Import data from JSONL files
A JSONL file is a file in which every line is a separate JSON document. Each line is parsed as node
or edge and each key in the JSON document is used as a node’s or edge’s property. The data from JSONL files
can be imported using LOAD JSONL clause.
LOAD JSONL Cypher clause
The LOAD JSONL clause uses simdjson library to parse JSON documents as
fast as possible. It can be used to load JSONL documents from the local disk, http, https, ftp and S3 servers.
LOAD JSONL clause syntax
The syntax of the LOAD JSONL clause is:
LOAD JSONL FROM <jsonl-location> ( WITH CONFIG configsMap=configMap ) ? AS <variable-name><jsonl-location>is a string representing the path from which JSONL file should be loaded. There are no restrictions on where in your file system the file can be located, as long as the path is valid (i.e., the file exists). Files can be imported directly from the public URL and S3. If you are using Docker to run Memgraph, you will need to copy the files from your local directory into Docker container where Memgraph can access them.<configs>Represents an optional configuration map through which you can specify configuration options:aws_region,aws_access_key,aws_secret_keyandaws_endpoint_url.<aws_region>: The region in which your S3 service is being located<aws_access_key>: Access key used to connect to S3 service<aws_secret_key>: Secret key used to connect S3 service<aws_endpoint_url>: Optional configuration parameter. Can be used to set the URL of the S3 compatible storage.
<variable-name>is a symbolic name representing the variable to which the contents of the parsed row will be bound to, enabling access to the row contents later in the query. The variable doesn’t have to be used in any subsequent clause.
LOAD JSONL clause specificities
When using the LOAD JSONL clause please keep in mind:
-
The JSONL parser parses the values in their appropriate type so you should get the same property type in Memgraph as in JSONL file. Memgraph supports the following JSON types:
-
string: The property in Memgraph will be of type string. -
uint64_t: The property in Memgraph will be cast to int64_t because Cypher standard doesn’t support uint64_t. -
int64_t: The property in Memgraph will be saved as int64_t. -
double: The property in Memgraph will be used as floating point number. -
boolean: The property in Memgraph will be saved as bool. -
array: The property in Memgraph will be saved as list. -
object: The property in Memgraph will be saved as map. -
The
LOAD JSONLclause is not a standalone clause, meaning a valid query must contain at least one more clause, for example:
LOAD JSONL FROM "./people.jsonl" AS row CREATE (p:Person) SET p += row; In this regard, the following query will throw an exception:
LOAD JSONL FROM "./file.jsonl" AS row;Adding a MATCH or MERGE clause before LOAD JSONL allows you to match certain entities in the graph before running LOAD JSONL, optimizing the process as
matched entities do not need to be searched for every row in the JSONL file.
But, the MATCH or MERGE clause can be used prior the LOAD JSONL clause only
if the clause returns only one row. Returning multiple rows before calling the
LOAD JSONL clause will cause a Memgraph runtime error.
- The
LOAD JSONLclause can be used at most once per query, so queries like the one below will throw an exception:
LOAD JSONL FROM "/x.jsonl" AS x
LOAD JSONL FROM "/y.jsonl" AS y
CREATE (n:A {p1 : x, p2 : y});Load from remote sources
The LOAD JSONL clause supports loading files from HTTP/HTTPS/FTP URLs and S3 buckets.
