MERGE clause
The MERGE clause is used to ensure that a pattern you are looking for exists
in the database. This means that if the pattern is not found, it will be
created. In a way, this clause is like a combination of MATCH and CREATE.
Indexing can increase performance when executing queries. Please take a look at our documentation on indexing for more details.
- Merging nodes
1.1. Merging nodes with labels
1.2. Merging nodes with properties
1.3. Merging nodes with labels and properties
1.4. Merging nodes with existing node properties - Merging relationships
2.1. Merging relationships
2.2. Merging on undirected relationships - Merging with ON CREATE and ON MATCH
3.1. Merging with ON CREATE SET
3.2. Merging with ON MATCH SET
3.3. Merging with ON CREATE SET and ON MATCH SET
3.4. Merging with SET
3.5. Combination of clauses - Errors related to invalid MERGE usage
4.1. Merging a null property
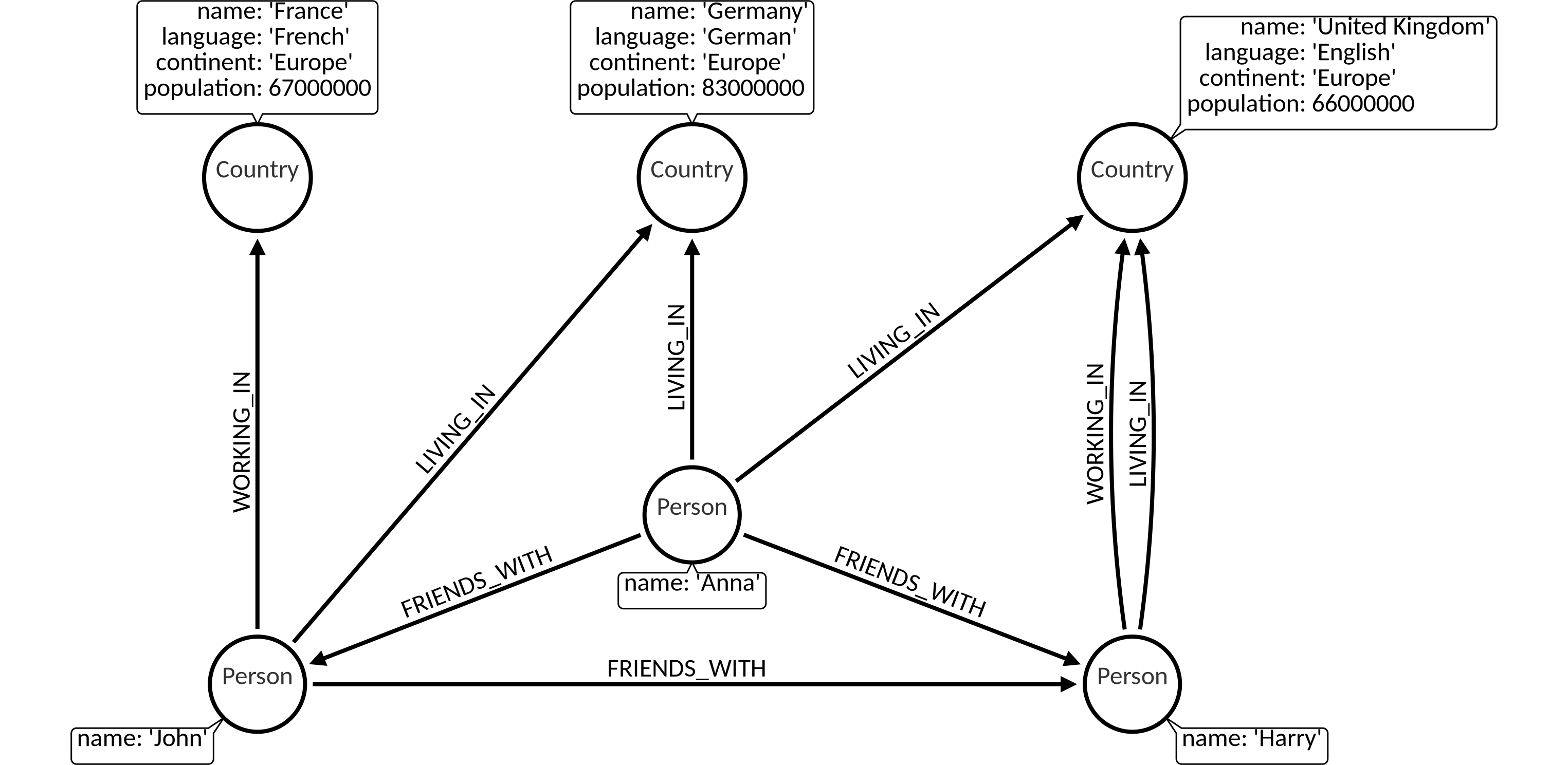
Data Set
The following examples are executed with this data set. You can create this data set locally by executing the queries at the end of the page: Dataset queries.
