Java client guide
Learn how to create a Java application that connects to the Memgraph database and executes simple queries.
Memgraph currently depends on the Neo4j Java driver. Memgraph and Neo4j both support Bolt protocol and Cypher queries, which means that same driver can be used to connect to both databases. This is very convenient if switching between the two databases is needed. This guide is based on the driver version v5 and above. Some examples may not be supported in older versions of the driver.
Memgraph created the Bolt Java Driver, which can be used to connect to a running Memgraph instance. We still recommend you use the above-mentioned driver.
Quickstart
The following guide will demonstrate how to start Memgraph, connect to Memgraph, seed the database with data, and run simple read and write queries.
Necessary prerequisites that should be installed in your local environment are:
Run Memgraph
If you’re new to Memgraph or you’re in a developing stage, we recommend using the Memgraph Platform. Besides the database, it also includes all the tools you might need to analyze your data, such as command-line interface mgconsole, web interface Memgraph Lab and a complete set of algorithms within a MAGE library.
Ensure Docker is running in the background. Depending on your operating system, execute the appropriate command in the console:
For Linux and macOS:
curl https://install.memgraph.com | shFor Windows:
iwr https://windows.memgraph.com | iexThe command above will start Memgraph Platform, which includes Memgraph database, Memgraph Lab and Memgraph MAGE. Memgraph uses Bolt protocol to communicate with the client using the exposed 7687 port. Memgraph Lab is a web application you can use to visualize the data. It’s accessible at http://localhost:3000 if Memgraph Platform is running correctly. The 7444 port enables Memgraph Lab to access and preview the logs, which is why both of these ports need to be exposed.
For more information visit the getting started guide on how to run Memgraph with Docker.
For Memgraph < 2.11, in order for the Neo4j driver to work, you need modify configuration
setting
--bolt-server-name-for-init. When running Memgraph, set
--bolt-server-name-for-init=Neo4j/5.2.0. If you use other version of Neo4j
driver, make sure to put the appropriate version number.
Open a favorite Java IDE
Start a new empty project in your favorite Java IDE, Eclipse, IntelliJ, VScode or any other. This step will depend on what type of application you are trying to build, but having a bare-bone project with a single Main.java file is enough for this guide.
Add a dependencies for you project
In order to use the Java driver you will need to add dependencies. If you are using Maven, add the following dependencies to your pom.xml file:
<dependencies>
<dependency>
<groupId>org.neo4j.driver</groupId>
<artifactId>neo4j-java-driver</artifactId>
<version>5.11.0</version>
</dependency>
</dependencies>If you are using Gradle, add the following dependencies to your build.gradle file:
dependencies {
implementation 'org.neo4j.driver:neo4j-java-driver:5.11.0'
}Write a minimal working example
Once you have a proper Neo4j dependency, you can start writing your first Java application. Start by adding the following code:
package org.example;
import org.neo4j.driver.*;
import org.neo4j.driver.Record;
import org.neo4j.driver.types.Node;
import java.util.Arrays;
import java.util.List;
public class HelloMemgraph implements AutoCloseable {
// Driiver instance used across the application
private final Driver driver;
// Create a driver instance, and pass the uri, username and password if required