Load from HTTP/HTTPS/FTP
When loading from HTTP, HTTPS, or FTP URLs, the file will be downloaded to the /tmp directory before being imported:
LOAD JSONL FROM "https://download.memgraph.com/asset/docs/people_nodes.jsonl" AS row
CREATE (n:Person {id: row.id, name: row.name, age: row.age, city: row.city});You can also use FTP URLs:
LOAD JSONL FROM "ftp://example.com/data/nodes.jsonl" AS row
CREATE (n:Node) SET n += row;Load from S3
To load files from S3, you can provide AWS credentials in three ways:
1. Using WITH CONFIG clause (Recommended for query-specific credentials)
LOAD JSONL FROM "s3://my-bucket/path/to/file.jsonl"
WITH CONFIG {
aws_region: "us-east-1",
aws_access_key: "YOUR_ACCESS_KEY",
aws_secret_key: "YOUR_SECRET_KEY"
}
AS row
CREATE (n:Node) SET n += row;For S3-compatible services (like MinIO), you can also specify the endpoint URL:
LOAD JSONL FROM "s3://my-bucket/data/nodes.jsonl"
WITH CONFIG {
aws_region: "us-east-1",
aws_access_key: "YOUR_ACCESS_KEY",
aws_secret_key: "YOUR_SECRET_KEY",
aws_endpoint_url: "https://s3-compatible-service.example.com"
}
AS row
CREATE (n:Node) SET n += row;2. Using environment variables
Set environment variables before starting Memgraph:
export AWS_REGION="us-east-1"
export AWS_ACCESS_KEY="YOUR_ACCESS_KEY"
export AWS_SECRET_KEY="YOUR_SECRET_KEY"
export AWS_ENDPOINT_URL="https://s3-compatible-service.example.com" # OptionalThen you can load files without specifying credentials in the query:
LOAD JSONL FROM "s3://my-bucket/path/to/file.jsonl" AS row
CREATE (n:Node) SET n += row;3. Using database settings
Set database-level AWS credentials:
SET DATABASE SETTING 'aws.region' TO 'us-east-1';
SET DATABASE SETTING 'aws.access_key' TO 'YOUR_ACCESS_KEY';
SET DATABASE SETTING 'aws.secret_key' TO 'YOUR_SECRET_KEY';
SET DATABASE SETTING 'aws.endpoint_url' TO 'https://s3-compatible-service.example.com'; -- OptionalThen load files without credentials in the query:
LOAD JSONL FROM "s3://my-bucket/path/to/file.jsonl" AS row
CREATE (n:Node) SET n += row;Credential precedence: If credentials are provided in multiple ways, the order of precedence is:
- WITH CONFIG clause in the query (highest priority)
- Environment variables
- Database settings (lowest priority)
When loading files from remote locations (HTTP, FTP, or S3), the file is first
downloaded to /tmp before being loaded into memory. Ensure you have sufficient
disk space for large files. The download can be interrupted using TERMINATE TRANSACTIONS <tx_id>. To find the transaction ID, use SHOW TRANSACTIONS.
| Option | Required | Description |
|---|---|---|
| aws_region | Yes | The AWS region where your S3 bucket is located (e.g., “us-east-1”) |
| aws_access_key | Yes | Your AWS access key ID |
| aws_secret_key | Yes | Your AWS secret access key |
| aws_endpoint_url | No | Custom endpoint URL for S3-compatible services |
Increase import speed
The LOAD JSONL clause will create relationships much faster and consequently
speed up data import if you create indexes on nodes or
node properties once you import them:
CREATE INDEX ON :Node(id);If the LOAD JSONL clause is merging data instead of creating it, create indexes
before running the LOAD JSONL clause.
The construct USING PERIODIC COMMIT <BATCH_SIZE> also improves the import speed because
it optimizes memory allocation patterns. In our benchmarks, periodic commit
speeds up the execution from 25% to 35%.
USING PERIODIC COMMMIT 1024 LOAD CLAUSE FROM "/x.jsonl" AS x
CREATE (n:A {p1 : x, p2 : y});You can also speed up the import if you switch Memgraph to analytical storage mode. In the analytical storage mode there are no ACID guarantees besides manually created snapshots. After import you can switch the storage mode back to transactional and enable ACID guarantees.
You can switch between modes within the session using the following query:
STORAGE MODE IN_MEMORY_{TRANSACTIONAL|ANALYTICAL};If you use IN_MEMORY_ANALYTICAL mode and have nodes and relationships stored in
separate JSONL files, you can run multiple concurrent LOAD JSONL queries to import data even faster.
In order to achieve the best import performance, split your nodes and relationships
files into smaller files and run multiple LOAD JSONL queries in parallel.
The key is to run all LOAD JSONL queries which create nodes first. After that, run
all LOAD JSONL queries that create relationships.
Import multiple JSONL files with distinct graph objects
In this example, the data is split across four files, each file contains nodes of a single label or relationships of a single type. Files are downloaded from public URLs. The same approach works for S3 files when proper credentials are provided.
JSONL files
-
people_nodes.jsonlis used to create nodes labeled:Person.
