refactor
The refactor module provides utilities for changing nodes and relationships.
| Trait | Value |
|---|---|
| Module type | util |
| Implementation | C++ |
| Parallelism | sequential |
Procedures
You can execute this algorithm on graph projections, subgraphs or portions of the graph.
from()
Redirect the relationship to use a new start (from) node.
This procedure is equivalent to apoc.refactor.from.
Input:
-
subgraph: Graph(OPTIONAL) ➡ A specific subgraph, which is an object of type Graph returned by theproject()function, on which the algorithm is run. If subgraph is not specified, the algorithm is computed on the entire graph by default. -
relationship: Relationship➡ Relationship that needs to be modified. -
new_from: Node➡ THe new start (from) node.
Output:
relationship- The modified relationship.
Usage:
The database contains the following data:
MERGE (ivan:Person {name: "Ivan"}) MERGE (matija:Person {name: "Matija"}) MERGE (diora:Person {name:"Idora"}) CREATE (ivan)-[:Friends]->(matija);The following query changes the the relationship Ivan ➡ Matija to Idora ➡ Matija:
MATCH (:Person {name: "Ivan"})-[rel:Friends]->(:Person {name: "Matija"}) MATCH (idora: Person {name:"Idora"}) CALL refactor.from(rel, idora) YIELD relationship RETURN relationship;to()
Redirect the relationship to use a new end (to) node.
This procedure is equivalent to apoc.refactor.to.
Input:
-
subgraph: Graph(OPTIONAL) ➡ A specific subgraph, which is an object of type Graph returned by theproject()function, on which the algorithm is run. If subgraph is not specified, the algorithm is computed on the entire graph by default. -
relationship: Relationship➡ Relationship that needs to be modified. -
new_to: Node➡ The new end (to) node.
Output:
relationship- The modified relationship.
Usage:
The database contains the following data:
MERGE (ivan:Person {name: "Ivan"}) MERGE (matija:Person {name: "Matija"})
MERGE (diora:Person {name:"Idora"}) CREATE (ivan)-[:Friends]->(matija);The following query changes the the relationship Ivan ➡ Matija to Ivan ➡ Idora:
MATCH (:Person {name: "Ivan"})-[rel:Friends]->(:Person {name: "Matija"})
MATCH (idora: Person {name:"Idora"}) CALL refactor.to(rel, idora)
YIELD relationship
RETURN relationship;rename_label()
Rename a label from old_label to new_label for all nodes. If nodes is
provided renaming is applied only to the given nodes. If a node doesn’t contain
the old_label the procedure doesn’t modify it.
This procedure is equivalent to apoc.refactor.rename.label.
Input:
-
subgraph: Graph(OPTIONAL) ➡ A specific subgraph, which is an object of type Graph returned by theproject()function, on which the algorithm is run. If subgraph is not specified, the algorithm is computed on the entire graph by default. -
old_label: str➡ The old label name. -
new_label: str➡ The new label name. -
nodes: List[Node]➡ The list of nodes to be modified.
Output:
nodes_changed: int➡ The number of modified nodes.
Usage:
The database contains the following data:
CREATE (:Node1 {title: "Node1"})
CREATE (:Node2 {title: "Node2"})
CREATE (:Node1);The following query changes the label of the first node to Node:
MATCH (n)
WITH collect(n) AS nodes
CALL refactor.rename_label("Node1", "Node3", nodes)
YIELD nodes_changed
RETURN nodes_changed;Result:
+----------------------------+
| nodes_changed |
+----------------------------+
| 2 |
+----------------------------+rename_node_property()
Rename a property from old_property to new_property for all nodes. If
nodes is provided renaming is applied only to the given nodes. If a node
doesn’t contain the old_property the procedure doesn’t modify it.
This procedure is equivalent to apoc.refactor.rename.nodeProperty.
Input:
-
subgraph: Graph(OPTIONAL) ➡ A specific subgraph, which is an object of type Graph returned by theproject()function, on which the algorithm is run. If subgraph is not specified, the algorithm is computed on the entire graph by default. -
old_property: str➡ The old property name. -
new_label: str➡ The new property name. -
nodes: List[Node]➡ The list of nodes to be modified.
Output:
nodes_changed: int➡ The number of modified nodes.
Usage:
CREATE (:Node1 {title: "Node1"})
CREATE (:Node2 {description: "Node2"})
CREATE (:Node3) CREATE (:Node4 {title: "title", description: "description"});The following query will modify Node1 and Node4:
MATCH (n)
WITH collect(n) AS nodes
CALL refactor.rename_node_property("title", "description", nodes)
YIELD nodes_changed
RETURN nodes_changed;Result:
+----------------------------+
| nodes_changed |
+----------------------------+
| 2 |
+----------------------------+categorize()
Generates a new category of nodes based on a specific property key from the existing nodes in the graph. Then, it creates relationships between the original and new category nodes to organize a graph based on these categories.
Input:
-
subgraph: Graph(OPTIONAL) ➡ A specific subgraph, which is an object of type Graph returned by theproject()function, on which the algorithm is run. If subgraph is not specified, the algorithm is computed on the entire graph by default. -
original_prop_key: string➡ The property key on the existing nodes used to determine the category. -
rel_type: string➡ The type of relationship to be created between the original nodes and the new category nodes. -
is_outgoing: bool➡ Determines the direction of the new relationships. Iftrue, relationships will be created from the original node to the category node. Iffalse, they’ll be created from the category node to the original node. -
new_label: string➡ The label to be assigned to the new category nodes. -
new_prop_name_key: string➡ The key for the new category node’s property whose value will be the same asoriginal_prop_keyvalue. -
copy_props_list: List[string] (default = [])➡ An array of property keys from the original nodes to be copied to the new category nodes.
Output:
status: string➡ Returnssuccessif no errors were generated.
Usage:
CALL refactor.categorize('genre', 'GENRE', false, "Genre", "name")
YIELD status
RETURN status;Results:
+----------------------------+
| status |
+----------------------------+
| success |
+----------------------------+Example:
The database contains the following data:

Created with the following Cypher queries:
CREATE (a:Movie {id: 0, name: "MovieName", genre: "Drama"})
CREATE (b:Book {id: 1, name: "BookName1", genre: "Drama", propertyToCopy: "copy me"})
CREATE (c:Book {id: 2, name: "BookName2", genre: "Romance"});Categorize the graph:
CALL refactor.categorize('genre', 'GENRE', true, "Genre", "name", ["propertyToCopy"])
YIELD status
RETURN status;The graph now looks like this:
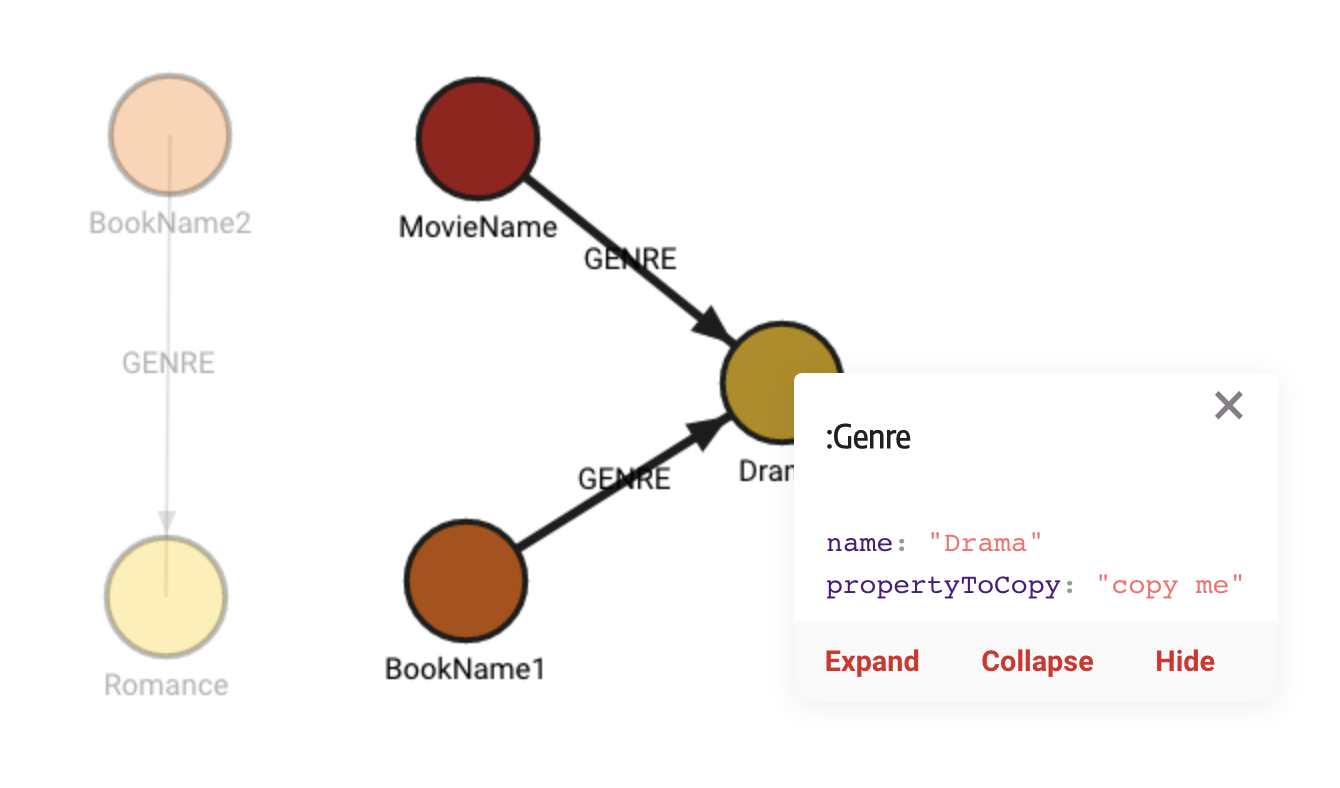
clone_nodes()
Clones specific nodes in the graph, preserving their original labels, properties and optionally relationships. Offers the flexibility to exclude specific node properties during the cloning process.