public HelloMemgraph(String uri, String user, String password){
driver = GraphDatabase.driver(uri, AuthTokens.basic(user, password));
}
// Creating indexes
public void createIndexes() {
List<String> indexes = Arrays.asList(
"CREATE INDEX ON :Developer(id);",
"CREATE INDEX ON :Technology(id);",
"CREATE INDEX ON :Developer(name);",
"CREATE INDEX ON :Technology(name);"
);
try (Session session = driver.session()) {
for (String index : indexes) {
session.run(index);
}
}
}
//Create nodes and relationships
public void createNodesAndRealationships() {
List<String> developerNodes = Arrays.asList(
"CREATE (n:Developer {id: 1, name:'Andy'});",
"CREATE (n:Developer {id: 2, name:'John'});",
"CREATE (n:Developer {id: 3, name:'Michael'});"
);
List<String> technologyNodes = Arrays.asList(
"CREATE (n:Technology {id: 1, name:'Memgraph', description: 'Fastest graph DB in the world!', createdAt: timestamp()})",
"CREATE (n:Technology {id: 2, name:'Java', description: 'Java programming language ', createdAt: timestamp()})",
"CREATE (n:Technology {id: 3, name:'Docker', description: 'Docker containerization engine', createdAt: timestamp()})",
"CREATE (n:Technology {id: 4, name:'Kubernetes', description: 'Kubernetes container orchestration engine', createdAt: timestamp()})",
"CREATE (n:Technology {id: 5, name:'Python', description: 'Python programming language', createdAt: timestamp()})"
);
List<String> relationships = Arrays.asList(
"MATCH (a:Developer {id: 1}),(b:Technology {id: 1}) CREATE (a)-[r:LOVES]->(b);",
"MATCH (a:Developer {id: 2}),(b:Technology {id: 3}) CREATE (a)-[r:LOVES]->(b);",
"MATCH (a:Developer {id: 3}),(b:Technology {id: 1}) CREATE (a)-[r:LOVES]->(b);",
"MATCH (a:Developer {id: 1}),(b:Technology {id: 5}) CREATE (a)-[r:LOVES]->(b);",
"MATCH (a:Developer {id: 2}),(b:Technology {id: 2}) CREATE (a)-[r:LOVES]->(b);",
"MATCH (a:Developer {id: 3}),(b:Technology {id: 4}) CREATE (a)-[r:LOVES]->(b);"
);
try (Session session = driver.session()) {
for (String node : developerNodes) {
session.run(node);
}
for (String node : technologyNodes) {
session.run(node);
}
for (String relationship : relationships) {
session.run(relationship);
}
}
}
// Read nodes and return as Record list
public List<Record> readNodes() {
String query = "MATCH (n:Technology{name: 'Memgraph'}) RETURN n;";
try (Session session = driver.session()) {
Result result = session.run(query);
return result.list();
}
}
public static void main(String[] args) {
try (var helloMemgraph = new HelloMemgraph("bolt://localhost:7687", "", "")){
// Create indexes
helloMemgraph.createIndexes();
// Create nodes and relationships
helloMemgraph.createNodesAndRealationships();
// Read nodes
var result = helloMemgraph.readNodes();
// Process results
for (Record node : result) {
Node n = node.get("n").asNode();
System.out.println(n); // Node type
System.out.println(n.asMap()); // Node properties
System.out.println(n.id()); // Node internal ID
System.out.println(n.labels()); // Node labels
System.out.println(n.get("id").asLong()); // Node user defined id property
System.out.println(n.get("name").asString()); // Node user defined name property
System.out.println(n.get("description").asString()); // Node user defined description property
}
}
}This code snippet is a minimal working example that will create a connection to the Memgraph database via Java driver, create indexes, create nodes and relationships, and read the data back. Take a look at the code in detail as it includes the comments to help you understand it. The Java client API usage and examples section will explain the code snippet in more details.
