path
The path module allows users to explore different paths, filter relationships,
and nodes based on specific criteria, and achieve more complex path-related
tasks that go beyond the capabilities of native Cypher - whether you’re seeking
all possible paths between two nodes, subgraphs that meet certain conditions, or
various other path-oriented operations.
| Trait | Value |
|---|---|
| Module type | algorithm |
| Implementation | C++ |
| Graph direction | directed/undirected |
| Edge weights | weighted/unweighted |
| Parallelism | sequential |
You can execute this algorithm on graph projections, subgraphs or portions of the graph.
Functions
elements()
The function converts the given path into a list with the node-relationship-node order.
Input:
path: Path➡ The given path.
Output:
List[Node|Relationship]➡ The given path in the form of node-relationship-node.
Usage:
Use the following query to convert a path into a list of graph objects:
CREATE (:Node1)-[:CONNECTED]->(:Node2)-[:CONNECTED]->(:Node3)-[:CONNECTED]->(:Node4)-[:CONNECTED]->(:Node5);
MATCH path = (:Node1)-[:CONNECTED*4]->(:Node5)
RETURN path.elements(path) AS result;The result is returned in shortened form with () signifying nodes and [] signifying relationships.
+------------------------------------------------------------------------------------------------------------------+
| result |
+------------------------------------------------------------------------------------------------------------------+
| [(:Node1), [:CONNECTED], (:Node2), [:CONNECTED], (:Node3), [:CONNECTED], (:Node4), [:CONNECTED], (:Node5)] |
+------------------------------------------------------------------------------------------------------------------+combine()
The function combines two given paths into one. The end of the first path and the beginning of the second path must match. Throws an exception if the given paths can’t be combined.
Input:
first: Path➡ The first path.second: Path➡ The second path.
Output:
Path➡ The combined path.
Usage:
Use the following query to combine two paths into one:
CREATE (:Node1)-[:CONNECTED]->(:Node2)-[:CONNECTED]->(:Node3)-[:CONNECTED]->(:Node4)-[:CONNECTED]->(:Node5)-[:CONNECTED]->(:Node6);
MATCH (node1:Node1), (node4:Node4), (node6:Node6)
MATCH path1 = (node1)-[:CONNECTED*3]->(node4)
MATCH path2 = (node4)-[:CONNECTED*2]->(node6)
RETURN path.combine(path1, path2) AS result;The result is returned in shortened form with () signifying nodes and [] signifying relationships.
+-----------------------------------------------------------------------------------------------------------------------------+
| result |
+-----------------------------------------------------------------------------------------------------------------------------+
| (:Node1)-[:CONNECTED]->(:Node2)-[:CONNECTED]->(:Node3)-[:CONNECTED]->(:Node4)-[:CONNECTED]->(:Node5)-[:CONNECTED]->(:Node6) |
+-----------------------------------------------------------------------------------------------------------------------------+slice()
The function returns a subpath of the given path.
Input:
path: Path➡ The given path.offset: int = 0➡ The first node index from the given path to be included in the subpath.length: int = -1➡ Length of the subpath. If set to -1 the subpath will end on the final node of the given path.
Output:
Path➡ The subpath of the given path.
Usage:
Use the following query to return a subpath of the given path:
CREATE (:Node1)-[:CONNECTED]->(:Node2)-[:CONNECTED]->(:Node3)-[:CONNECTED]->(:Node4)-[:CONNECTED]->(:Node5);
MATCH path = (:Node1)-[:CONNECTED*4]->(:Node5)
RETURN path.slice(path, 1, -1) AS result;The result is returned in shortened form with () signifying nodes and [] signifying relationships.
+------------------------------------------------------------------------------------------------------+
| result |
+------------------------------------------------------------------------------------------------------+
| (:Node2)-[:CONNECTED]->(:Node3)-[:CONNECTED]->(:Node4)-[:CONNECTED]->(:Node5) |
+------------------------------------------------------------------------------------------------------+Procedures
create()
The procedure creates a path from the given starting node and a list of relationships. Iteratively appends all relationships in the list to the new path until a relationship is null (as a result of optional match) or a relationship from the last node of the path to one of the nodes in the current relationship (the one that isn’t the last one in the path) doesn’t exist.
Input:
-
subgraph: Graph(OPTIONAL) ➡ A specific subgraph, which is an object of type Graph returned by theproject()function, on which the algorithm is run. If subgraph is not specified, the algorithm is computed on the entire graph by default. -
start_node: Node- The starting node of the path. -
relationships: Map- A map with the keyrelthat contains a list of the given relationships.
