Reference architectures
This page presents different deployment scenarios for Memgraph HA clusters, covering various aspects such as the number of data centers, geographic distribution, performance scaling, consistency requirements, and fault tolerance considerations.
Basic architectures
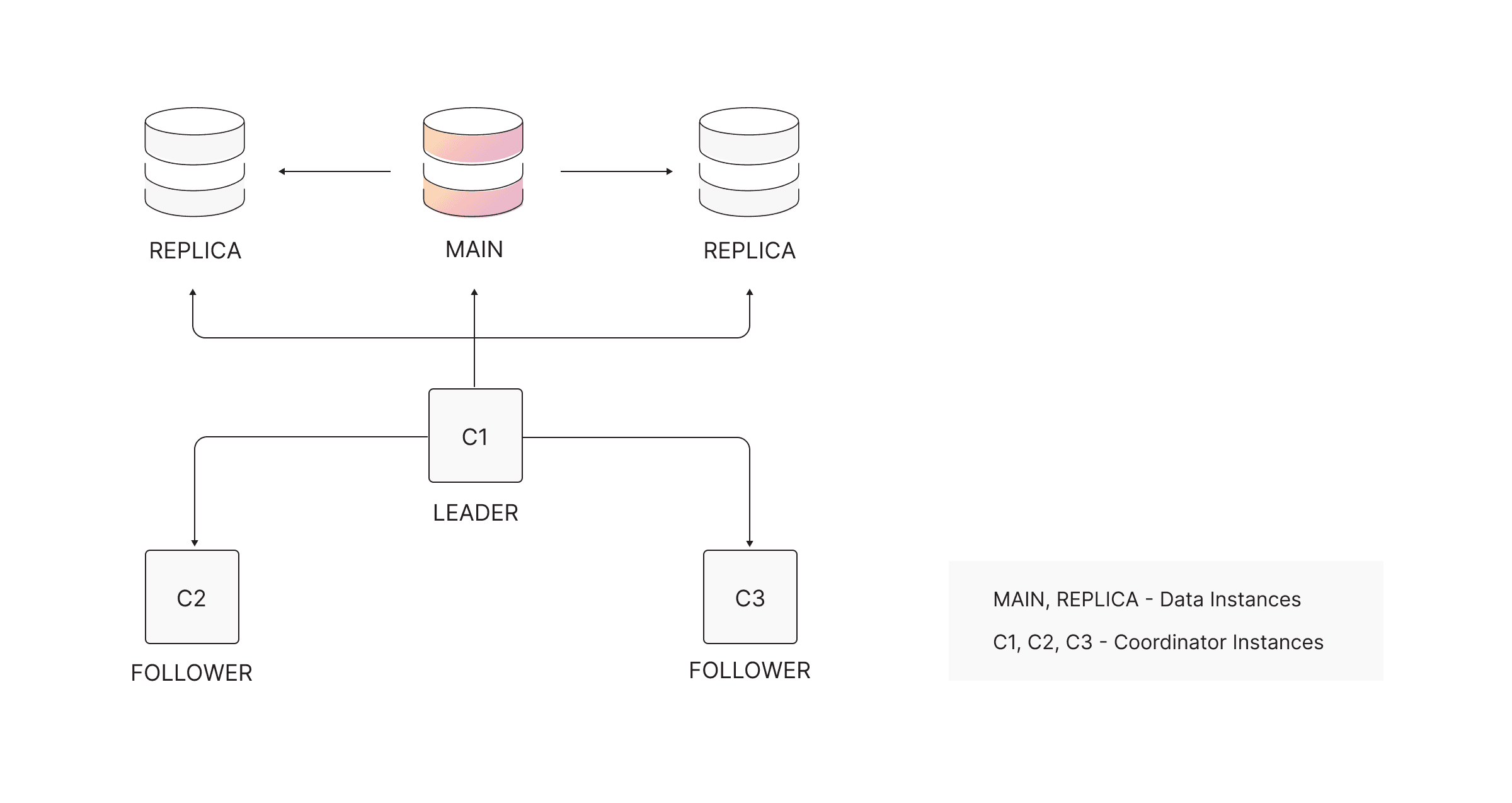
Typical HA cluster
A typical HA deployment consists of:
- Three data instances (1 MAIN + 2 REPLICAs)
- Three coordinators (1 Leader + 2 Followers)
Data instances require hardware sized for memory-intensive workloads. Coordinators, responsible for cluster state and failover logic, are lightweight and typically run comfortably on 4-8 GB RAM servers.
