Graph data model
This page will walk you through the fundamentals of graph databases, their advantages over traditional databases, common use cases, and good practices for designing an optimal graph schema. Whether you’re exploring graph databases for the first time or looking to refine your data modeling approach, you’ll find valuable insights on how to leverage the power of graph technology for efficient and scalable data analysis.
What is a graph database?
A graph database is a database designed to store and manage data as a network of nodes (entities) and relationships (connections). Unlike traditional relational databases, where relationships are inferred through joins, graph databases store relationships as first-class citizens, enabling efficient traversal and querying.
Graph databases use graph theory principles to structure data, making them ideal for representing highly connected information. By storing data in this format, queries become more intuitive, and retrieval speeds improve, especially in scenarios where relationships drive insights.
Why use a graph database?
Graph databases are optimized for relationship-heavy data structures, where connections between entities are as important as the entities themselves. Unlike relational databases, which require complex JOIN operations to connect tables, graph databases enable direct relationship traversal, leading to:
- Faster queries – Get results quickly even across multiple hops; directly linked data reduces both latency and cost compared to complex table joins.
- Flexible schema – Easily evolve your data model without migrations.
- Scalability – Handle dynamic, interconnected data efficiently.
Common use cases
Graph databases power a wide range of applications that require fast, flexible, and scalable data traversal. Some of the most common use cases include:
- Knowledge graph: A knowledge graph structures and links information, making it easier to explore relationships between concepts. These are used in AI, semantic search, and context-aware applications like virtual assistants.
- Social network analysis: Graph databases naturally model social connections, making them ideal for community detection, influence analysis, friend recommendations.
- Fraud detection: Fraudsters often create complex, multi-hop schemes that are hard to detect in traditional databases. This makes then great for real-time anomaly detection by tracking unusual patterns and multihop relationship analysis to uncover hidden fraud networks.
- Network and IT infrastructure management: Managing complex computer networks, telecommunications systems, and IoT devices requires analyzing connectivity between devices, dependencies in network topologies, and failure points and bottlenecks.
- Recommendation systems: Graph databases enhance personalized recommendations by analyzing user behavior and preferences, similarities between products, content, or services, and real-time interactions and trends.
- Supply chain and logistics: Graph-based supply chain management helps in tracking product flow from suppliers to customers, identifying vulnerabilities in the distribution network, and optimizing delivery routes for cost and efficiency.
- Data lineage and management: Graph databases help businesses track the flow of data across systems, making it easier to maintain data integrity, monitor data dependencies, and manage regulatory compliance.
Labeled Property Graph (LPG)
Memgraph implements the Labeled Property Graph (LPG) model, a flexible and powerful way to structure data. LPG represents data as a graph of nodes (entities) and relationships (connections), both of which can have properties—key-value pairs storing additional information. This structure enables intuitive, high-performance queries without relying on complex joins, as in relational databases.
Graph Components
A graph consists of three core components: nodes, relationships, and labels.
1. Nodes
Nodes represent entities in your dataset. Each node can belong to one or multiple labels, which act as categories or types. Labels help define the role and grouping of nodes within the graph.
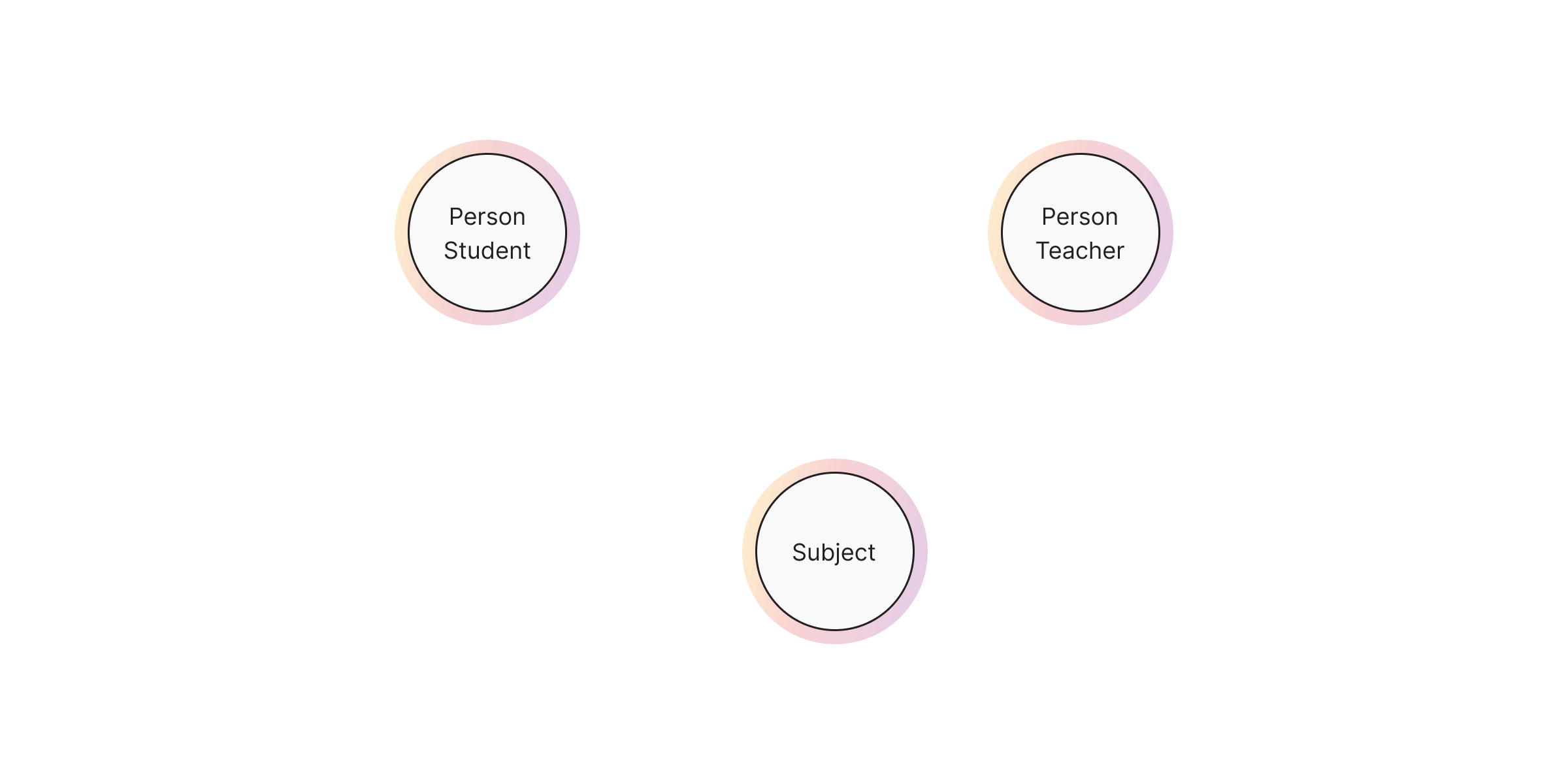
For example:
(:Person:Student {name: "Alice", age: 20})
(:Person:Teacher {name: "Mr. Smith", experience: 10})
(:Subject {name: "Mathematics"})Here, Alice is a Person node with the additional label Student, while Mr. Smith is
a Person with the label Teacher and has a property for experience.