Output:
path: Path- The created path.
Usage:
Use the following query to create a path from the given starting node and a list of relationships:
MERGE (croatia:Country {name: 'Croatia'})
MERGE (madrid:City {name: 'Madrid'})
MERGE (kutina:City {name: 'Kutina'})
MERGE (real:Club {name: 'Real Madrid'})
MERGE (moslavina:Club {name: 'NK Moslavina'})
MERGE (kutina)-[:In_country]->(croatia)
MERGE (moslavina)-[:In_city]->(kutina)
MERGE (real)-[:In_city]->(madrid);
MATCH (club:Club) OPTIONAL MATCH (club)-[inCity:In_city]->(city:City)
OPTIONAL MATCH (city)-[inCountry:In_country]->(:Country)
CALL path.create(club, {rel:[inCity, inCountry]})
YIELD path
RETURN path;Result:
+------------------------------------------------------------------------------------------------------------------+
| path |
+------------------------------------------------------------------------------------------------------------------+
| (:Club {name: 'Real Madrid'}-[:In_city]->(:City {name 'Madrid'})) |
+------------------------------------------------------------------------------------------------------------------+
| (:Club {name: 'NK Moslavina'}-[:In_city]->(:City {name 'Kutina'})-[:In_country]->(:Country {name 'Croatia'})) |
+------------------------------------------------------------------------------------------------------------------+expand()
The procedure expands from the start node(s) following the given relationships and label filters, from min to max number of allowed hops. Return all paths inside the allowed number of hops, which satisfy relationship and label filters.
Input:
-
subgraph: Graph(OPTIONAL) ➡ A specific subgraph, which is an object of type Graph returned by theproject()function, on which the algorithm is run. If subgraph is not specified, the algorithm is computed on the entire graph by default. -
start: any➡ A node, node ID, or a list of nodes and/or node IDs from which the function will expand. -
relationships: List[string]➡ A list of relationships which the expanding will follow. Relationships can be filtered using the notation described below. -
labels: List[string]➡ A list of labels which will define filtering. Labels can be filtered using the notation described below. -
min_hops: int➡ The minimum number of hops for a path to be returned. -
max_hops: int➡ The maximum number of hops for a path to be returned.
Relationship filters:
| Option | Explanation |
|---|---|
TYPE | Path will expand with either outgoing or incoming relationships of this type. |
<TYPE | Path will expand with incoming relationships of this type. |
TYPE> | Path will expand with outgoing relationships of this type. |
<TYPE> | Path will expand if both incoming and outgoing relationship of this type exists between the same two nodes. |
> | Path will expand with all outgoing relationships. |
< | Path will expand will all incoming relationships. |
If the relationship filter is empty, all relationship types are allowed.
Examples:
Relationship list : [<LOVES, >]: path will expand on all outgoing relationships, and incoming relationshipLOVES.Relationship list : [<LOVES, LOVES]: path will expand on incoming relationshipLOVES, and all directions of relationshipLOVES, making the first element in the relationship list functionally obsolete.Relationship list : []: path will expand on all relationships.
Label filters:
| Option | Explanation |
|---|---|
+LABEL | Label is added to the whitelist. All nodes in the path must have a label in the whitelist. If the whitelist is empty, it is as if all nodes are whitelisted. |
>LABEL | Label is added to the end list. When end list has labels, only paths ending with these labels will be returned, but they can be expanded further, to return paths ending in nodes with end labels beyond it, but the expansion will only go through nodes with whitelisted labels. Labels in the end list do not have to respect the whitelist. |
-LABEL | Label is added to the blacklist. No node in the path will contain labels in the blacklist. The blacklist takes precedence over all other filters. |
/LABEL | Label is added to the termination list. When termination list contains labels, only paths ending with these labels will be returned, and any further expansion is stopped. Labels in the termination list do not have to respect the whitelist. |
Any other label syntax is added to the whitelist. For example, LABEL will be
added to the whitelist as LABEL, and !LABEL will be added to the whitelist
as !LABEL.
To know where the label will be added, look at the first element of the label.
For example, >LABEL> will be added to the end list as LABEL>.
Examples:
Consider the graph provided in the usage section below. In this subsection,
number of hops will be limited from 0 to 2, and the starting node will be Dog.
