Read and modify data
The simplest usage of the language is to find data stored in the database. For that, you can use one of the following clauses:
MATCHwhich searches for patterns.WHEREfor filtering the matched data.RETURNfor defining what will be presented to the user in the result set.UNIONandUNION ALLfor combining results from multiple queries.UNWINDfor unwinding a list of values as individual rows.
MATCH
This clause is used to obtain data from Memgraph by matching it to a given pattern. For example, you can use the following query to find each node in the database:
MATCH (node) RETURN node;Finding connected nodes can be achieved by using the query:
MATCH (node1)-[connection]-(node2) RETURN node1, connection, node2;In addition to general pattern matching, you can narrow the search down by
specifying node labels and properties. Similarly, relationship types and properties can
also be specified. For example, finding each node labeled as Person and with
property age being 42, is done with the following query:
MATCH (n:Person {age: 42}) RETURN n;
Each node and relationship gets a identifier generated during their initialization which is persisted through the durability mechanism.
Return it with the [`id()` function](/querying/functions).
You can use the following query to find their friends:
MATCH (n:Person {age: 42})-[:FRIENDS_WITH]-(friend) RETURN friend;There are cases when a user needs to find data that is connected by traversing a
path of connections, but the user doesn’t know how many connections need to be
traversed. Cypher allows for designating patterns with variable path
lengths. Matching such a path is achieved by using the * (asterisk) symbol
inside the relationship element of a pattern. For example, traversing from node1 to
node2 by following any number of connections in a single direction can be
achieved with:
MATCH (node1)-[r*]->(node2) RETURN node1, r, node2;If paths are very long, finding them could take a long time. To prevent that, a user can provide the minimum and maximum length of the path. For example, paths of length between two and four nodes can be obtained with a query like:
MATCH (node1)-[r*2..4]->(node2) RETURN node1, r, node2;It is possible to name patterns in the query and return the resulting paths. This is especially useful when matching variable length paths:
MATCH path = ()-[r*2..4]->() RETURN path;More details on how MATCH works can be found here.
The MATCH clause can be modified by prepending the OPTIONAL keyword.
OPTIONAL MATCH clause behaves the same as a regular MATCH, but when it fails
to find the pattern, missing parts of the pattern will be filled with null
values. Examples can be found here.
WHERE
You have already seen how to achieve simple filtering by using labels and
properties in MATCH patterns. When more complex filtering is desired, you can
use WHERE paired with MATCH or OPTIONAL MATCH. For example, finding each
person older than 20 is done with this query:
MATCH (n:Person) WHERE n.age > 20 RETURN n;Additional examples can be found here.
Regular expressions
Inside WHERE clause, you can use regular expressions for text filtering. To
use a regular expression, you need to use the =~ operator.
For example, finding all Person nodes which have a name ending with son:
MATCH (n:Person) WHERE n.name =~ ".*son$" RETURN n;The regular expression syntax is based on the modified ECMAScript regular expression grammar. The ECMAScript grammar can be found here, while the modifications are described in this document.
RETURN
The RETURN clause defines which data should be included in the resulting set.
Basic usage was already shown in the examples for MATCH and WHERE clauses.
Another feature of RETURN is renaming the results using the AS keyword.
For example:
MATCH (n:Person) RETURN n AS people;That query would display all nodes under the header named people instead of
n.
When you want to get everything that was matched, you can use the *
(asterisk) symbol.
This query:
MATCH (node1)-[connection]-(node2) RETURN *;is equivalent to:
MATCH (node1)-[connection]-(node2) RETURN node1, connection, node2;RETURN can be followed by the DISTINCT operator, which will remove duplicate
results. For example, getting unique names of people can be achieved with:
MATCH (n:Person) RETURN DISTINCT n.name;Besides choosing what will be the result and how it will be named, the RETURN
clause can also be used to:
- limit results with
LIMITsub-clause; - skip results with
SKIPsub-clause; - order results with
ORDER BYsub-clause and - perform aggregations (such as
count).
More details on RETURN can be found here.
SKIP & LIMIT
These sub-clauses take a number of how many results to skip or limit. For example, to get the first three results you can use this query:
MATCH (n:Person) RETURN n LIMIT 3;If you want to get all the results after the first 3, you can use the following:
MATCH (n:Person) RETURN n SKIP 3;The SKIP and LIMIT can be combined. So for example, to get the 2nd result,
you can do:
MATCH (n:Person) RETURN n SKIP 1 LIMIT 1;ORDER BY
Since the patterns which are matched can come in any order, it is very useful to
be able to enforce some ordering among the results. In such cases, you can use
the ORDER BY sub-clause.
