Streams
This page is currently being refactored as part of the Awesome Data streams deprecation and streaming examples migration.
The content here may be outdated or under active revision. Please check back soon or follow the GitHub issue for updates.
Memgraph can connect to existing Kafka, Redpanda, and Pulsar data streams, enabling you to ingest data directly. Memgraph Lab offers an intuitive interface for managing streams under the Streams section. You can also manage streams manually through Cypher queries for greater control. For more details, check the stream reference guide.
This guide provides detailed instructions on how to:
-
Add a new stream: Learn how to connect Memgraph to a new Kafka, Redpanda or Pulsar stream by configuring the stream name, server address and subscribing to the relevant topics.
-
Edit stream settings: Discover how to modify key settings such as the consumer group, batch interval and batch size to fine-tune the data stream for your specific use case.
-
Add a transformation module: Understand the process of attaching a transformation module, either in Python or C/C++, to process and convert data from the stream into Cypher queries that update the graph in Memgraph.
-
Set Kafka configuration parameters: Customize your Kafka stream connection by adding necessary configuration parameters to ensure secure and efficient data transfer.
-
Start a stream: Once your stream and transformation module are ready, follow the steps to start the stream, enabling data ingestion into Memgraph in real-time.
-
Manage a stream: Learn how to start, stop, and delete streams, as well as manage the transformation module and adjust the stream offset during the stream’s lifecycle.
-
Configure Kafka stream offset: Gain insight into how to adjust Kafka stream offsets via Cypher queries, allowing for precise control over data consumption.
Add a new stream
In Memgraph Lab, you can easily connect to a new data stream. To do this:
- Navigate to the Streams section and click Add new stream.
- Choose between Kafka, Redpanda or Pulsar.
- Provide the stream name, the server address where data is being streamed from, and the topics you’re subscribing to.

Edit stream settings
To modify a stream’s configuration, click on the Edit (pencil icon). From there, you can adjust settings such as:
- Consumer group
- Batch interval
- Batch size

This gives you control over how your data is consumed and processed.
Add a transformation module
To connect to a stream, you first need to attach a transformation module to it.

The transformation module is a query module containing a user-defined procedure, written either in Python or C/C++, that processes incoming data into Cypher queries for updating Memgraph’s graph.
To add a Python transformation module to a stream:
- Click on Add transformation module.
- Expand on Choose transformation module.
- Select an existing transformation module or + Create new transformation.
- Review an existing module or clear the screen and name and write a new transformation procedure.
- Save the transformation module.
- Check if the necessary transformation procedure is visible under Detected transformation functions on the right.
- Select a transformation procedure and click on Attach to stream.
For Python modules, you can write and test the transformation procedure directly within Memgraph Lab. Alternatively, if you’ve already developed a C/C++ procedure, it needs to be loaded into Memgraph first before attaching it to the stream.
Once attached, you can proceed with starting the stream.
Set Kafka configuration parameters
If necessary, add the Kafka configuration parameters to customize the stream further:
- In the Kafka configuration parameters click on + Add parameter field.
- Insert the parameter name and value.
- To add another parameter, click on + Add parameter field.
- Click on Save configuration once you have set all parameters.