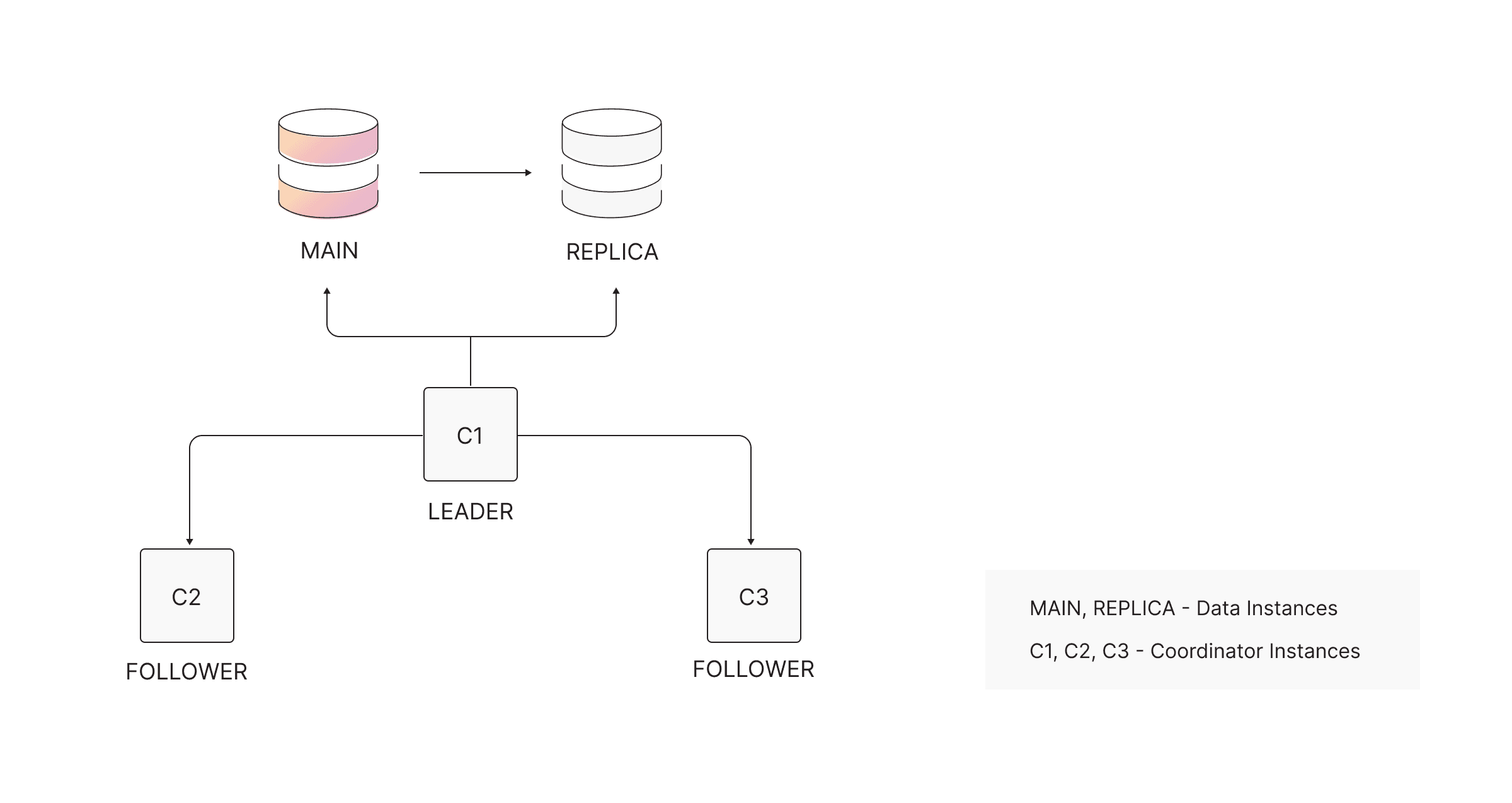
Minimal HA cluster
The smallest valid HA configuration consists of:
- Two data instances (1 MAIN + 1 REPLICA)
- Three coordinators
This results in a minimum of five total instances.
Architectures for scaling performance
Memgraph is an in-memory graph database designed for extremely high read and write throughput on a single machine. Distributing this architecture across multiple servers increases resource requirements but enables scaling for demanding real-time analytics and transactional workloads.
