export_util
Module for exporting a graph database or query results in different formats.
Currently, this module supports:
- exporting the database in a JSON format to a file or a stream
- exporting certain nodes and relationships in a JSON format to a file or a stream
- exporting the database to Cypher queries in a file or a stream
- exporting query results in a CSV format to a file or a stream
- exporting certain nodes and relationships in a CSV format to a file or a stream
- exporting database in a graphML file format to a file or a stream.
| Trait | Value |
|---|---|
| Module type | util |
| Implementation | Python |
| Parallelism | sequential |
Procedures
You can execute this algorithm on graph projections, subgraphs or portions of the graph.
json()
The procedure exports the graph database to a local file.
Input:
-
subgraph: Graph(OPTIONAL) ➡ A specific subgraph, which is an object of type Graph returned by theproject()function, on which the algorithm is run. If subgraph is not specified, the algorithm is computed on the entire graph by default. -
path: string➡ Path to the JSON file containing the exported graph database. -
config: Map➡ Map of the configuration with the following keys:stream: boolean (default=False)➡ Is the data exported to a stream rather than a file.write_properties: boolean (default=True)➡ Are the properties exported as well.
Output:
path: string➡ The path to the exported file.data: string➡ Exported data if thestreamflag was set toTrue.
Usage:
The path you have to provide as procedure argument depends on how you started
Memgraph.
If you ran Memgraph with Docker, database will be exported to a JSON file inside
the Docker container. We recommend exporting the database to the JSON file
inside the /usr/lib/memgraph/query_modules directory.
You can call the procedure by running the following query:
CALL export_util.json(path);The path is the path to the JSON file inside the
/usr/lib/memgraph/query_modules directory in the running Docker container (e.g.,
/usr/lib/memgraph/query_modules/export.json).
You can copy the exported JSON file to your local file
system
using the docker cp command.
json_graph()
Exports the given nodes and relationships to the JSON format. All nodes from the relationships have to be contained in the nodes as well.
Input:
-
subgraph: Graph(OPTIONAL) ➡ A specific subgraph, which is an object of type Graph returned by theproject()function, on which the algorithm is run. If subgraph is not specified, the algorithm is computed on the entire graph by default. -
nodes: List[Node]➡ The list of nodes that need to be exported. -
relationships: List[Relationship]➡ The list of relationships that need to be exported. -
path: string➡ The path to the JSON file containing the exported data. -
config: Map➡ Map of the configuration with the following keys:stream: boolean (default=False)➡ Is the data exported to a stream rather than a file.write_properties: boolean (default=True)➡ Are the properties exported as well.
Output:
path: string➡ The path to the exported file.data: string➡ Exported data if thestreamflag was set toTrue.
cypher_all()
Exports the database as a list of Cypher queries in the specified .cyp file or
stream.
Input:
-
subgraph: Graph(OPTIONAL) ➡ A specific subgraph, which is an object of type Graph returned by theproject()function, on which the algorithm is run. If subgraph is not specified, the algorithm is computed on the entire graph by default. -
path: string➡ The path to the Cypher file containing the exported graph database. -
config: Map➡ The map of the configuration with the following keys:stream: boolean (default= False)➡ Is the data exported to a stream rather than a file.write_properties: boolean (default=True)➡ Are the properties exported as well.write_triggers: boolean (default=True)➡ Are triggers exported as well.write_indexes: boolean (default=True)➡ Are indexes exported as well.write_constraints: boolean (default=True)➡ Are constraints exported as well.
Output:
path: string➡ The path to the exported file.data: string➡ Exported data if thestreamflag was set toTrue.
csv_query()
The procedure exports query results to a CSV file.
Input:
-
subgraph: Graph(OPTIONAL) ➡ A specific subgraph, which is an object of type Graph returned by theproject()function, on which the algorithm is run. If subgraph is not specified, the algorithm is computed on the entire graph by default. -
query: string➡ The query from which the results will be saved to a CSV file. -
file_path: string➡ The path to the CSV file where the query results will be exported. -
stream: boolean (default=False)➡ Will the procedure return a stream of query results in CSV format rather than a file.
Output:
file_path: string➡ The path to the CSV file where the query results are exported.data: string➡ A stream of query results in a CSV format if thestreamflag was set to true.
Usage:
The file_path you have to provide as procedure argument depends on how you started
Memgraph.
If you ran Memgraph with Docker, query results will be exported to a CSV file inside
the Docker container. We recommend exporting the database to the CSV file
inside the /usr/lib/memgraph/query_modules directory.
You can call the procedure by running the following query:
CALL export_util.csv_query(path);The path is the path to a CSV file inside the
/usr/lib/memgraph/query_modules directory in the running Docker container (e.g.,
/usr/lib/memgraph/query_modules/export.csv).
You can copy the exported CSV file to your local file
system
using the docker cp command.
csv_graph()
The procedure exports the given lists of nodes and relationships into a CSV file.
Input:
nodes_list: List[Node]➡ The list of nodes that will be exported.relationships_list: List[Relationship]➡ The list of relationships that will be exported.path: string (default="./exported_file.csv")➡ The path where the exported file will be saved, ending with the filename, for example,folder_outer/folder/file.csv.config: Map➡ The map of the configuration with the following keys:delimiter: string (default=",")➡ The delimiter used to separate fields in the CSV file.quotes: string (default="All")➡ The type of quoting to apply to fields in the CSV file. Possible values arenonefor no quotes added,ifNeededfor adding quotes only when necessary,Allto always use quote.separateHeader: boolean (default=False)➡ Indicates whether the CSV file header should be separated into its own file. IfTrue, a file namedheader.csvwill be created in the specified or default directory.stream: boolean (default=False)➡ Will the procedure return a stream of data rather than a file.