Mathematics is a Subject node.
2. Relationships
Relationships define connections between nodes. They are directed, meaning they always have a start node and an end node, but queries can traverse them in any direction.
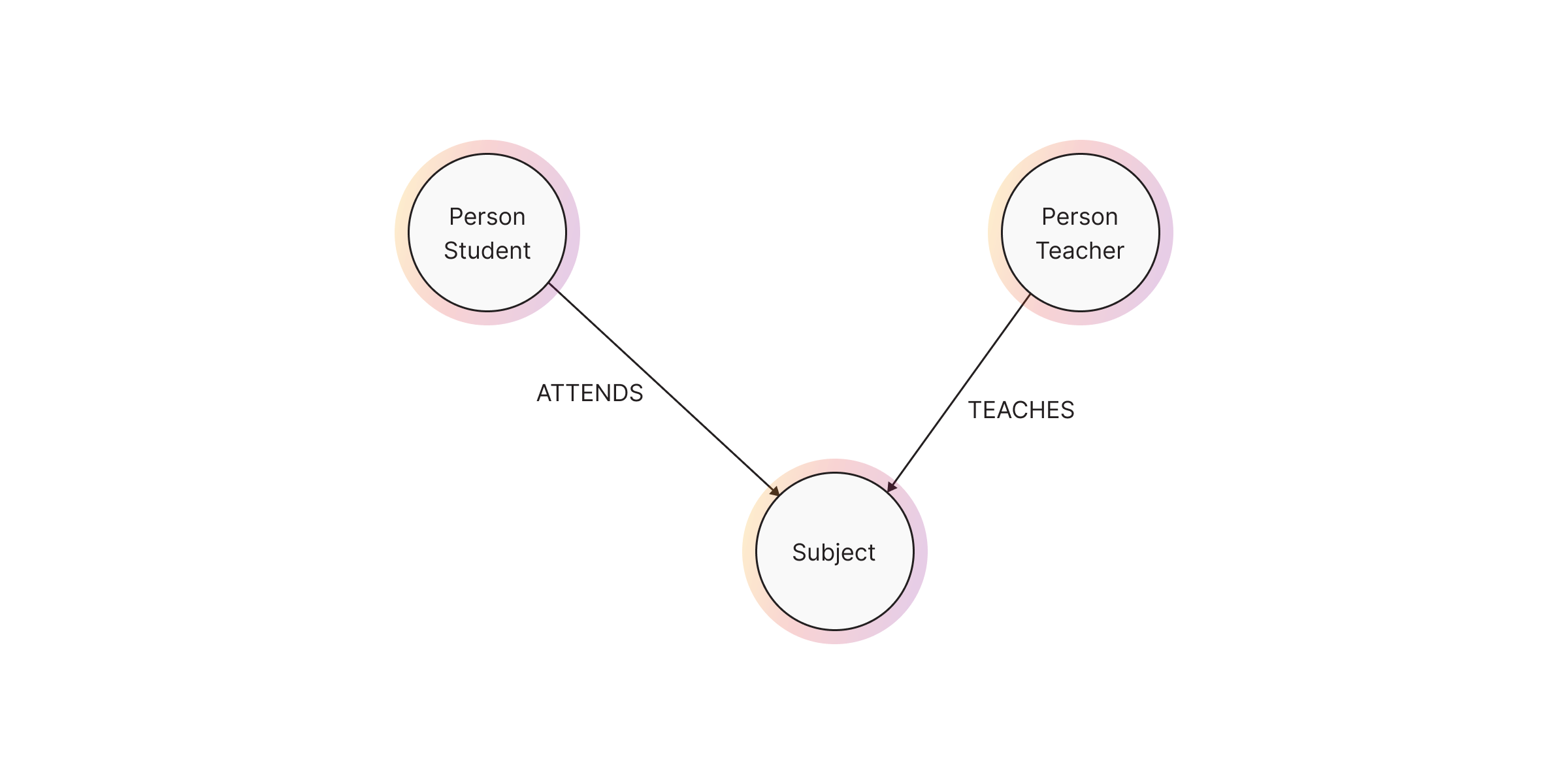
Example:
(:Person:Teacher {name: "Mr. Smith"})-[:TEACHES]->(:Subject {name: "Mathematics"})
(:Person:Student {name: "Alice"})-[:STUDIES {grade: "A"}]->(:Subject {name: "Mathematics"})TEACHES links teachers to the subjects they teach and
STUDIES links students to the subjects they study and stores a grade property.
