Create graph objects
For creating graph objects, you can use the following clauses.
CREATE, for creating new nodes and relationships.SET, for adding new or updating existing labels and properties.
You can still use the RETURN clause to produce results after writing, but it
is not mandatory.
Details on which kind of data can be stored in Memgraph can be found in the Storage chapter.
Indexing can increase performance when executing queries. Please take a look at our documentation on indexing for more details.
CREATE
This clause is used to add new nodes and relationships to the database. The creation is
done by providing a pattern, similarly to MATCH clause.
For example, use this query to create two new nodes connected with a new relationship.
CREATE (node1)-[:RELATIONSHIP_TYPE]->(node2);Labels and properties can be set during creation using the same syntax as in
MATCH patterns. For example, creating a node with a label and a property:
CREATE (node:Label {property: 'my property value'});Additional information on CREATE is available here.
WITH
The write part of the query cannot be simply followed by another read part. To
combine them, the WITH clause must be used. The names this clause establishes
are transferred from one part to another.
For example, creating a node and finding all nodes with the same property.
CREATE (node {property: 42}) WITH node.property AS propValue
MATCH (n {property: propValue}) RETURN n;Note that the node is not visible after WITH, since only node.property was
carried over.
This clause behaves very much like RETURN, so you should refer to features of
RETURN.
MERGE
The MERGE clause is used to ensure that a pattern you are looking for exists
in the database. This means that it will be created if the pattern is not found.
In a way, this clause is like a combination of MATCH and CREATE.
For example, ensure that a person has at least one friend:
MATCH (n:Person) MERGE (n)-[:FRIENDS_WITH]->(m);The clause also provides additional features for updating the values depending
on whether the pattern was created or matched. This is achieved with ON CREATE
and ON MATCH sub clauses.
For example, set different properties depending on what MERGE did:
MATCH (n:Person) MERGE (n)-[:FRIENDS_WITH]->(m)
ON CREATE SET m.prop = "created" ON MATCH SET m.prop = "existed";For more details, check out this guide.
Import existing data from CSV
Using CSV files is just one of the ways to import your
data into Memgraph. The LOAD CSV clause enables
you to load and use data from a
CSV file. Memgraph supports the Excel CSV dialect, as it’s the most commonly
used one. For the syntax of the clause, please check the LOAD
CSV page in the Cypher manual.
Relationships
Relationships (or edges) are the lines that connect nodes to each other and represent a defined connection between them. Every relationship has a source node and a target node that represent in which direction the relationship works. If this direction is important, the relationship is considered directed, otherwise, it’s undirected.
Relationships can also store data in the form of properties, just as nodes. In most cases, relationships store quantitative properties such as weight, costs, distances, ratings, etc.
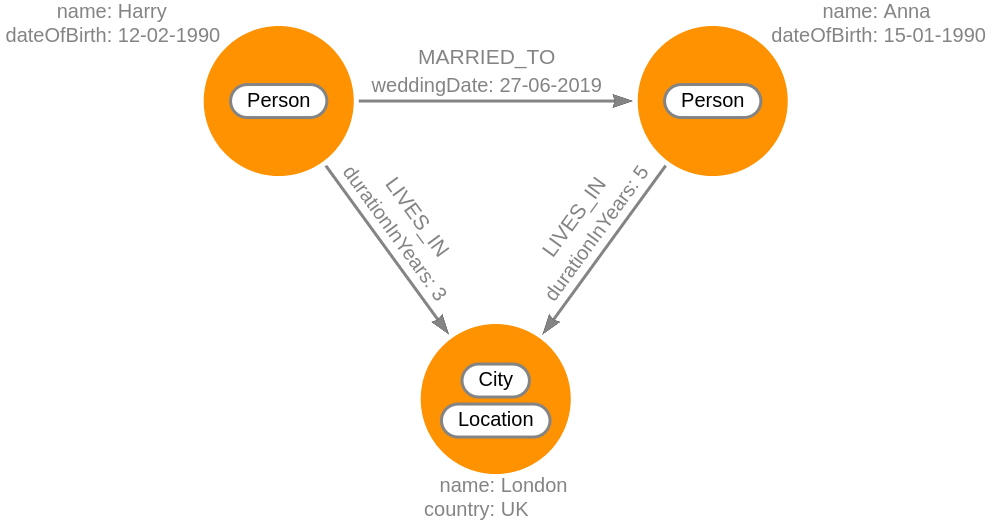
In our example, the relationship between two nodes labeled Person could be of
the type MARRIED_TO. The relationship between Person and City is
represented by the type LIVES_IN.
The relationship of the type MARRIED_TO has the property weddingDate, which
represents the date when the marriage was formed. Relationships of the type
LIVES_IN have the property durationInYears which denotes how long a person
has lived in the specified location.
Creating relationships
To create a relationship between two nodes, we need to specify which nodes
either by creating them or filtering them with the WHERE clause:
CREATE (p1:Person {name: 'Harry'}), (p2:Person {name: 'Anna'})
CREATE (p1)-[r:MARRIED_TO]->(p2)
RETURN p1, r, p2;If the nodes already existed, the query would look like this:
MATCH (p1:Person),(p2:Person)
WHERE p1.name = 'Harry' AND p2.name = 'Anna'
CREATE (p1)-[r:MARRIED_TO]->(p2)
RETURN p1, r, p2;Instead of using the CREATE clause, you are just searching for existing nodes
using the WHERE clause and accessing them using variables p1 and p2.
Retrieving relationship types
The built-in function type() can be used to return the type of a relationship:
CREATE (p1:Person {name: 'Harry'}), (p2:Person {name: 'Anna'})
CREATE (p1)-[r:MARRIED_TO {weddingDate: '27-06-2019'}]->(p2)
RETURN type(r);Querying using relationships
You can query the database using relationship types. The following query will return nodes connected with the relationship of the following type:
MATCH (p1)-[r:MARRIED_TO]->(p2)
RETURN p1, r, p2;Relationship properties
Just like with properties on nodes, the same rules apply when creating or matching a relationship. You can add properties to relationships at the time of creation:
CREATE (p1:Person {name: 'Harry'}), (p2:Person {name: 'Anna'})
CREATE (p1)-[r:MARRIED_TO {weddingDate: '27-06-2019'}]->(p2)
RETURN p1, r, p2;You can also specify them in the MATCH clause:
MATCH (p1)-[r:MARRIED_TO {weddingDate: '27-06-2019'}]->(p2)
RETURN p1, r, p2;