Output:
data: string➡ Ifstreamflag was set toTrue, a string stream representation of data.path: string➡ The path to the exported CSV file.
File structure
The CSV file columns are structured in the following way:
| _id | _labels | node_properties_sorted | _start | _end | _type | relationship_properties_sorted |
|---|---|---|---|---|---|---|
| node ID | node labels | alphabetically sorted properties of all nodes (all node properties present in the graph) | ID of the start node of a relationship | ID of the end node of a relationship | type of relationship | alphabetically sorted properties of all relationships (all relationship properties present in the graph) |
For example, consider a simple graph created with the following Cypher query:
CREATE (d:Dog {name: "Rex", breed: "Dalmatian"})-[i:IS_OWNED_BY {rel_property: 30}]->(h:Human {name: "Carl", age: 50});The Dog node’s ID is 0, and the Human node’s ID is 1.
Exporting would result in a CSV file structured in the following way:
| _id | _labels | age | breed | name | _start | _end | _type | rel_property |
|---|---|---|---|---|---|---|---|---|
| 0 | :Dog | Dalmatian | Rex | |||||
| 1 | :Human | 50 | Carl | |||||
| 0 | 1 | IS_OWNED_BY | 30 |
Usage without configurations:
The following example will show how to use the csv_graph procedure without any additional configuration.
First, create a graph using the following queries:
CREATE (d:Dog {name: "Rex", breed: "Dalmatian"})-[i:IS_OWNED_BY {rel_property: 30}]->(h:Human {name: "Carl", age: 50});
CREATE (hs:Human:Soldier {branch : "Army"})-[t:TRAINS { duration: duration("P10D")}]->(d:Dog:K9 {name: "Bolt", years_of_service: 3});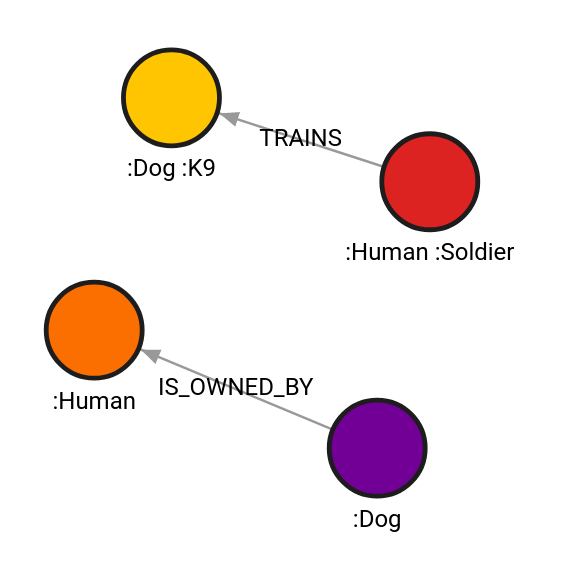
Then run the query to export nodes and relationships into a file.csv file in /demontration/export directory:
MATCH (n)
OPTIONAL MATCH (n)-[r]-()
WITH COLLECT(DISTINCT n) AS nodes, COLLECT(DISTINCT r) AS relationships
CALL export_util.csv_graph(nodes, relationships, "/demonstration/export/Documents/file.csv", {}) YIELD data, path RETURN data, path;CSV result as a table:
| _id | _labels | age | branch | breed | name | years_of_service | _start | _end | _type | duration | rel_property |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | :Dog | Dalmatian | Rex | ||||||||
| 1 | :Human | 50 | Carl | ||||||||
| 2 | :Human:Soldier | Army | |||||||||
| 3 | :Dog:K9 | Bolt | 3 | ||||||||
| 0 | 1 | IS_OWNED_BY | 30 | ||||||||
| 2 | 3 | TRAINS | duration(10 days,0:00:00) |
CSV file:
"_id","_labels","age","branch","breed","name","years_of_service","_start","_end","_type","duration","rel_property"
"0",":Dog","","","Dalmatian","Rex","","","","","",""
"1",":Human","50","","","Carl","","","","","",""
"2",":Human:Soldier","","Army","","","","","","","",""
"3",":Dog:K9","","","","Bolt","3","","","","",""
"","","","","","","","0","1","IS_OWNED_BY","","30"
"","","","","","","","2","3","TRAINS","duration(10 days, 0:00:00)",""Usage with configurations:
The following example will show how to use the csv_graph procedure with additional configuration.
First, create a graph using the following queries:
CREATE (d:Dog {name: "Rex", breed: "Dalmatian"})-[i:IS_OWNED_BY {rel_property: 30}]->(h:Human {name: "Carl", age: 50});
CREATE (hs:Human:Soldier {branch : "Army"})-[t:TRAINS { duration: duration("P10D")}]->(d:Dog:K9 {name: "Bolt", years_of_service: 3});
Delimiter
The following query is an example of using a different delimiter than default.
MATCH (n)
OPTIONAL MATCH (n)-[r]-()
WITH COLLECT(DISTINCT n) AS nodes, COLLECT(DISTINCT r) AS relationships
CALL export_util.csv_graph(nodes, relationships, "/demonstration/export/Documents/file.csv", {delimiter : "|"}) YIELD data, path RETURN data, path;"_id"|"_labels"|"age"|"branch"|"breed"|"name"|"years_of_service"|"_start"|"_end"|"_type"|"duration"|"rel_property"
"0"|":Dog"|""|""|"Dalmatian"|"Rex"|""|""|""|""|""|""
"1"|":Human"|"50"|""|""|"Carl"|""|""|""|""|""|""
"2"|":Human:Soldier"|""|"Army"|""|""|""|""|""|""|""|""
"3"|":Dog:K9"|""|""|""|"Bolt"|"3"|""|""|""|""|""
""|""|""|""|""|""|""|"0"|"1"|"IS_OWNED_BY"|""|"30"
""|""|""|""|""|""|""|"2"|"3"|"TRAINS"|"duration(10 days, 0:00:00)"|""Quoting
The following query is an example of using different delimiters.