3. Labels
Labels categorize nodes and make querying more efficient. A node can have multiple labels, allowing for flexible classification.
| Node | Label(s) | Properties |
|---|---|---|
Person:Student | Person, Student | name, dateOfBirth, yearOfStudy |
Person:Teacher | Person, Teacher | name, email, age |
Subject | Subject | name |

Using multiple labels, allows for queries such as:
MATCH (p:Person:Student) RETURN p.name;4. Properties
Both nodes and relationships can have properties, which store structured data within the graph. Properties use key-value pairs and store metadata inside nodes and relationships.
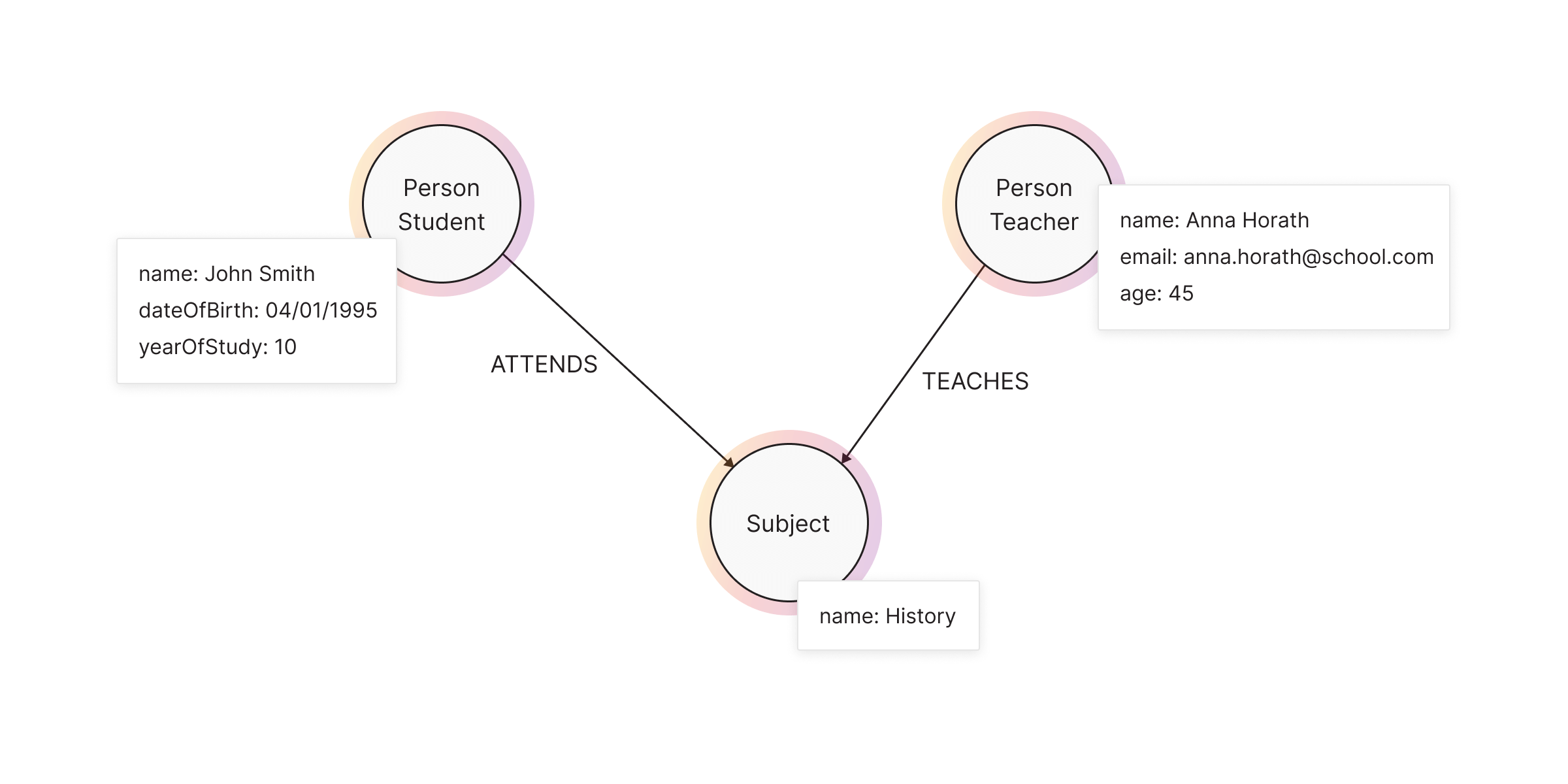
In the university example, the most relevant questions properties corresponding to the answers would be:
- What are the names of the students, professors, and courses? -
name - How old are the students and the professors? -
dateOfBirth,age - What year of studies does the student attend? -
yearOfStudies - How to get in touch with the professor? -
email
Designing a graph database schema
Designing a graph database schema starts with defining what the database will be used for. The requirements of your use case will determine the structure of your graph, including the nodes, relationships, and properties, as well as the final implementation.
A good practice is to start with a requirements document that outlines the goals and the data your graph will manage. Unlike relational databases, graph databases don’t require a predefined schema. However, well-structured data ensures efficient queries and optimized storage.