This procedure is equivalent to apoc.refactor.cloneNodes.
Input:
-
subgraph: Graph(OPTIONAL) ➡ A specific subgraph, which is an object of type Graph returned by theproject()function, on which the algorithm is run. If subgraph is not specified, the algorithm is computed on the entire graph by default. -
nodes: List[Node]➡ A list of nodes intended for duplication. -
withRelationships: bool (default = false)➡ If set totrue, the function will also clone the relationships of the original nodes, connecting them to the cloned nodes in the same manner. -
skipProperties: List[string] (default = [])➡ A list of property keys, properties associated with these keys will be skipped during the cloning process.
Output:
input: int➡ ID of the original node which was cloned.output: Node➡ The new cloned node.
Usage:
Use the following query to clone nodes:
MATCH (a:Person {name: "Ana", age: 22, id:0})
CALL refactor.clone_nodes([a], False, ["age", "id"])
YIELD input, output
RETURN input, output;Result:
+----------------------------+----------------------------+
| input | output |
+----------------------------+----------------------------+
| 0 | { |
| | "id": 1, |
| | "labels": [ |
| | "Person" |
| | ], |
| | "properties": { |
| | name: "Ana" |
| | }, |
| | "type": "node" |
| | } |
+----------------------------+----------------------------+Example:
The database contains the following data:
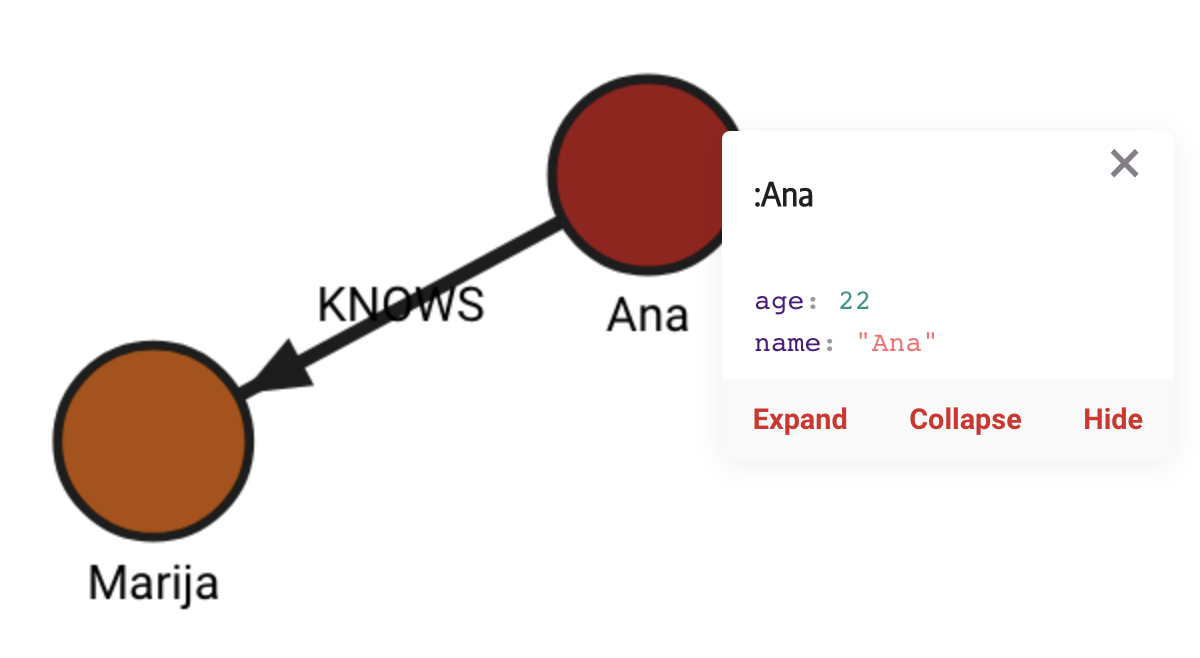
Created with the following Cypher queries:
CREATE (a:Ana {name: "Ana", age: 22})
CREATE (b:Marija {name: "Marija", age: 20})
CREATE (a)-[r:KNOWS]->(b);Clone the nodes using the following nodes:
MATCH (a:Ana) MATCH (b:Marija)
CALL refactor.clone_nodes([a, b], True, ["age"])
YIELD input, output
RETURN input, output;The graph now looks like this:
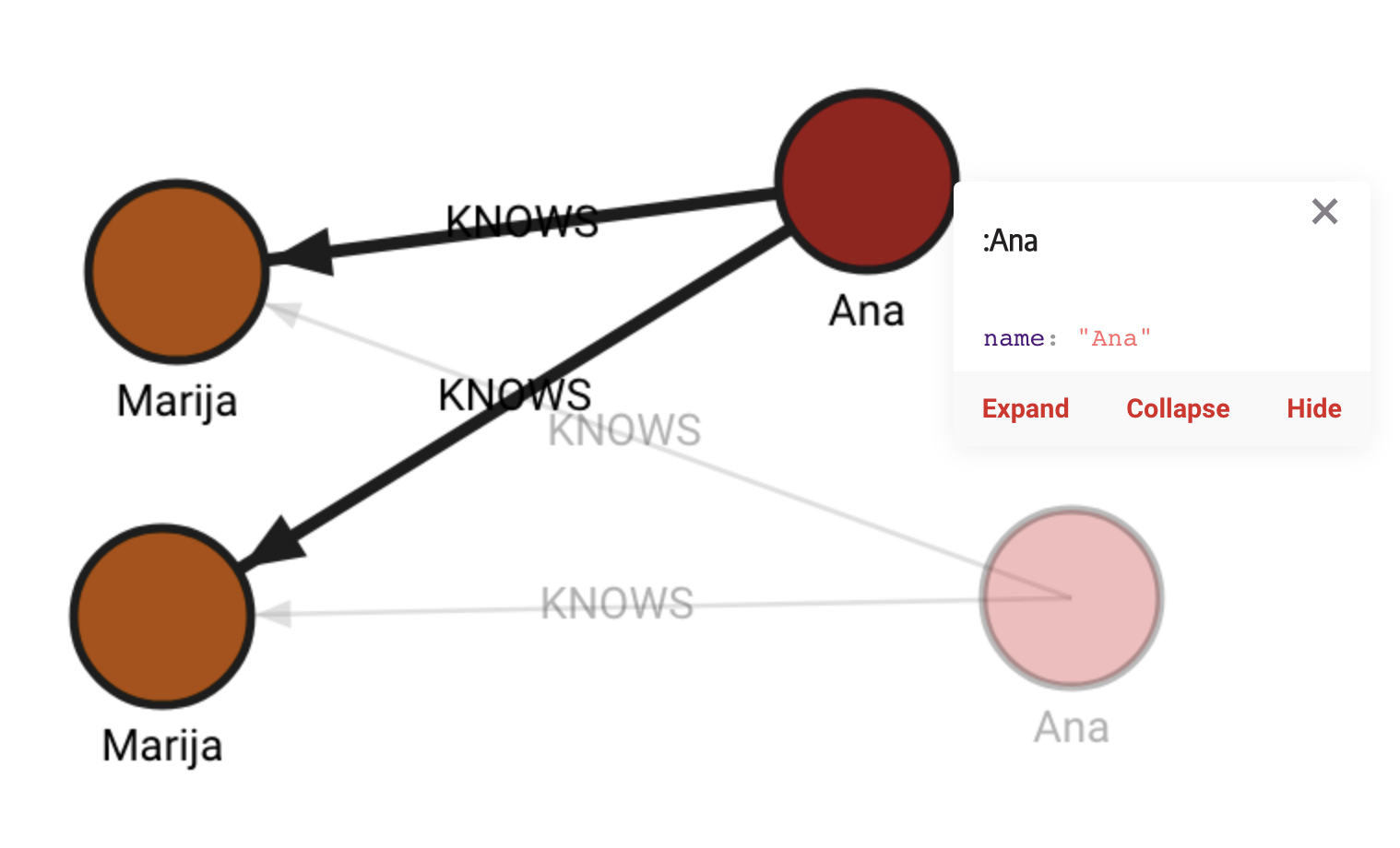
clone_subgraph()
Clones the subgraph by cloning the given list of nodes and relationships. If no relationships are provided, all existing relationships between the given nodes will be cloned.