Run this query with quoting "All":
MATCH (n)
OPTIONAL MATCH (n)-[r]-()
WITH COLLECT(DISTINCT n) AS nodes, COLLECT(DISTINCT r) AS relationships
CALL export_util.csv_graph(nodes, relationships, "/demonstration/export/Documents/file.csv", {quotes : "All"}) YIELD data, path RETURN data, path;Result is the following CSV file:
"_id","_labels","age","branch","breed","name","years_of_service","_start","_end","_type","duration","rel_property"
"0",":Dog","","","Dalmatian","Rex","","","","","",""
"1",":Human","50","","","Carl","","","","","",""
"2",":Human:Soldier","","Army","","","","","","","",""
"3",":Dog:K9","","","","Bolt","3","","","","",""
"","","","","","","","0","1","IS_OWNED_BY","","30"
"","","","","","","","2","3","TRAINS","duration(10 days, 0:00:00)",""Run this query with quoting "ifNeeded":
MATCH (n)
OPTIONAL MATCH (n)-[r]-()
WITH COLLECT(DISTINCT n) AS nodes, COLLECT(DISTINCT r) AS relationships
CALL export_util.csv_graph(nodes, relationships, "/demonstration/export/Documents/file.csv", {quotes : "ifNeeded"}) YIELD data, path RETURN data, path;Result is the following CSV file:
_id,_labels,age,branch,breed,name,years_of_service,_start,_end,_type,duration,rel_property
0,:Dog,,,Dalmatian,Rex,,,,,,
1,:Human,50,,,Carl,,,,,,
2,:Human:Soldier,,Army,,,,,,,,
3,:Dog:K9,,,,Bolt,3,,,,,
,,,,,,,0,1,IS_OWNED_BY,,30
,,,,,,,2,3,TRAINS,"duration(10 days, 0:00:00)",Run this query with quoting "none":
MATCH (n)
OPTIONAL MATCH (n)-[r]-()
WITH COLLECT(DISTINCT n) AS nodes, COLLECT(DISTINCT r) AS relationships
CALL export_util.csv_graph(nodes, relationships, "/demonstration/export/Documents/file.csv", {quotes : "none"}) YIELD data, path RETURN data, path;_id,_labels,age,branch,breed,name,years_of_service,_start,_end,_type,duration,rel_property
0,:Dog,,,Dalmatian,Rex,,,,,,
1,:Human,50,,,Carl,,,,,,
2,:Human:Soldier,,Army,,,,,,,,
3,:Dog:K9,,,,Bolt,3,,,,,
,,,,,,,0,1,IS_OWNED_BY,,30
,,,,,,,2,3,TRAINS,duration(10 days\, 0:00:00),SeparateHeader
The following query is an example separating the header.
MATCH (n)
OPTIONAL MATCH (n)-[r]-()
WITH COLLECT(DISTINCT n) AS nodes, COLLECT(DISTINCT r) AS relationships
CALL export_util.csv_graph(nodes, relationships, "/demonstration/export/Documents/file.csv", {separateHeader: true}) YIELD data, path RETURN data, path;The CSV file containing the header:
"_id","_labels","age","branch","breed","name","years_of_service","_start","_end","_type","duration","rel_property"The CSV file containing the rest of the data:
"0",":Dog","","","Dalmatian","Rex","","","","","",""
"1",":Human","50","","","Carl","","","","","",""
"2",":Human:Soldier","","Army","","","","","","","",""
"3",":Dog:K9","","","","Bolt","3","","","","",""
"","","","","","","","0","1","IS_OWNED_BY","","30"
"","","","","","","","2","3","TRAINS","duration(10 days, 0:00:00)",""Stream
Example of exporting data to a stream. When the stream flag is True, the CSV file is not created, so the file path can be set as "" and ignored.
MATCH (n)
OPTIONAL MATCH (n)-[r]-()
WITH COLLECT(DISTINCT n) AS nodes, COLLECT(DISTINCT r) AS relationships
CALL export_util.csv_graph(nodes, relationships, "", {stream: True}) YIELD data, path RETURN data;Stream:
"_id","_labels","age","branch","breed","name","years_of_service","_start","_end","_type","duration","rel_property"
"0",":Dog","","","Dalmatian","Rex","","","","","",""
"1",":Human","50","","","Carl","","","","","",""
"2",":Human:Soldier","","Army","","","","","","","",""
"3",":Dog:K9","","","","Bolt","3","","","","",""
"","","","","","","","0","1","IS_OWNED_BY","","30"
"","","","","","","","2","3","TRAINS","duration(10 days, 0:00:00)",""graphml()
The procedure exports graph database to a graphML file.
Input:
path: string➡ path to the graphML file that will contain the exported graph database.config: Map➡ The map of the configuration with the following keys:stream: boolean (default=False)➡ Will the procedure return a stream of data rather than a file.format: string(default="") ➡ Set the export format to “gephi” or “tinkerpop”.caption: List➡ A list of keys of properties, the value of which is eligible as value for thelabeldata element in Gephi format. Order is important and if no match is found, then there is a fallback to the node’s first property. If the node has no properties then the ID is used.useTypes: boolean (default=False)➡ Is the information about property values’ type stored.leaveOutLabels: boolean (default=False)➡ Are node’s labels stored.leaveOutProperties: boolean (default=False)➡ Are node’s properties stored.