For example, the following query will get all :Person nodes and order them by
their names:
MATCH (n:Person) RETURN n ORDER BY n.name;By default, ordering will be ascending. To change the order to be descending,
you should append DESC.
For example, you can use this query to order people by their name descending:
MATCH (n:Person) RETURN n ORDER BY n.name DESC;You can also order by multiple variables. The results will be sorted by the first variable listed. If the values are equal, the results are sorted by the second variable, and so on.
For example, ordering by first name descending and last name ascending:
MATCH (n:Person) RETURN n ORDER BY n.name DESC, n.lastName;Note that ORDER BY sees only the variable names as carried over by RETURN.
This means that the following will result in an error.
MATCH (old:Person) RETURN old AS new ORDER BY old.name;Instead, the new variable must be used:
MATCH (old:Person) RETURN old AS new ORDER BY new.name;The ORDER BY sub-clause may come in handy with SKIP and/or LIMIT
sub-clauses. For example, to get the oldest person you can use the following:
MATCH (n:Person) RETURN n ORDER BY n.age DESC LIMIT 1;You can also order result before returning them. The following query will order all the nodes according to name, and then return them in a list.
MATCH (n)
WITH n ORDER BY n.name DESC
RETURN collect(n.name) AS names;Aggregating
Cypher has functions for aggregating data. Memgraph currently supports the following aggregating functions.
avg, for calculating the average value.sum, for calculating the sum of numeric values.collect, for collecting multiple values into a single list or map. If given a single expression values are collected into a list. If given two expressions, values are collected into a map where the first expression denotes map keys (must be string values) and the second expression denotes map values.count, for counting the resulting values.max, for returning the maximum value.min, for returning the minimum value.
Example, calculating the average age:
MATCH (n:Person) RETURN avg(n.age) AS averageAge;Collecting items into a list:
MATCH (n:Person) RETURN collect(n.name) AS list_of_names;Collecting items into a map:
MATCH (n:Person) RETURN collect(n.name, n.age) AS map_name_to_age;Check the detailed signatures of aggregation functions.
UNION and UNION ALL
Cypher supports combining results from multiple queries into a single result set. That result will contain rows that belong to queries in the union respecting the union type.
Using UNION will contain only distinct rows, while UNION ALL will keep all
rows from all given queries.
Restrictions when using UNION or UNION ALL:
- The number and the names of columns returned by queries must be the same for all of them.
- There can be only one union type between single queries, i.e. a query can’t
contain both
UNIONandUNION ALL.
For example to get distinct names that are shared between persons and movies use the following query:
MATCH (n:Person) RETURN n.name AS name UNION MATCH (n:Movie) RETURN n.name AS name;To get all names that are shared between persons and movies (including duplicates) do the following:
MATCH (n:Person) RETURN n.name AS name UNION ALL MATCH (n:Movie) RETURN n.name AS name;UNWIND
The UNWIND clause is used to unwind a list of values as individual rows.
To produce rows out of a single list, use the following query:
UNWIND [1,2,3] AS listElement RETURN listElement;More examples can be found here.
Traversing relationships
Patterns are used to indicate specific graph traversals given directional
relationships. How a graph is traversed for a query depends on what directions
are defined for relationships and how the pattern is specified in the MATCH
clause.