Run the application
Once code is in place, you can run the application. If you are using an IDE, you can run the application from there. If everything is working correctly, you should see the following output:
node<76>
{name=Memgraph, createdAt=1693389566657284, description=Fastest graph DB in the world!, id=1}
76
[Technology]
1
Memgraph
Fastest graph DB in the world!Visualize the data
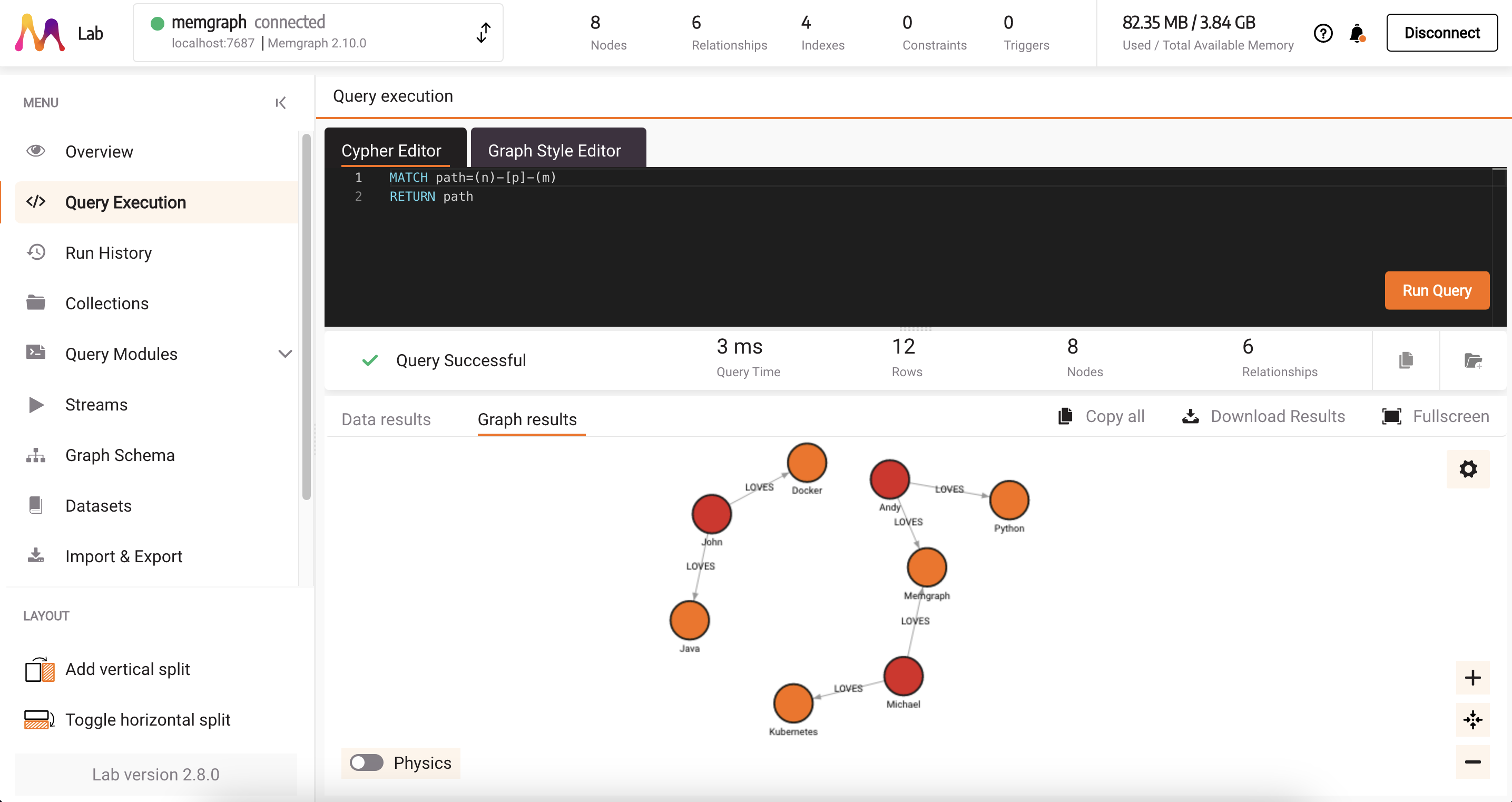
To visualize objects created in the database with the code snippet above, head over to http://localhost:3000/ and run MATCH path=(n)-[p]-(m) RETURN path in the Query Execution tab.
The query will visualize the created nodes and relationships. By clicking on a node or relationship, you can explore different properties.
Next steps
You can continue building your Java applications. For more information on how to use the Java driver, continue reading about Java client API usage and examples.
Java client API usage and examples
After a brief Quickstart guide, this section will go into more detail on how to use the Java driver API, explain code snippets, and provide more examples. Feel free to skip to the section that interests you the most.
Database connection
Once the database is running and the driver is installed or available in Java, you should be able to connect to the database in one of two ways::
Connect without authentication (default)
By default, the Memgraph database is running without authentication, which means that you can connect to the database without providing any credentials (username and password).