Before scaling horizontally or vertically, first ensure your standalone instance has been fully optimized.
Scaling reads
To increase read capacity, add additional REPLICA instances. Replicas can serve read-only workloads, making them ideal for analytics, reporting, and latency-sensitive queries.
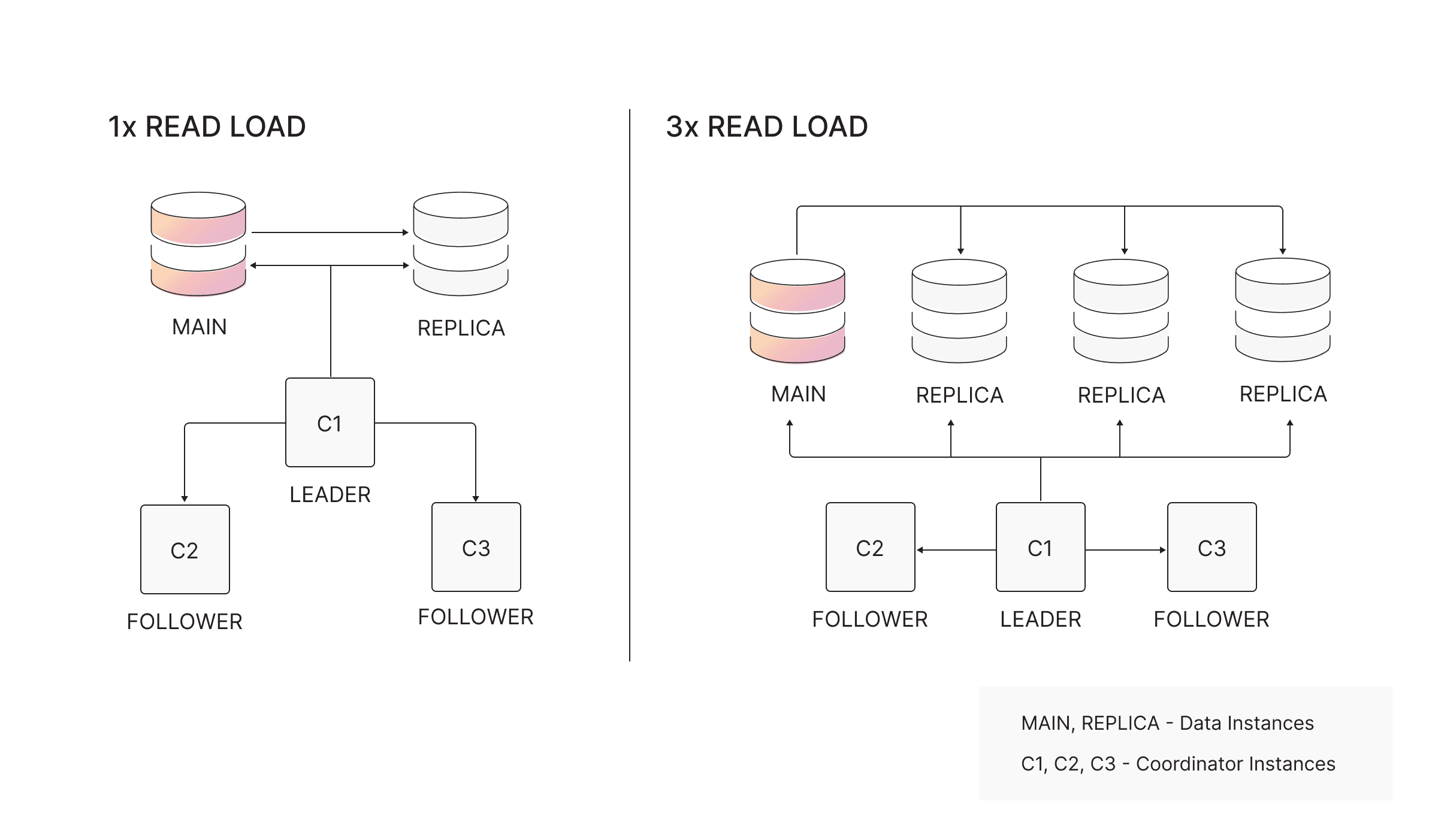
Scaling writes
Write scalability is achieved by scaling the MAIN vertically (more CPU, memory). Only the MAIN accepts writes, which aligns with the design of graph workloads, especially multi-hop traversals, which do not benefit from horizontal write sharding.