Patterns in a query
Here is an example of a pattern that utilizes the FRIENDS_WITH relationships
from our graph:
MATCH (p1:Person)-[r:FRIENDS_WITH]->(p2:Person {name:'Alison'})
RETURN p1, r, p2;The output is:
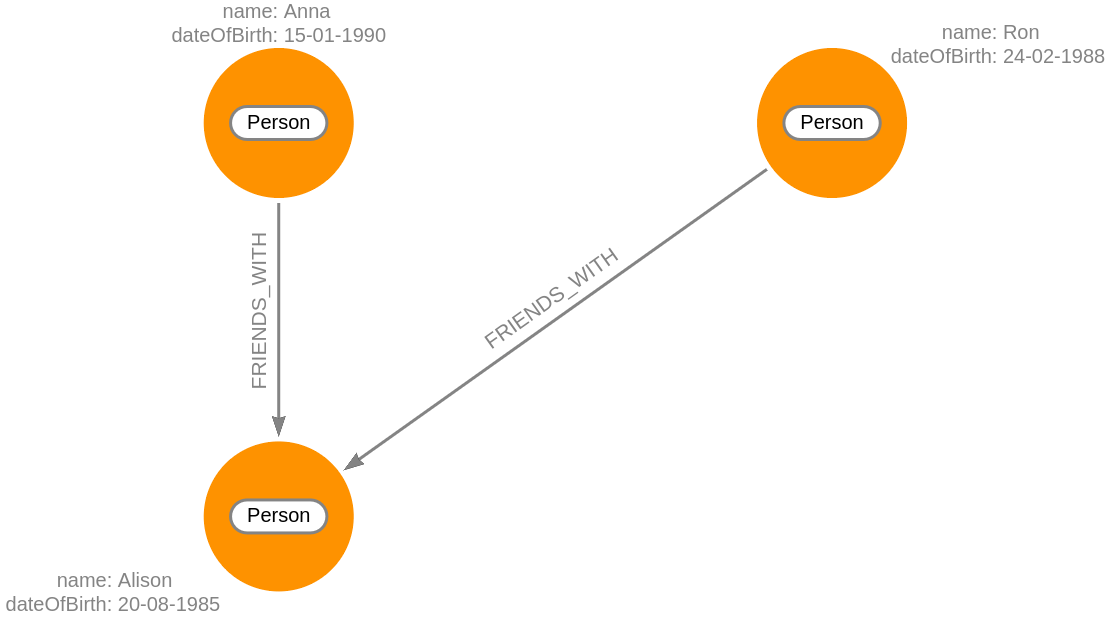
Because the FRIENDS_WITH relationship is directional, only these two nodes are
returned.
Reversing traversals
When the relationship from the previous query is reversed, with the person named Alison being the anchor node, the returned results are:
MATCH (p1:Person)<-[r:FRIENDS_WITH]-(p2:Person {name:'Alison'})
RETURN p1, r, p2;The output is:

Bidirectional traversals
We can also find out what Person nodes are connected with the FRIENDS_WITH
relationship in either direction by removing the directional arrow from the
pattern:
MATCH (p1:Person)-[r:FRIENDS_WITH]-(p2:Person {name:'Alison'})
RETURN p1, r, p2;The output is:
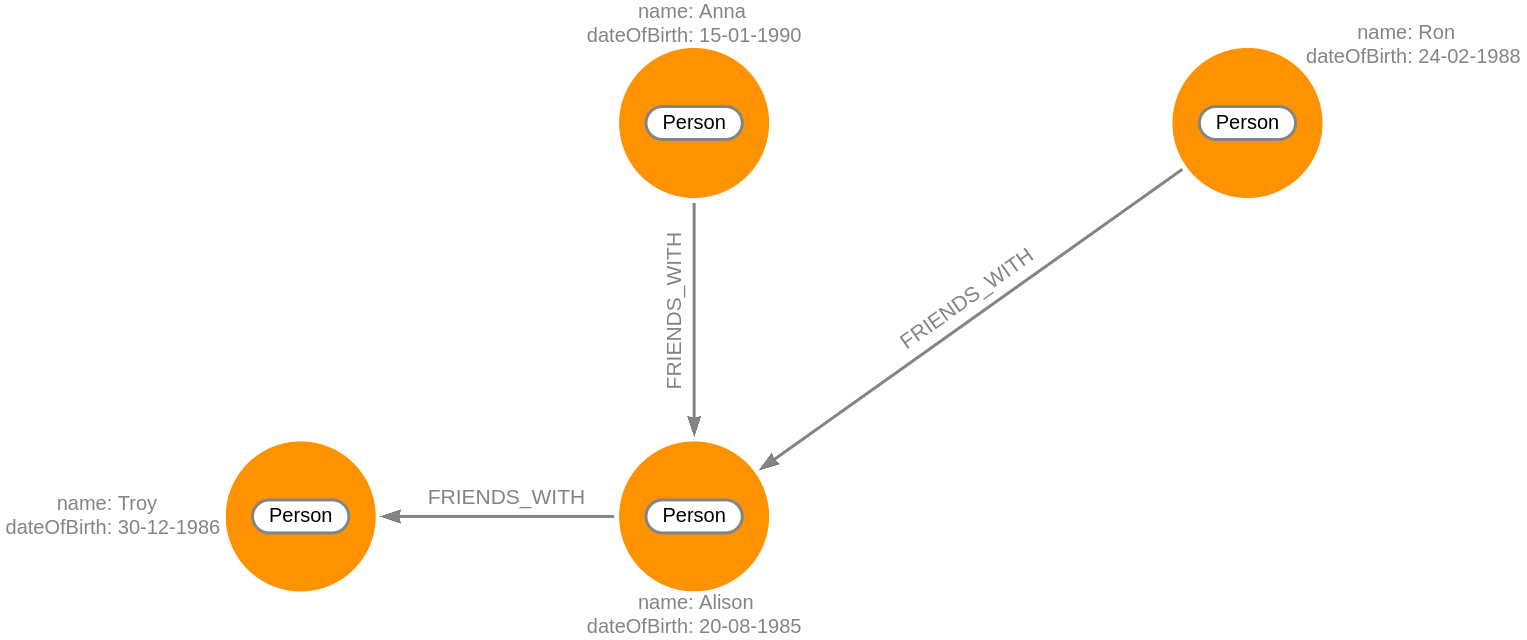
Traversing multiple relationships
Since we have a graph, we can traverse through nodes to obtain relationships further into the traversal.