This procedure is equivalent to apoc.refactor.cloneSubgraph.
Input:
-
subgraph: Graph(OPTIONAL) ➡ A specific subgraph, which is an object of type Graph returned by theproject()function, on which the algorithm is run. If subgraph is not specified, the algorithm is computed on the entire graph by default. -
nodes: List[Node]➡ A list of nodes which form the subgraph intended for duplication. -
rels: List[Relationship] (default = [])➡ A list of relationships intended for duplication. If this list is empty or not provided, all existing relationships between the given nodes will be cloned. -
config: Map (default = {})➡ Configuration parameters explained below.
Parameters:
| Name | Type | Default | Description |
|---|---|---|---|
| skipProperties | List | [ ] | A list of property keys. Properties associated with these keys will be skipped during the cloning process. Therefore, new nodes will not have them. |
| standinNodes | List | [ ] | A list of pairs (lists with only two elements) where the first element is the original node (from the input nodes list) that you’re planning to clone and the second element is an existing node in the graph that will “stand in” or replace the clone of the original node in the resultant subgraph. |
Output:
input: int➡ ID of the original node which was cloned.output: Node➡ The new cloned node.
Usage:
Use the following query to clone the subgraph:
MATCH (ana:Ana {id: 0}), (marija:Marija {id: 1})
MATCH (ana)-[r1:KNOWS]->(marija)
CALL refactor.clone_subgraph([ana, marija], [r1], {standinNodes: [[ana, marija]]})
YIELD input, output
RETURN input, output;Result:
+----------------------------+----------------------------+
| input | output |
+----------------------------+----------------------------+
| 1 | { |
| | "id": 2, |
| | "labels": [ | -> node :Ana was not cloned
| | "Marija" | because :Marija is its
| | ], | "stand-in" node
| | "properties": {}, |
| | "type": "node" |
| | } |
+----------------------------+----------------------------+Example:
The database contains the following data:
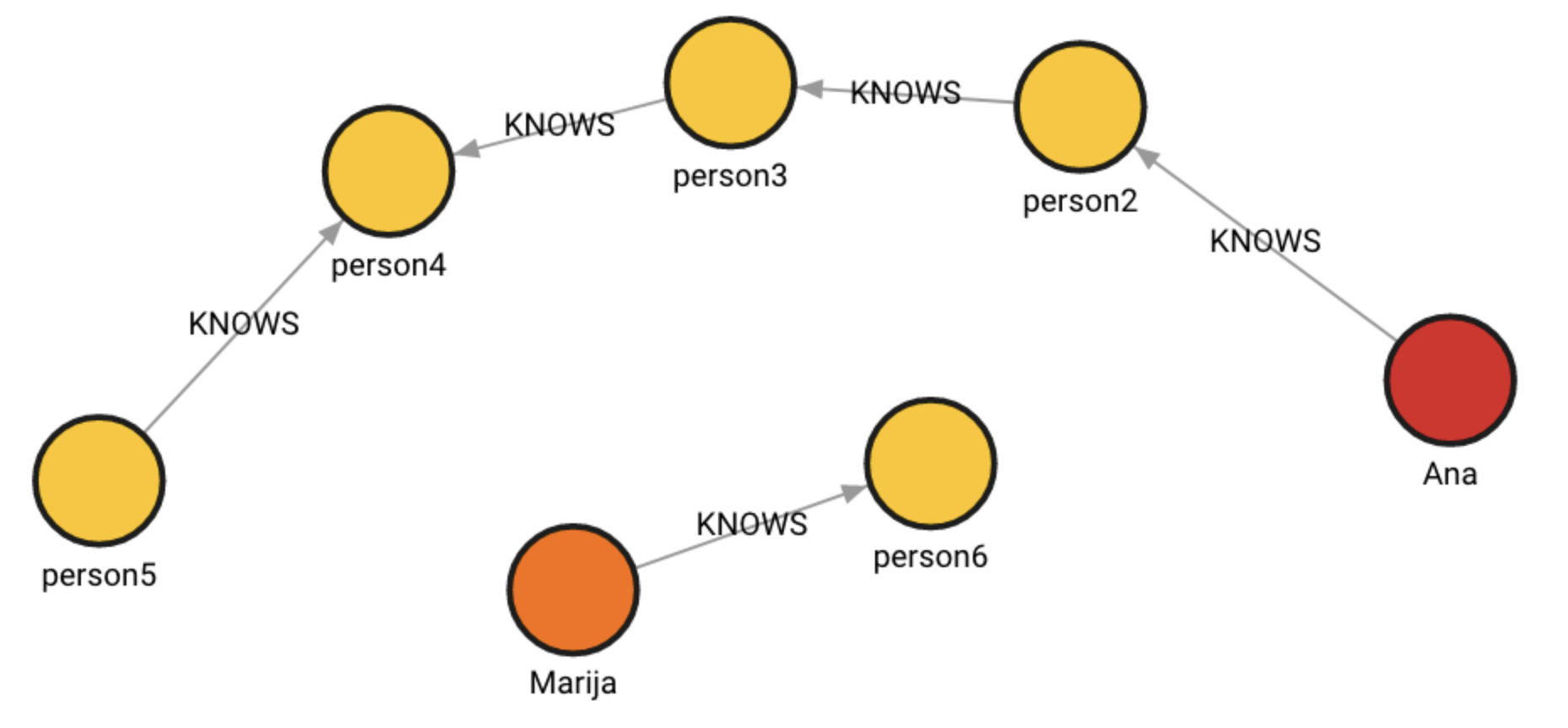
Created with the following Cypher queries:
MERGE (ana:Ana{name:'Ana'})
MERGE (marija:Marija{name:'Marija'})
MERGE (p2:Person{name:'person2'})
MERGE (p3:Person{name:'person3'})
MERGE (p4:Person{name:'person4'})
MERGE (p5:Person{name:'person5'})
MERGE (p6:Person{name:'person6'})
CREATE (ana)-[:KNOWS]->(p2)-[:KNOWS]->(p3)-[:KNOWS]->(p4)
CREATE (p4)<-[:KNOWS]-(p5)
CREATE (marija)-[:KNOWS]->(p6);Clone the subgraph:
MATCH (ana:Ana),
(p2:Person{name: "person2"}),
(p3:Person{name: "person3"}),
(p4:Person{name: "person4"}),
(p5:Person{name: "person5"})
CALL refactor.clone_subgraph([ana, p2, p3, p4, p5], [], {
standinNodes:[[ana, marija]]
})
YIELD input, output
RETURN input, output;The whole subgraph was cloned except for node :Ana because node :Marija was
used as its “stand-in” node.