Why vertical scaling works well in Memgraph:
- Fine-grained locking
- Lock-free skiplists for node/relationship storage
- MVCC (Multi-Version Concurrency Control) ensuring writers do not block readers
- Predictable scaling under higher CPU core counts
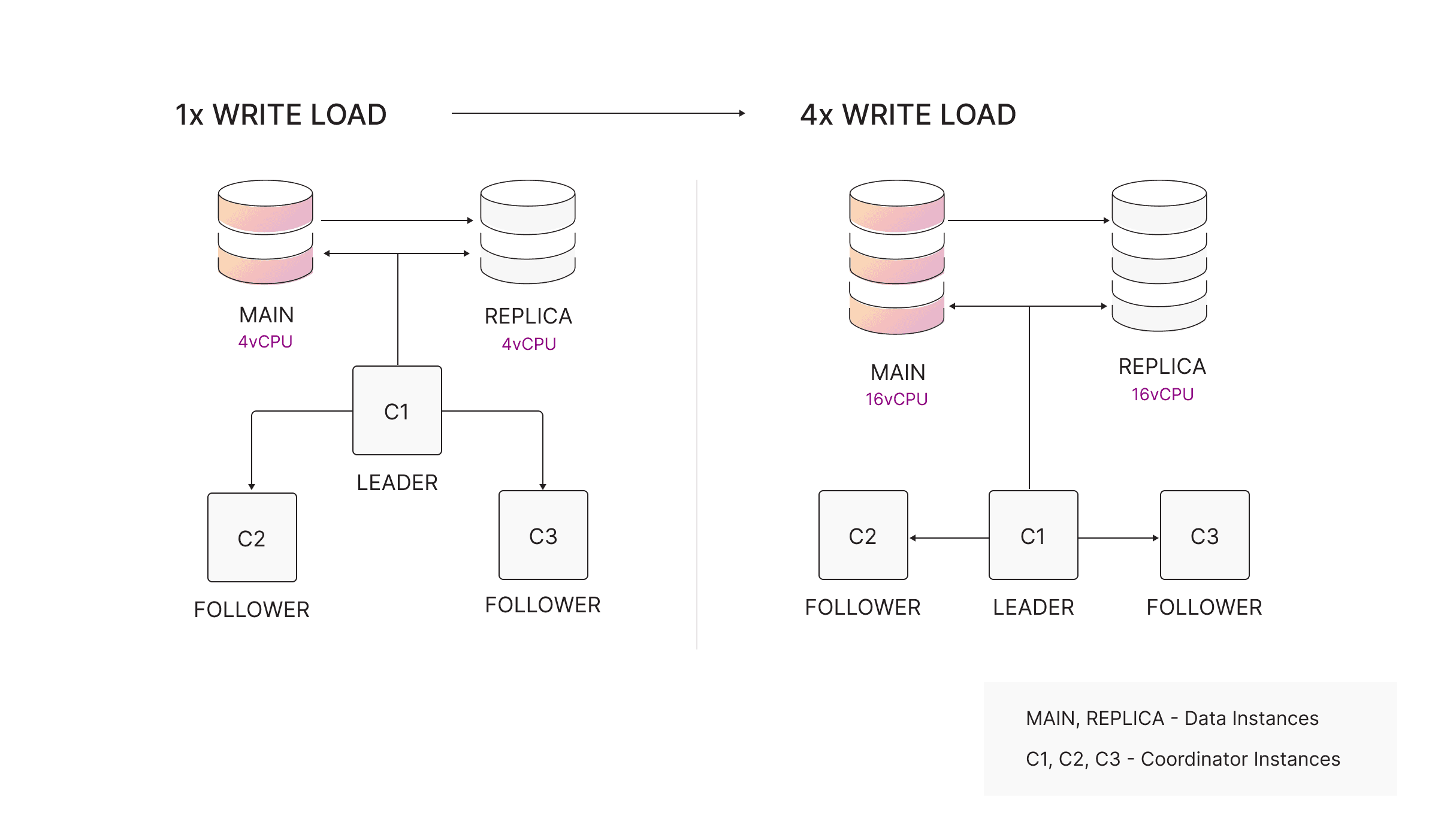
Horizontal write scaling, often available in non-graph databases, is not suitable for graph workloads because multi-hop queries would require cross-shard traversal, significantly degrading performance and consistency guarantees.