Understanding the graph property model
The property graph model focuses on nodes (entities) and relationships (connections) to explain how data is linked. A good graph model includes:
- Clear node labels to group similar entities.
- Well-defined relationships that describe how entities interact.
- Strategic use of properties (store data in relationships if it belongs to the connection itself).
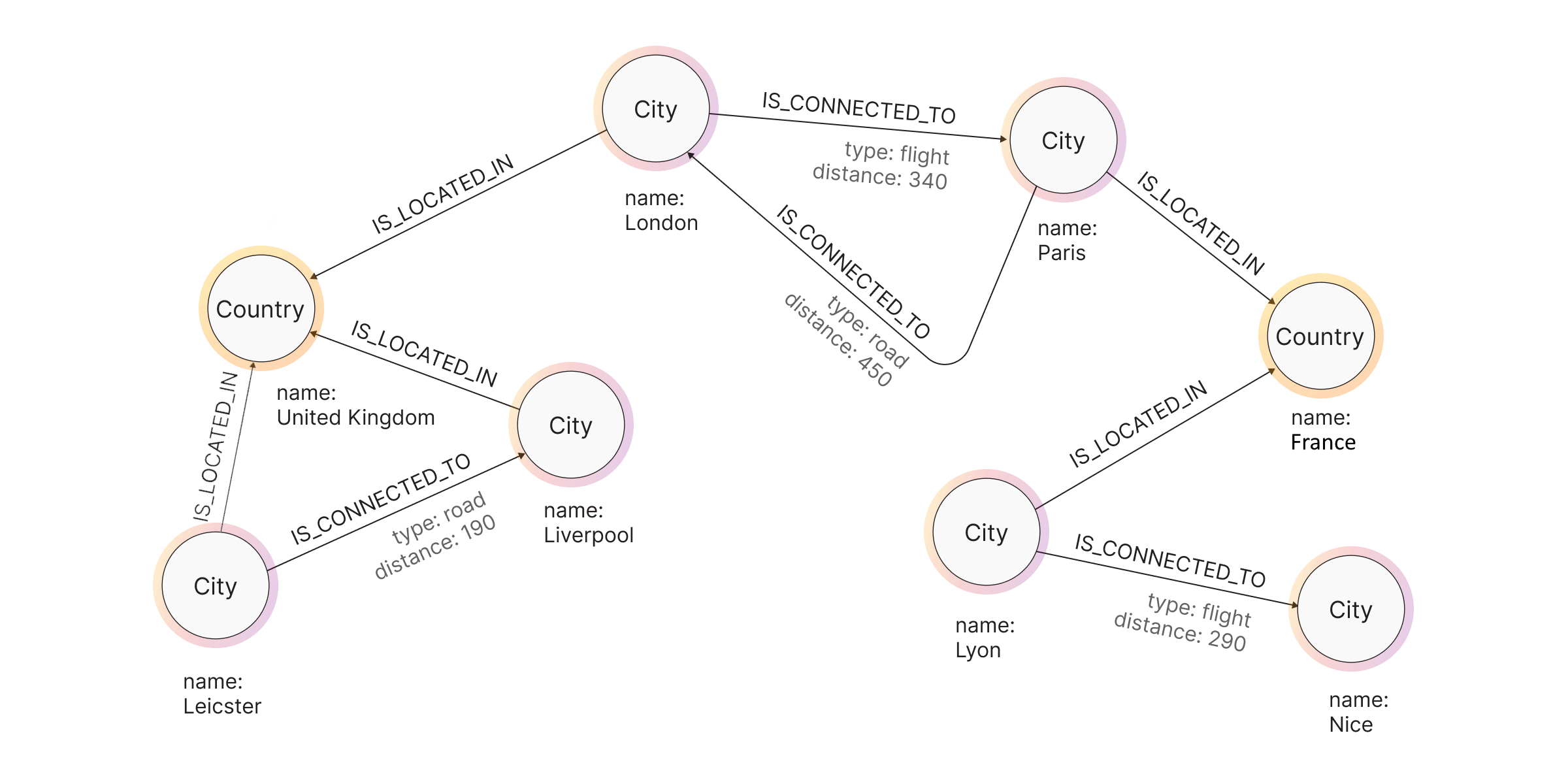
Here’s an example scenario:
-
Cities like London and Paris are connected by flights and roads.
-
Distances differ based on the mode of connection (340 km by flight and 455 km by road).
-
London is in England and connected to Liverpool and Leicester by roads (190 km distance).
-
Paris is in France and connected to Lyon and Nice by flights (290 km distance).
Defining the requirements
Before structuring a graph, answer:
- What entities exist in your domain?
- How do these entities interact?
- What properties should be stored, and where?
It helps to have a requirements document that describes the domain.
