Storage memory usage
Memgraph’s architecture has been built natively for in-memory data analysis and storage. Being ACID compliant, it ensures consistency and reliability in its core design. However, Memgraph also offers flexibility with it’s other storage modes.
Storage modes
Memgraph supports three different storage modes:
IN_MEMORY_TRANSACTIONAL- the default database storage mode that favors strongly-consistent ACID transactions using WAL files and snapshots, but requires more time and resources during data import and analysis.IN_MEMORY_ANALYTICAL- speeds up import and data analysis but offers no ACID guarantees besides manually created snapshots.ON_DISK_TRANSACTIONAL- supports ACID properties in the same way asIN_MEMORY_TRANSACTIONALwith the additional ability to store data on disk (HDD or SSD), thus trading performance for lower costs.
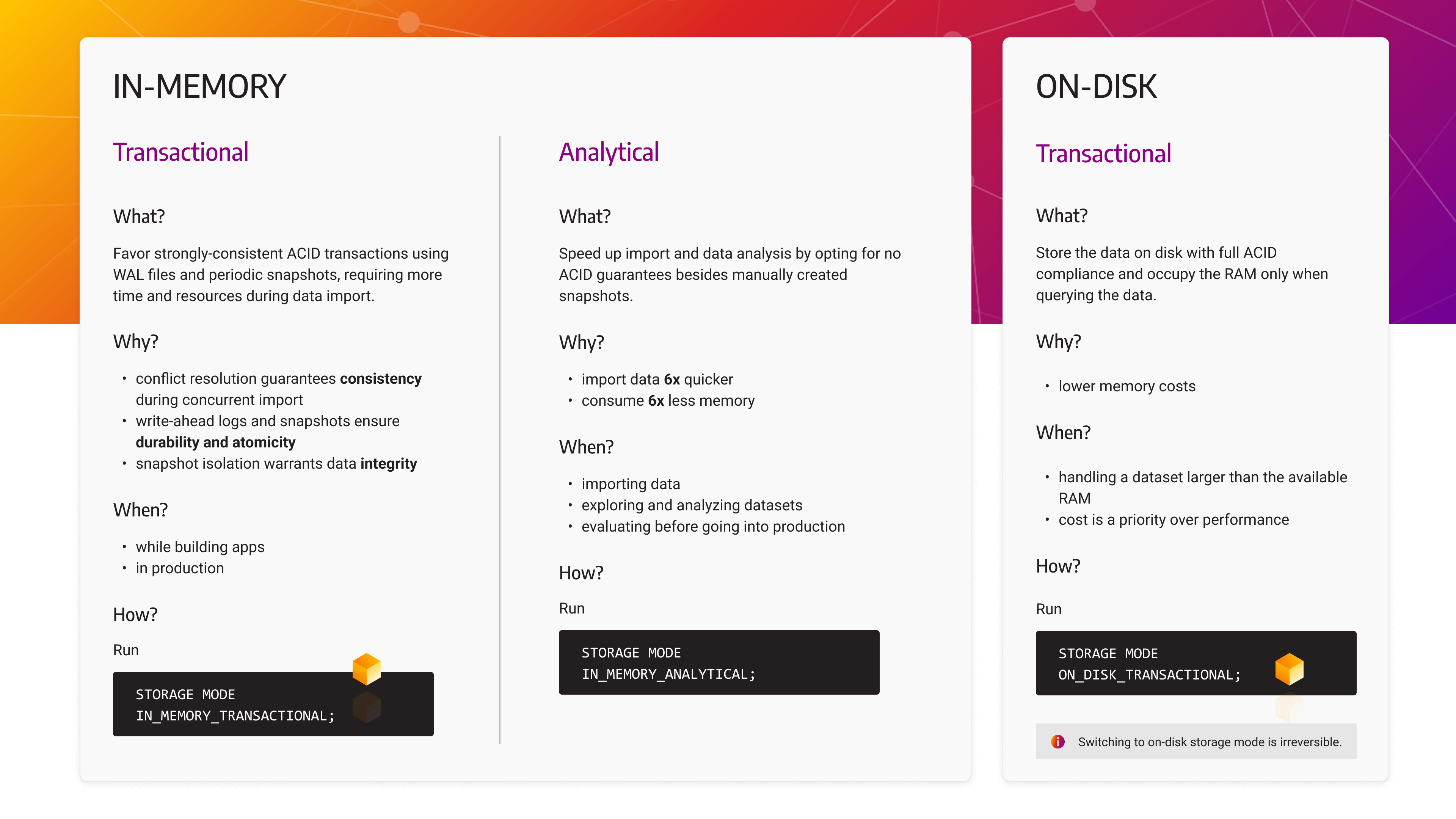
Start Memgraph with a specific storage mode
By default, an empty instance will start using in-memory transactional storage
mode.