Architectures for robust fault tolerance
Cross-data center deployment
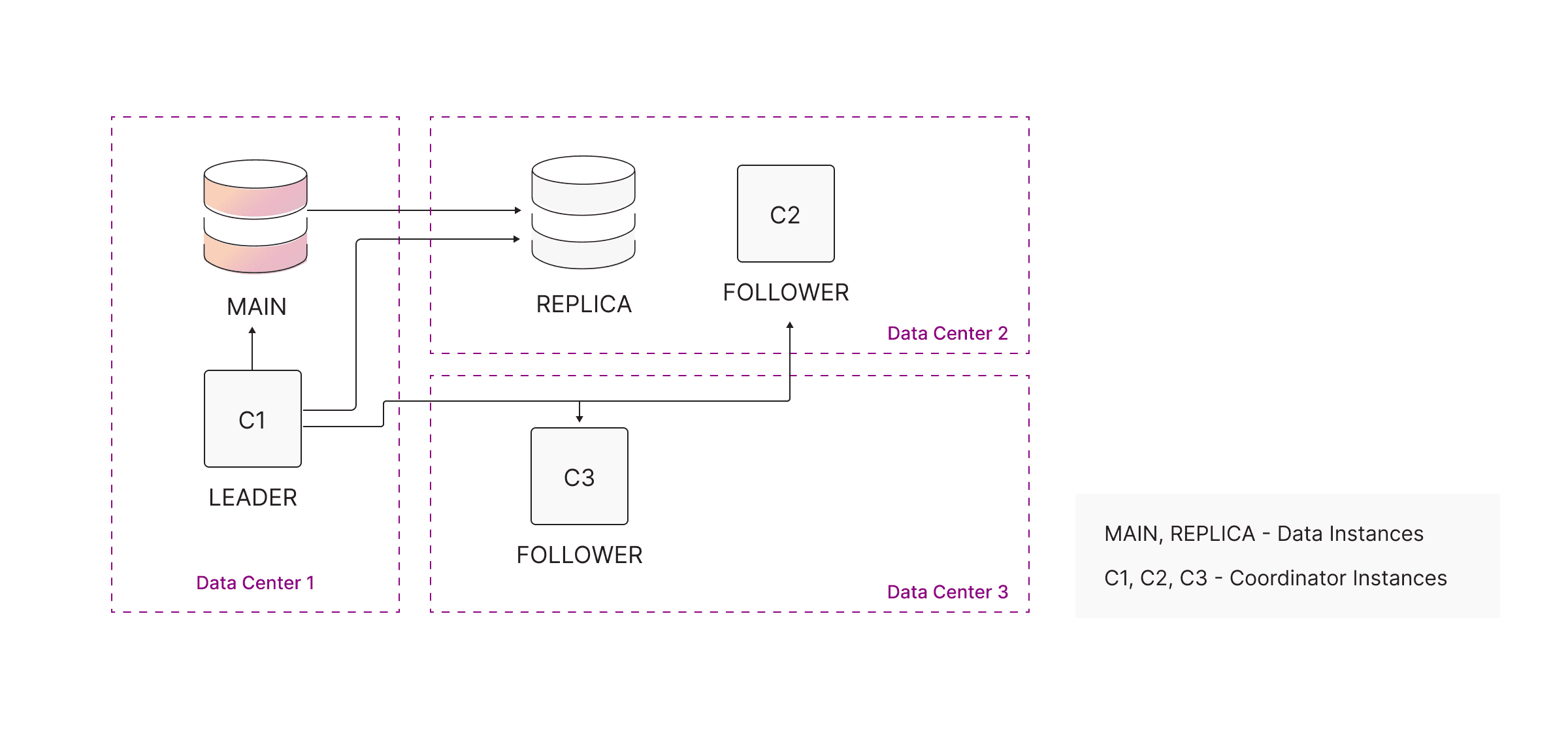
For disaster recovery and data center-level fault tolerance, Memgraph HA can be deployed across three separate data centers, for example:
- Data Center 1: MAIN + 1 Coordinator
- Data Center 2: REPLICA + 1 Coordinator
- Data Center 3: Coordinator
Failure behavior:
-
Data Center 1 failure
- RAFT retains quorum
- REPLICA is automatically promoted to MAIN
- Cluster continues serving reads and writes
-
Data Center 2 failure
- MAIN remains available
