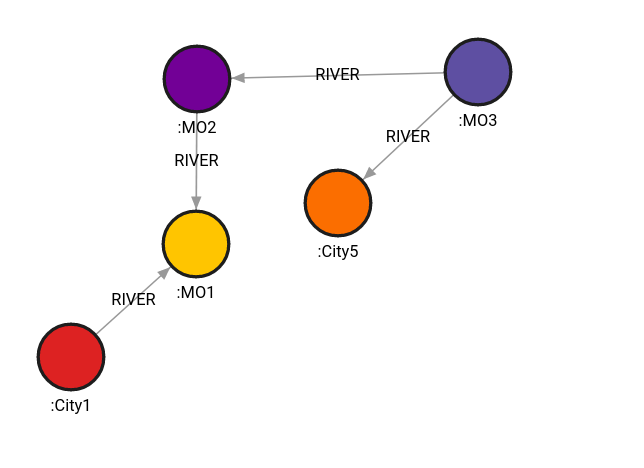
+----------------------------+
| weight |
+----------------------------+
| 16,020,000,000 |
+----------------------------+