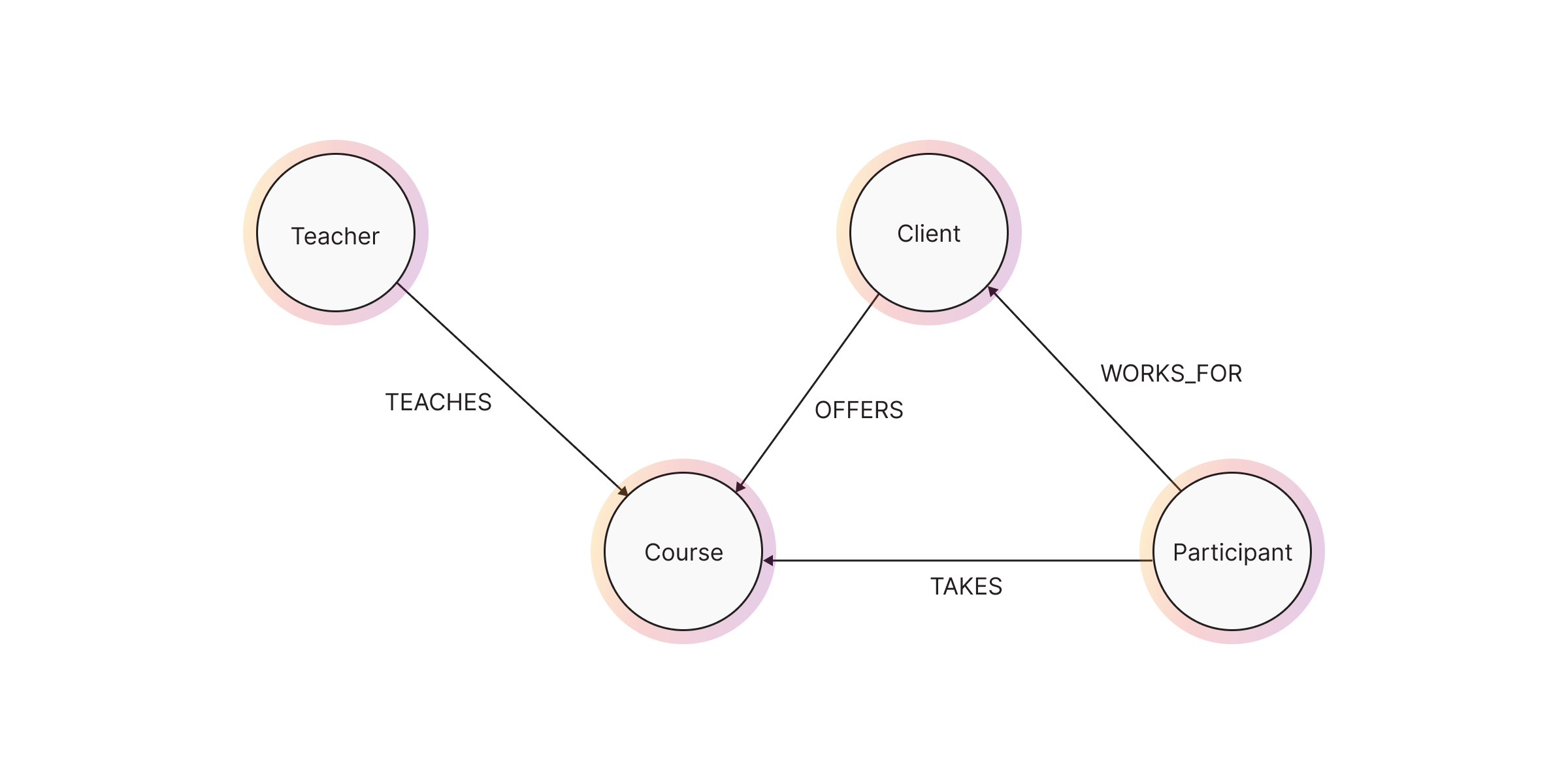
Here’s an example: The language school offers courses taught by teachers to clients and their employees. Employees (participants) may take multiple courses, and each course is taught by one teacher. Courses are either held at the client’s office or the school’s premises.
Identifying nodes
Nodes represent the core entities in your domain. If an entity has a unique identity, it’s likely a node.
From the language school scenario, the following nouns become
nodes: Teacher, Course, Client, Participant.
Mapping relationships
Relationships define how nodes interact. They are typically verbs in the requirements.
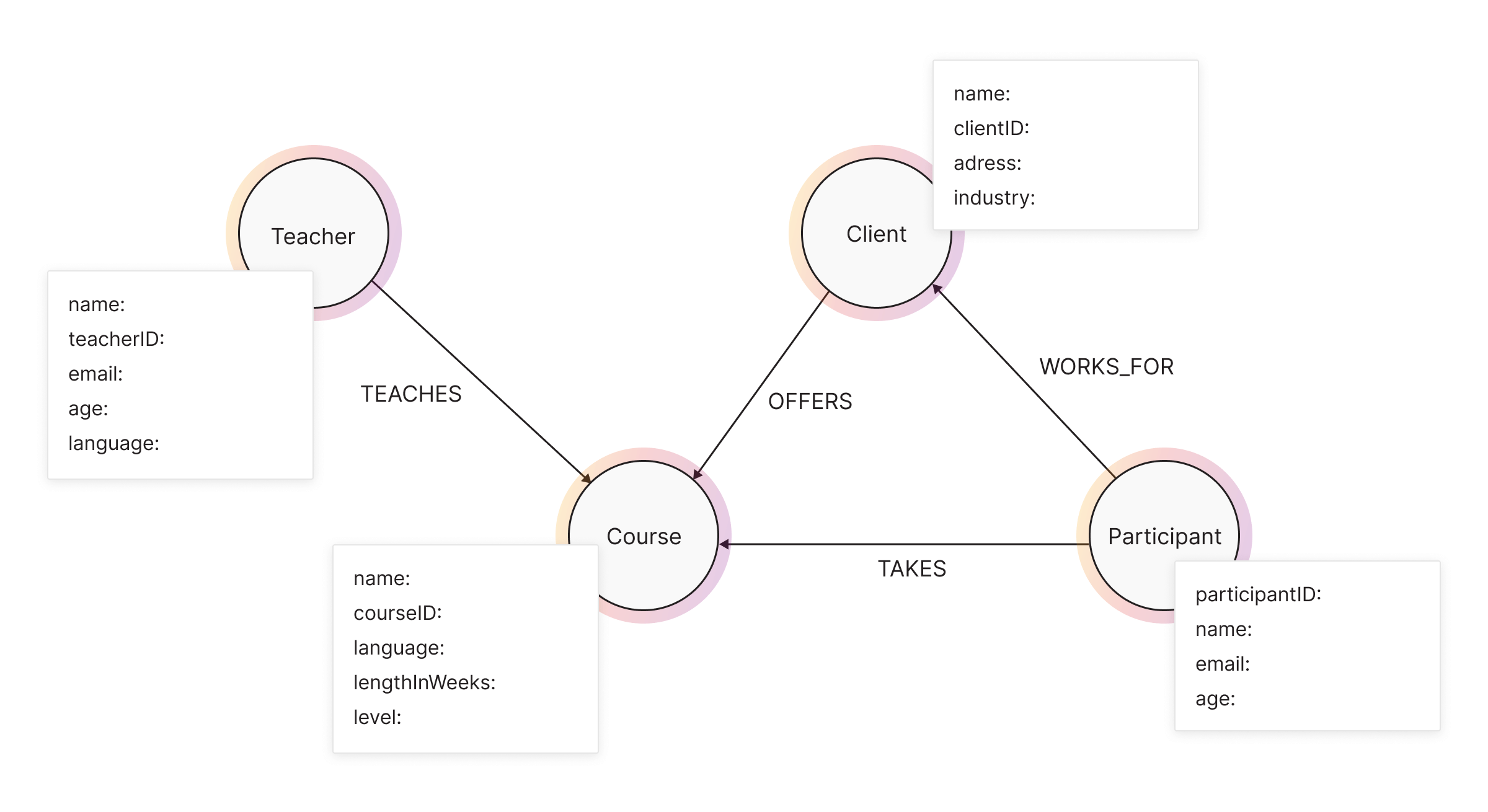
Properties to store
Deciding whether to store a property inside a node or a relationship depends on whether the data describes the entity itself or the connection between entities.
If the data describes the entity itself, it’s usually the best to store it as a node property. On the other hand, if the data describes connection between entities, then it might be better to store it as a relationship property.