- Coordinators maintain quorum
- REPLICA recovers automatically when restored
-
Data Center 3 failure
- Quorum maintained with the remaining two coordinators
- No failover needed
Other architectures
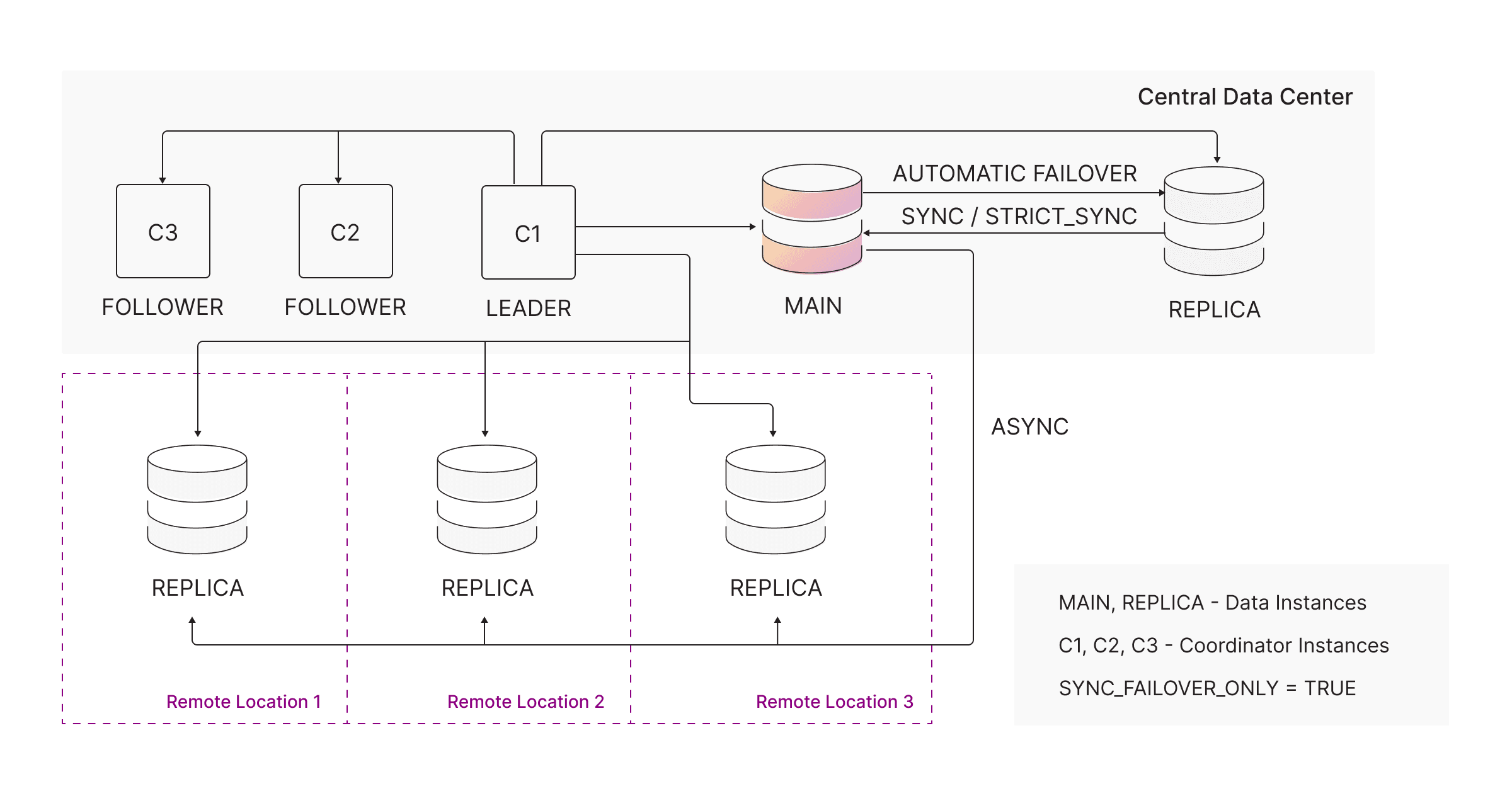
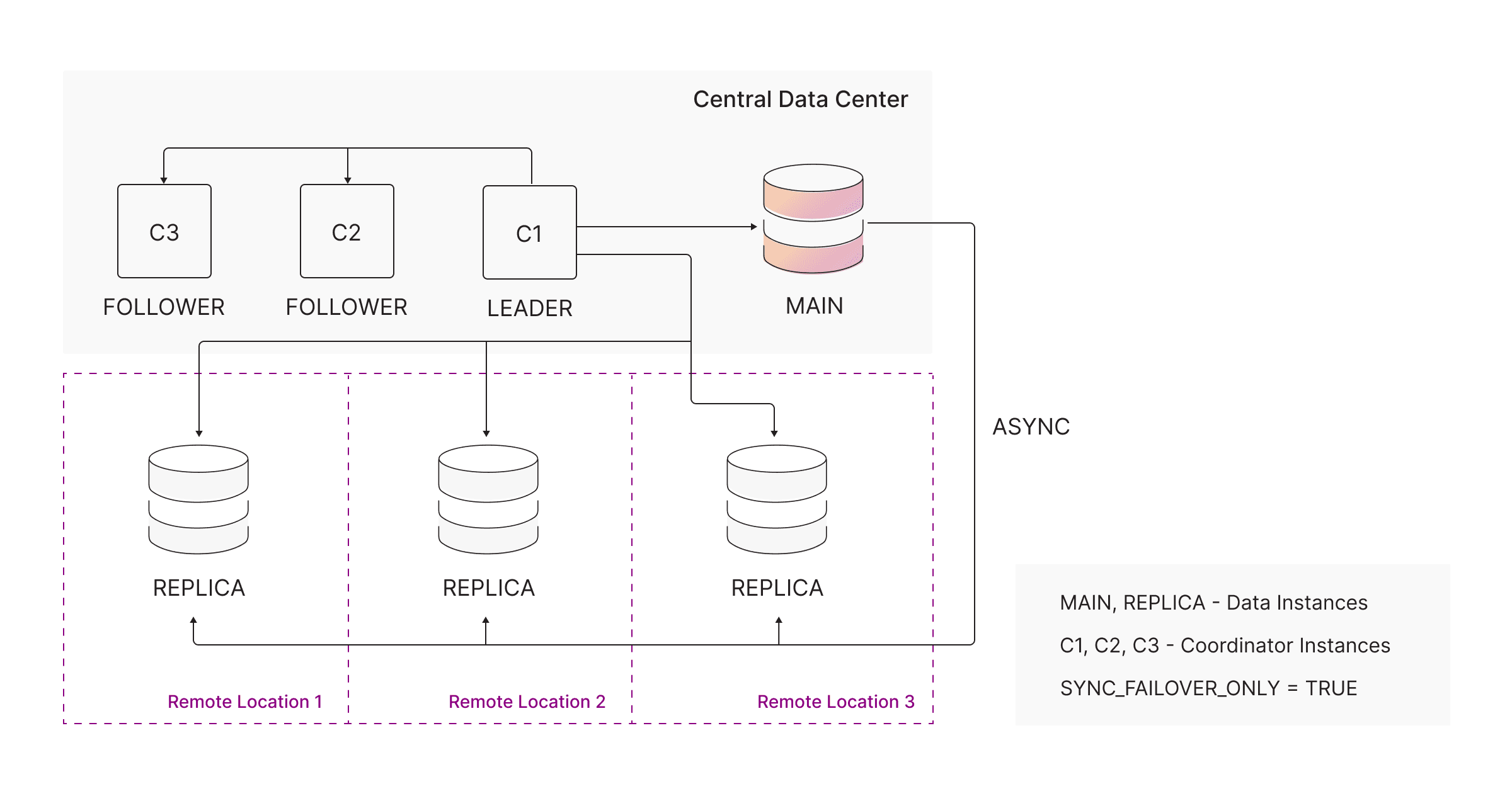
Centralized MAIN with remote REPLICAs
Some organizations need low-latency local reads across multiple regions while keeping writes centralized for consistency.
Deploy remote REPLICAs using ASYNC replication in regional data centers:
- Local reads are extremely fast
- MAIN remains authoritative
- Writes remain centralized
Set the coordinator setting:
sync_failover_only = trueThis ensures failover never promotes a remote ASYNC replica.
Centralized MAIN with regional REPLICAs + failover protection
To add failover capability to the centralized architecture, add a SYNC or
STRICT_SYNC REPLICA in the same region as the MAIN.
This creates:
- Local failover between MAIN and the nearby SYNC replica
- Remote read replicas in other regions for latency-sensitive workloads
Only SYNC or STRICT_SYNC replicas are eligible for failover.