To start Memgraph in the ON_DISK_TRANSACTIONAL or IN_MEMORY_ANALYTICAL
storage node, change the --storage-mode configuration
flag accordingly.
Switch storage modes
You can switch between in-memory modes within a session using the following query:
STORAGE MODE IN_MEMORY_TRANSACTIONAL;STORAGE MODE IN_MEMORY_ANALYTICAL;You cannot switch from an in-memory storage mode to an on-disk storage mode when the database contains data. It is also impossible to start Memgraph in one storage mode and to load a snapshot image that was created with another storage mode.
When switching modes, Memgraph will wait until all other transactions are done.
If some other transactions are running in your system, you will receive a
warning message, so be sure to set the log level at least to
WARNING.
Switching from the in-memory storage mode to the on-disk storage mode is allowed
when there is only one active session and the database is empty. As Memgraph Lab
uses multiple sessions to run queries in parallel, it is currently impossible to
switch to the on-disk storage mode within Memgraph Lab. You can change the
storage mode to on-disk transactional using mgconsole, then connect to the
instance with Memgraph Lab and query the instance as usual.
To change the storage mode to ON_DISK_TRANSACTIONAL, use the following query:
STORAGE MODE ON_DISK_TRANSACTIONAL;It is forbidden to change the storage mode from ON_DISK_TRANSACTIONAL to any
of the in-memory storage modes while there is data in the database as it might
not fit into the RAM. To change the storage mode to any of the in-memory
storages, empty the instance and restart it. An empty database will start in the
default storage mode (in-memory transactional) or the storage mode defined by
the --storage-mode configuration
flag.
If you are running the Memgraph Enterprise Edition, you need to have
STORAGE_MODE permission to change the storage
mode.
By default, an empty instance will start using in-memory transactional storage
mode. Non-empty database using in-memory transactional or analytical storage
mode will restart in transactional storage mode. This behavior can be changed
using the --storage-mode configuration
flag. But, regardless of what the flag
is set to, a non-empty instance in the on-disk storage mode cannot change
storage mode even upon restart.
Check storage mode
You can check the current (runtime) storage mode of the database you are
connected to using the following query and reading the storage_mode field:
SHOW STORAGE INFO ON CURRENT DATABASE;The unscoped SHOW STORAGE INFO only reports global_storage_mode, which is the
startup-default storage mode (the --storage-mode
flag) and does not reflect runtime STORAGE MODE … changes.
In-memory transactional storage mode (default)
IN_MEMORY_TRANSACTIONAL storage mode offers all ACID guarantees. WAL files and
periodic snapshots are created automatically, and you can also create snapshots
manually.
In the IN_MEMORY_TRANSACTIONAL mode, Memgraph creates a
Delta object each time data is changed. Deltas are the
backbone upon which Memgraph provides atomicity, consistency, isolation, and
durability - ACID. By using Deltas, Memgraph creates
write-ahead-logs
for durability, provides isolation, consistency, and atomicity (by ensuring that
everything is executed or nothing is).
Depending on the transaction isolation level, other transactions may see changes from other transactions.
In the transactional storage mode,
snapshots are created
periodically or manually. They capture the database state and store it on the
disk. A snapshot is used to recover the database upon startup (depending on the
setting of the configuration flag
--data-recovery-on-startup,
which defaults to true).
When Memgraph starts creating a periodic snapshot, it is not possible to manually create a snapshot, until the periodic snapshot is created. Snapshot creation requires a transactional view. This can lead to spikes in memory consumption when data is being ingested in parallel to snapshot creation. It is possible to pause the periodic snapshot background job at run-time. This can speed up ingestion time and lower memory usage.
Manual snapshots are created by running the CREATE SNAPSHOT; query.
In-memory analytical storage mode
In the transactional storage mode, Memgraph is fully ACID
compliant which could cause memory
spikes during data import because each time data is changed Memgraph creates
Delta objects to provides atomicity, consistency, isolation, and durability.
But Deltas also require memory (56B per change), especially when
there are a lot of changes (for example, during import with the LOAD CSV
clause). By switching the storage mode to IN_MEMORY_ANALYTICAL mode disables
the creation of Deltas thus drastically speeding up import with lower memory
consumption - up to 6 times faster import and less memory consumption.