Output:
status: string➡ The data if thestreamflag is set toTrue,successotherwise.
Usage:
The path you have to provide as procedure argument depends on how you started
Memgraph.
If you ran Memgraph with Docker, database will be exported to a graphML file inside
the Docker container. We recommend exporting the database to the graphML file
inside the /usr/lib/memgraph/query_modules directory.
You can call the procedure by running the following query:
CALL export_util.graphml(path);The path is the path to the graphML file inside the
/usr/lib/memgraph/query_modules directory in the running Docker container (e.g.,
/usr/lib/memgraph/query_modules/export.graphml).
You can copy the exported file to your local file
system
using the docker cp command.
Examples
Export database to a JSON file
Database state
Create a simple graph database by running the following queries:
CREATE (n:Person {name:"Anna"}), (m:Person {name:"John"}), (k:Person {name:"Kim"})
CREATE (n)-[:IS_FRIENDS_WITH]->(m), (n)-[:IS_FRIENDS_WITH]->(k), (m)-[:IS_MARRIED_TO]->(k);The queries will create the following graph:
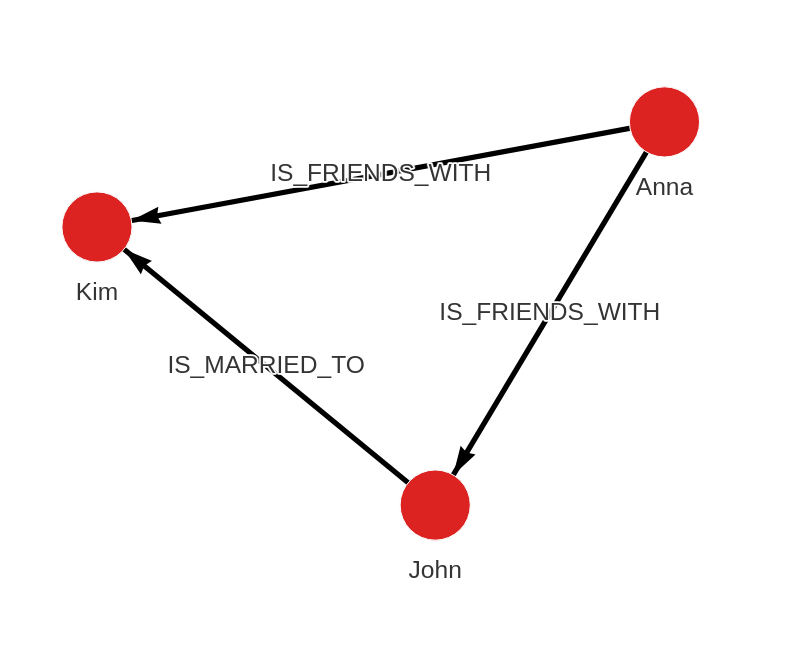
Export data
If you’re using Memgraph with Docker, the following Cypher query will
export the database to the export.json file in the
/usr/lib/memgraph/query_modules directory inside the running Docker container:
CALL export_util.json("/usr/lib/memgraph/query_modules/export.json");If you’re using Memgraph on Ubuntu, Debian, RPM package or WSL, the
following Cypher query will export the database to the export.json file in the
/users/my_user/export_folder.
CALL export_util.json("/users/my_user/export_folder/export.json");Results
The export.json file should be similar to the one below, except for the
id values that depend on the internal database id values:
[
{
"id": 6114,
"labels": [
"Person"
],
"properties": {
"name": "Anna"
},
"type": "node"
},
{
"id": 6115,
"labels": [
"Person"
],
"properties": {
"name": "John"
},
"type": "node"
},
{
"id": 6116,
"labels": [
"Person"
],
"properties": {
"name": "Kim"
},
"type": "node"
},
{
"end": 6115,
"id": 21120,
"label": "IS_FRIENDS_WITH",
"properties": {},
"start": 6114,
"type": "relationship"
},
{
"end": 6116,
"id": 21121,
"label": "IS_FRIENDS_WITH",
"properties": {},
"start": 6114,
"type": "relationship"
},
{
"end": 6116,
"id": 21122,
"label": "IS_MARRIED_TO",
"properties": {},
"start": 6115,
"type": "relationship"
}
]Export database to a Cypher file
Database state
The database contains the following data:
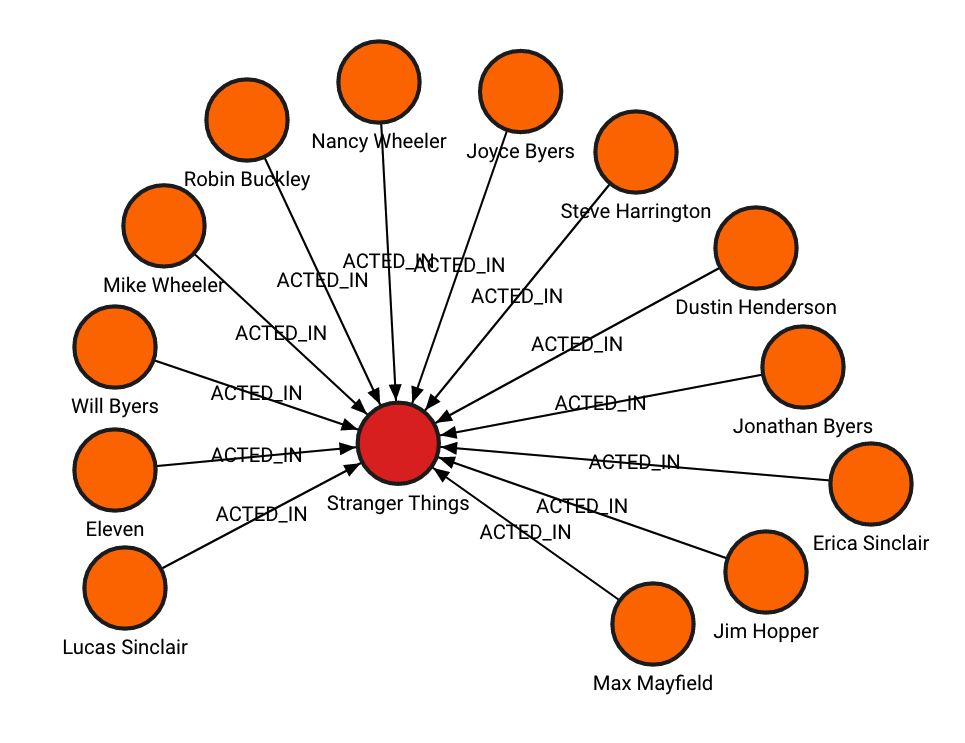
Created using the following queries:
CREATE (StrangerThings:TVShow {title:'Stranger Things', released:2016, program_creators:['Matt Duffer', 'Ross Duffer']})
CREATE (Eleven:Character {name:'Eleven', portrayed_by:'Millie Bobby Brown'})
CREATE (JoyceByers:Character {name:'Joyce Byers', portrayed_by:'Winona Ryder'})
CREATE (JimHopper:Character {name:'Jim Hopper', portrayed_by:'David Harbour'})
CREATE (MikeWheeler:Character {name:'Mike Wheeler', portrayed_by:'Finn Wolfhard'})
CREATE (DustinHenderson:Character {name:'Dustin Henderson', portrayed_by:'Gaten Matarazzo'})
CREATE (LucasSinclair:Character {name:'Lucas Sinclair', portrayed_by:'Caleb McLaughlin'})
CREATE (NancyWheeler:Character {name:'Nancy Wheeler', portrayed_by:'Natalia Dyer'})
CREATE (JonathanByers:Character {name:'Jonathan Byers', portrayed_by:'Charlie Heaton'})
CREATE (WillByers:Character {name:'Will Byers', portrayed_by:'Noah Schnapp'})