Property vs. relationship
Deciding whether to model something as a property or a relationship is a common question when working with labeled property graph models. While the rules are generally straightforward, there are exceptions that depend on your data and use case.
The key principle for this decision is limiting the scope of your searches to ensure efficient queries and optimal performance. Searching through properties for shared data can significantly increase memory usage and reduce performance, especially when dealing with large datasets.
When to use a property? When you describe the entity or relationship itself or when it’s unique or specific to the node/relationship and not shared across multiple nodes.
(:Product {name: "Milk", price: 2.99, expirationDate: "2024-01-01"})Here, price and expirationDate are specific to the Milk product and make
sense as properties.
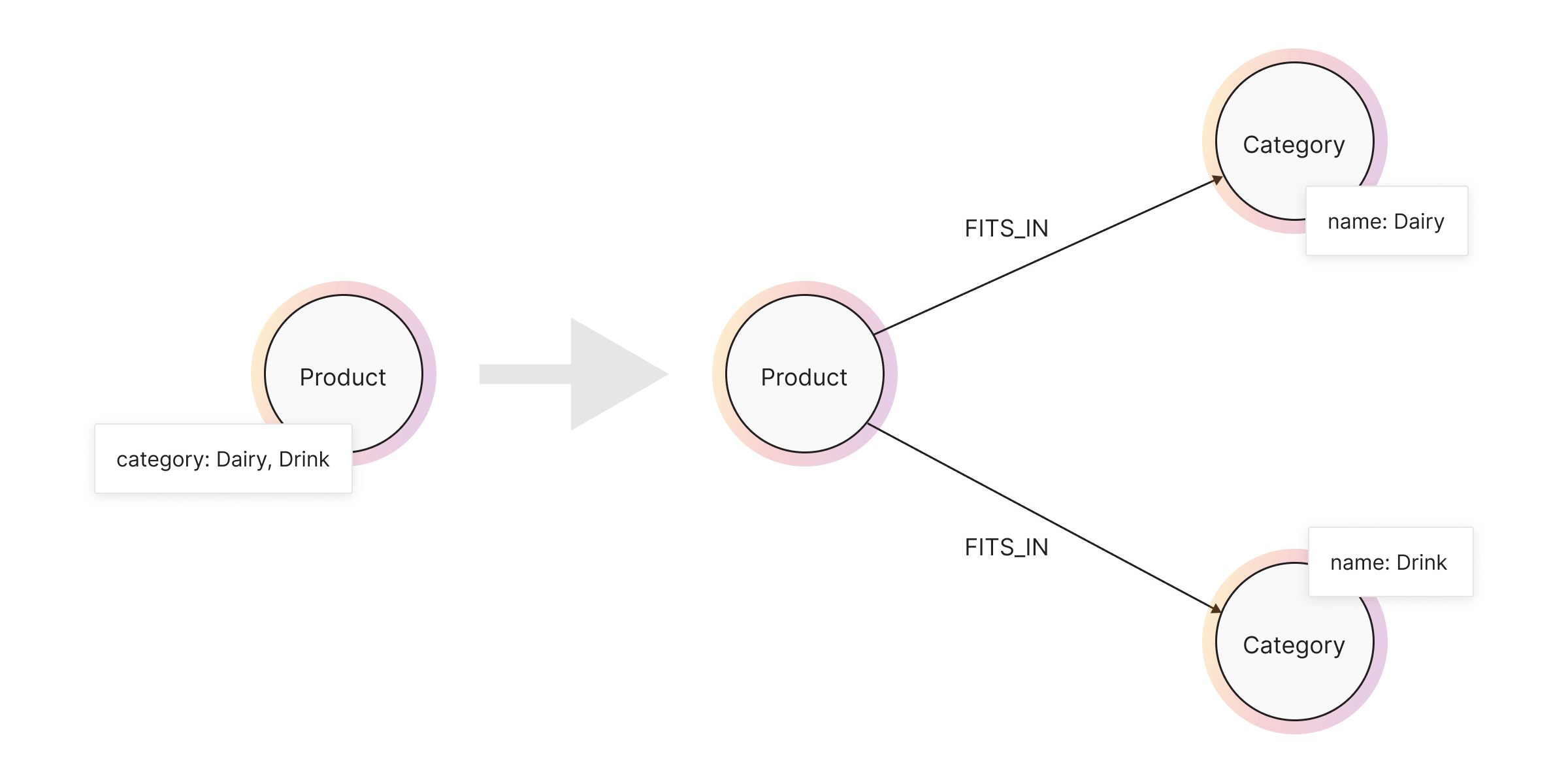
When to use a relationship? When the data connects entities and can be shared across multiple nodes or when it’s queried frequently to find related nodes or patterns. For example, in product categories.