1. Merging nodes
1.1. Merging nodes with labels
If MERGE is used on a node with a label that doesn’t exist in the database, the node is created:
MERGE (city:City)
RETURN city;Output:
+---------+
| city |
+---------+
| (:City) |
+---------+1.2. Merging nodes with properties
If MERGE is used on a node with properties that don’t match any existing node, that node is created:
MERGE (city {name: 'London'})
RETURN city;Output:
+--------------------+
| city |
+--------------------+
| ({name: "London"}) |
+--------------------+1.3. Merging nodes with labels and properties
If MERGE is used on a node with labels and properties that don’t match any existing node, that node is created:
MERGE (city:City {name: 'London'})
RETURN city;Output:
+--------------------------+
| city |
+--------------------------+
| (:City {name: "London"}) |
+--------------------------+1.4. Merging nodes with existing node properties
If MERGE is used with properties on an existing node, a new node is created for each unique value of that property:
MATCH (p:Person)
MERGE (h:Human {name: p.name})
RETURN h.name;Output:
+--------+
| h.name |
+--------+
| John |
| Harry |
| Anna |
+--------+2. Merging relationships
2.1. Merging relationships
Just as with nodes, MERGE can be used to match or create relationships:
MATCH (p1:Person {name: 'John'}), (p2:Person {name: 'Anna'})
MERGE (p1)-[r:RELATED]->(p2)
RETURN r;Output:
+-----------+
| r |
+-----------+
| [RELATED] |
+-----------+Multiple relationships can be matched or created with MERGE in the same query:
MATCH (p1:Person {name: 'John'}), (p2:Person {name:'Anna'})
MERGE (p1)-[r1:RELATED_TO]->(p2)-[r2:RELATED_TO]->(p1)
RETURN r1, r2;Output:
+--------------+--------------+
| r1 | r2 |
+--------------+--------------+
| [RELATED_TO] | [RELATED_TO] |
+--------------+--------------+2.2. Merging on undirected relationships
If MERGE is used on an undirected relationship, the direction will be chosen at random:
MATCH (p1:Person {name: 'John'}), (p2:Person {name: 'Anna'})
MERGE path=((p1)-[r:WORKS_WITH]->(p2))
RETURN path;Output:
+-----------------------------------------------------------------+
| p |
+-----------------------------------------------------------------+
| (:Person {name: "John"})-[WORKS_WITH]->(:Person {name: "Anna"}) |
+-----------------------------------------------------------------+In this example, a path is returned to show the direction of the relationships.