To connect to Memgraph, create a driver object with the appropriate URI and credentials arguments. If you’re running Memgraph locally, the URI should be similar to bolt://localhost:7687, and if you are running Memgraph on a remote server,
replace localhost with the appropriate IP address.
If you ran Memgraph on a port different than 7687, do not forget to update that in the URI too.
By default, you can set the username and password in the AuthTokens.basic("", "") argument as empty strings. This means that you are connecting without authentication.
To connect a Java driver to the Memgraph database, you can use the following snippet:
import org.neo4j.driver.AuthTokens;
import org.neo4j.driver.Driver;
import org.neo4j.driver.GraphDatabase;
public class HelloMemgraph implements AutoCloseable {
private final Driver driver;
public HelloMemgraph(String uri, String user, String password) {
driver = GraphDatabase.driver(uri, AuthTokens.basic(user, password));
}
@Override
public void close() throws RuntimeException {
driver.close();
}
public static void main(String[] args) {
try (var helloMemgraph = new HelloMemgraph("bolt://localhost:7687", "", "")) {
// Use the driver
}
}
}Notice that AuthTokens.basic takes two arguments, the first is username and the second is password.
For both username and password, you can pass an empty string, this means that you are connecting without authentication.
Connect with authentication
In order to set up authentication in Memgraph, you need to create a user with a username and password. In Memgraph you can set a username and password by executing the following query:
CREATE USER `memgraph` IDENTIFIED BY 'memgraph';Then, you can connect to the database with the following snippet:
import org.neo4j.driver.AuthTokens;
import org.neo4j.driver.Driver;
import org.neo4j.driver.GraphDatabase;
public class HelloMemgraph implements AutoCloseable {
private final Driver driver;
public HelloMemgraph(String uri, String user, String password) {
driver = GraphDatabase.driver(uri, AuthTokens.basic(user, password));
}
@Override
public void close() throws RuntimeException {
driver.close();
}
public static void main(String[] args) {
String uri = "bolt://localhost:7687";
String username = "memgraph";
String password = "memgraph";
try (var helloMemgraph = new HelloMemgraph(uri, username, password)) {
// Use the driver
}
}
}You may receive this error:
Exception in thread "main" org.neo4j.driver.exceptions.SecurityException: Authentication failure
The error indicates that you have probably enabled authentication in Memgraph, but are trying to connect without authentication. For more details on how to set authentication further, visit the Memgraph authentication guide.
Java client connection lifecycle management
Once the driver connection to Memgraph is established, it doesn’t need to be closed. It’s sufficient to open a single client connection to Memgraph and use it for all queries. Once the client connection is open, the lifecycle can be managed using the Java AutoCloseable interface. The client’s lifetime is tied to the application lifecycle.
The following implementation of AutoCloseable interface will make sure to close the client connection once the application is finished:
@Override
public void close() throws RuntimeException {
driver.close();
}Keep in mind that the driver object is thread-safe and can be reused between different threads.
Query the database
After connecting your driver to Memgraph you can start running queries. The simplest way to run the query is via writeTransaction() and readTransaction() methods.
Run a write query
The following query will create a node inside the database:
public void createNode() {
try (Session session = driver.session(SessionConfig.forDatabase("memgraph"))) {
session.writeTransaction(tx -> {
tx.run("CREATE (n:Technology {name:'Memgraph'})");
return null;
});
}
}The session object takes a SessionConfig object as its argument. The SessionConfig object is used to specify the database name and other session configuration options. Session API supports writeTransaction() and readTransaction() methods.
The writeTransaction() method takes a TransactionWork functional interface as its argument. The TransactionWork interface has a single method execute(), which takes a Transaction object tx as its argument and returns a value of generic type T, void in this case.
As of Memgraph version 3.2, queries are categorized as read or write and the corresponding storage access is taken. This allows for better query parallelization and higher throughput.
Using writeTransaction informs Memgraph that the transaction will be modifying data. See transaction accessor misalignment for more details.