As Deltas are the foundation for ACID properties, they provide information on what has changed
in different concurrent transactions. They also cause conflicts between transactions
when multiple transactions change the same graph object. A typical scenario would be adding
a relationship to the same node or adding a property to the same node. In the analytical storage mode,
Memgraph does not create Deltas, and therefore, there won’t be any conflicts between transactions.
Adding relationships is thread-safe, which means that multiple transactions can add relationships to the same node without any conflicts.
That leads to a very efficient import process in scenarios with a dense graph and supernode.
If you want to enable ACID compliance, you can switch back to
IN_MEMORY_TRANSACTIONAL and continue with regular work on the database or you
can take advantage of the low memory costs of the analytical mode to run
analytical queries that will not change the data, but be aware that no backup is
created automatically, and there are no ACID guarantees besides manually created
snapshots. There are no WAL files created nor periodic snapshots. Users
can create a snapshot manually.
Implications
In the analytical storage mode, there are no ACID guarantees and other transactions can see the changes of ongoing transactions. Also, a transaction can see the changes it is doing. This means that the transactions can be committed in random orders, and the updates to the data, in the end, might not be correct.
In the practical sense, not having ACID properties leads to the following implications:
- Atomicity - if your write transaction fails for any reason, the changes are not rolled back.
- Consistency - database consistency is not guaranteed as transactions may fail and leave the database in an inconsistent state.
- Isolation - if you have a long-running write transaction, other transactions can see the changes of ongoing transactions even if changes are not committed.
- Durability - Memgraph does not create WAL files and periodic snapshots in the analytical storage mode. They need to be created manually.
The absence of isolation guarantees also implies that changes by parallel transactions may affect the correctness of query procedures that read from the graph. The most critical case is that of the procedure returning a graph element (node or relationship), or a container type holding those. If the returned graph element has been deleted by a parallel transaction, the built-in behavior is as follows:
- procedures: skip all records that contain any deleted value
- functions: return a null value
Please note that deleting same part of the graph from parallel transaction will lead to undefined behavior.
Users developing custom query procedures and functions intended to work in the analytical storage mode should use API methods to check if Memgraph is running in a transactional (ACID-compliant) storage mode. If not, the query module APIs let you check whether graph elements (nodes and relationships) are deleted, and whether containers (maps, lists and paths) that may hold graph elements don’t contain any deleted values.
Memgraph uses snapshots
and write-ahead
logs to ensure
data durability and backup. Snapshots capture the database state and store it on
the disk. A snapshot is then used to recover the database upon startup (depending on
the setting of the configuration
flag
--data-recovery-on-startup, which defaults to true).
In Memgraph, snapshots are created periodically or manually with CREATE SNAPSHOT; Cypher query.
In the analytical storage mode, WAL files and periodic snapshots are not created.
Before switching back to the in-memory transactional storage mode create a snapshot manually. In the in-memory analytical storage mode, Memgraph guarantees that creating a snapshot is the only transaction present in the system, and all the other transactions will wait until the snapshot is created to ensure its validity. Once Memgraph switches to the in-memory transactional mode, it will restore data from the snapshot file and create a WAL for all new updates, if not otherwise instructed by the config file.
These are some of the implications of not having ACID properties. But if you do not have write-heavy workload, and you want to run analytical queries that will not change the data, you can take advantage of the low memory costs of the analytical mode.
At the moment, the in-memory analytical storage mode doesn’t support replication and high availability.
On-disk transactional storage mode
The on-disk transactional storage mode is still in the experimental phase. We recommend our users use in-memory storage modes whenever possible. If you try out on-disk transactional storage mode and encounter an issue, please open it on our GitHub repository. In case your data is larger than your RAM can handle, and you can’t continue with the in-memory storage modes, don’t hesitate to reach out to us and schedule an office hours call so we can advise you and help you. Our goal is to improve the on-disk transactional storage mode in the future, so any feedback would be greatly appreciated.
In the on-disk transactional storage mode, disk is used as a physical storage which allows you to save more data than the capacity of your RAM. This helps keep the hardware costs to a minimum, but you should except slower performance when compared to the in-memory transactional storage mode. Keep in mind that while executing queries, all the graph objects used in the transactions still need to be able to fit in the RAM, or Memgraph will throw an exception.
Memgraph uses RocksDB as a background storage to serialize nodes and relationships into a key-value format. The used architecture is also known as “larger than memory” as it enables in-memory databases to save more data than the main memory can hold, without the performance overhead caused by the buffer pool.
