Getting started with Memgraph
Get Memgraph up and running on your data by following these installation steps for Docker environment. If you’re new to Memgraph or you’re in a developing stage, we recommend installing Memgraph Platform. Besides the database, you’ll also have all the tools you might need to analyze your data, such as command-line interface mgconsole, web interface Memgraph Lab and a complete set of algorithms within a MAGE library running.
Memgraph Platform is no longer a single-container application. Before (Memgraph < 2.14), Memgraph Platform was a separate Docker image released on Docker Hub. This image is no longer supported, because having database service and client service in the same container is not a good practice. Still, with Memgraph Lab being released on Docker Hub, it is possible to run Memgraph MAGE and Lab as two separate services, and in that way, running Memgraph Platform as a multi-container application with Docker Compose.
Install Memgraph Platform
If you want to quickly try out Memgraph Platform (Memgraph database + MAGE library + Memgraph Lab) for the first time, do the following:
Install Docker
Ensure Docker is running in the background.
Run Memgraph Platform
Depending on your operating system, execute the appropriate command in the console:
curl https://install.memgraph.com | shThe above command runs a script that downloads a Docker Compose
file
to your system, builds and starts memgraph-mage and memgraph-lab Docker
services in two separate containers. The Docker Compose file is downloaded into
a folder called memgraph-platform usually located inside the user folder, e.g.
/Users/katelatte/memgraph-platform. You’ll see the message during the download
process, similar to:
-e Downloading docker compose file to: /Users/katelatte/memgraph-platform/docker-compose.ymlTo manage the containers with Docker Compose, position yourself into the
memgraph-platform folder. Most commonly used commands are docker compose start, stop, down and restart. The running containers can be managed with
Docker as well. To learn how to do that, follow the First steps with Docker
guide.
The above installation process is a quick start, but make sure you explore other installation options and choose the preferred way of running Memgraph in your environment.
Connect to the database
You can connect to the Memgraph instance using the command-line interface mgconsole by running the following command in a new terminal:
docker run -it memgraph/mgconsole:latest [--host HOST_IP] [--port PORT]The arguments --host and --port are only required if you’re running Memgraph on a
remote server or different port. Otherwise, they can be omitted.
Alternatively, you can connect to Memgraph using the Memgraph Lab web
application available on localhost:3000 or
as a Desktop app.
Import and query data
As a new user, you’ll want to populate your fresh Memgraph installation with data. The method you choose will largely depend on the format of your data. Memgraph supports imports from various formats, such as CSV, JSON and using queries listed in a CYPHERL file. For detailed instructions on migrating your data, refer to the data migration documentation.
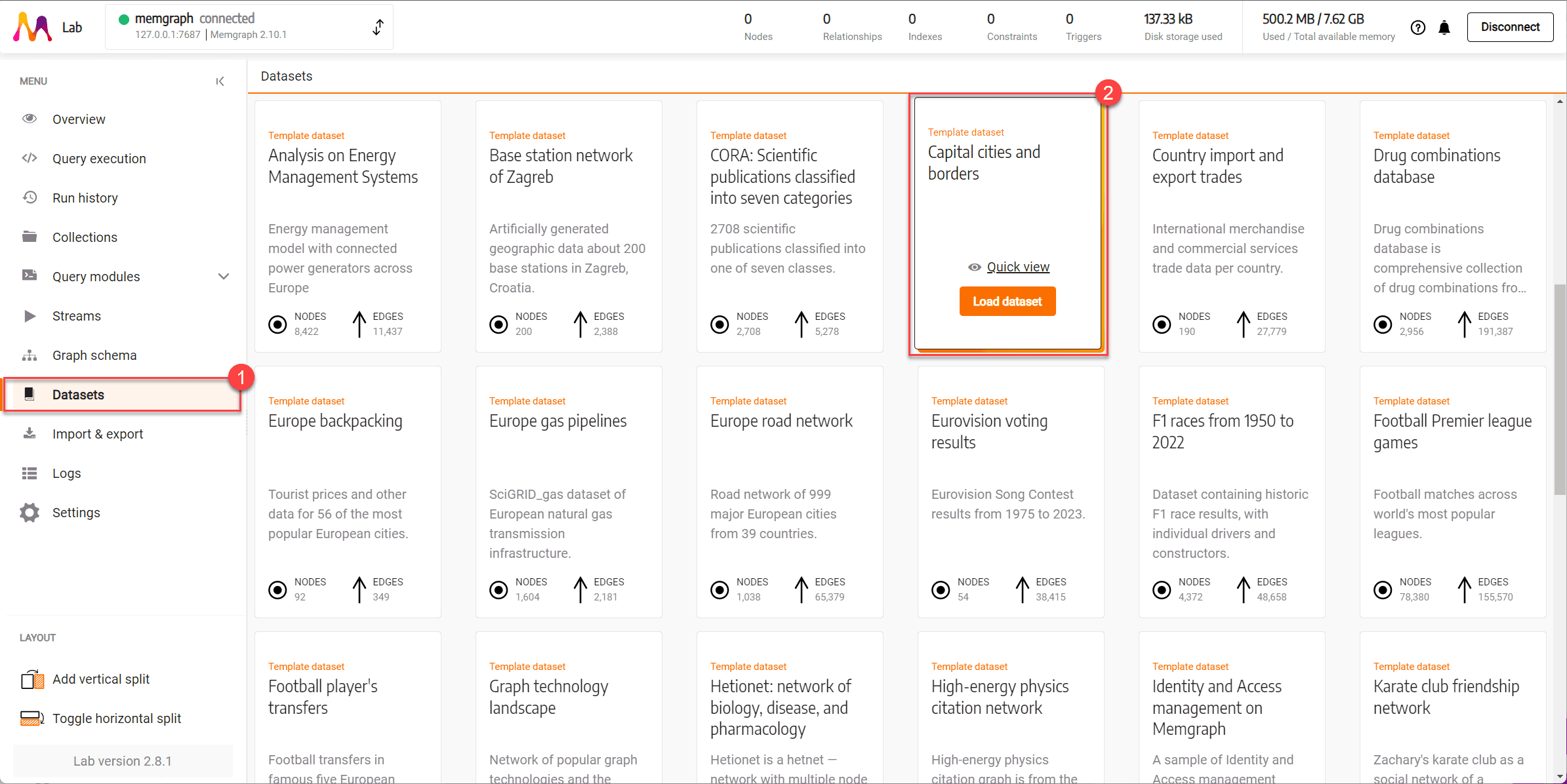
If you’re just getting started and want a quick setup, Memgraph offers a range of pre-made datasets ideal for testing and learning. We have prepared more than 20 datasets you can use for testing and learning. If you wish to use a demo dataset, go to Datasets section, chose a dataset and Load dataset.