Run a read query
Similar to the write query, readTranasction() method can be used to run read queries. The difference is that read will return the results of the query.
The following query will read data from the database:
public void readNode() {
try (Session session = driver.session(SessionConfig.forDatabase("memgraph"))) {
List<Record> result = session.readTransaction(tx -> {
Result queryResult = tx.run("MATCH (n:Technology{name: 'Memgraph'}) RETURN n");
List<Record> records = queryResult.list();
return records;
});
System.out.println(result);
// Print each node as map
for (Record record : result) {
System.out.println(record.get("n").asMap());
}
}
}In the above query, each Record contains a Node accessible by the asMap() method.
As of Memgraph version 3.2, queries are categorized as read or write and the corresponding storage access is taken. This allows for better query parallelization and higher throughput. An exception will be thrown if the user tries to execute a write query inside a read transaction. See transaction accessor misalignment for more details.
Running queries with property map
If you want to pass a property map to the query, you can do it like this:
public void createNodeWithProperties() {
try (Session session = driver.session(SessionConfig.forDatabase("memgraph"))) {
Map< String, Object > properties = new HashMap<>();
properties.put("name", "Memgraph");
properties.put("type", "graph database");
session.writeTransaction(tx -> {
tx.run("CREATE (n:Technology {name: $name, type: $type})", properties);
return null;
});
}
}Using this approach, the queries will not contain hard-coded values, they can be more dynamic.
Process the results
In order to serve the read results back to the Java application, their types need to be handled properly because Java is a statically typed language. Depending on the type of request made, you can receive different results. Let’s go over a few basic examples of how to handle different types and access properties of the returned results.
Process the Node results
Run the following query:
public List<Record> readNodes() {
String query = "MATCH (n:Technology {name: 'Memgraph'}) RETURN n;";
try (Session session = driver.session()) {
Result result = session.run(query);
return result.list();
}
}Records field contains all the records returned by the query. To process the results, you can iterate over the records and access the fields you need.
Here is an example:
for (Record record : result) {
System.out.println(record.get("n").asMap());
}{name=Memgraph, createdAt=1693389566657284, description=Fastest graph DB in the world!, id=1}In the example above, each returned Record is converted into a map. From the map, you can access the n field, which is a Node returned from a query. The returned record and all its properties are of type any. This means you must cast them to the relevant Java type if you want to use methods or features defined on such types.
You can access individual properties of the Node using one of the following options:
Node n = node.get("n").asNode();
System.out.println(n); // node<65>
System.out.println(n.asMap()); // {name=Memgraph, createdAt=1693400712958077, description=Fastest graph DB in the world!, id=1}
System.out.println(n.id()); // 65
System.out.println(n.labels()); // [Technology]
System.out.println(n.get("id").asLong()); // 1
System.out.println(n.get("name").asString()); // Memgraph
System.out.println(n.get("description").asString()); // Fastest graph DB in the world!You can access all Node properties by casting and accessing Node. Keep in mind that the id() returns the internal ID of the node, which is not the same as the user-defined ID, and it should not
be used for any application-level logic.
Processing Relationship results
You can also receive a Relationship from the query. For example:
//Create relationship
public void createRelationship() {
String query = "CREATE (d:Developer {name: 'John Doe'})-[:LOVES {id:99}]->(t:Technology {id: 1, name:'Memgraph', description: 'Fastest graph DB in the world!', createdAt: date()})";
try (Session session = driver.session(SessionConfig.forDatabase("memgraph"))) {
session.writeTransaction(tx -> {
tx.run(query);
return null;
});
}
}
//Read relationship
public List<Record> readRelationship() {
String query = "MATCH (d:Developer)-[r:LOVES]->(t:Technology) RETURN r";
try (Session session = driver.session(SessionConfig.forDatabase("memgraph"))) {
List<Record> result = session.readTransaction(tx -> {
Result queryResult = tx.run(query);
List<Record> records = queryResult.list();
return records;
});
return result;
}
}
//Process results
for (Record rel : records) {
Relationship relationship = rel.get("r").asRelationship();
System.out.println(relationship);
System.out.println(relationship.asMap());
System.out.println(relationship.id());
System.out.println(relationship.type());
System.out.println(relationship.startNodeId());
System.out.println(relationship.endNodeId());
System.out.println(relationship.get("id").asLong());
}You can access Relationship properties in the same way as you access the Node properties. ID values from startNodeId() and endNodeId() methods are the internal IDs of the start and end node of the relationship. Do not use them in your application logic.