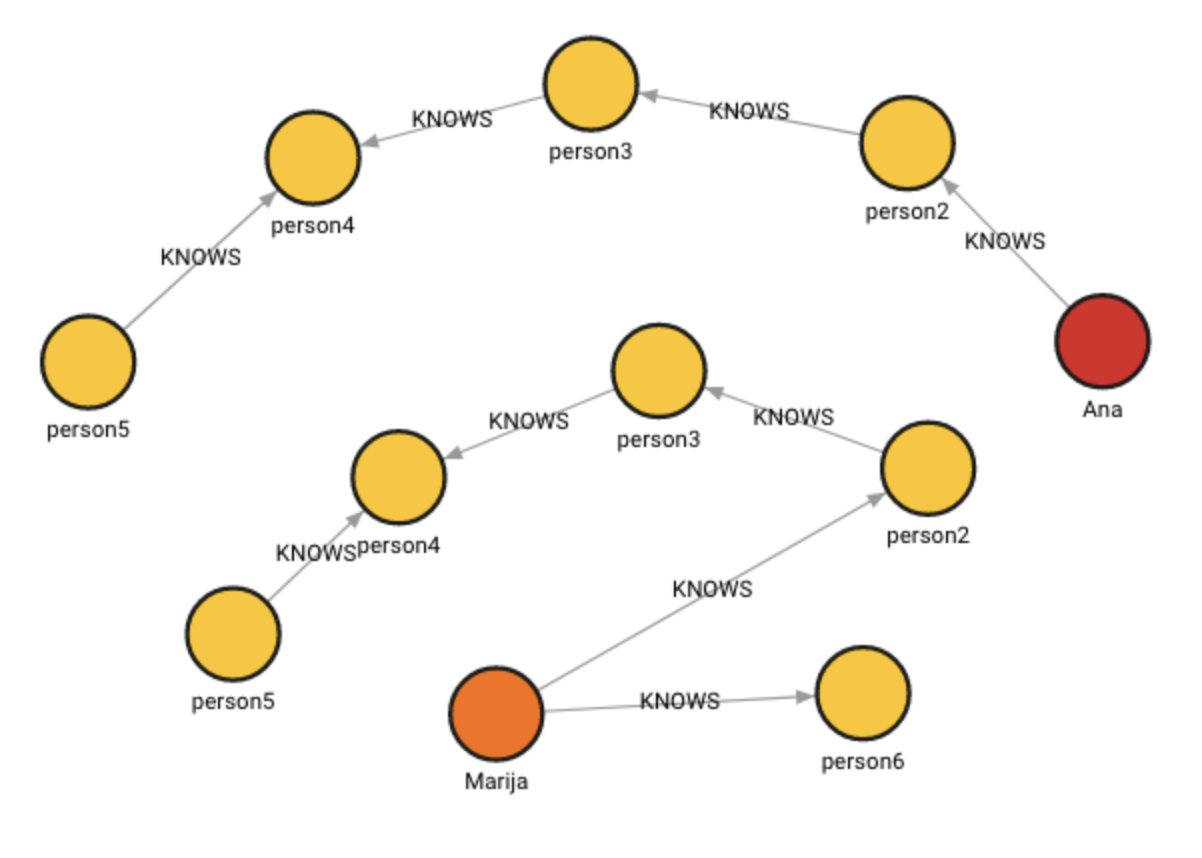
clone_subgraph_from_paths()
Clones the subgraph specified by a specific list of paths. A path is a series of nodes connected by relationships.
This procedure is equivalent to apoc.refactor.cloneSubgraphFromPaths.
Input:
-
subgraph: Graph(OPTIONAL) ➡ A specific subgraph, which is an object of type Graph returned by theproject()function, on which the algorithm is run. If subgraph is not specified, the algorithm is computed on the entire graph by default. -
paths: List[Path]➡ A list of paths which define the subgraph intended for duplication. -
config: Map (default = {})➡ Configuration parameters explained below.
Parameters:
| Name | Type | Default | Description |
|---|---|---|---|
| skipProperties | List | [ ] | A list of property keys. Properties associated with these keys will be skipped during the cloning process. Therefore, new nodes will not have them. |
| standinNodes | List | [ ] | A list of pairs (lists with only two elements) where the first element is the original node (from the input nodes list) that you’re planning to clone, and the second element is an existing node in the graph that will “stand-in” or replace the clone of the original node in the resultant subgraph. |
Input:
-
subgraph: Graph(OPTIONAL) ➡ A specific subgraph, which is an object of type Graph returned by theproject()function, on which the algorithm is run. If subgraph is not specified, the algorithm is computed on the entire graph by default. -
input: int➡ ID of the original node which was cloned. -
output: Node➡ The new cloned node.
Usage:
Clone a subgraph from paths:
MATCH (ana:Ana {id: 0}), (marija:Marija {id: 1})
MATCH path = (ana)-[:KNOWS*]->(marija)
CALL refactor.clone_subgraph_from_paths([path], {standinNodes:[[ana, marija]]})
YIELD input, output RETURN input, output;Results:
+----------------------------+----------------------------+
| input | output |
+----------------------------+----------------------------+
| 1 | { |