The imported data is residing on the disk, while the main memory contains two
caches, one executing operations on main RocksDB instance and the other for
operations that require indexes. In both cases, Memgraph’s custom
SkipList cache is used, which allows a multithreaded read-write access pattern.
Implications
Concurrent execution of transactions is supported differently for on-disk
storage than for in-memory. The in-memory storage mode relies on
Delta objects which store the exact versions of data
at the specific moment in time. Therefore, the in-memory storage mode uses a
pessimistic approach and immediately checks whether there is a conflict between
two transactions.
In the on-disk storage mode, the cache is used per transaction. This significantly simplifies object management since there is no need to question certain object’s validity, but it also requires the optimistic approach for conflict resolution between transactions.
In the on-disk storage mode, the conflict is checked at the transaction’s commit time with the help of RocksDB’s transaction support. This also implies that Deltas are cleared after each transaction, which can optimize memory usage during execution. Deltas are still used to fully support Cypher’s semantic of the write queries. The design of the on-disk storage also simplifies the process of garbage collection, since all the data is on disk.
The on-disk storage mode supports only snapshot isolation level. Mostly because it’s the Memgraph viewpoint that snapshot isolation should be the default isolation level for most applications relying on databases. But the snapshot isolation level also simplifies the query’s execution flow since no data is transferred to the disk until the commit of the transaction.
Label and label-property indexes are stored in separate RocksDB instances as key-value pairs so that the access to the data is faster. Whenever the indexed node is accessed, it’s stored into a separate in-memory cache to maximize the reading speed.
When it comes to constraints, the existence constraints don’t use context from the disk since the validity of nodes can be checked by looking only at this single node. On the other side, uniqueness constraints require a different approach. For a node to be valid, the engine needs to iterate through all other nodes under constraint and check whether a conflict exists. To speed up this iteration process, nodes under constraint are stored into a separate RocksDB instance to eliminate the cost of iterating over nodes which are not under constraint.
In the on-disk storage mode, durability is supported by RocksDB since it keeps its own WAL files. Memgraph persists the metadata used in the implementation of the on-disk storage.
If the workload is larger than memory, a single transaction must fit into the memory. A memory tracker tracks all allocations happening throughout the transaction’s lifetime. Disk space also has to be carefully managed. Since the timestamp is serialized together with the raw node and relationship data, the engine needs to ensure that when the new version of the same node is stored, the old one is deleted.
At the moment, the on-disk storage doesn’t support replication and high availability.
Data formats
Below is the format in which data is serialized to the disk.
Vertex format for main disk storage:
Key - label1, label2, ... | vertex gid | commit_timestamp
Value - properties
Edge format for the main disk storage:
Key - edge gid
Value - src_vertex_gid | dst_vertex_gid | edge_type | properties
To achieve fast expansions, we also store connectivity index for outcoming and incoming edges on disk:
Outcoming connectivity index:
Key - src_vertex_gid
Value - out_edge_gid1, out_edge_gid2, ...
Incoming connectivity index:
Key - dst_vertex_gid
Value - in_edge_gid1, in_edge_gid2, ...
Format for label index on disk:
Key - indexing label | vertex gid | commit_timestamp
Value - label1_id, label2_id, ... | properties
Value does not contain indexing label.
Format for label-property index on disk:
Key - indexing label | indexing property | vertex gid | commit_timestamp
Value - label1_id, label2_id, ... | properties
Value does not contain indexing label.
Edge import mode
Memgraph on-disk storage supports the EDGE IMPORT MODE to import relationships
with high throughput. When the database is in this mode, only relationships can
be created and modified. Any operation on nodes other than read are prohibited
and will throw an exception.
To enable the mode run:
EDGE IMPORT MODE ACTIVE;To disable the mode run:
EDGE IMPORT MODE INACTIVE;Import data using `LOAD CSV` clause
When importing data using a CSV file, import nodes and relationships separately. Currently, to import relationships as fast as possible, don’t create indexes.
Here is an example how to import data using the LOAD CSV clause.
First, import the nodes:
LOAD CSV FROM "/path-to/people_nodes.csv" WITH HEADER AS row
CREATE (p:Person {id: row.id, name: row.name});Activate the EDGE IMPORT MODE:
EDGE IMPORT MODE ACTIVE;Import the relationships:
LOAD CSV FROM "/path-to/people_relationships.csv" WITH HEADER AS row
MATCH (p1:Person {id: row.id_from}), (p2:Person {id: row.id_to})
CREATE (p1)-[:IS_FRIENDS_WITH]->(p2);Deactivate the EDGE IMPORT MODE:
EDGE IMPORT MODE INACTIVE;Import data using Cypher queries
For files containing Cypher queries (.cypherql),
create all nodes, then activate the EDGE IMPORT MODE and create relationships.