For example, to connect to the Awesome Data Stream, use the following configuration:
- sasl.username | public
- sasl.password | public
- security.protocol | SASL_PLAINTEXT
- sasl.mechanism | PLAIN
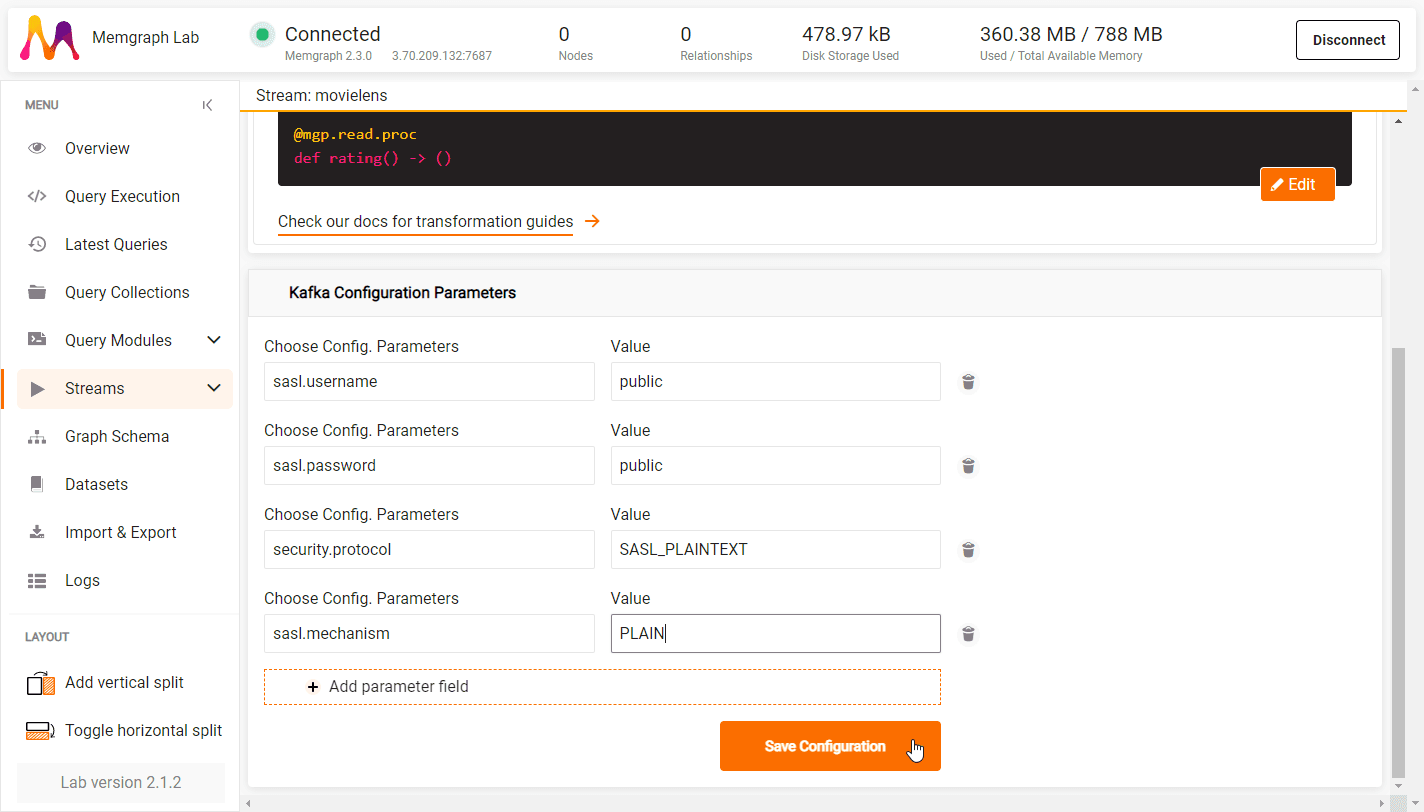
These parameters will enable Memgraph to securely connect to the Kafka server.
Start a stream
Once the stream is configured, you can click on Connect to stream.

Memgraph will do a series of checks, ensuring that defined topics and transformation procedures are correctly configured. If all checks pass successfully, you can click on Start the stream. Once you start the stream, you will no longer be able to change any of the configuration settings, just the transformation module.
The stream status changes to Running, and data is ingested into Memgraph. You can see the number of nodes and relationships rising as the data keeps coming in. If your nodes and relationships numbers stay at zero, check the transformation module, as there might be a flaw in the logic that needs to be resolved.
Switch to Query execution and monitor the data ingestion by running a query like:
MATCH p=(n)-[r]-(m)
RETURN p LIMIT 100;This will show the graph being populated in real-time. If the node and relationship counts remain zero, it might indicate an issue with the transformation procedure.