The file contains the following data:{"id": 100, "name": "Daniel", "age": 30, "city": "London"} {"id": 101, "name": "Alex", "age": 15, "city": "Paris"} {"id": 102, "name": "Sarah", "age": 17, "city": "London"} {"id": 103, "name": "Mia", "age": 25, "city": "Zagreb"} {"id": 104, "name": "Lucy", "age": 21, "city": "Paris"} -
restaurants_nodes.jsonlis used to create nodes labeled:Restaurants.
The file contains the following data:{"id": 200, "name": "Mc Donalds", "menu": "Fries;BigMac;McChicken;Apple Pie"} {"id": 201, "name": "KFC", "menu": "Fried Chicken;Fries;Chicken Bucket"} {"id": 202, "name": "Subway", "menu": "Ham Sandwich;Turkey Sandwich;Foot-long"} {"id": 203, "name": "Dominos", "menu": "Pepperoni Pizza;Double Dish Pizza;Cheese filled Crust"} -
people_relationships.jsonlis used to connect people with the:IS_FRIENDS_WITHrelationship.
The file contains the following data:{"first_person": 100, "second_person": 102, "met_in": 2014} {"first_person": 103, "second_person": 101, "met_in": 2021} {"first_person": 102, "second_person": 103, "met_in": 2005} {"first_person": 101, "second_person": 104, "met_in": 2005} {"first_person": 104, "second_person": 100, "met_in": 2018} {"first_person": 101, "second_person": 102, "met_in": 2017} {"first_person": 100, "second_person": 103, "met_in": 2001} -
restaurants_relationships.jsonlis used to connect people with restaurants using the:ATE_ATrelationship.
The file contains the following data:{"PERSON_ID": 100, "REST_ID": 200, "liked": true} {"PERSON_ID": 103, "REST_ID": 201, "liked": false} {"PERSON_ID": 104, "REST_ID": 200, "liked": true} {"PERSON_ID": 101, "REST_ID": 202, "liked": false} {"PERSON_ID": 101, "REST_ID": 203, "liked": false} {"PERSON_ID": 101, "REST_ID": 200, "liked": true} {"PERSON_ID": 102, "REST_ID": 201, "liked": true}
Import nodes
Each row will be parsed as a map, and the
fields can be accessed using the property lookup syntax (e.g. id: row.id). Files should be downloaded and then accessed from the local disk.
The following query will load row by row from the file, and create a new node for each row with properties based on the parsed row values:
LOAD JSONL FROM "https://download.memgraph.com/asset/docs/people_nodes.jsonl"
AS row
CREATE (n:Person {id: row.id, name: row.name, age: row.age, city: row.city});In the same manner, the following query will create a new node for each restaurant:
LOAD JSONL FROM "https://download.memgraph.com/asset/docs/restaurants_nodes.jsonl" AS row
CREATE (n:Restaurant {id: row.id, name: row.name, menu: row.menu});Create indexes
Creating an index on a property used to connect nodes
with relationships, in this case, the id property of the :Person nodes,
will speed up the import of relationships, especially with large datasets:
CREATE INDEX ON :Person(id);Import relationships
The following query will create relationships between the people nodes:
LOAD JSONL FROM "https://download.memgraph.com/asset/docs/people_relationships.jsonl" AS row
MATCH (p1:Person {id: row.first_person})
MATCH (p2:Person {id: row.second_person})
CREATE (p1)-[f:IS_FRIENDS_WITH]->(p2)
SET f.met_in = row.met_in;The following query will create relationships between people and restaurants where they ate:
LOAD JSONL FROM "https://download.memgraph.com/asset/docs/restaurants_relationships.jsonl" AS row
MATCH (p1:Person {id: row.PERSON_ID})
MATCH (re:Restaurant {id: row.REST_ID})
CREATE (p1)-[ate:ATE_AT]->(re)
SET ate.liked = ToBoolean(row.liked);Final result
Run the following query to see how the imported data looks as a graph:
MATCH p=()-[]-() RETURN p;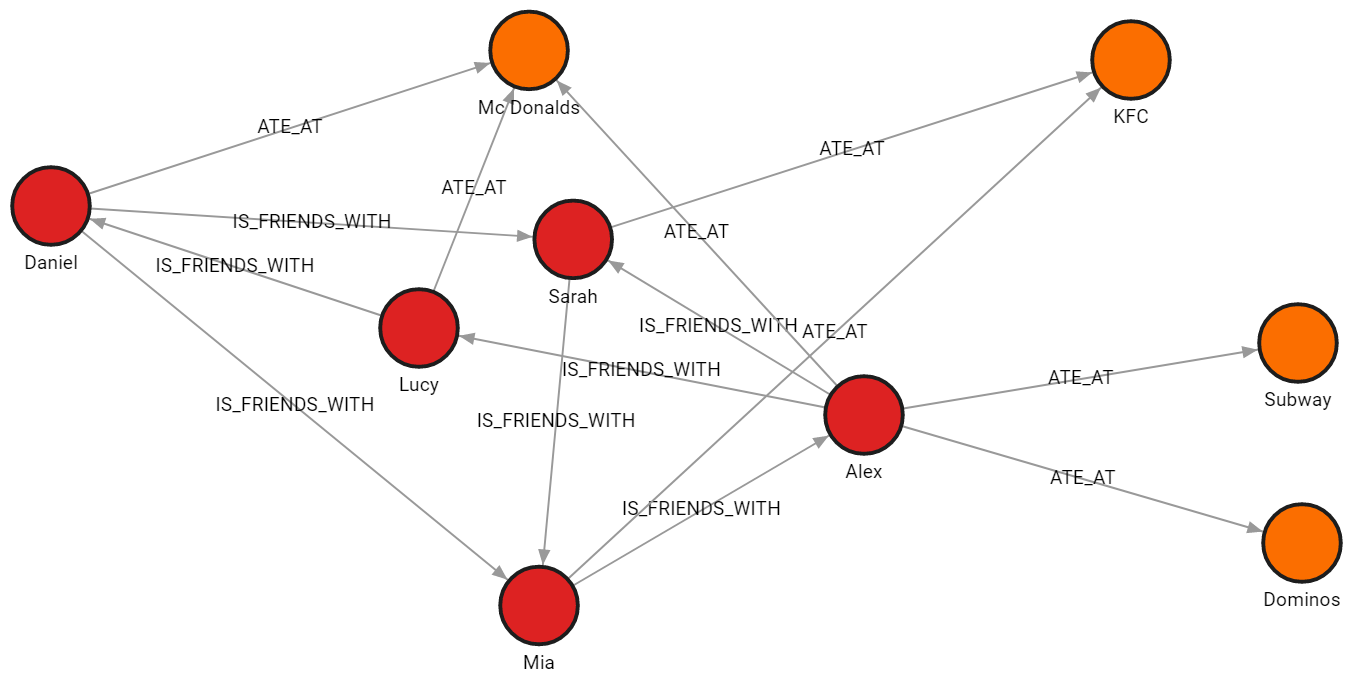
Import data from JSON files
A JSON file is a file that stores simple data structures and objects in JavaScript Object Notation format, which is a standard data interchange format. The data you want to import to the database is often saved in JSON format, and you might want to import parts of that data as graph objects - nodes or relationships.
Data can be imported using query modules implemented in the MAGE library:
json_utilquery moduleimport_utilquery module.
The difference is that json_util.load_from_path() has no requirements about
the formatting of data inside the JSON file, while the import_util.json()
procedure requires data to be formatted in a specific way. It is the same
formatting the export_util.json() procedure generates when it’s used to export
data from Memgraph into a JSON file.
JSON file data format required by the import_util.json() procedure:
[
{
"id": 6114,
"labels": [
"Person"
],
"properties": {
"name": "Anna"
},
"type": "node"
},
{
"id": 6115,
"labels": [
"Person"
],
"properties": {
"name": "John"
},
"type": "node"
},
{
"id": 6116,
"labels": [
"Person"
],
"properties": {
"name": "Kim"
},
"type": "node"
},
{
"end": 6115,
"id": 21120,
"label": "IS_FRIENDS_WITH",
"properties": {},
"start": 6114,
"type": "relationship"
},
{
"end": 6116,
"id": 21121,
"label": "IS_FRIENDS_WITH",
"properties": {},
"start": 6114,
"type": "relationship"
},
{
"end": 6116,
"id": 21122,
"label": "IS_MARRIED_TO",
"properties": {},
"start": 6115,
"type": "relationship"
}
]To be able to call the procedures, you need to install MAGE graph library and load query modules.
The library is already a part of the memgraph-platform and memgraph-mage Docker images.
If you can choose the format of the data you want to import, the fastest way to import data into Memgraph is from a CSV file using the LOAD CSV clause. Learn more about the shortest path to import data into Memgraph by reading best practices for import.