| | "id": 2, |
| | "labels": [ | -> node :Ana was not cloned
| | "Marija" | because :Marija is its
| | ], | "stand-in" node
| | "properties": {}, |
| | "type": "node" |
| | } |
+----------------------------+----------------------------+Example
The database contains the following data:
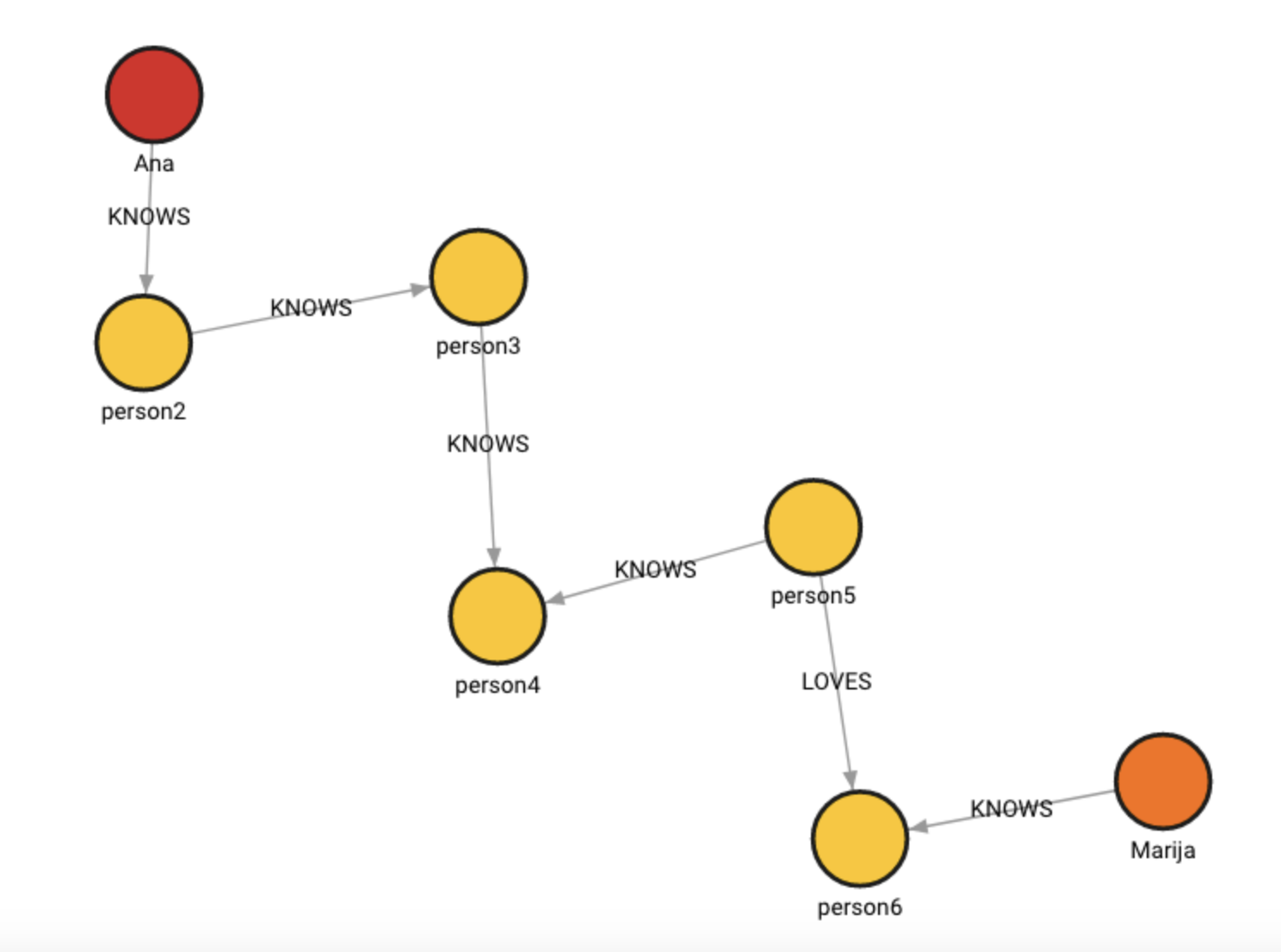
Created with the following Cypher queries:
MERGE (ana:Ana{name:'Ana'})
MERGE (marija:Marija{name:'Marija'})
MERGE (p2:Person{name:'person2'})
MERGE (p3:Person{name:'person3'})
MERGE (p4:Person{name:'person4'})
MERGE (p5:Person{name:'person5'})
MERGE (p6:Person{name:'person6'})
CREATE (ana)-[:KNOWS]->(p2)-[:KNOWS]->(p3)-[:KNOWS]->(p4)
CREATE (p4)<-[:KNOWS]-(p5) CREATE (p5)-[:LOVES]->(p6)
CREATE (marija)-[:KNOWS]->(p6);Clone a subgraph:
MATCH (ana:Ana),
(marija:Marija)
MATCH path = (ana)-[:KNOWS*]->(node)
WITH ana, marija, collect(path) as paths
CALL refactor.clone_subgraph_from_paths(paths, {
standinNodes:[[ana, marija]]
})
YIELD input, output
RETURN input, output;Note that the whole subgraph was cloned except for the node :Ana because node
:Marija was used as its “stand-in” node.
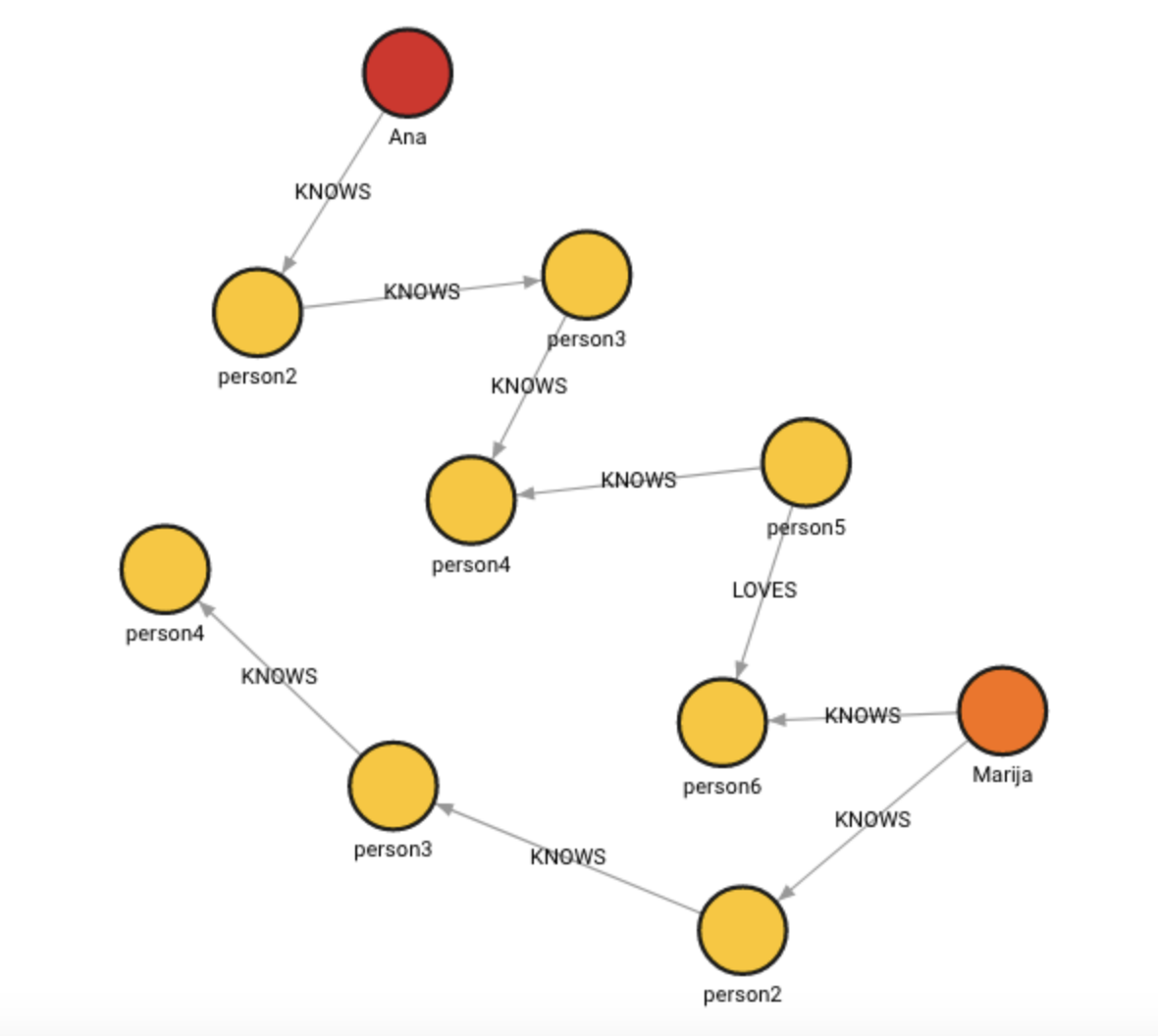
collapse_node()
Collapses a node into a relationship. The procedure can only collapse nodes with exactly 1 in relationship, and exactly 1 out relationship. The node must not have any self relationships. Collapsing any node that doesn’t satisfy these requirements results in an exception.
This procedure is equivalent to apoc.refactor.collapseNode.
Input:
-
subgraph: Graph(OPTIONAL) ➡ A specific subgraph, which is an object of type Graph returned by theproject()function, on which the algorithm is run. If subgraph is not specified, the algorithm is computed on the entire graph by default. -
nodes: Any➡ A node, node ID, or list of nodes and node IDs. -
type: string➡ The type of the new relationship.
Output:
id_collapsed: integer➡ ID of the collapsed node.new_relationship: integer➡ The newly created relationship.