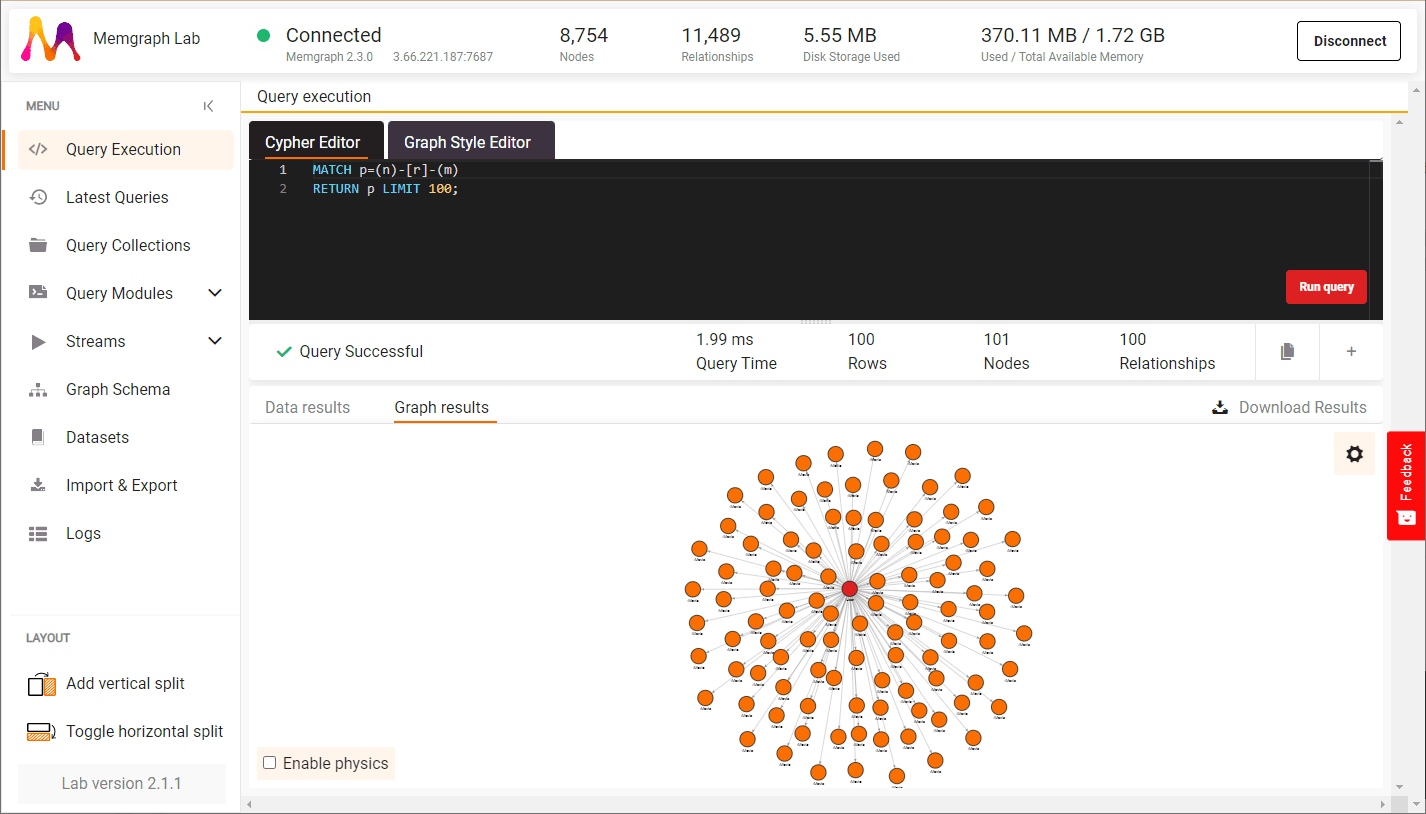
Manage a stream
To start a draft stream, click on Connect to stream.
To manage an existing stream:
- Navigate to the Streams section.
- Click the stream you wish to manage.
From here, you can:
- Start or Stop the stream.
- Delete the stream (note that this action is irreversible).
If you need to adjust the transformation module or the stream offset, you can do so at any time, but keep in mind that you cannot modify a stream once it is running.
Configure Kafka stream offset
To change the Kafka stream offset, use the following query:
CALL mg.kafka_set_stream_offset(streamName, offset)- Setting the offset to
-1will reset to the beginning of the topic. - Setting it to
-2will start from the end of the stream, consuming only new messages.