community_detection_online (Enterprise)
From Memgraph 3.0, dynamic graph algorithms became a part of the Memgraph Enterprise license. To use dynamic graph algorithms, you need to enable Memgraph Enterprise license. If you want to know more and learn how this affects you, read our announcement.
Community in graphs mirrors real-world communities, like social circles. In a graph, communities are sets of nodes. M. Girvan and M. E. J. Newman note that nodes in a community connect more intensely with each other than with outside nodes.
The query module uses the LabelRankT dynamic community detection algorithm.
LabelRankT is a label propagation algorithm where nodes determine their communities by learning from neighbors. Efficiently designed for large-scale graphs, it operates in time with space complexity, where and represent the counts of vertices and edges, respectively.
This dynamic method is ideal for graph streaming platforms like Memgraph. It processes only those sections of the graph affected by updates, thus optimizing efforts. The algorithm is deterministic, ensuring consistent results. By taking into account edge weight and directedness, it provides superior community detection and can be applied to a diverse range of graphs.
| Trait | Value |
|---|---|
| Module type | algorithm |
| Implementation | C++ |
| Graph direction | directed / undirected |
| Edge weights | weighted / unweighted |
| Parallelism | sequential |
Procedures
You can execute this algorithm on graph projections, subgraphs or portions of the graph.
set()
Performs dynamic community detection using the LabelRankT algorithm.
The default values of the similarity_threshold, exponent and min_value
parameters are not universally applicable, and the actual values should be
determined experimentally. This is especially pertinent to setting the
min_value parameter. For example, with the default value, vertices
of degree greater than 10 are at risk of not being assigned to any community and
the user should check if that is indeed the case.
Input:
-
subgraph: Graph(OPTIONAL) ➡ A specific subgraph, which is an object of type Graph returned by theproject()function, on which the algorithm is run. If subgraph is not specified, the algorithm is computed on the entire graph by default. -
directed: boolean (default=False)➡ Specifies whether the graph is directed. If not set, the graph is treated as undirected. -
weighted: boolean (default=False)➡ Specifies whether the graph is weighted. If not set, the graph is considered unweighted. -
similarity_threshold: double (default=0.7)➡ Maximum similarity between node’s and its neighbors’ communities for the node to be updated in the ongoing iteration. -
exponent: double (default=4)➡ Power which community probability nodes are raised elementwise to. -
min_value: double (default=0.1)➡ Smallest community probability that is not pruned between iterations. -
weight_property: string (default="weight")➡ For directed graphs, the values at the given relationship property are used as weights in the community detection algorithm. -
w_selfloop: double (default=1)➡ Each node has a self-loop added to smooth the label propagation. This parameter specifies the weight assigned to the self-loops. If the graph is unweighted, this value is ignored. -
max_iterations: integer (default=100)➡ Maximum number of iterations to run. -
max_updates: integer (default=5)➡ Maximum number of updates to any node’s community probabilities.
Output:
node: Vertex➡ A graph node for which the algorithm was performed and returned as part of the results.community_id: integer➡ Community ID. If the node is not associated with any community, defaults to .
Usage:
To run community detection, use the following query:
CALL community_detection_online.set(False, False, 0.7, 4.0, 0.1, "weight", 1, 100, 5)
YIELD node, community_id;get()
Returns the latest previously calculated community detection results. If there
are none, defaults to calling set() with default parameters.
Input:
subgraph: Graph(OPTIONAL) ➡ A specific subgraph, which is an object of type Graph returned by theproject()function, on which the algorithm is run. If subgraph is not specified, the algorithm is computed on the entire graph by default.
Output:
node: Vertex➡ A graph node for which the algorithm was performed and returned as part of the results.community_id: integer➡ Community ID. Defaults to if the node does not belong to any community.
Usage:
Use the following query, to get the calculated community detection results
CALL community_detection_online.get()
YIELD node, community_id;update()
Dynamically updates previously calculated community detection results based on changes applied in the latest graph update and returns the results.
Input:
-
subgraph: Graph(OPTIONAL) ➡ A specific subgraph, which is an object of type Graph returned by theproject()function, on which the algorithm is run. If subgraph is not specified, the algorithm is computed on the entire graph by default. -
createdVertices: mgp.List[mgp.Vertex]➡ Nodes created in the latest graph update. -
createdEdges: mgp.List[mgp.Edge]➡ Relationships created in the latest graph update. -
updatedVertices: mgp.List[mgp.Vertex]➡ Nodes updated in the latest graph update. -
updatedEdges: mgp.List[mgp.Edge]➡ Relationships updated in the latest graph update. -
deletedVertices: mgp.List[mgp.Vertex]➡ Nodes deleted in the latest graph update. -
deletedEdges: mgp.List[mgp.Edge]➡ Relationships deleted in the latest graph update.