Indexes can be created before or after activating the EDGE IMPORT MODE. It’s
best to create a label-property index on node
properties used to match nodes that will be connected with a relationship.
Here as an exampe of a CYPHERL file:
CREATE (n:User {id: 1});
CREATE (n:User {id: 2});
CREATE (n:User {id: 3});
CREATE (n:User {id: 4});
EDGE IMPORT MODE ACTIVE;
CREATE INDEX ON :User(id);
MATCH (n:User {id: 1}), (m:User {id: 2}) CREATE (n)-[r:FRIENDS {id: 1}]->(m);
MATCH (n:User {id: 3}), (m:User {id: 4}) CREATE (n)-[r:FRIENDS {id: 2}]->(m);
EDGE IMPORT MODE INACTIVE;Calculate storage memory usage
Estimating Memgraph’s storage memory usage is not entirely straightforward because it depends on a lot of variables, but it is possible to do so quite accurately.
If you want to estimate memory usage in IN_MEMORY_TRANSACTIONAL storage mode, use the following formula:
You can also use the Storage memory calculator.
Let’s test this formula on the Marvel Comic Universe Social Network dataset, which is also available as a dataset inside Memgraph Lab and contains 21,723 vertices and 682,943 edges.
According to the formula, storage memory usage should be:
Now, let’s run an empty Memgraph instance on a x86 Ubuntu. It consumes ~75MB
of RAM due to baseline runtime overhead. Once the dataset is loaded, RAM usage
rises up to ~260MB. Memory usage primarily consists of storage and query
execution memory usage. After executing FREE MEMORY query to force the cleanup
of query execution, the RAM usage drops to ~200MB. If the baseline runtime
overhead of 75MB is subtracted from the total memory usage of the dataset,
which is 200MB, and storage memory usage comes up to ~125MB, which shows
that the formula is correct.
The calculation in detail
Let’s dive deeper into the IN_MEMORY_TRANSACTIONAL storage mode memory usage
values. Because Memgraph works on the x86 architecture, calculations are based
on the x86 Linux memory usage.
Each Vertex and Edge object has a pointer to a Delta object. The
Delta object stores all changes on a certain Vertex or Edge and that’s
why Vertex and Edge memory usage will be increased by the memory of
the Delta objects they are pointing to. If there are few updates, there are
also few Delta objects because the latest data is stored in the object.
But, if the database has a lot of concurrent operations, many Delta objects
will be created. Of course, the Delta objects will be kept in memory as long as
needed, and a bit more, because of the internal GC inefficiencies.
Delta memory layout
Each Delta object has a least 56B.
Vertex memory layout
Each Vertex object has at least 80B + 56B for the Delta object, in
total, a minimum of 136B.
Each additional label takes 4B.
Keep in mind that three labels take as much space as four labels, and five to seven labels take as much space as eight labels, etc., due to the dynamic memory allocation.
Edge memory layout
Each Edge object has at least 32B + 56B for the Delta object, in
total, a minimum of 88B.
By default, each Edge object is also placed inside the edge SkipList, which
adds the SkipListNode container overhead described below (roughly 24B per
edge). The lightweight edges mode
(--storage-light-edge) removes this container and pool-allocates edges
directly, eliminating that overhead.
SkipList memory layout
Each object (Vertex, Edge) is placed inside a data structure
called a SkipList. The SkipList has an additional overhead in terms of
SkipListNode structure and next_pointers. Each SkipListNode has an
additional 8B element overhead and another 8B for each of the next_pointers.
It is impossible to know the exact number of next_pointers upfront, and consequently the total size, but it’s never more than double the number of objects because the number of pointers is generated by binomial distribution (take a look at the source code for details).
Index memory layout
Each LabelIndex::Entry object has exactly 16B.
Depending on the actual value stored, each LabelPropertyIndex::Entry has at least 72B.
Objects of both types are placed into the SkipList.
Each index object in total
SkipListNode<LabelIndex::Entry>object has 24B.SkipListNode<LabelPropertyIndex::Entry>has at least 80B.- Each
SkipListNodehas an additional 16B because of the next_pointers.
Properties
All properties use 1B for metadata - type, size of property ID and the size
of payload in the case of NULL and BOOLEAN values, or size of payload size
indicator for other types (how big is the stored value, for example, integers
can be 1B, 2B 4B or 8b depending on their value).