Label list: ["/Mouse"]- The filtering will return all the paths ending withMouse. Because no labels were added to the whitelist, all labels are considered whitelisted. The filtering will return 3 paths:Dog->Cat->Mouse,Dog<-Human->Mouse,Dog->Mouse.Label list: ["/Mouse", "Cat"]- Now, labelCatis added to the whitelist, becoming the only whitelisted label. The meaning of the filter can now be represented as:"return all paths ending with Mouse, which expand through Cat and Cat only". This filtering will return two paths, one whereDogconnects to theMousedirectly(Dog->Mouse), and one whereCatis included (Dog->Cat->Mouse).Label list: ["/Mouse", "-Cat", "-Human"]- Now, bothCatandHumanare blacklisted, and there is only one eligible path that can reachMouse:Dog->Mouse.
For the final example, the starting node is Cat, and the maximum number of
hops is increased to 4.
Label list: [">Dog", "+Human", "+Wolf"]- Now, only paths ending withDogwill be returned, but they can be further expanded through the nodes with whitelisted labels. This filtering returns 3 paths:Cat<-Dog,Cat<-Dog<-Human->Wolf->Dog,Cat<-Dog<-Wolf<-Human->Dog.
Output:
result: Path➡ all paths expanded from the start node.
Usage:
The database contains the following data:
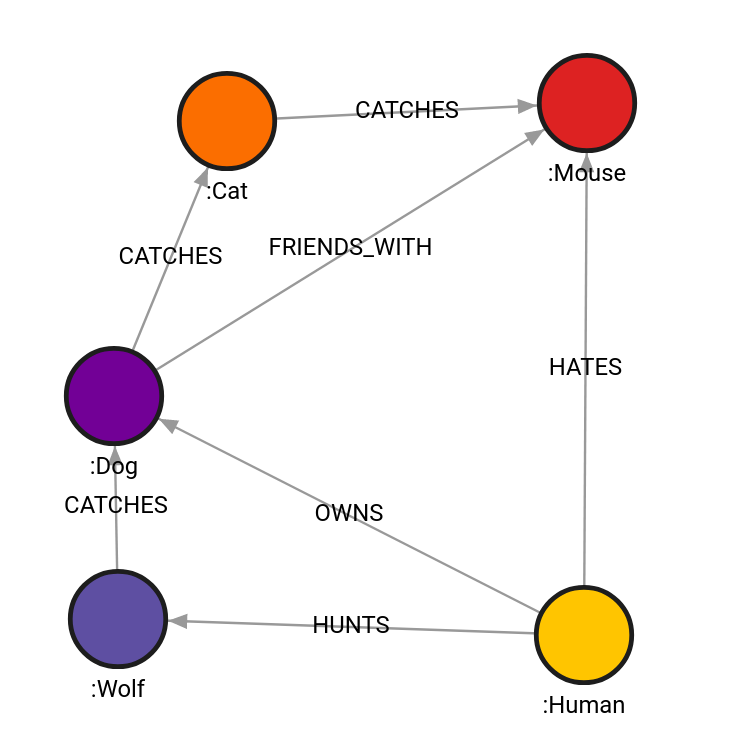
Created with the following Cypher queries:
CREATE (w:Wolf)-[ca:CATCHES]->(d:Dog), (c:Cat), (m:Mouse), (h:Human);
MATCH (w:Wolf), (d:Dog), (c:Cat), (m:Mouse), (h:Human)
WITH w, d, c, m, h
CREATE (d)-[:CATCHES]->(c)
CREATE (c)-[:CATCHES]->(m)
CREATE (d)-[:FRIENDS_WITH]->(m)
CREATE (h)-[:OWNS]->(d)
CREATE (h)-[:HUNTS]->(w)
CREATE (h)-[:HATES]->(m);Example 1
The query will expand from Dog labeled nodes on outgoing relationship CATCHES and
incoming relationship HATES, with Mouse and Human being labels in end
list. Whitelist is empty, hence, all labels are whitelisted.