Using a property:
(:Product {name: "Milk", categories: ["Dairy", "Organic"]})If you want to find other products in the same categories as Milk, you would
need to loop through the categories array for every node. This approach can
cause performance bottlenecks for large datasets.
Using a relationship:
(:Product {name: "Milk"})-[:BELONGS_TO]->(:Category {name: "Dairy"})
(:Product {name: "Milk"})-[:BELONGS_TO]->(:Category {name: "Organic"})This structure allows you to query related products easily:
MATCH (:Product {name: "Milk"})-[:BELONGS_TO]->(c:Category)<-[:BELONGS_TO]-(otherProducts:Product)
RETURN otherProducts.nameThis approach avoids looping through properties and significantly improves performance.
While relationships improve performance for shared data, they can make your graph more complex and require additional memory. Consider the following:
- If a property is rarely queried or unique, it’s better to keep it as a property.
- If a property is shared across nodes or frequently queried, model it as a relationship.
IMPORTANT
Creating a new node—and a corresponding relationship—for every property increases memory usage. If the property is shared across many nodes, it can result in a supernode, which can negatively impact the performance and scalability of your graph database. Avoid supernodes by carefully considering how to model shared data.
Types of graphs
There are some characteristics that define the type of graph. Here are some basic types:
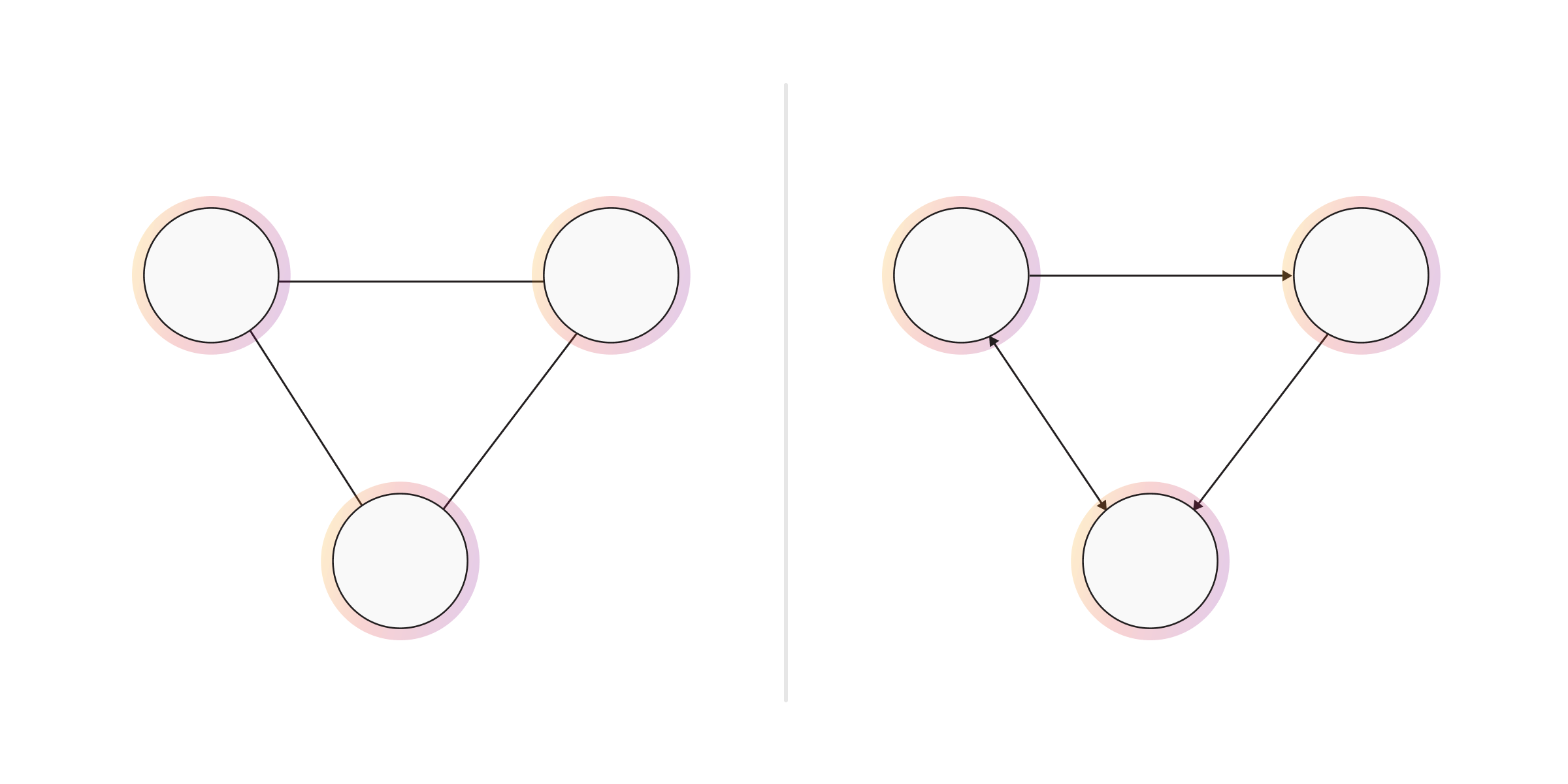
- Undirected and Directed Graphs - In an undirected graph, the relationships have no orientation. These relationships are sometimes referred to as bi-directional. The relationships in a directed graph have an orientation.