CREATE (SteveHarrington:Character {name:'Steve Harrington', portrayed_by:'Joe Keery'})
CREATE (MaxMayfield:Character {name:'Max Mayfield', portrayed_by:'Sadie Sink'})
CREATE (RobinBuckley:Character {name:'Robin Buckley', portrayed_by:'Maya Hawke'})
CREATE (EricaSinclair:Character {name:'Erica Sinclair', portrayed_by:'Priah Ferguson'})
CREATE
(Eleven)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(JoyceByers)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(JimHopper)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(MikeWheeler)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(DustinHenderson)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(LucasSinclair)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(NancyWheeler)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(JonathanByers)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(WillByers)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(SteveHarrington)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(MaxMayfield)-[:ACTED_IN {seasons:[2, 3, 4]}]->(StrangerThings),
(RobinBuckley)-[:ACTED_IN {seasons:[3, 4]}]->(StrangerThings),
(EricaSinclair)-[:ACTED_IN {seasons:[2, 3, 4]}]->(StrangerThings);Export data
Use the following query to export data into a Cypher file:
CALL export_util.cypher_all("export.cyp") YIELD path RETURN path;The query will result in the export.cyp file with the following content:
CREATE (n:TVShow:_IMPORT_ID {title: 'Stranger Things', released: 2016, program_creators: ['Matt Duffer', 'Ross Duffer'], _IMPORT_ID: 0});
CREATE (n:Character:_IMPORT_ID {name: 'Eleven', portrayed_by: 'Millie Bobby Brown', _IMPORT_ID: 1});
CREATE (n:Character:_IMPORT_ID {name: 'Joyce Byers', portrayed_by: 'Winona Ryder', _IMPORT_ID: 2});
CREATE (n:Character:_IMPORT_ID {name: 'Jim Hopper', portrayed_by: 'David Harbour', _IMPORT_ID: 3});
CREATE (n:Character:_IMPORT_ID {name: 'Mike Wheeler', portrayed_by: 'Finn Wolfhard', _IMPORT_ID: 4});
CREATE (n:Character:_IMPORT_ID {name: 'Dustin Henderson', portrayed_by: 'Gaten Matarazzo', _IMPORT_ID: 5});
CREATE (n:Character:_IMPORT_ID {name: 'Lucas Sinclair', portrayed_by: 'Caleb McLaughlin', _IMPORT_ID: 6});
CREATE (n:Character:_IMPORT_ID {name: 'Nancy Wheeler', portrayed_by: 'Natalia Dyer', _IMPORT_ID: 7});
CREATE (n:Character:_IMPORT_ID {name: 'Jonathan Byers', portrayed_by: 'Charlie Heaton', _IMPORT_ID: 8});
CREATE (n:Character:_IMPORT_ID {name: 'Will Byers', portrayed_by: 'Noah Schnapp', _IMPORT_ID: 9});
CREATE (n:Character:_IMPORT_ID {name: 'Steve Harrington', portrayed_by: 'Joe Keery', _IMPORT_ID: 10});
CREATE (n:Character:_IMPORT_ID {name: 'Max Mayfield', portrayed_by: 'Sadie Sink', _IMPORT_ID: 11});
CREATE (n:Character:_IMPORT_ID {name: 'Robin Buckley', portrayed_by: 'Maya Hawke', _IMPORT_ID: 12});
CREATE (n:Character:_IMPORT_ID {name: 'Erica Sinclair', portrayed_by: 'Priah Ferguson', _IMPORT_ID: 13});
MATCH (n:_IMPORT_ID {_IMPORT_ID: 1}) MATCH (m:_IMPORT_ID {_IMPORT_ID: 0}) CREATE (n)-[:ACTED_IN {seasons: [1, 2, 3, 4]}]->(m);
MATCH (n:_IMPORT_ID {_IMPORT_ID: 2}) MATCH (m:_IMPORT_ID {_IMPORT_ID: 0}) CREATE (n)-[:ACTED_IN {seasons: [1, 2, 3, 4]}]->(m);
MATCH (n:_IMPORT_ID {_IMPORT_ID: 3}) MATCH (m:_IMPORT_ID {_IMPORT_ID: 0}) CREATE (n)-[:ACTED_IN {seasons: [1, 2, 3, 4]}]->(m);
MATCH (n:_IMPORT_ID {_IMPORT_ID: 4}) MATCH (m:_IMPORT_ID {_IMPORT_ID: 0}) CREATE (n)-[:ACTED_IN {seasons: [1, 2, 3, 4]}]->(m);
MATCH (n:_IMPORT_ID {_IMPORT_ID: 5}) MATCH (m:_IMPORT_ID {_IMPORT_ID: 0}) CREATE (n)-[:ACTED_IN {seasons: [1, 2, 3, 4]}]->(m);