MATCH (w:Wolf), (d:Dog), (c:Cat), (m:Mouse), (h:Human)
CALL path.expand(d,["CATCHES>","<HATES"],[">Mouse", ">Human"],0,4) YIELD result RETURN result;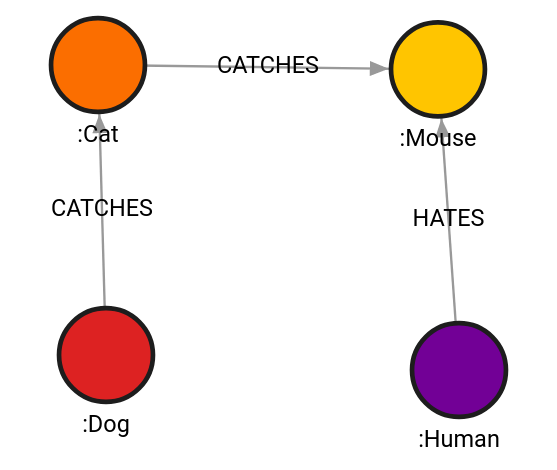
| result |
|---|
{"nodes":[{"id":1,"labels":["Dog"],"properties":{},"type":"node"},{"id":2,"labels":["Cat"],"properties":{},"type":"node"},{"id":3,"labels":["Mouse"],"properties":{},"type":"node"}],"relationships":[{"id":1,"start":1,"end":2,"label":"CATCHES","properties":{},"type":"relationship"},{"id":2,"start":2,"end":3,"label":"CATCHES","properties":{},"type":"relationship"}],"type":"path"} |
{"nodes":[{"id":1,"labels":["Dog"],"properties":{},"type":"node"},{"id":2,"labels":["Cat"],"properties":{},"type":"node"},{"id":3,"labels":["Mouse"],"properties":{},"type":"node"},{"id":4,"labels":["Human"],"properties":{},"type":"node"}],"relationships":[{"id":1,"start":1,"end":2,"label":"CATCHES","properties":{},"type":"relationship"},{"id":2,"start":2,"end":3,"label":"CATCHES","properties":{},"type":"relationship"},{"id":6,"start":4,"end":3,"label":"HATES","properties":{},"type":"relationship"}],"type":"path"} |
Example 2
The query will expand from the Dog labeled node only on incoming
relationships. Also, label Human is blacklisted.
MATCH (w:Wolf), (d:Dog), (c:Cat), (m:Mouse), (h:Human)
CALL path.expand(d,["<"],["-Human"],0,4) YIELD result RETURN result;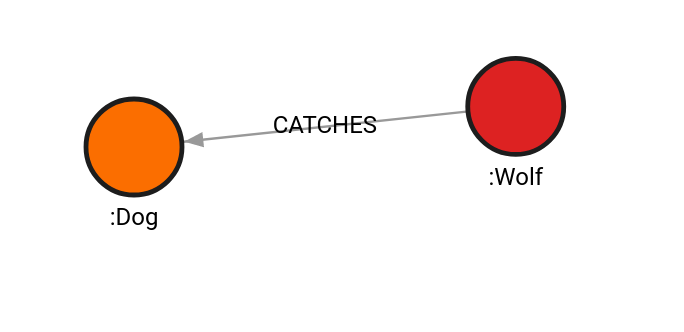
| result |
|---|
{"nodes":[{"id":1,"labels":["Dog"],"properties":{},"type":"node"},{"id":0,"labels":["Wolf"],"properties":{},"type":"node"}],"relationships":[{"id":0,"start":0,"end":1,"label":"CATCHES","properties":{},"type":"relationship"}],"type":"path"} |
Example 2
The query will expand from Dog and Mouse labeled nodes. Cat is the
termination label, and the maximum number of hops is 1. Also, Mouse is passed
as ID, to demonstrate that capability of the expand function.