Examples
Below, you can find two examples of how to load data from a JSON file depending on the file location:
Load JSON from a local file
To import data from a local JSON file, you can use the
json_util.load_from_path() procedure
or import_util.json() procedure.
The difference is that json_util.load_from_path() has no requirements about
the formatting of data inside the JSON file while the import_util.json()
procedure does. It is the same formatting the export_util.json() procedure
generates when it’s used to export data from Memgraph into a JSON file.
json_util.load_from_path() procedure
The json_util.load_from_path() procedure takes one string argument (path)
and returns a list of JSON objects from the file located at the provided path.
Let’s import data from a file data.json with the following content:
{
"first_name": "Jessica",
"last_name": "Rabbit",
"pets": ["dog", "cat", "bird"]
}If you are using Docker to run Memgraph, you will need to copy the files from your local directory into the Docker container where Memgraph can access them.
To create a node with the label Person and first_name, last_name and pets
as properties, run the following query:
CALL json_util.load_from_path("path/to/data.json")
YIELD objects
UNWIND objects AS o
CREATE (:Person {first_name: o.first_name, last_name: o.last_name, pets: o.pets});After you execute the above query, the graph in Memgraph should look like this:

import_util.json() procedure
To find out how to import data with the import_util.json() procedure check
out the MAGE documentation.
Load JSON from a remote address
To import data from a remote JSON file, use load_from_url(url) procedure that
takes one string argument (url) and returns a list of JSON objects from the
file located at the provided URL.
For example, at "https://download.memgraph.com/asset/mage/data.json", you can
find the following data.json file:
{
"first_name": "James",
"last_name": "Bond",
"pets": ["dog", "cat", "fish"]
}To create a node with the label Person and first_name, last_name and
pets as properties from the data.json file. You can run the following query:
CALL json_util.load_from_url("https://download.memgraph.com/asset/mage/data.json")
YIELD objects
UNWIND objects AS o
CREATE (:Person {first_name: o.first_name, last_name: o.last_name, pets: o.pets});After you run the above query, the graph in Memgraph should look like this:
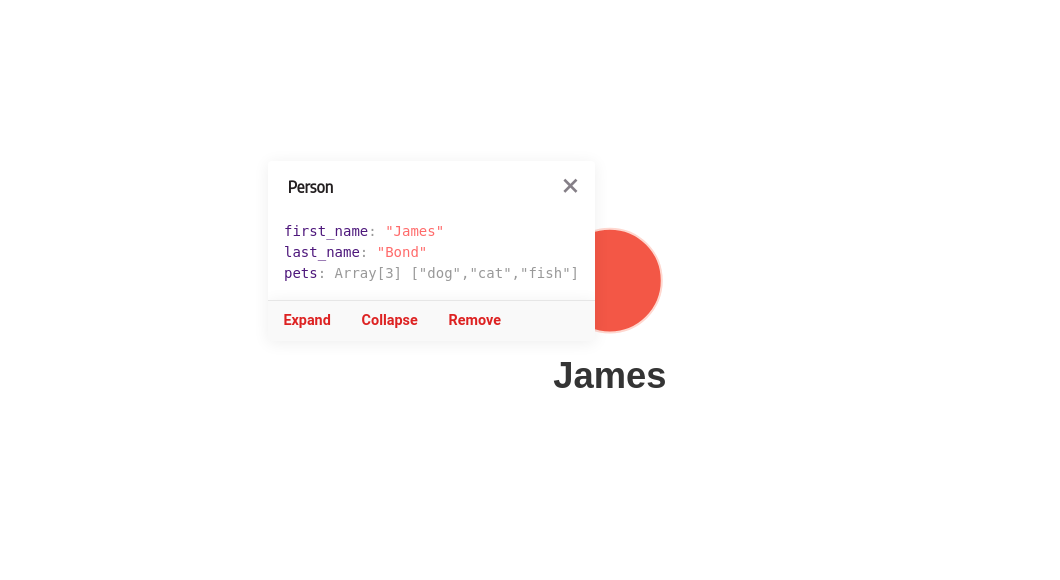
To load JSON files from another local or remote location, just replace the argument of the procedure with the appropriate path or URL. If you want to create a different kind of graph, you need to change the query accordingly.