Usage:
Create the following graph:
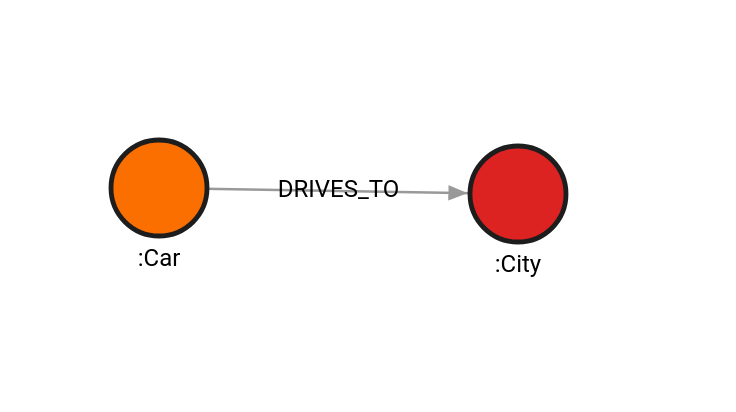
CREATE (c:Car)-[t:DRIVES_ON]->(r:Road)-[l:LEADS_TO]->(ci:City);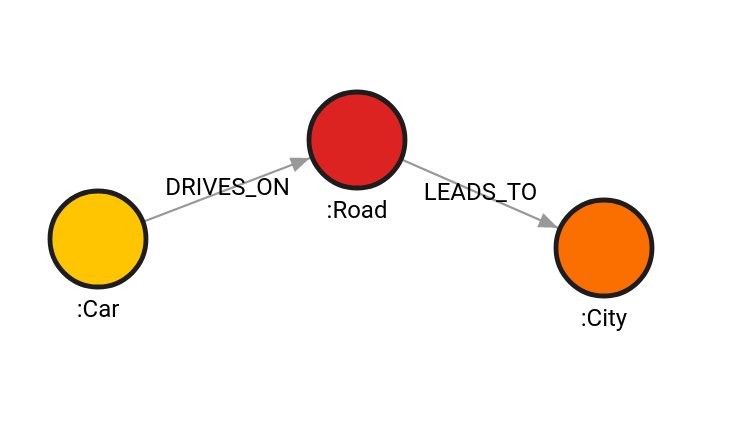
Run the refactor.collapse_node() procedure:
MATCH (r:Road)
CALL refactor.collapse_node(r, "DRIVES_TO")
YIELD id_collapsed, new_relationship
RETURN id_collapsed, new_relationship;Result:
+-------------------------------------------------------------------------------------------------------------------+
| id_collapsed | new_relationship |
+-------------------------------------------------------------------------------------------------------------------+
| 1 | {"id": 2,"start": 0,"end": 2,"label": "DRIVES_TO","properties": {},"type": "relationship"} |
+-------------------------------------------------------------------------------------------------------------------+
invert()
Invert the direction of a given relationship.
This procedure is equivalent to apoc.refactor.invert.
Input:
-
subgraph: Graph(OPTIONAL) ➡ A specific subgraph, which is an object of type Graph returned by theproject()function, on which the algorithm is run. If subgraph is not specified, the algorithm is computed on the entire graph by default. -
relationship: Any➡ A relationship, relationship ID, or a list of relationships or relationship IDs.
Output:
input: integer➡ ID of the inverted relationship.output: Relationship➡ The inverted relationship.
Usage:
Create the following graph:
CREATE (d:Dog)-[l:LOVES]->(h:Human);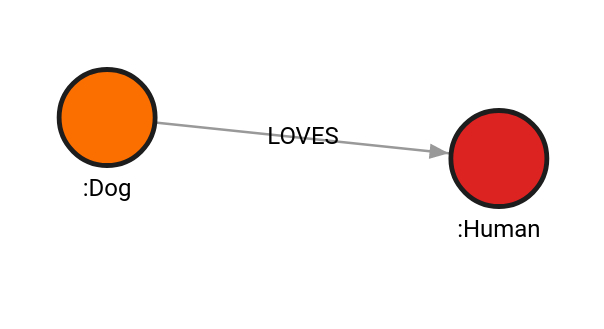
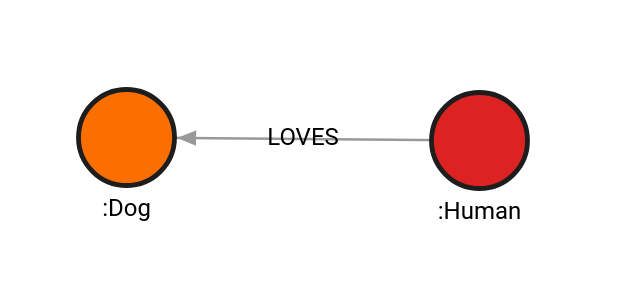
Run the refactor.invert() procedure:
MATCH (d:Dog)-[l:LOVES]->(h:Human)
CALL refactor.invert(l)
YIELD input, output
RETURN input, output;Result:
+-------------------------------------------------------------------------------------------------------------------+
| input | output |
+-------------------------------------------------------------------------------------------------------------------+
| 0 | {"id": 0,"start": 1,"end": 0,"label": "LOVES","properties": {},"type": "relationship"} |
+-------------------------------------------------------------------------------------------------------------------+
normalize_as_boolean()
The procedure normalizes properties to true or false depending on whether
the property value is contained in true_values or false_values. If the
property value is not contained in either list, the property is removed. Throws
an exception if both lists contain the same value.
This procedure is equivalent to apoc.refactor.normalizeAsBoolean.
Input:
-
subgraph: Graph(OPTIONAL) ➡ A specific subgraph, which is an object of type Graph returned by theproject()function, on which the algorithm is run. If subgraph is not specified, the algorithm is computed on the entire graph by default. -
entity: Node|Relationship➡ The node or relationship on which the property value will be normalized. -
property_key: string➡ The key of the property to be normalized. -
true_values: List[Any]➡ A list of property values that will be normalized totrue. -
false_values: List[Any]➡ A list of property values that will be normalized tofalse.
Usage:
Create a graph using the queries below:
CREATE (n1:Node1 {property: "YES"})
CREATE (n2:Node2 {property: "NO"})
CREATE (n3:Node3 {property: "MAYBE", exists:true})
CREATE (n4:Node4)
CREATE (n5:Node5 {exists:false})
CREATE (n1)-[:Rel1 {property:"YES"}]->(n2)
CREATE (n2)-[:Rel2 {property:"NO"}]->(n3)
CREATE (n3)-[:Rel3]->(n4)
CREATE (n4)-[:Rel4 {property:"MAYBE", exists:"YES"}]->(n5);The following query will set every property called property to true if it
is equal to YES, and to false if it is equal to NO, otherwise it will
delete the property:
MATCH (n)
WITH collect(n) AS nodes
CALL refactor.normalize_as_boolean(nodes, 'property', ['YES'], ['NO']);extract_node()
The procedure creates a node from the given relationship (and deletes the relationship) with the given labels and connects the new node to the start and end node of the given relationship with the given types.
This procedure is equivalent to apoc.refactor.extractNode.
Input:
-
subgraph: Graph(OPTIONAL) ➡ A specific subgraph, which is an object of type Graph returned by theproject()function, on which the algorithm is run. If subgraph is not specified, the algorithm is computed on the entire graph by default. -
relationships: Relationship|int|List[Relationship|int]➡ Relationships to be changed into a node defined by their ID, themselves, or a list of any of those two. -
labels: List[string]➡ A list of labels that should assigned to the newly created node. -
outType: String➡ The type of the outgoing relationship from the newly created node. -
inType: String➡ The type of the incoming relationship to the newly created node.
Output:
input: integer➡ The ID of the provided, now deleted relationship.output: Node➡ The newly created node.