For example, we can write a Cypher query to return all friends of friends of the person named Alison:
MATCH (p1:Person {name:'Alison'})-[r1:FRIENDS_WITH]->
(p2:Person)-[r2:FRIENDS_WITH]-(p3:Person)
RETURN p1, r1, p2, r2, p3;Keep in mind that the first relationship is directional while the second one isn’t. The output is:
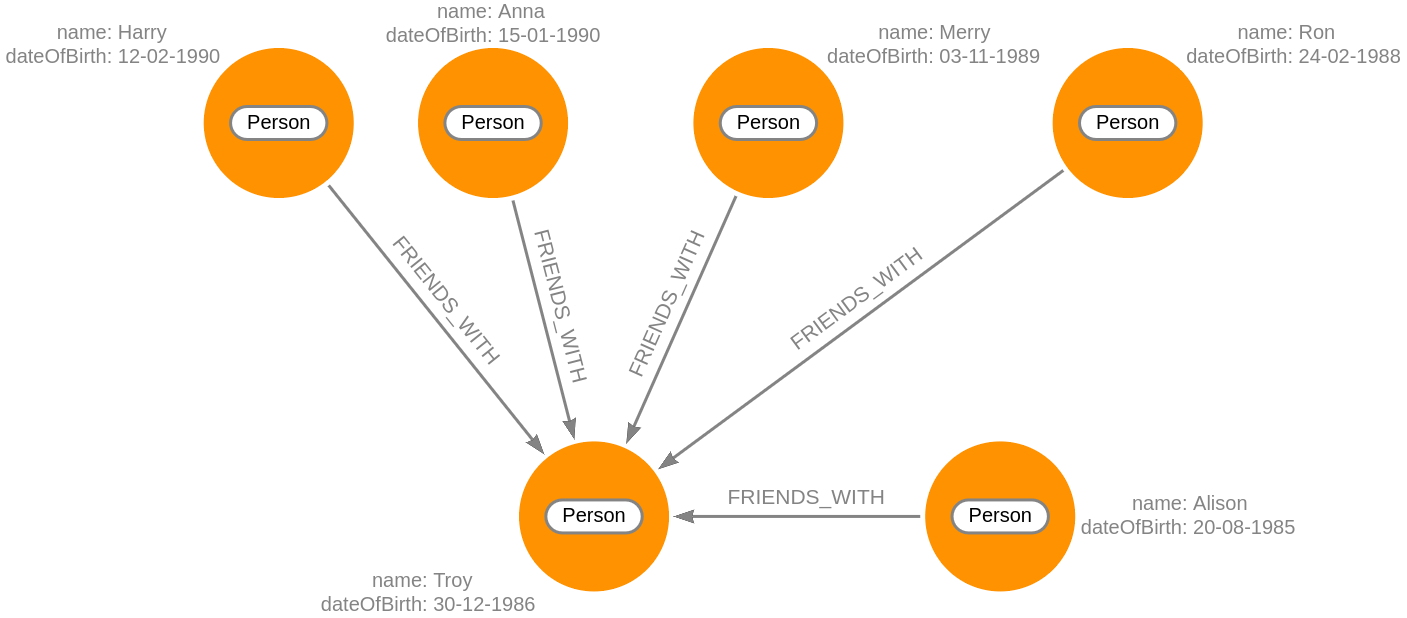
Modify data
SET clause
Use the SET clause to update labels on nodes and properties on nodes and
relationships.
Click here for a more detailed explanation of what can be
done with SET.
Cypher supports combining multiple reads and writes using the WITH clause.