Then they take up another byte for storing property ID, which means each
property takes up at least 2B. After those 2B, some properties (for example,
STRING values) store addition metadata. And lastly, all properties store the
value. So the layout of each property is:
| Value type | Sizing in detail | Total estimated size | Note |
|---|---|---|---|
NULL | 0B | 0B | Memgraph treats null values same as if they’re not present. Therefore, NULL values are not stored in the property store. |
BOOL | 1B + 1B | 2B | The value is written in the first byte of the basic metadata. |
INT | 1B + 1B + 1B, 2B, 4B or 8B | 3B - 10B | Basic metadata, property ID and the value depending on the size of the integer. |
DOUBLE | 1B + 1B + 2B, 4B or 8B | 4B, 6B or 10B | Basic metadata, property ID and the value. Value size depends on --storage-floating-point-resolution-bits: 16-bit (half), 32-bit (float), 64-bit (double). |
STRING | 1B + 1B + 1B + min 1B | at least 4B | Basic metadata, property ID, additional metadata and lastly the value depending on the size of the string, where 1 ASCII character in the string takes up 1B. |
LIST | 1B + 1B + 1B + min 1B | at least 4B (empty) | Basic metadata, property ID, additional metadata and the total size depends on the number and size of the values in the list. |
MAP | 1B + 1B + 1B + min 1B | at least 4B (empty) | Basic metadata, property ID, additional metadata and the total size depends on the number and size of the values in the map. |
TEMPORAL_DATA | 1B + 1B + 1B + min 1B + min 1B | 12B | Basic metadata, property ID, additional metadata, seconds, microseconds. Value of the seconds and microseconds is at least 1B, but probably 4B in most cases due to the large values they store. |
ZONED_TEMPORAL_DATA | TEMPORAL_DATA + 1B + min 1B | at least 14B | Like TEMPORAL_DATA, but followed by timezone name length (1 byte) and string (1 byte per character). |
OFFSET_ZONED_TEMPORAL_DATA | TEMPORAL_DATA + 2B | at least 14B | Like TEMPORAL_DATA, but followed by the offset from UTC (in minutes; always 2 bytes). |
ENUM | 1B + 1B + 2B, 4B, 8B or 16B | 4B - 18B | Basic metadata, property ID and the value depending on required size representation required. |
Users can additionally inspect the exact size of a property in bytes using the propertySize() function. The query usage is the following:
MATCH (n)
RETURN n.id AS id, propertySize(n, "id") AS prop_size_bytes;Output:
+-----------+-----------------+
| id | prop_size_bytes |
+-----------+-----------------+
| 1 | 3 |
+-----------+-----------------+Marvel dataset use case
The Marvel dataset consists of Hero, Comic and ComicSeries labels, which
are indexed. There are also three label-property indexes - on the name
property of Hero and Comic vertices, and on the title property of
ComicSeries vertices. The ComicSeries vertices also have the publishYear