MATCH (w:Wolf), (d:Dog), (c:Cat), (m:Mouse), (h:Human)
CALL path.expand([d, id(m)],[],["/Cat"],0,1) YIELD result RETURN result;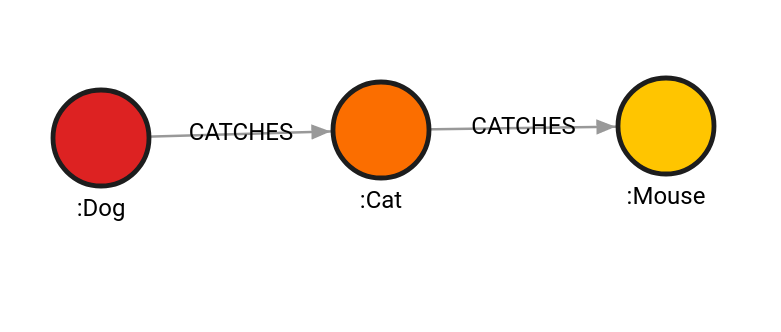
| result |
|---|
{"nodes":[{"id":1,"labels":["Dog"],"properties":{},"type":"node"},{"id":2,"labels":["Cat"],"properties":{},"type":"node"}],"relationships":[{"id":1,"start":1,"end":2,"label":"CATCHES","properties":{},"type":"relationship"}],"type":"path"} |
{"nodes":[{"id":3,"labels":["Mouse"],"properties":{},"type":"node"},{"id":2,"labels":["Cat"],"properties":{},"type":"node"}],"relationships":[{"id":2,"start":2,"end":3,"label":"CATCHES","properties":{},"type":"relationship"}],"type":"path"} |
subgraph_all()
Returns a subgraph in a form of nodes and relationships that can be reached from a given start node. While traversing the graph, the function evaluates nodes based on specified criteria: it adheres to a maximum hop limit, applies relationship and label filters, and ensures each node is visited only once. The procedure uses bfs.
Input:
-
subgraph: Graph(OPTIONAL) ➡ A specific subgraph, which is an object of type Graph returned by theproject()function, on which the algorithm is run. If subgraph is not specified, the algorithm is computed on the entire graph by default. -
start_node: Any➡ A node, node ID, or a list of nodes and/or node IDs from which the traversing will start. -
config: Map (default={})➡ The configuration parameters:
| Name | Type | Default | Description |
|---|---|---|---|
| minHops | Int | 0 | The minimum number of hops in the traversal. Set to 0 if the start node should be included in the subgraph, or 1 otherwise. |
| maxHops | Int | -1 | The maximum number of hops in the traversal. |
| relationshipFilter | List | [ ] | List of relationships which the subgraph formation will follow. Relationships can be filtered using the notation described below. |
| labelFilter | List | [ ] | List of labels which will define filtering. Labels can be filtered using the notation described below. |
| filterStartNode | Bool | False | Whether the labelFilter applies to the start nodes. |
Relationship filters:
| Option | Explanation |
|---|---|
TYPE | Path will expand with either outgoing or incoming relationships of this type. |
<TYPE | Path will expand with incoming relationships of this type. |
TYPE> | Path will expand with outgoing relationships of this type. |
<TYPE> | Path will expand if both incoming and outgoing relationship of this type exists between the same two nodes. |
> | Path will expand with all outgoing relationships. |
< | Path will expand will all incoming relationships. |
If the relationship filter is empty, all relationship types are allowed.
Examples:
Relationship list : [<LOVES, >]: The path will expand on all outgoing relationships, and incoming relationshipLOVES.Relationship list : [<LOVES, LOVES]: The path will expand on incoming relationshipLOVES, and all directions of relationshipLOVES, making the first element in the relationship list functionally obsolete.Relationship list : []: The path will expand on all relationships.
Label filters:
Label filters are described in the table below:
| Option | Explanation |
|---|---|
+LABEL | Label is added to the whitelist. All nodes in the path must have a label in the whitelist. If the whitelist is empty, it is as if all nodes are whitelisted. |
>LABEL | Label is added to the end list. When end list has labels, only paths ending with these labels will be returned, but they can be expanded further, to return paths ending in nodes with end labels beyond it, but the expansion will only go through nodes with whitelisted labels. Labels in the end list do not have to respect the whitelist. |
-LABEL | Label is added to the blacklist. No node in the path will contain labels in the blacklist. The blacklist takes precedence over all other filters. |
/LABEL | Label is added to the termination list. When termination list contains labels, only paths ending with these labels will be returned, and any further expansion is stopped. Labels in the termination list do not have to respect the whitelist. |
Any other label syntax is added to the whitelist. For example, LABEL will be
added to the whitelist as LABEL, and !LABEL will be added to the whitelist
as !LABEL.
To know where the label will be added, look at the first element of the label.
For example, >LABEL> will be added to the end list as LABEL>.
Examples
Consider the graph provided in the usage section below. In this subsection, number of hops will be limited from 0 to 2, and the starting node will be Dog.