MATCH (n:_IMPORT_ID {_IMPORT_ID: 6}) MATCH (m:_IMPORT_ID {_IMPORT_ID: 0}) CREATE (n)-[:ACTED_IN {seasons: [1, 2, 3, 4]}]->(m);
MATCH (n:_IMPORT_ID {_IMPORT_ID: 7}) MATCH (m:_IMPORT_ID {_IMPORT_ID: 0}) CREATE (n)-[:ACTED_IN {seasons: [1, 2, 3, 4]}]->(m);
MATCH (n:_IMPORT_ID {_IMPORT_ID: 8}) MATCH (m:_IMPORT_ID {_IMPORT_ID: 0}) CREATE (n)-[:ACTED_IN {seasons: [1, 2, 3, 4]}]->(m);
MATCH (n:_IMPORT_ID {_IMPORT_ID: 9}) MATCH (m:_IMPORT_ID {_IMPORT_ID: 0}) CREATE (n)-[:ACTED_IN {seasons: [1, 2, 3, 4]}]->(m);
MATCH (n:_IMPORT_ID {_IMPORT_ID: 10}) MATCH (m:_IMPORT_ID {_IMPORT_ID: 0}) CREATE (n)-[:ACTED_IN {seasons: [1, 2, 3, 4]}]->(m);
MATCH (n:_IMPORT_ID {_IMPORT_ID: 11}) MATCH (m:_IMPORT_ID {_IMPORT_ID: 0}) CREATE (n)-[:ACTED_IN {seasons: [2, 3, 4]}]->(m);
MATCH (n:_IMPORT_ID {_IMPORT_ID: 12}) MATCH (m:_IMPORT_ID {_IMPORT_ID: 0}) CREATE (n)-[:ACTED_IN {seasons: [3, 4]}]->(m);
MATCH (n:_IMPORT_ID {_IMPORT_ID: 13}) MATCH (m:_IMPORT_ID {_IMPORT_ID: 0}) CREATE (n)-[:ACTED_IN {seasons: [2, 3, 4]}]->(m);
MATCH (n:_IMPORT_ID) REMOVE n:`_IMPORT_ID` REMOVE n._IMPORT_ID;Export query results to a CSV file
Database state
The database contains the following data:
Created using the following queries:
CREATE (StrangerThings:TVShow {title:'Stranger Things', released:2016, program_creators:['Matt Duffer', 'Ross Duffer']})
CREATE (Eleven:Character {name:'Eleven', portrayed_by:'Millie Bobby Brown'})
CREATE (JoyceByers:Character {name:'Joyce Byers', portrayed_by:'Winona Ryder'})
CREATE (JimHopper:Character {name:'Jim Hopper', portrayed_by:'David Harbour'})
CREATE (MikeWheeler:Character {name:'Mike Wheeler', portrayed_by:'Finn Wolfhard'})
CREATE (DustinHenderson:Character {name:'Dustin Henderson', portrayed_by:'Gaten Matarazzo'})
CREATE (LucasSinclair:Character {name:'Lucas Sinclair', portrayed_by:'Caleb McLaughlin'})
CREATE (NancyWheeler:Character {name:'Nancy Wheeler', portrayed_by:'Natalia Dyer'})
CREATE (JonathanByers:Character {name:'Jonathan Byers', portrayed_by:'Charlie Heaton'})
CREATE (WillByers:Character {name:'Will Byers', portrayed_by:'Noah Schnapp'})
CREATE (SteveHarrington:Character {name:'Steve Harrington', portrayed_by:'Joe Keery'})
CREATE (MaxMayfield:Character {name:'Max Mayfield', portrayed_by:'Sadie Sink'})
CREATE (RobinBuckley:Character {name:'Robin Buckley', portrayed_by:'Maya Hawke'})
CREATE (EricaSinclair:Character {name:'Erica Sinclair', portrayed_by:'Priah Ferguson'})
CREATE
(Eleven)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(JoyceByers)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(JimHopper)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(MikeWheeler)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(DustinHenderson)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(LucasSinclair)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(NancyWheeler)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(JonathanByers)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(WillByers)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(SteveHarrington)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(MaxMayfield)-[:ACTED_IN {seasons:[2, 3, 4]}]->(StrangerThings),
(RobinBuckley)-[:ACTED_IN {seasons:[3, 4]}]->(StrangerThings),
(EricaSinclair)-[:ACTED_IN {seasons:[2, 3, 4]}]->(StrangerThings);Export query results
If you’re using Memgraph with Docker, the following Cypher query will export
the query result to the export.csv file in the /usr/lib/memgraph/query_modules
directory inside the running Docker container.