property.
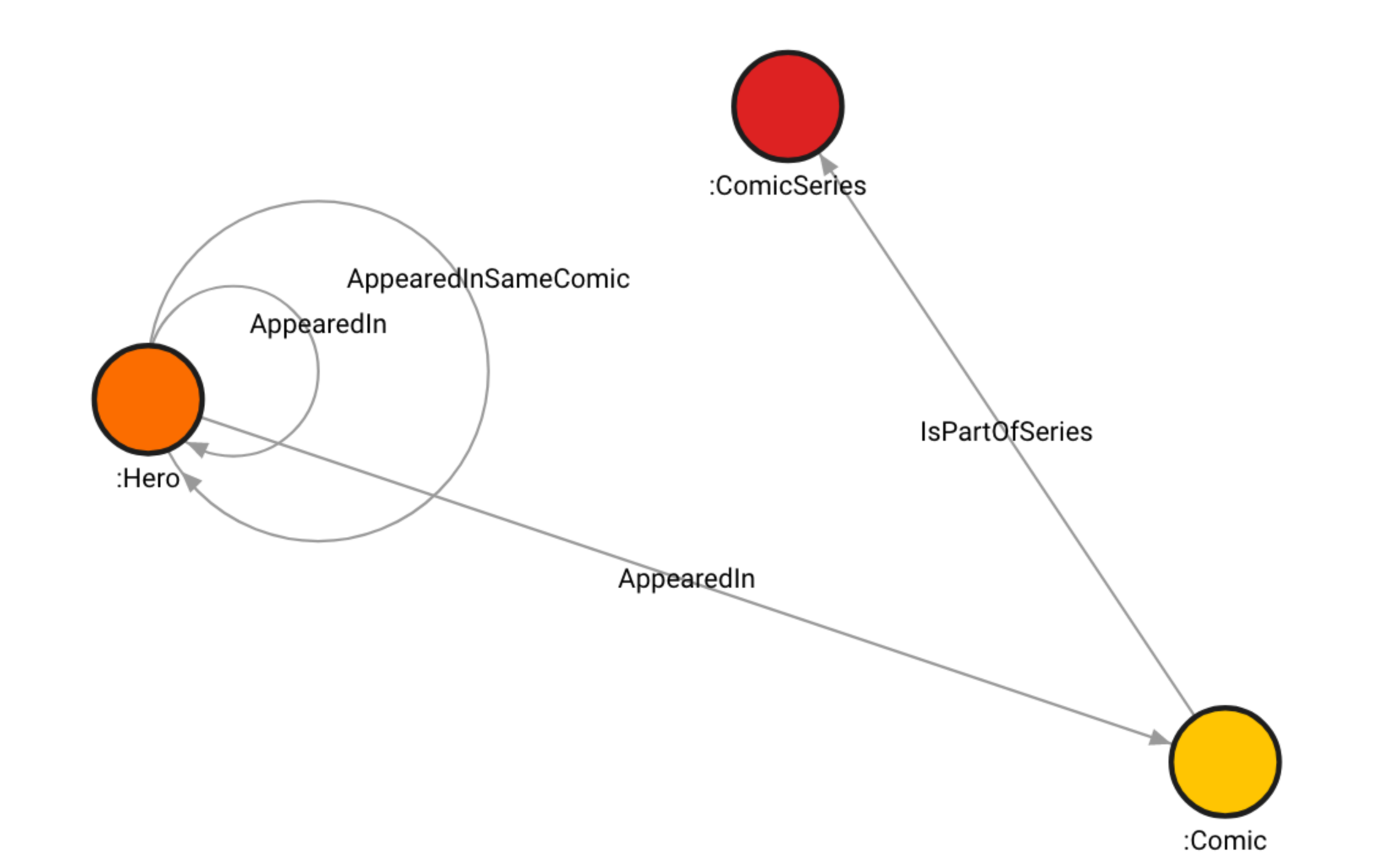
There are 6487 Hero and 12,661 Comic vertices with the property name.
That’s 19,148 vertices in total. To calculate how much storage those vertices
and properties occupy, we are going to use the following formula:
Let’s assume the name on average has (each name is on average 10 characters long). Once the average values are included, the calculation is:
The remaining 2,584 vertices are the ComicSeries vertices with the title and
publishYear properties. Let’s assume that the title property is
approximately the same length as the name property. The publishYear property
is a list of integers. The average length of the publishYear list is 2.17,
let’s round it up to 3 elements. Since the year is an integer, 2B for each
integer will be more than enough, plus the 2B for the metadata. Therefore, each
list occupies . Using the same
formula as above, but being careful to include both title and publishYear
properties, the calculation is:
In total, to store vertices.
The edges don’t have any properties on them, so the formula is as follows:
There are 682,943 edges in the Marvel dataset. Hence, we have:
Next, Hero, Comic and ComicSeries labels have label indexes. To calculate
how much space they take up, use the following formula:
Since there are three label indexes, we have the following calculation:
For label-property index, labeled property needs to be taken into account.
Property name is indexed on Hero and Comic vertices, while property
title is indexed on ComicSeries vertices. We already assumed that the
title property is approximately the same length as the name property.
Here is the formula:
When the appropriate values are included, the calculation is:
Now let’s sum up everything we calculated:
Bear in mind the number can vary because objects can have higher overhead due to the additional data.
Control memory usage
In Memgraph, you can control memory usage by limiting, inspecting and deallocating memory.
You can control the memory usage of:
- a whole instance by setting the
--memory-limitwithin the configuration file - a query by including the
QUERY MEMORYclause at the end of a query - a procedure by including the
PROCEDURE MEMORYclause
Control instance memory usage
By setting the --memory-limit flag in the configuration
file, you can set the maximum amount of
memory (in MiB) that a Memgraph instance can allocate during its runtime. If the
memory limit is exceeded, only the queries that don’t require additional memory
are allowed. If the memory limit is exceeded while a query is running, the query
is aborted and its transaction becomes invalid.
The effective allocation limit (shown as memory_limit in
SHOW STORAGE INFO) is set to the lower of the --memory-limit
configuration flag and the Enterprise license memory
limit.