Processing Path results
You can receive Path from the database, using the following construct:
public List<Record> readPath() {
String query = "MATCH path=(d:Developer)-[r:LOVES]->(t:Technology) RETURN path";
try (Session session = driver.session(SessionConfig.forDatabase("memgraph"))) {
List<Record> result = session.readTransaction(tx -> {
Result queryResult = tx.run(query);
List<Record> records = queryResult.list();
return records;
});
return result;
}
}
for (Record path : path_records) {
Path p = path.get("path").asPath();
System.out.println(p);
System.out.println(p.start());
System.out.println(p.end());
System.out.println(p.length());
System.out.println(p.nodes());
System.out.println(p.relationships());
}Path will contain Nodes and [Relationships[#process-the-relationship-result], that can be accessed in the same way as in the previous examples, by casting them to the relevant type.
Types mapping Cypher and Java
Here is the full table of the mapping between Memgraph Cypher types and the types used in the Java driver:
| Cypher Type | Driver Type |
|---|---|
| Null | null |
| String | String |
| Boolean | boolean |
| Integer | long |
| Float | double |
| List | List(Object) |
| Map | Map < String, Object > |
| Node | Node |
| Relationship | Relationship |
| Path | Path |
| Duration | IsoDuration |
| Date | LocalDate |
| LocalTime | LocalTime |
| LocalDateTime | LocalDateTime |
Keep in mind that, at the moment, Memgraph does not support Timezones, ByteArray and Point.
Transaction management
Transaction is a unit of work that is executed on the database, it could be some basic read, write or complex set of steps in form of series of queries. There can be multiple ways to mange transaction, but usually, they are managed automatically by the driver or manually by the explicit code steps. Transaction management defines how to handle the transaction, when to commit, rollback, or terminate it.
On the driver side, if a transaction fails because of a transient error, the transaction is retried automatically. The transient error will occur during write conflicts or network failures. The driver will retry the transaction function with an exponentially increasing delay.
Simple transaction management
Simple transaction management provides a standard blocking style API for Cypher execution. It also provides the most straightforward programming style to work with since API calls are executed strictly sequentially.
Session management
Before doing any transaction management, you need to create a session. A session is a specific connection to the database that can live for a certain period. The session connection is lightweight and should be closed after the wanted queries have been executed instead of keeping it open for the whole duration of the application. To open a session, use the code snippet below:
try (Session session = driver.session(...)) {
// transactions go here
}The Java “try-with-resources” statement will automatically close the session once the code block is finished. Sessions are not thread-safe, so you should create a new session for each thread.
You can use the following transaction management methods with sessions:
writeTransaction- executes a managed explicit transaction workload in write access mode with retry logic.readTransaction- executes a managed explicit transaction workload in read access mode with retry logic.run- executes a implicit auto-commit transaction and returns result.
Error with multicommand transactions
If you experience Index manipulation not allowed in multicommand transactions error, use implicit (or auto-commit) transactions instead.
Managed transactions
Let’s look at the basic example of reading data from the database.
Run a simple transaction using the writeTransaction:
public void createNode() {
try (Session session = driver.session(SessionConfig.forDatabase("memgraph"))) {
session.writeTransaction(tx -> {
tx.run("CREATE (n:Technology {name:'Memgraph'})");
tx.run("CREATE (n:Technology {name:'Java'})");
//Some other queries
return null;
});
}
}All the previous examples from this guide have used simple transaction management. It allows you to run multiple queries in a single transaction and have control over the transaction. You could have multiple logic blocks in the transaction, rollback or end the transaction if needed. Also, managed transactions have a retry logic, which means that if the transaction fails, it will be retried. Managed transactions are the most flexible way to run a Cypher query.