Label list: ["/Mouse"]- The filtering will return all the paths ending withMouse. Because no labels were added to the whitelist, all labels are considered whitelisted. This filtering will return 3 paths:Dog->Cat->Mouse,Dog<-Human->Mouse,Dog->Mouse.Label list: ["/Mouse", "Cat"]- Now, labelCatis added to the whitelist, becoming the only whitelisted label. The meaning of the filter can now be represented as:"return all paths ending with Mouse, which expand through Cat and Cat only". This filtering will return two paths, one whereDogconnects to theMousedirectly (Dog->Mouse), and one whereCatis included (Dog->Cat->Mouse).Label list: ["/Mouse", "-Cat", "-Human"]- Now, bothCatandHumanare blacklisted, and there is only one eligible path that can reachMouse:Dog->Mouse.
For the final example, the starting node is Cat, and the maximum number of
hops is increased to 4.
Label list: [">Dog", "+Human", "+Wolf"]- Now, only paths ending withDogwill be returned, but they can be further expanded through the nodes with whitelisted labels. This filtering returns 3 paths:Cat<-Dog,Cat<-Dog<-Human->Wolf->Dog,Cat<-Dog<-Wolf<-Human->Dog.
Output:
nodes: List[Node]➡ A list of nodes which form the subgraph.rels: List[Relationship]➡ A list of relationships which form the subgraph.
Usage:
The database contains the following data:
Created with the following Cypher queries:
CREATE (w:Wolf)-[ca:CATCHES]->(d:Dog), (c:Cat), (m:Mouse), (h:Human);
MATCH (w:Wolf), (d:Dog), (c:Cat), (m:Mouse), (h:Human)
WITH w, d, c, m, h
CREATE (d)-[:CATCHES]->(c)
CREATE (c)-[:CATCHES]->(m)
CREATE (d)-[:FRIENDS_WITH]->(m)
CREATE (h)-[:OWNS]->(d)
CREATE (h)-[:HUNTS]->(w)
CREATE (h)-[:HATES]->(m);Example 1
Create a subgraph from Dog on outgoing relationship CATCHES and incoming
relationship HATES, with Mouse and Human being labels in end list.
Whitelist is empty, hence, all labels are whitelisted.
MATCH (w:Wolf), (d:Dog), (c:Cat), (m:Mouse), (h:Human)
CALL path.subgraph_all(d, {
relationshipFilter: ["CATCHES>","<HATES"],
labelFilter: [">Mouse", ">Human"],
minHops: 0,
maxHops: 4
})
YIELD nodes, rels
RETURN nodes, rels;
The results should be identical to the ones below, except for the id values
that depend on the internal database id values.
+----------------------------+----------------------------+
| nodes | rels |
+----------------------------+----------------------------+
| { | { |
| "id": 3, | "id": 6, |
| "labels": [ | "start": 4, |
| "Mouse" | "end": 3, |
| ], | "label": "HATES", |
| "properties": {}, | "properties": {}, |
| "type": "node" | "type": "relationship" |
| } | } |
+----------------------------+----------------------------+
| { | |
| "id": 4, | |
| "labels": [ | |
| "Human" | |
| ], | |
| "properties": {}, | |
| "type": "node" | |
| } | |
+----------------------------+----------------------------+Example 2
Create subgraph from Dog only on incoming relationships. Also, Human is blacklisted.
MATCH (w:Wolf), (d:Dog), (c:Cat), (m:Mouse), (h:Human)
CALL path.subgraph_all(d, {
relationshipFilter: ["<"],
labelFilter: ["-Human"],
minHops: 0,
maxHops: 4
})
YIELD nodes, rels
RETURN nodes, rels;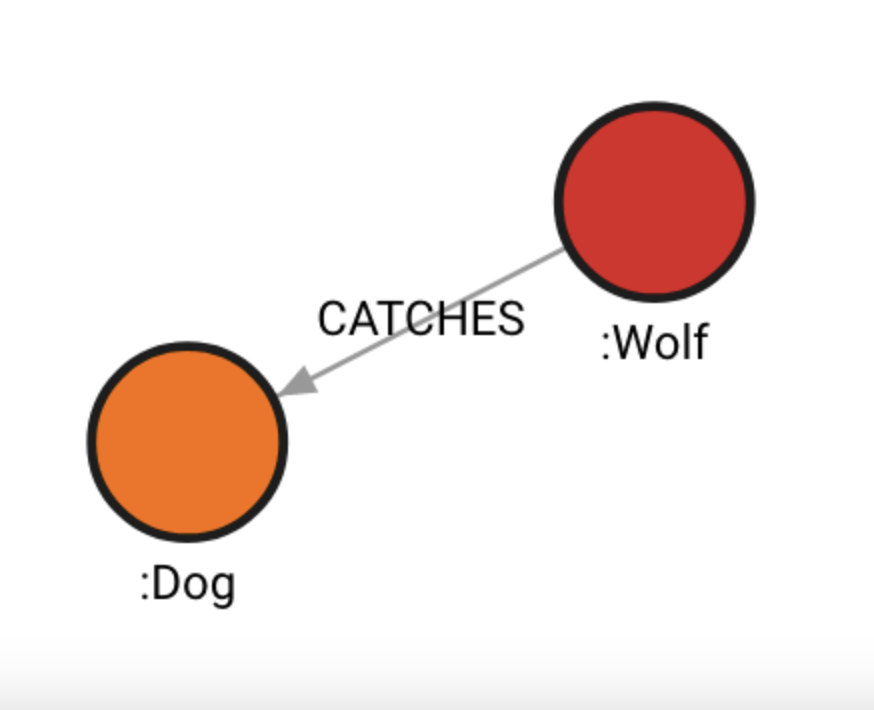
The results should be identical to the ones below, except for the id values that depend on the internal database id values.