3. Merging with ON CREATE SET and ON MATCH SET
3.1. Merging with ON CREATE SET
The ON CREATE SET part of a MERGE clause will only be executed if the node needs to be created:
MERGE (p:Person {name: 'Lucille'})
ON CREATE SET p.date_of_creation = timestamp()
RETURN p.name, p.date_of_creation;Output:
+--------------------+--------------------+
| p.name | p.date_of_creation |
+--------------------+--------------------+
| Lucille | 1605080852685000 |
+--------------------+--------------------+3.2. Merging with ON MATCH SET
The ON MATCH SET part of a MERGE clause will only be executed if the node is found:
MERGE (p:Person {name: 'John'})
ON MATCH SET p.found = TRUE
RETURN p.name, p.found;Output:
+---------+---------+
| p.name | p.found |
+---------+---------+
| John | true |
+---------+---------+3.3. Merging with ON CREATE SET and ON MATCH SET
The MERGE clause can be used with both the ON CREATE SET and ON MATCH SET options:
MERGE (p:Person {name: 'Angela'})
ON CREATE SET p.notFound = TRUE
ON MATCH SET p.found = TRUE
RETURN p.name, p.notFound, p.found;Output:
+------------+------------+------------+
| p.name | p.notFound | p.found |
+------------+------------+------------+
| Angela | true | Null |
+------------+------------+------------+3.4. Merging with SET
If a certain property wants to be set to the same value in the case of ON CREATE SET and ON MATCH SET you can just use SET:
MERGE (p:Person {name: 'Angela'})
ON CREATE SET p.found = TRUE
ON MATCH SET p.found = TRUE;is the same as the query below:
MERGE (p:Person {name: 'Angela'})
SET p.Found = TRUE;3.5. Combination of clauses
You can also combine all three clauses (ON CREATE SET, ON MATCH SET and
SET) to set a certain property depending on whether the node has been merged
or created, and to set another property to a certain value regardless of the
creation or merger of the node:
MERGE (p:Person {name: 'Angela'})
ON CREATE SET p.found = FALSE
ON MATCH SET p.found = TRUE
SET p.last_name = 'Smith'The found property will be set to FALSE if the node was created, on TRUE
if it was merged, but in any case, the last name will be set to Smith.
Dataset Queries
We encourage you to try out the examples by yourself. You can get our data set locally by executing the following query block.
MATCH (n) DETACH DELETE n;
CREATE (c1:Country {name: 'Germany', language: 'German', continent: 'Europe', population: 83000000});
CREATE (c2:Country {name: 'France', language: 'French', continent: 'Europe', population: 67000000});
CREATE (c3:Country {name: 'United Kingdom', language: 'English', continent: 'Europe', population: 66000000});
MATCH (c1),(c2)
WHERE c1.name = 'Germany' AND c2.name = 'France'
CREATE (c2)<-[:WORKING_IN {date_of_start: 2014}]-(p:Person {name: 'John'})-[:LIVING_IN {date_of_start: 2014}]->(c1);
MATCH (c)
WHERE c.name = 'United Kingdom'
CREATE (c)<-[:WORKING_IN {date_of_start: 2014}]-(p:Person {name: 'Harry'})-[:LIVING_IN {date_of_start: 2013}]->(c);
MATCH (p1),(p2)
WHERE p1.name = 'John' AND p2.name = 'Harry'
CREATE (p1)-[:FRIENDS_WITH {date_of_start: 2011}]->(p2);
MATCH (p1),(p2)
WHERE p1.name = 'John' AND p2.name = 'Harry'
CREATE (p1)<-[:FRIENDS_WITH {date_of_start: 2012}]-(:Person {name: 'Anna'})-[:FRIENDS_WITH {date_of_start: 2014}]->(p2);
MATCH (p),(c1),(c2)
WHERE p.name = 'Anna' AND c1.name = 'United Kingdom' AND c2.name = 'Germany'
CREATE (c2)<-[:LIVING_IN {date_of_start: 2014}]-(p)-[:LIVING_IN {date_of_start: 2014}]->(c1);
MATCH (n)-[r]->(m) RETURN n,r,m;4. Errors related to invalid MERGE usage
4.1. Merging a null property
Issuing a query like the following:
MERGE (n:Node {id:null})will result in the following error
Can't have null literal properties inside merge (n.id)!Due to Memgraph having the same behavior for null types, which also corresponds to not having the property at all,
we do not support this behavior.
This applies to both node and edge properties. The check is evaluated at runtime.
To mitigate this issue, try modifying the query using ON CREATE SET, ON MATCH SET, or just SET after the MERGE clause.