As of Memgraph version 3.2, queries are categorized as read or write and the corresponding storage access is taken. This allows for better query parallelization and higher throughput.
Using writeTransaction and readTransaction informs Memgraph what type of access is required for the transaction.
An exception will be thrown if the user tries to execute a write query inside a read transaction. See transaction accessor misalignment for more details.
Implicit transactions
Implicit auto-commit queries are the simplest way to run a Cypher query since they aren’t automatically retried like writeTransaction and readTransaction are.
With implicit auto-commit transactions, you don’t have the same control of transactions as with managed explicit transactions.
As of Memgraph version 3.2, queries are categorized as read or write and the corresponding storage access is taken. This allows for better query parallelization and higher throughput. For single query implicit transaction, no user input is required, Memgraph will deduce the access type needed at parse-time. See transaction accessor misalignment for more details.
Here is an example of an implicit transaction:
public void createNode() {
try (Session session = driver.session(SessionConfig.forDatabase("memgraph"))) {
session.run("CREATE (n:Technology {name:'Memgraph'})");
}
}The above code runs a simple query without any transaction management. It simplifies the experience, but you lose flexibility when running queries. Since explicit transactions are multi-statement transactions, creating an index, constraints or auth config queries is not possible in multi-line transactions. Therefore, you need to use implicit transactions for those queries.
Asynchronous transaction management
Asynchronous transactions management provides an API to work with Futures in transactions. The Future class represents a future result of an asynchronous computation in Java. This result will eventually appear in the Future after the processing is complete. This allows client applications to work within asynchronous code bases while managing transactions.
Session management
Asynchronous sessions provide an API to work with Futures. Asynchronous sessions are not thread-safe, so you should create a new session for each thread.
Session lifetime begins with session construction, and the session is typically closed automatically when all results are consumed.
The session is opened using the following code snippet:
var session = driver.session(AsyncSession.class);You can use the following transaction management methods via async session API:
writeTransactionAsync- executes a managed transaction workload in write access mode with retry logic.readTransactionAsync- executes a managed transaction workload in read access mode with retry logic.runAsync- executes a implicit auto-commit transaction and returns result.
Managed transactions
As of Memgraph version 3.2, queries are categorized as read or write and the corresponding storage access is taken. This allows for better query parallelization and higher throughput.
Using executeReadAsync and executeWriteAsync informs Memgraph what type of access is required for the transaction.
An exception will be thrown if the user tries to execute a write query inside a read transaction. See transaction accessor misalignment for more details.
Here is a basic example of reading data from the database via Async session API:
public CompletionStage<ResultSummary> readNodesAsync() {
String query = "MATCH (n:Technology {name: 'Memgraph'}) RETURN n;";
var session = driver.session(AsyncSession.class);
return session.executeReadAsync(tx -> tx.runAsync(query)
.thenCompose(cursor -> cursor.forEachAsync(record ->
// asynchronously print every record
System.out.println(record.get(0).asString()))));
}Implicit auto-commit asynchronous transactions
Implicit auto-commit queries are the simplest way to run a Cypher query since they aren’t automatically retried like writeTransactionAsync and readTransactionAsync are.
As of Memgraph version 3.2, queries are categorized as read or write and the corresponding storage access is taken. This allows for better query parallelization and higher throughput. For single query implicit transaction, no user input is required, Memgraph will deduce the access type needed at parse-time. See transaction accessor misalignment for more details.
Here is an example of an implicit transaction:
public CompletionStage<ResultSummary> createNodeAsync() {
String query = "CREATE (n:Technology {name:'Memgraph'})";
var session = driver.session(AsyncSession.class);
return session.runAsync(query)
.thenCompose(ResultCursor::consumeAsync)
.whenComplete((resultSummary, error) -> session.closeAsync());
}If you encounter serialization errors while using Java client, we recommend referring to our Serialization errors page for detailed guidance on troubleshooting and best practices.