Usage:
Create a graph using the query below:
CREATE (Node1:Label {name: 'Node1'})
CREATE (Node2:Label {name: 'Node2'})
CREATE (Node3:Label {name: 'Node3'})
CREATE (Node4:Label {name: 'Node4'})
CREATE (Node5:Label {name: 'Node5'})
CREATE (Node1)-[:Rel1]->(Node2)
CREATE (Node2)-[:Rel2]->(Node3)
CREATE (Node3)-[:Rel3]->(Node4)
CREATE (Node4)-[:Rel4]->(Node5);The query will delete all the relationships in the graph, create them as nodes
with the label NewLabel and connect them to the nodes they connected as a
relationship:
MATCH ()-[rel]->()
CALL refactor.extract_node(rel, ["NewLabel"], "OutRelationship", "InRelationship")
YIELD output
RETURN output;The new state of the graph:
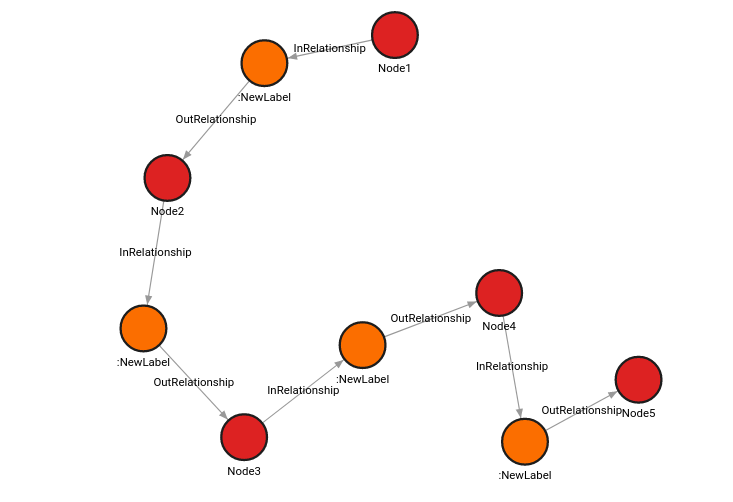
delete_and_reconnect()
The procedure deletes the given nodes from the given path (deleting them in the graph) and reconnects the remaining nodes.
This procedure is equivalent to apoc.refactor.deleteAndReconnect.
Input:
-
subgraph: Graph(OPTIONAL) ➡ A specific subgraph, which is an object of type Graph returned by theproject()function, on which the algorithm is run. If subgraph is not specified, the algorithm is computed on the entire graph by default. -
path: Path➡ The given path. -
nodes: List[Node]➡ A list of nodes to be deleted. -
config: Map➡ Config for reconnecting nodes.relationshipSelectionStrategy: string (default = "incoming"):"incoming"- Relationship with the lower index in the path will be used for reconnection."outgoing"- The relationship with the higher index in the path will be used for reconnection."merge"- The relationships will be merged, and the relationship type will be changed to “type2_type1” where type1 is the type of the relationship with the lower index in the path. If both relationships have the same property the property in the reconnected relationship will be decided bypropertiesin the config.
properties: string (default = "combine"):"discard"- The property of the relationship with the lower index in the path wins."overwrite"/ “override” - The property of the relationship with the higher index in the path wins."combine"- Merges properties by creating a list in which both property values are contained.
Output:
nodes: List[Node]➡ Nodes which were not deleted from the graph.relationships: List[Relationship]➡ Relationships which were not deleted from the graph.
Usage:
All the usage examples show how the procedure operates using the following graph:
CREATE (n1:Node {name: "Node 1"})-[:Rel1 {name: "Rel1"}]->(n2:Node {name: "Node 2"})-[:Rel2 {name: "Rel2"}]->(n3:Node {name: "Node 3"})-[:Rel3 {name: "Rel3"}]->(n4:Node {name: "Node 4"})-[:Rel4 {name: "Rel4"}]->(n5:Node {name: "Node 5"});Use the relationships with the lower index in the path to reconnect the nodes:
MATCH p=(a:Node)-->(b:Node)-->(c:Node)-->(d:Node)-->(e:Node)
WITH p, [b,d] as l CALL refactor.delete_and_reconnect(p, l, {relationshipSelectionStrategy: 'incoming'})
YIELD nodes, relationships
RETURN nodes, relationships;Result:
nodes: [{"id": 5, "labels": ["Node"], "properties": {"name": "Node 1"}, "type": "node"}, {"id": 7, "labels": ["Node"], "properties": {"name": "Node 3"}, "type": "node"}, {"id": 9, "labels": ["Node"], "properties": {"name": "Node 5"}, "type": "node"}]
relationships: [{"id": 4, "start": 5, "end": 7, "label": "Rel1", "properties": {"name": "Rel1"}, "type": "relationship"}, {"id": 6, "start": 7, "end": 9, "label": "Rel3", "properties": {"name": "Rel3"}, "type": "relationship"}]Use the relationships with the higher index in the path to reconnect the nodes:
MATCH p=(a:Node)-->(b:Node)-->(c:Node)-->(d:Node)-->(e:Node)
WITH p, [b,d] as l CALL refactor.delete_and_reconnect(p, l, {relationshipSelectionStrategy: 'outgoing'})
YIELD nodes, relationships
RETURN nodes, relationships;Result:
nodes: [{"id": 15, "labels": ["Node"], "properties": {"name": "Node 1"}, "type": "node"}, {"id": 17, "labels": ["Node"], "properties": {"name": "Node 3"}, "type": "node"}, {"id": 19, "labels": ["Node"], "properties": {"name": "Node 5"}, "type": "node"}]
relationships: [{"id": 13, "start": 15, "end": 17, "label": "Rel2", "properties": {"name": "Rel2"}, "type": "relationship"}, {"id": 15, "start": 17, "end": 19, "label": "Rel4", "properties": {"name": "Rel4"}, "type": "relationship"}]The relationship used for reconnecting will have properties of both relationships but in case of a conflict (properties with the same key) the property from the relationship with the smaller index in the path will prevail:
MATCH p=(a:Node)-->(b:Node)-->(c:Node)-->(d:Node)-->(e:Node)
WITH p, [b,d] as l CALL refactor.delete_and_reconnect(p, l, {relationshipSelectionStrategy: 'merge', properties: 'discard'})
YIELD nodes, relationships
RETURN nodes, relationships;Result:
nodes: [{"id": 20, "labels": ["Node"], "properties": {"name": "Node 1"}, "type": "node"}, {"id": 22, "labels": ["Node"], "properties": {"name": "Node 3"}, "type": "node"}, {"id": 24, "labels": ["Node"], "properties": {"name": "Node 5"}, "type": "node"}]
relationships: [{"id": 16, "start": 20, "end": 22, "label": "Rel2_Rel1", "properties": {"name": "Rel1"}, "type": "relationship"}, {"id": 18, "start": 22, "end": 24, "label": "Rel4_Rel3", "properties": {"name": "Rel3"}, "type": "relationship"}]The relationship used for reconnecting will have properties of both relationships but in case of a conflict (properties with the same key) the property from the relationship with the higher index in the path will prevail:
MATCH p=(a:Node)-->(b:Node)-->(c:Node)-->(d:Node)-->(e:Node)
WITH p, [b,d] as l CALL refactor.delete_and_reconnect(p, l, {relationshipSelectionStrategy: 'merge', properties: 'override'})
YIELD nodes, relationships
RETURN nodes, relationships;Result:
nodes: [{"id": 25, "labels": ["Node"], "properties": {"name": "Node 1"}, "type": "node"}, {"id": 27, "labels": ["Node"], "properties": {"name": "Node 3"}, "type": "node"}, {"id": 29, "labels": ["Node"], "properties": {"name": "Node 5"}, "type": "node"}]
relationships: [{"id": 21, "start": 25, "end": 27, "label": "Rel2_Rel1", "properties": {"name": "Rel2"}, "type": "relationship"}, {"id": 23, "start": 27, "end": 29, "label": "Rel4_Rel3", "properties": {"name": "Rel4"}, "type": "relationship"}]The relationship used for reconnecting will have properties of both relationships but in case of a conflict (properties with the same key) the new property will be a list containing both properties:
MATCH p=(a:Node)-->(b:Node)-->(c:Node)-->(d:Node)-->(e:Node)
WITH p, [b,d] as l CALL refactor.delete_and_reconnect(p, l, {relationshipSelectionStrategy: 'merge', properties: 'combine'})
YIELD nodes, relationships
RETURN nodes, relationships;Result:
nodes: [{"id": 35, "labels": ["Node"], "properties": {"name": "Node 1"}, "type": "node"}, {"id": 37, "labels": ["Node"], "properties": {"name": "Node 3"}, "type": "node"}, {"id": 39, "labels": ["Node"], "properties": {"name": "Node 5"}, "type": "node"}]
relationships: [{"id": 28, "start": 35, "end": 37, "label": "Rel2_Rel1", "properties": {"name": ["Rel1", "Rel2"]}, "type": "relationship"}, {"id": 30, "start": 37, "end": 39, "label": "Rel4_Rel3", "properties": {"name": ["Rel3", "Rel4"]}, "type": "relationship"}]rename_type()
The procedure changes the relationship type.