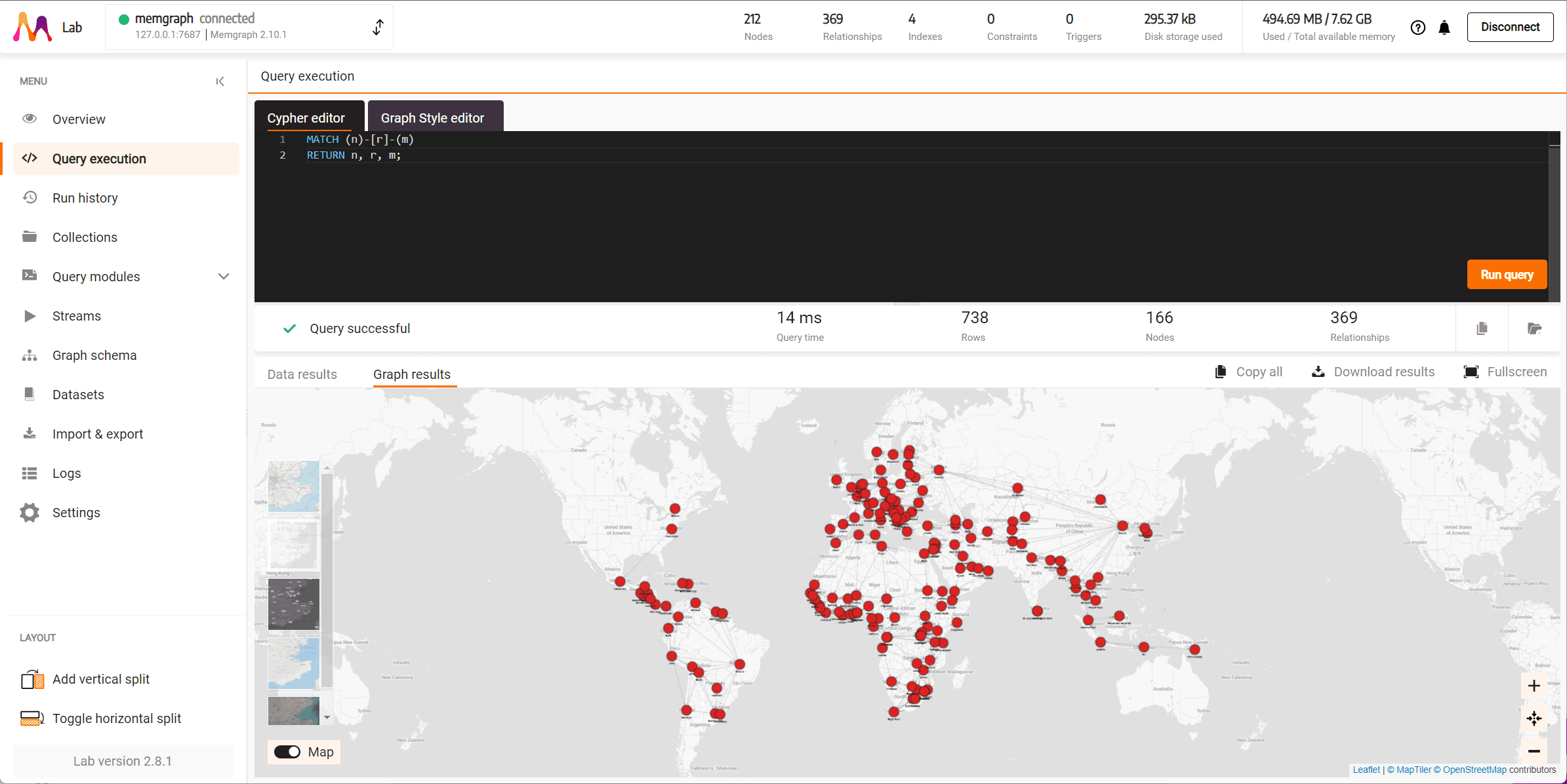
Now that the data is imported it is time to run your first Cypher query. Go to the Query Execution section in the sidebar, and then copy-and-paste the following code into the Cypher editor.
MATCH (n)-[r]-(m)
RETURN n, r, m;
Click Run query to run the above query that will return all the nodes and relationships in the database and see the result in the Graph results tab.
This an example using one of the preloaded datasets:
If you’re transitioning from Neo4j to Memgraph, adapting your existing Cypher queries is essential. While both platforms use the Cypher query language, there might be platform-specific features that require adjustments. To assist you, we provide a comprehensive documentation to help you adapt and optimize your queries for Memgraph.
To start using Memgraph in your application, use one of the following client libraries and follow their getting started guide.
Run advanced algorithms
Memgraph offers a range of procedures tailored to address specific graph problems. Built-in deep path traversal algorithms such as BFS, DFS, Weighted shortest path, All shortest paths, and K shortest paths can be executed using their specific clauses.
Memgraph comes with expanded set of algorithms called Memgraph Advanced Graph Extensions (MAGE) library. MAGE is an open-source repository housing graph algorithms, both by the Memgraph team and the community. These are presented as query modules.