In addition to combining, the MERGE clause is provided which may create
patterns if they do not exist.
Creating and updating properties
The SET clause can be used to create/update the value of a property on a node or
relationship:
MATCH (c:City)
WHERE c.name = 'London'
SET c.population = 8900000
RETURN c;The SET clause can be used to create/update the value of multiple properties
on nodes or relationships by separating them with a comma:
MATCH (c:City)
WHERE c.name = 'London'
SET c.population = 8900000, c.country = 'United Kingdom'
RETURN c;Creating and updating node labels
The SET clause can be used to create/update the label on a node. If the node has
a label, a new one will be added while the old one is left as is:
MATCH (c:City:Location)
SET c:City
RETURN labels(c);Removing a property
The SET clause can be used to remove the value of a property on a node or
relationship by setting it to NULL:
MATCH (c:City)
WHERE c.name = 'London'
SET c.country = NULL
RETURN c;Copy all properties
If SET is used to copy the properties of one node/relationship to another, all
the properties of the latter will be removed and replaced with the new ones:
CREATE (p1:Person {name: 'Harry'}), (p2:Person {name: 'Anna'})
SET p1 = p2
RETURN p1, p2;Setting a nested property
If the property of a node or relationship is a map, Memgraph supports setting nested properties within the map for more granular updates. The following command updates a nested property of a node:
MATCH (h:Person {name: 'Harry'})
SET h.details.age = 21;If the map property does not exist beforehand, it will be created as an empty map with the nested properties placed inside.
There are certain schema guarantees — you cannot modify a nested property if the parent property exists and is not of type Map.
For more information, read the guide on setting nested propertes
Removing a nested property
Similar to setting nested properties, Memgraph supports removing nested properties for more fine-grained manipulation of object data. The following Cypher query deletes a nested property from a node:
MATCH (h:Person {name: 'Harry'})
REMOVE h.details.age;If the leaf property does not exist, the command will not raise an exception. However, if the parent property maps do not exist, the query will result in a runtime exception.
For more information, read the guide on removing nested propertes
Bulk update
You can use SET clause to do a bulk update. Here is an example of how to
increment everyone’s age by 1:
MATCH (n:Person) SET n.age = n.age + 1;Delete data
DELETE
This clause is used to delete nodes, relationships and paths from the database.
For example, removing all relationships of a single type:
MATCH ()-[relationship :type]-() DELETE relationship;When testing the database, you often want to have a clean start by deleting every node and relationship in the database. It is reasonable that deleting each node should delete all relationships coming into or out of that node.
MATCH (node) DELETE node;But, Cypher prevents accidental deletion of relationships. Therefore, the above
query will report an error. Instead, you need to use the DETACH keyword, which
will remove relationships from a node you are deleting. The following should work and
delete everything in the database.
MATCH (node) DETACH DELETE node;To delete a path, use the following syntax:
MATCH p = (:X)-->()-->()-->()
DETACH DELETE p;DROP GRAPH
To delete all the data, along with all indices, constraints, triggers, and streams, in an efficient manner, you can use the following query:
DROP GRAPH;More details are available at DROP GRAPH documentation.
REMOVE
The REMOVE clause is used to remove labels and properties from nodes and
relationships:
MATCH (n:WrongLabel) REMOVE n:WrongLabel, n.property;Periodic execution
The data should be reverted to its original state if the query updating it
fails. To ensure that, write queries need to use additional memory. The memory
overhead is linear to the number of updates queries performed. These updates
during query execution are called Delta
objects.
The number of created Delta objects grows during the execution and it can’t
grow more than the available RAM. That’s why Delta objects are temporary and
deleted during garbage collection at the end of transaction. There is always a
thread allocated in Memgraph for garbage collection (GC) that cleans temporary
allocated space during query execution. Still, sometimes the Delta objects are
accumulating faster than GC cleans them up.
Let’s see that on an example. The following query deletes all data in the database:
MATCH (n) DETACH DELETE n;The amount of created Delta overhead is the total number of nodes and
relationships in the graph. Every Delta object is around 56 bytes in size. For
a dataset of 40 million entities, it adds up to 2.24GB, which is significant. In
practice, memory spike happens when the number of allocated Delta objects is
in the magnitude of millions. It would be expected that the memory goes back to
previous state when updates are done or that is goes down if deletes were
performed.