WITH "MATCH path = (c:Character)-[:ACTED_IN]->(tvshow) RETURN c.name AS name, c.portrayed_by AS portrayed_by, tvshow.title AS title, tvshow.released AS released, tvshow.program_creators AS program_creators" AS query
CALL export_util.csv_query(query, "/usr/lib/memgraph/query_modules/export.csv", True)
YIELD file_path, data
RETURN file_path, data;If you’re using Memgraph on Ubuntu, Debian, RPM package or WSL, the
following Cypher query will export the query results to the export.csv file in the
/users/my_user/export_folder.
WITH "MATCH path = (c:Character)-[:ACTED_IN]->(tvshow) RETURN c.name AS name, c.portrayed_by AS portrayed_by, tvshow.title AS title, tvshow.released AS released, tvshow.program_creators AS program_creators" AS query
CALL export_util.csv_query(query, "/users/my_user/export_folder/export.csv", True)
YIELD file_path, data
RETURN file_path, data;The output in the export.csv file should look like this:
name,portrayed_by,title,released,program_creators
Eleven,Millie Bobby Brown,Stranger Things,2016,"['Matt Duffer', 'Ross Duffer']"
Joyce Byers,Winona Ryder,Stranger Things,2016,"['Matt Duffer', 'Ross Duffer']"
Jim Hopper,David Harbour,Stranger Things,2016,"['Matt Duffer', 'Ross Duffer']"
Mike Wheeler,Finn Wolfhard,Stranger Things,2016,"['Matt Duffer', 'Ross Duffer']"
Dustin Henderson,Gaten Matarazzo,Stranger Things,2016,"['Matt Duffer', 'Ross Duffer']"
Lucas Sinclair,Caleb McLaughlin,Stranger Things,2016,"['Matt Duffer', 'Ross Duffer']"
Nancy Wheeler,Natalia Dyer,Stranger Things,2016,"['Matt Duffer', 'Ross Duffer']"
Jonathan Byers,Charlie Heaton,Stranger Things,2016,"['Matt Duffer', 'Ross Duffer']"
Will Byers,Noah Schnapp,Stranger Things,2016,"['Matt Duffer', 'Ross Duffer']"
Steve Harrington,Joe Keery,Stranger Things,2016,"['Matt Duffer', 'Ross Duffer']"
Max Mayfield,Sadie Sink,Stranger Things,2016,"['Matt Duffer', 'Ross Duffer']"
Robin Buckley,Maya Hawke,Stranger Things,2016,"['Matt Duffer', 'Ross Duffer']"
Erica Sinclair,Priah Ferguson,Stranger Things,2016,"['Matt Duffer', 'Ross Duffer']"Export database to a graphML file
Database state
The database contains the following data:
Created using the following queries:
CREATE (StrangerThings:TVShow {title:'Stranger Things', released:2016, program_creators:['Matt Duffer', 'Ross Duffer']})
CREATE (Eleven:Character {name:'Eleven', portrayed_by:'Millie Bobby Brown'})
CREATE (JoyceByers:Character {name:'Joyce Byers', portrayed_by:'Winona Ryder'})
CREATE (JimHopper:Character {name:'Jim Hopper', portrayed_by:'David Harbour'})
CREATE (MikeWheeler:Character {name:'Mike Wheeler', portrayed_by:'Finn Wolfhard'})
CREATE (DustinHenderson:Character {name:'Dustin Henderson', portrayed_by:'Gaten Matarazzo'})
CREATE (LucasSinclair:Character {name:'Lucas Sinclair', portrayed_by:'Caleb McLaughlin'})
CREATE (NancyWheeler:Character {name:'Nancy Wheeler', portrayed_by:'Natalia Dyer'})
CREATE (JonathanByers:Character {name:'Jonathan Byers', portrayed_by:'Charlie Heaton'})
CREATE (WillByers:Character {name:'Will Byers', portrayed_by:'Noah Schnapp'})
CREATE (SteveHarrington:Character {name:'Steve Harrington', portrayed_by:'Joe Keery'})
CREATE (MaxMayfield:Character {name:'Max Mayfield', portrayed_by:'Sadie Sink'})
CREATE (RobinBuckley:Character {name:'Robin Buckley', portrayed_by:'Maya Hawke'})
CREATE (EricaSinclair:Character {name:'Erica Sinclair', portrayed_by:'Priah Ferguson'})
CREATE
(Eleven)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(JoyceByers)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(JimHopper)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(MikeWheeler)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(DustinHenderson)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(LucasSinclair)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(NancyWheeler)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(JonathanByers)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(WillByers)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(SteveHarrington)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(MaxMayfield)-[:ACTED_IN {seasons:[2, 3, 4]}]->(StrangerThings),
(RobinBuckley)-[:ACTED_IN {seasons:[3, 4]}]->(StrangerThings),
(EricaSinclair)-[:ACTED_IN {seasons:[2, 3, 4]}]->(StrangerThings);Export data
If you’re using Memgraph with Docker, the following Cypher query will
export the database to the export.graphml file in the
/usr/lib/memgraph/query_modules directory inside the running Docker container.
CALL export_util.graphml("/usr/lib/memgraph/query_modules/export.graphml, {useTypes: true})
YIELD status RETURN status;If you’re using Memgraph on Ubuntu, Debian, RPM package or WSL, the
following Cypher query will export the database to the export.graphml file in the
/users/my_user/export_folder.