+----------------------------+----------------------------+
| nodes | rels |
+----------------------------+----------------------------+
| { | { |
| "id": 1, | "id": 0, |
| "labels": [ | "start": 0, |
| "Dog" | "end": 1, |
| ], | "label": "CATCHES", |
| "properties": {}, | "properties": {}, |
| "type": "node" | "type": "relationship" |
| } | } |
+----------------------------+----------------------------+
| { | |
| "id": 0, | |
| "labels": [ | |
| "Wolf" | |
| ], | |
| "properties": {}, | |
| "type": "node" | |
| } | |
+----------------------------+----------------------------+subgraph_nodes()
The procedure returns a subgraph made out of those nodes that can be reached from a given start node. While traversing the graph, the function evaluates nodes based on specified criteria: it adheres to a maximum hop limit, applies relationship and label filters, and ensures each node is visited only once.
Input:
subgraph: Graph(OPTIONAL) ➡ A specific subgraph, which is an object of type Graph returned by theproject()function, on which the algorithm is run. If subgraph is not specified, the algorithm is computed on the entire graph by default.start_node: Any➡ A node, node ID, or a list of nodes and/or node IDs from which the traversing will start.config: Map (default={})➡ Configuration parameters:
| Name | Type | Default | Description |
|---|---|---|---|
| minHops | Int | 0 | The minimum number of hops in the traversal. Set to 0 if the start node should be included in the subgraph, or 1 otherwise. |
| maxHops | Int | -1 | The maximum number of hops in the traversal. |
| relationshipFilter | List | [ ] | List of relationships which the subgraph formation will follow. Explained in detail below. |
| labelFilter | List | [ ] | List of labels which will define filtering. Explained in detail below. |
| filterStartNode | Bool | False | Whether the labelFilter applies to the start nodes. |
Relationship filters
| Option | Explanation |
|---|---|
TYPE | Path will expand with either outgoing or incoming relationships of this type. |
<TYPE | Path will expand with incoming relationships of this type. |
TYPE> | Path will expand with outgoing relationships of this type. |
<TYPE> | Path will expand if both incoming and outgoing relationship of this type exists between the same two nodes. |
> | Path will expand with all outgoing relationships. |
< | Path will expand will all incoming relationships. |
If the relationship filter is empty, all relationship types are allowed.
Examples:
Relationship list : [<LOVES, >]: The path will expand on all outgoing relationships, and incoming relationshipLOVES.Relationship list : [<LOVES, LOVES]: The path will expand on incoming relationshipLOVES, and all directions of relationshipLOVES, making the first element in the relationship list functionally obsolete.Relationship list : []: The path will expand on all relationships.
Label filter
| Option | Explanation |
|---|---|
+LABEL | Label is added to the whitelist. All nodes in the path must have a label in the whitelist. If the whitelist is empty, it is as if all nodes are whitelisted. |
>LABEL | Label is added to the end list. When end list has labels, only paths ending with these labels will be returned, but they can be expanded further, to return paths ending in nodes with end labels beyond it, but the expansion will only go through nodes with whitelisted labels. Labels in the end list do not have to respect the whitelist. |
-LABEL | Label is added to the blacklist. No node in the path will contain labels in the blacklist. The blacklist takes precedence over all other filters. |
/LABEL | Label is added to the termination list. When termination list contains labels, only paths ending with these labels will be returned, and any further expansion is stopped. Labels in the termination list do not have to respect the whitelist. |
Any other label syntax is added to the whitelist. For example, LABEL will be added to the whitelist as LABEL, and !LABEL will be added to the whitelist as !LABEL. NOTE: when deciding where the label will be added, it is done by looking at the first element of the label. For example, >LABEL> will be added to the end list as LABEL>.