Output:
node: Vertex➡ A graph node for which the algorithm was performed and returned as part of the results.community_id: integer➡ Community ID. If the node is not associated with any community, defaults to .
Usage:
As there are a total of six complex obligatory parameters, setting the parameters by hand might be cumbersome. The recommended use of this method is to call it within a trigger, making sure beforehand that all predefined variables are available:
CREATE TRIGGER sample_trigger BEFORE COMMIT
EXECUTE CALL community_detection_online.update(createdVertices, createdEdges, updatedVertices, updatedEdges, deletedVertices, deletedEdges) YIELD node, community_id;Communities calculated by update() are also accessible by subsequently calling
get():
CREATE TRIGGER sample_trigger BEFORE COMMIT
EXECUTE CALL community_detection_online.update(createdVertices, createdEdges, updatedVertices, updatedEdges, deletedVertices, deletedEdges)
YIELD node, community_id
RETURN node, community_id;
CALL community_detection_online.get()
YIELD node, community_id
RETURN node.id AS node_id, community_id
ORDER BY node_id;reset()
Resets the algorithm to its initial state.
Input:
subgraph: Graph(OPTIONAL) ➡ A specific subgraph, which is an object of type Graph returned by theproject()function, on which the algorithm is run. If subgraph is not specified, the algorithm is computed on the entire graph by default.
Output:
message: string➡ Reports whether the algorithm was successfully reset.
Usage:
Use the following query, to reset the algorithm to its initial state:
CALL community_detection_online.reset()
YIELD message;Example
Create a trigger
The following query sets a trigger which will update the values upon creating new data or deleting existing data:
CREATE TRIGGER community_detection_online_trigger BEFORE COMMIT
EXECUTE CALL community_detection_online.update(createdVertices, createdEdges, updatedVertices, updatedEdges, deletedVertices, deletedEdges) YIELD node, community_id
SET node.community_id = community_id;Add new data
New data is added to the database:
MERGE (a: Node {id: 0}) MERGE (b: Node {id: 1}) CREATE (a)-[r: Relation]->(b);
MERGE (a: Node {id: 0}) MERGE (b: Node {id: 2}) CREATE (a)-[r: Relation]->(b);
MERGE (a: Node {id: 1}) MERGE (b: Node {id: 2}) CREATE (a)-[r: Relation]->(b);
MERGE (a: Node {id: 2}) MERGE (b: Node {id: 3}) CREATE (a)-[r: Relation]->(b);
MERGE (a: Node {id: 3}) MERGE (b: Node {id: 4}) CREATE (a)-[r: Relation]->(b);
MERGE (a: Node {id: 3}) MERGE (b: Node {id: 5}) CREATE (a)-[r: Relation]->(b);
MERGE (a: Node {id: 4}) MERGE (b: Node {id: 5}) CREATE (a)-[r: Relation]->(b);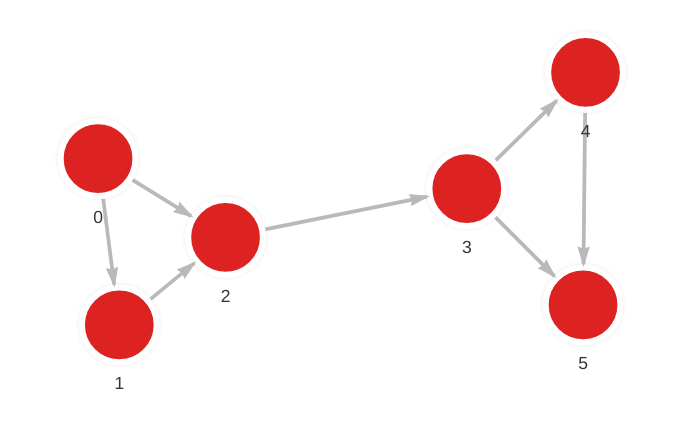
As new data is added, the triggered community_detection_online.update() procedure calculates the values.
Detect communities
Return the values using the following query:
CALL community_detection_online.get()
YIELD node, community_id
RETURN node.id AS node_id, community_id
ORDER BY node_id;Results:
+-------------------------+-------------------------+
| node_id | community_id |
+-------------------------+-------------------------+
| 0 | 1 |
| 1 | 1 |
| 2 | 1 |
| 3 | 2 |
| 4 | 2 |
| 5 | 2 |
+-------------------------+-------------------------+