- Weighted And Unweighted Graphs - A weighted graph has attributes on its relationships that specify their weight. For example, a relationship that represents the distance between two cities would have this distance stored as a relationship attribute. Unweighted graphs have no such relationship attributes and are sometimes referred to as Non-Weighted Graphs.
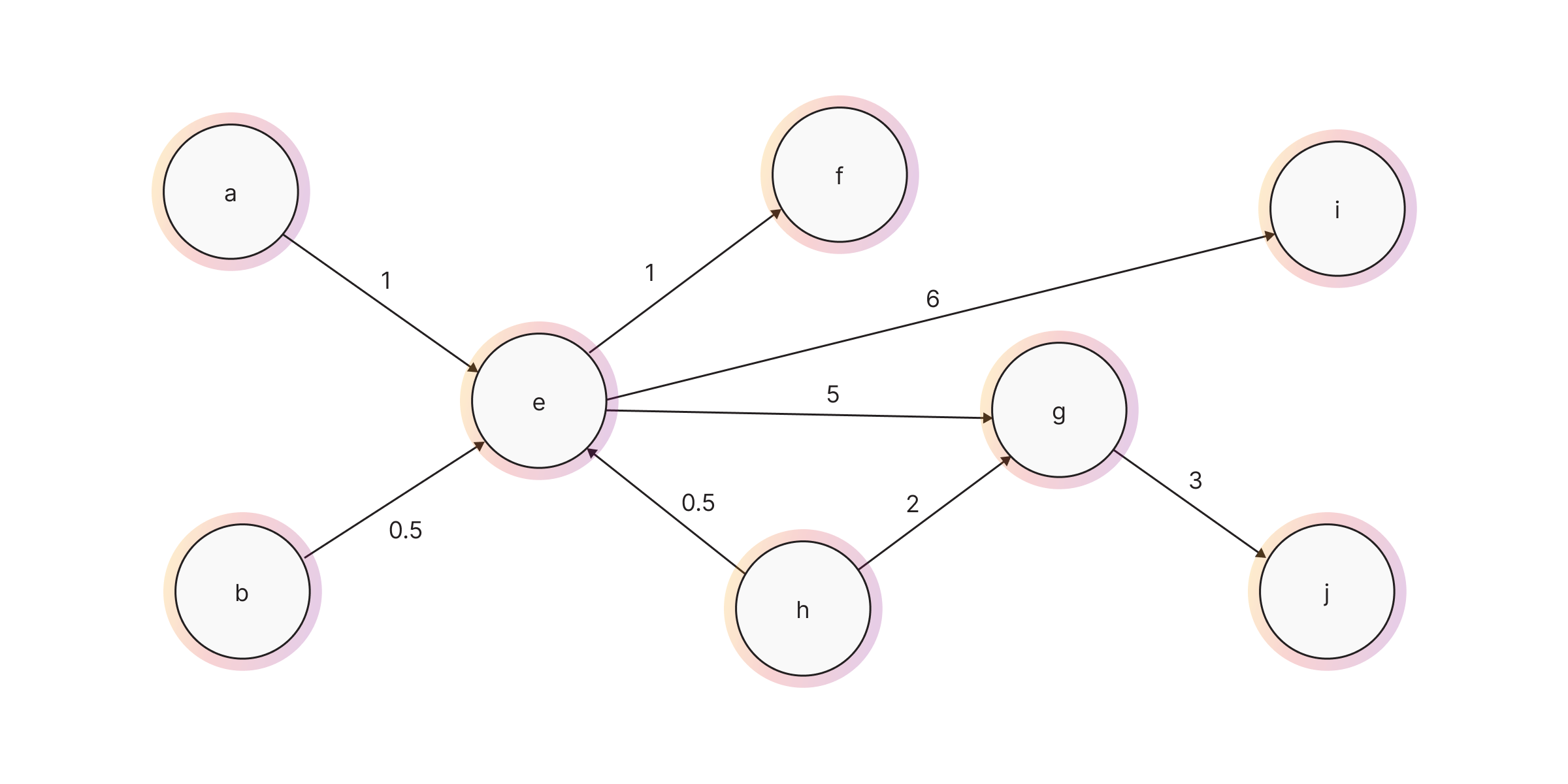
On top of direction and graph can also have a self-loop (also called a loop or a buckle). Self-loop is a relationship that connects a node to itself, while parallel relationships (also called multiple relationships or a multi-relationship) are two or more relationships that are incident to the same two nodes.

With a combination of mentioned characteristics and properties, you can create different graphs:
- Graph - An undirected graph with self-loops.
- DiGraph - A directed graph with self-loops.
- MultiGraph - An undirected graph with self-loops and parallel relationships.
- MultiDiGraph - A directed graph with self-loops and parallel relationships.