CALL export_util.graphml("/users/my_user/export_folder/export.graphml, {useTypes: true})
YIELD status RETURN status;The output in the export.graphml should look like this:
<?xml version="1.0" encoding="UTF-8"?>
<graphml xmlns="http://graphml.graphdrawing.org/xmlns" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://graphml.graphdrawing.org/xmlns http://graphml.graphdrawing.org/xmlns/1.0/graphml.xsd">
<key id="labels" for="node" attr.name="labels" attr.type="string"/>
<key id="title" for="node" attr.name="title" attr.type="string"/>
<key id="released" for="node" attr.name="released" attr.type="int"/>
<key id="program_creators" for="node" attr.name="program_creators" attr.type="string" attr.list="string"/>
<key id="name" for="node" attr.name="name" attr.type="string"/>
<key id="portrayed_by" for="node" attr.name="portrayed_by" attr.type="string"/>
<key id="label" for="edge" attr.name="label" attr.type="string"/>
<key id="seasons" for="edge" attr.name="seasons" attr.type="string" attr.list="int"/>
<graph id="G" edgedefault="directed">
<node id="n0" labels=":TVShow"><data key="labels">:TVShow</data><data key="title">Stranger Things</data><data key="released">2016</data><data key="program_creators">["Matt Duffer", "Ross Duffer"]</data></node>
<node id="n1" labels=":Character"><data key="labels">:Character</data><data key="name">Eleven</data><data key="portrayed_by">Millie Bobby Brown</data></node>
<node id="n2" labels=":Character"><data key="labels">:Character</data><data key="name">Joyce Byers</data><data key="portrayed_by">Winona Ryder</data></node>
<node id="n3" labels=":Character"><data key="labels">:Character</data><data key="name">Jim Hopper</data><data key="portrayed_by">David Harbour</data></node>
<node id="n4" labels=":Character"><data key="labels">:Character</data><data key="name">Mike Wheeler</data><data key="portrayed_by">Finn Wolfhard</data></node>
<node id="n5" labels=":Character"><data key="labels">:Character</data><data key="name">Dustin Henderson</data><data key="portrayed_by">Gaten Matarazzo</data></node>
<node id="n6" labels=":Character"><data key="labels">:Character</data><data key="name">Lucas Sinclair</data><data key="portrayed_by">Caleb McLaughlin</data></node>
<node id="n7" labels=":Character"><data key="labels">:Character</data><data key="name">Nancy Wheeler</data><data key="portrayed_by">Natalia Dyer</data></node>
<node id="n8" labels=":Character"><data key="labels">:Character</data><data key="name">Jonathan Byers</data><data key="portrayed_by">Charlie Heaton</data></node>
<node id="n9" labels=":Character"><data key="labels">:Character</data><data key="name">Will Byers</data><data key="portrayed_by">Noah Schnapp</data></node>
<node id="n10" labels=":Character"><data key="labels">:Character</data><data key="name">Steve Harrington</data><data key="portrayed_by">Joe Keery</data></node>
<node id="n11" labels=":Character"><data key="labels">:Character</data><data key="name">Max Mayfield</data><data key="portrayed_by">Sadie Sink</data></node>
<node id="n12" labels=":Character"><data key="labels">:Character</data><data key="name">Robin Buckley</data><data key="portrayed_by">Maya Hawke</data></node>
<node id="n13" labels=":Character"><data key="labels">:Character</data><data key="name">Erica Sinclair</data><data key="portrayed_by">Priah Ferguson</data></node>
<edge id="e0" source="n1" target="n0" label="ACTED_IN"><data key="label">ACTED_IN</data><data key="seasons">[1, 2, 3, 4]</data></edge>
<edge id="e1" source="n2" target="n0" label="ACTED_IN"><data key="label">ACTED_IN</data><data key="seasons">[1, 2, 3, 4]</data></edge>
<edge id="e2" source="n3" target="n0" label="ACTED_IN"><data key="label">ACTED_IN</data><data key="seasons">[1, 2, 3, 4]</data></edge>
<edge id="e3" source="n4" target="n0" label="ACTED_IN"><data key="label">ACTED_IN</data><data key="seasons">[1, 2, 3, 4]</data></edge>
<edge id="e4" source="n5" target="n0" label="ACTED_IN"><data key="label">ACTED_IN</data><data key="seasons">[1, 2, 3, 4]</data></edge>
<edge id="e5" source="n6" target="n0" label="ACTED_IN"><data key="label">ACTED_IN</data><data key="seasons">[1, 2, 3, 4]</data></edge>
<edge id="e6" source="n7" target="n0" label="ACTED_IN"><data key="label">ACTED_IN</data><data key="seasons">[1, 2, 3, 4]</data></edge>
<edge id="e7" source="n8" target="n0" label="ACTED_IN"><data key="label">ACTED_IN</data><data key="seasons">[1, 2, 3, 4]</data></edge>
<edge id="e8" source="n9" target="n0" label="ACTED_IN"><data key="label">ACTED_IN</data><data key="seasons">[1, 2, 3, 4]</data></edge>
<edge id="e9" source="n10" target="n0" label="ACTED_IN"><data key="label">ACTED_IN</data><data key="seasons">[1, 2, 3, 4]</data></edge>
<edge id="e10" source="n11" target="n0" label="ACTED_IN"><data key="label">ACTED_IN</data><data key="seasons">[2, 3, 4]</data></edge>
<edge id="e11" source="n12" target="n0" label="ACTED_IN"><data key="label">ACTED_IN</data><data key="seasons">[3, 4]</data></edge>
<edge id="e12" source="n13" target="n0" label="ACTED_IN"><data key="label">ACTED_IN</data><data key="seasons">[2, 3, 4]</data></edge>
</graph>
</graphml>