Examples:
Consider the graph provided in the usage section below. In this subsection, number of hops will be limited from 0 to 2, and the starting node will be Dog.
Label list: ["/Mouse"]- The filtering will return all the paths ending withMouse. Because no labels were added to the whitelist, all labels are considered whitelisted. This filtering will return 3 paths:Dog->Cat->Mouse,Dog<-Human->Mouse,Dog->Mouse.Label list: ["/Mouse", "Cat"]- Now, labelCatis added to the whitelist, becoming the only whitelisted label. The meaning of the filter can now be represented as:"return all paths ending with Mouse, which expand through Cat and Cat only". This filtering will return two paths, one whereDogconnects to theMousedirectly (Dog->Mouse), and one whereCatis included (Dog->Cat->Mouse).Label list: ["/Mouse", "-Cat", "-Human"]- Now, bothCatandHumanare blacklisted, and there is only one eligible path that can reachMouse:Dog->Mouse.
For the final example, the starting node is Cat, and the maximum number of
hops is increased to 4.
Label list: [">Dog", "+Human", "+Wolf"]- Now, only paths ending withDogwill be returned, but they can be further expanded through the nodes with whitelisted labels. This filtering returns 3 paths:Cat<-Dog,Cat<-Dog<-Human->Wolf->Dog,Cat<-Dog<-Wolf<-Human->Dog.
Output:
nodes: Node➡ The nodes that form the subgraph.
Usage:
Usage:
The database contains the following data:
Created with the following Cypher queries:
CREATE (w:Wolf)-[ca:CATCHES]->(d:Dog), (c:Cat), (m:Mouse), (h:Human);
MATCH (w:Wolf), (d:Dog), (c:Cat), (m:Mouse), (h:Human)
WITH w, d, c, m, h
CREATE (d)-[:CATCHES]->(c)
CREATE (c)-[:CATCHES]->(m)
CREATE (d)-[:FRIENDS_WITH]->(m)
CREATE (h)-[:OWNS]->(d)
CREATE (h)-[:HUNTS]->(w)
CREATE (h)-[:HATES]->(m);Example 1
Create a subgraph from Dog on outgoing relationship CATCHES and incoming
relationship HATES, with Mouse and Human being labels in end list.
Whitelist is empty, hence, all labels are whitelisted.
MATCH (w:Wolf), (d:Dog), (c:Cat), (m:Mouse), (h:Human)
CALL path.subgraph_nodes(d, {
relationshipFilter: ["CATCHES>","<HATES"],
labelFilter: [">Mouse", ">Human"],
minHops: 0,
maxHops: 4
})
YIELD nodes
RETURN nodes;
The results should be identical to the ones below, except for the id values
that depend on the internal database id values.
+----------------------------+
| nodes |
+----------------------------+
| { |
| "id": 3, |
| "labels": [ |
| "Mouse" |
| ], |
| "properties": {}, |
| "type": "node" |
| } |
+----------------------------+
| { |
| "id": 4, |
| "labels": [ |
| "Human" |
| ], |
| "properties": {}, |
| "type": "node" |
| } |
+----------------------------+Example 2
Create subgraph from Dog only on incoming relationships. Also, Human is
blacklisted.
MATCH (w:Wolf), (d:Dog), (c:Cat), (m:Mouse), (h:Human)
CALL path.subgraph_nodes(d, {
relationshipFilter: ["<"],
labelFilter: ["-Human"],
minHops: 0,
maxHops: 4
})
YIELD nodes
RETURN nodes
The results should be identical to the ones below, except for the id values
that depend on the internal database id values.
+----------------------------+
| nodes |
+----------------------------+
| { |
| "id": 1, |
| "labels": [ |
| "Dog" |
| ], |
| "properties": {}, |
| "type": "node" |
| } |
+----------------------------+
| { |
| "id": 0, |
| "labels": [ |
| "Wolf" |
| ], |
| "properties": {}, |
| "type": "node" |
| } |
+----------------------------+