This procedure is equivalent to apoc.refactor.renameType.
Input:
-
subgraph: Graph(OPTIONAL) ➡ A specific subgraph, which is an object of type Graph returned by theproject()function, on which the algorithm is run. If subgraph is not specified, the algorithm is computed on the entire graph by default. -
oldType: string➡ The relationship type that will be renamed. -
newType: string➡ The new relationship type. -
rels: List[Relationship]➡ The list of relationships whose types will be renamed.
Output:
relationships_changed: integer➡ The number of relationships with a changed property name.
Usage:
Create a graph using the queries below:
CREATE (h:Human {name:"Carl"})-[r1:RUNS {distance_in_km:20}]->(d:Destination),
(h1:Human {name:"Marta"})-[r2:RUNS {distance_in_km: 20}]->(d),
(h2:Human {name:"Peter"})-[r3:RUNS {distance_in_km: 40}]->(d);Use the procedure to change the type RUNS to SPRINTS in all relationships:
MATCH ()-[r]-()
WITH COLLECT(distinct(r)) AS rels
CALL refactor.rename_type("RUNS", "SPRINTS", rels) YIELD relationships_changed RETURN relationships_changed;The procedure returns the number of updated relationships:
+---------------------------------------+
| relationships_changed |
+---------------------------------------+
| 3 |
+---------------------------------------+rename_type_property()
Renames the property of a relationship.
This procedure is equivalent to apoc.refactor.rename.typeProperty.
Input:
-
subgraph: Graph(OPTIONAL) ➡ A specific subgraph, which is an object of type Graph returned by theproject()function, on which the algorithm is run. If subgraph is not specified, the algorithm is computed on the entire graph by default. -
old_property: string➡ The relationship property that will be renamed. -
new_property: string➡ The new property name. -
rels: List[Relationship]➡ The list of relationships whose properties will be renamed.
Output:
relationships_changed: integer➡ The number of relationships with a changed property name.
Usage:
Create a graph using the queries below:
CREATE (h:Human {name:"Carl"})-[r1:RUNS {distance_in_km:20}]->(d:Destination),
(h1:Human {name:"Marta"})-[r2:RUNS {distance_in_km: 20}]->(d),
(h2:Human {name:"Peter"})-[r3:RUNS {distance_in_km: 40}]->(d);The graph schema is as follows:
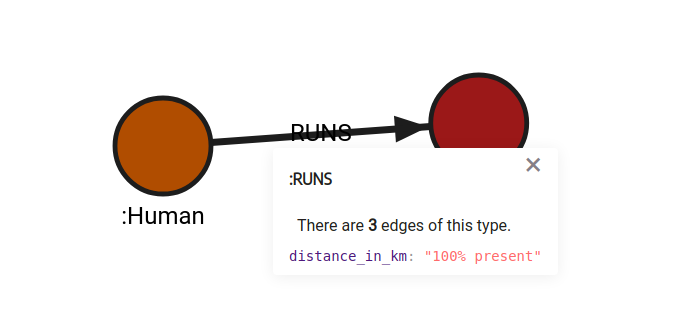
Use the procedure to change the name of distance_in_km property of all relationships into distance:
MATCH ()-[r]-()
WITH COLLECT(distinct(r)) AS rels
CALL refactor.rename_type_property("distance_in_km", "distance", rels)
YIELD relationships_changed
RETURN relationships_changed;The procedure returns the number of updated relationships:
+---------------------------------------+
| relationships_changed |
+---------------------------------------+
| 3 |
+---------------------------------------+The graph schema after the update is as follows:
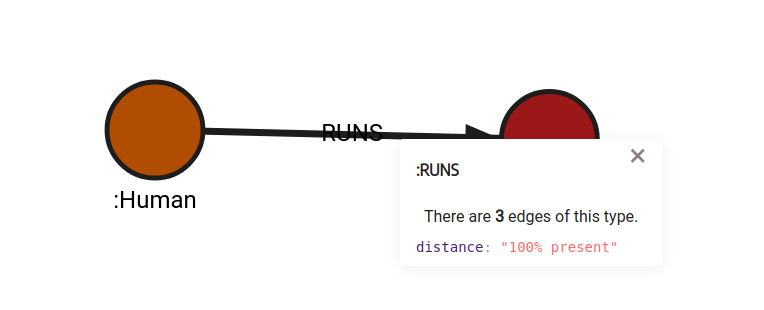
The following query will change the name of distance_in_km property in a specific relationship, in this case, relationship going from the Human node with the name property Carl:
MATCH (h:Human {name:"Carl"})-[r]-()
CALL refactor.rename_type_property("distance_in_km","distance",[r]) YIELD relationships_changed RETURN relationships_changed;+---------------------------------------+
| relationships_changed |
+---------------------------------------+
| 1 |
+---------------------------------------+mergeNodes()
Merges the properties, labels and relationships for the source nodes to the target node.
This procedure is equivalent to apoc.refactor.mergeNodes.
Input:
-
subgraph: Graph(OPTIONAL) ➡ A specific subgraph, which is an object of type Graph returned by theproject()function, on which the algorithm is run. If subgraph is not specified, the algorithm is computed on the entire graph by default. -
nodes: List[Node]➡ List of nodes that will be merged into the first node of the list. Exception is thrown if the node list is empty. -
config: Map➡ Configuration parameters:properties: string➡ values:combine,override/overwrite,discard:combine➡ if there are multiple values of the properties, they will be merged into a list of values. if there is only one property, then it will be the same valueoverride➡ last property in the list winsoverwrite➡ same asoverridediscard➡ discard the properties of the nodes - value will be null
.*: string➡ equivalent to propertiesmergeRels: boolean➡ specify whether the relationships will be merged into the target node or discarded.
Output:
node: Node➡ Merged node with updated properties, labels and relationships.
Usage:
Create a graph using the queries below:
CREATE (n1:Person {name: 'Alice', age: 30, city: 'New York'})
CREATE (n2:Person {name: 'Bob', age: 25, country: 'USA'}); Use the procedure to merge the nodes:
MATCH (n1:Person {name: 'Alice'}), (n2:Person {name: 'Bob'})
CALL refactor.merge_nodes([n1, n2], {properties: 'combine'}) YIELD node
RETURN node.name as name, node.age as age, node.city as city, node.country as country;or
MATCH (n1:Person {name: 'Alice'}), (n2:Person {name: 'Bob'})
CALL refactor.merge_nodes([n1, n2], {`.*`: 'combine'}) YIELD node
RETURN node.name as name, node.age as age, node.city as city, node.country as country;The procedure returns the merged node properties:
+-----------------------------------------------------+
| name | age | city | country |
+-----------------------------------------------------+
| ["Alice", "Bob"] | [30, 25] | "New York" | "USA" |
+-----------------------------------------------------+The following scenario will also merge the relationships:
Create a graph using the queries below:
CREATE (n1:Person {name: 'Alice', age: 30, city: 'New York'})
CREATE (n2:Person {name: 'Bob', age: 25, country: 'USA'})
CREATE (n3:Person {name: 'Charlie', age: 35, city: 'London'})
CREATE (n1)-[:KNOWS {since: 2020}]->(n2)
CREATE (n2)-[:WORKS_WITH {project: 'Project X'}]->(n3)
CREATE (n3)-[:FRIENDS_WITH {since: 2019}]->(n1); Use the procedure to merge the nodes and relationships:
MATCH (n1:Person {name: 'Alice'}), (n2:Person {name: 'Bob'}), (n3:Person {name: 'Charlie'})
CALL refactor.merge_nodes([n1, n2, n3], {properties: 'combine', mergeRels: true}) YIELD node
RETURN node.name as name, outDegree(node) as out_degree, inDegree(node) as in_degree;The procedure returns the merged node properties:
+----------------------------------------------------+
| name | inDegree | outDegree |
+----------------------------------------------------+
| ["Alice", "Bob", "Charlie"] | 3 | 3 |
+----------------------------------------------------+