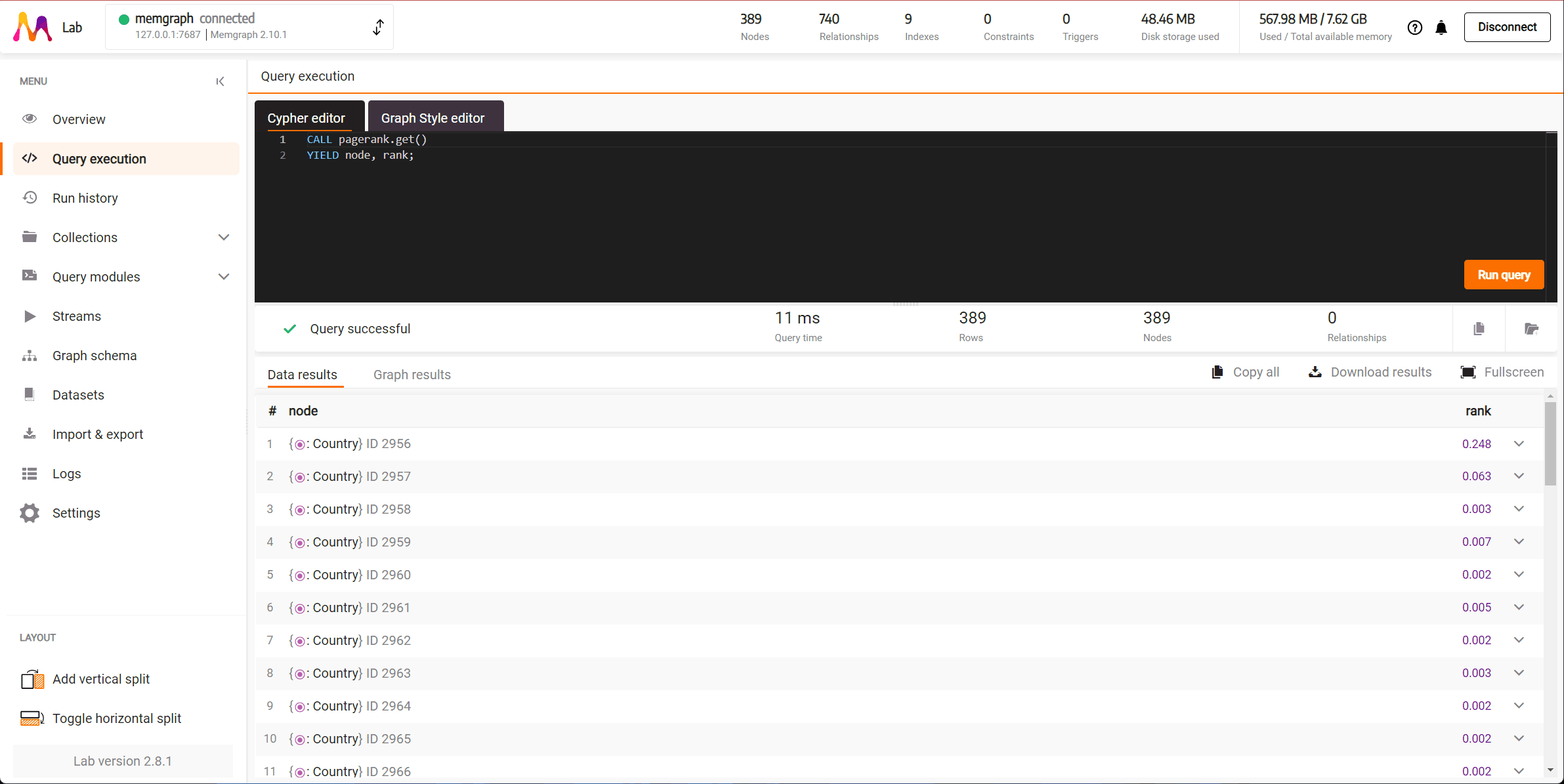
One of the advanced algorithms at your disposal is the PageRank algorithm. You can run it with the following code:
CALL pagerank.get()
YIELD node, rank;