Another example of an unusual spike in memory is during the creation of graph objects. Consider the following query:
LOAD CSV FROM "/temp.csv" WITH HEADER AS row
CREATE (:Node {id: row.id, name: row.name});This command will create multiple Delta objects for every CSV row ingested:
- One
Deltaobject for creating a node in the graph - One
Deltaobject for adding a labelNode - Two
Deltaobjects for adding propertiesidandname
The memory overhead could be even larger than in the previous example, since
this query is generating four Delta objects per row.
To avoid memory overhead, you can use periodic commit or
CALL subqueries in transactions to batch the
query into smaller chunks, which enables the Delta objects to be deallocated
during query execution. That means that there will be a lower number of Delta
objects allocated at a point in time (in the magnitude of thousands, and not in
millions).
Periodic commit
To specify how often the query will be batched, use the USING PERIODIC COMMIT num_rows pre-query directive. After every batch, the system will attempt to
clear the Delta objects to release additional memory to the system. This will
succeed if this query is the only one executing in the system at the time. The
num_rows literal is a positive integer which indicates the batch size of
processed rows after which the Delta objects will be cleaned from the system.
Consider again the previous LOAD CSV example, but with a periodic commit:
USING PERIODIC COMMIT 1000
LOAD CSV FROM "/temp.csv" WITH HEADER AS row
CREATE (:Node {id: row.id, name: row.name});Here is the query execution plan for the above query:
+---------------------+
| QUERY PLAN |
+---------------------+
| " * EmptyResult" |
| " * PeriodicCommit" |
| " * CreateNode" |
| " * LoadCsv {row}" |
| " * Once" |
+---------------------+The query plan is read from bottom to top. Notice the
PeriodicCommit operator at the end of the query used to count the number of
rows produced through that operator. After the counter reaches the limit (in
this case 1000), the query will be batched and committed, and the Delta objects
will potentially be released, if the query is the only one executing at the
time.
As opposed to the 2.24GB of additional memory overhead during query execution, the modified query with the periodic commit in batches of 1000 will produce around 224KB of additional memory overhead.
CALL subqueries in transactions
The CALL { subquery } IN TRANSACTIONS OF num_rows ROWS is an additional syntax
for periodic execution. The num_rows literal is the positive integer which
indicates the input branch batch size, after which the periodic execution will
start releasing Delta objects.
Consider this example:
explain
LOAD CSV FROM "/temp.csv" WITH HEADER AS row
CALL {
WITH row
CREATE (:Node {id: row.id, name: row.name})
} IN TRANSACTIONS OF 1000 ROWS;The syntax is similar to the periodic commit, but it offers a more fine-grained batching of the query. The query execution plan for this query is:
+-----------------------+
| QUERY PLAN |
+-----------------------+
| " * EmptyResult" |
| " * Accumulate" |
| " * PeriodicSubquery" |
| " |\\ " |
| " | * EmptyResult" |
| " | * CreateNode" |
| " | * Produce {row}" |
| " | * Once" |
| " * LoadCsv {row}" |
| " * Once" |
+-----------------------+The PeriodicSubquery is the operator that is used in this case for batching
the query and counting the number of rows. Input branch of the
PeriodicSubquery is the LoadCsv. After the number of rows have been consumed
from the input branch, the query is batched and the Delta objects are
potentially released.
Batching deletes
The memory spike usually happens when users are trying to delete a large portion of their graph which consists of millions of nodes and relationships.
To resolve this, use periodic commit. Currently, batching deletes with CALL subqueries in transactions is not implemented and user will get an exception during the query planning. Users are advised to perform periodic delete in a similar manner to the below examples.
Query to delete all nodes:
USING PERIODIC COMMIT num_rows
MATCH (n:Node)
DETACH DELETE n;Query to delete nodes labeled with Node:
USING PERIODIC COMMIT num_rows
MATCH (n:Node)
DETACH DELETE n;Query to delete relationships of type :REL:
USING PERIODIC COMMIT num_rows
MATCH (n)-[r:REL]->(m)
DELETE r;Query to delete all relationships:
USING PERIODIC COMMIT num_rows
MATCH (n)-[r]->(m)
DELETE r;Choose the num_rows which is most suitable for the amount of RAM you have
available, based on the calculations we provided before. If the deletion still
consumes too much memory, consider lowering the batch size.
ACID guarantees for periodic execution
Since the Delta objects are necessary for reverting the query, it is possible
to only guarantee the ACID compliance with respect to the batches committed
inside the query. If the query experiences a failure during execution, the query
is reverted up to the latest committed batch. Most common failure of queries is
during write-write
conflicts, and it is
recommended that no other write operations are performed during periodic
execution.