This limit applies to the entire Memgraph instance across all databases. To set
a per-database / per-tenant memory limit (which also covers query memory usage
against a single database), visit Tenant
Profiles.
If the flag is set to 0, it will use the default values. Default values are:
- 90% of the total memory if the system doesn’t have swap memory.
- 100% of the total memory if the system has swap memory.
Control query memory usage
Query execution also uses up RAM. All allocations inside query are counted from intermediary results to allocations made while creating nodes and relationships. In some cases, intermediate results are aggregated to return valid query results and the query execution memory can end up using a large amount of RAM. Keep in mind that query execution memory monotonically grows in size during the execution, and it’s freed once the query execution is done. A general rule of thumb is to have double the RAM than what the actual dataset is occupying.
Each Cypher query can include the following clause at the end:
QUERY MEMORY ( UNLIMITED | LIMIT num (KB | MB) )If you use the LIMIT option, you have to specify the amount of memory a query
can allocate for its execution. You can use this clause in a query only once at
the end of the query. The limit is applied to the entire query.
Examples:
MATCH (n) RETURN (n) QUERY MEMORY LIMIT 10 KB;MATCH (n) RETURN (n) QUERY MEMORY UNLIMITED;Control procedure memory usage
Each procedure call can contain the following clause:
PROCEDURE MEMORY ( UNLIMITED | LIMIT num ( KB | MB) )If you use the LIMIT option, you can specify the amount of memory that the
called procedure can allocate for its execution. If you use the UNLIMITED
option, no memory restrictions will be imposed when the procedure is called. If
you don’t specify the clause, the memory limit is set to a default value of 100 MB.
One procedure call can have only one PROCEDURE MEMORY clause at the end of the
call. If a query contains multiple procedure calls, each call can have its own
limit specification.
Examples:
CALL example.procedure(arg1, arg2, ...) PROCEDURE MEMORY LIMIT 100 KB YIELD result;CALL example.procedure(arg1, arg2, ...) PROCEDURE MEMORY LIMIT 100 MB YIELD result;CALL example.procedure(arg1, arg2, ...) PROCEDURE MEMORY UNLIMITED YIELD result;Inspect memory usage
Run the following query to get instance-level (process-wide) information about memory usage, disk usage, tracked memory and the allocation limit:
SHOW STORAGE INFO;+--------------------------------+----------------------------------------+
| storage info | value |
+--------------------------------+----------------------------------------+
| "vm_max_map_count" | 453125 |
| "memory_res" | "43.16MiB" |
| "peak_memory_res" | "43.16MiB" |
| "disk_usage" | "104.46KiB" |
| "memory_tracked" | "8.52MiB" |
| "memory_limit" | "58.55GiB" |
| "license_memory_limit" | "unlimited" |
| "query+graph_memory_tracked" | "6.14MiB" |
| "vector_index_memory_tracked" | "2.38MiB" |
| "global_isolation_level" | "SNAPSHOT_ISOLATION" |
| "session_isolation_level" | "" |
| "next_session_isolation_level" | "" |
| "global_storage_mode" | "IN_MEMORY_TRANSACTIONAL" |
+--------------------------------+----------------------------------------+The unscoped SHOW STORAGE INFO returns only instance-level fields. For
per-database metrics (such as vertex_count, edge_count, the live
storage_mode and per-database memory trackers), use
SHOW STORAGE INFO ON CURRENT DATABASE or SHOW STORAGE INFO ON DATABASE <name>.
Find out more about SHOW STORAGE INFO query on Server
stats.
Per-database memory tracking Enterprise
In multi-tenant deployments, Memgraph Enterprise tracks memory for each database independently. Each database’s allocations are counted against both the database’s own limit and the global instance limit, ensuring no single database can starve others of resources.
Storage, query execution, and vector index allocations are all attributed to the database that originated them, giving a complete picture of per-database memory usage.
Per-database storage and memory metrics are exposed through these queries
(SHOW STORAGE INFO ON CURRENT DATABASE is new in Memgraph 3.11; the other two
already existed):
SHOW STORAGE INFO ON CURRENT DATABASE;
SHOW STORAGE INFO ON DATABASE mydb;
SHOW MEMORY INFO;Their editions and privileges differ — see the availability note below.
ON CURRENT DATABASE targets the session’s currently-selected database, while
ON DATABASE <name> targets a named database. Both return the full per-database
field set (storage stats, isolation level, storage mode and the memory trackers).
The memory-related fields are:
| Field | Description |
|---|---|
graph_memory_tracked | Storage memory (vertices, edges, properties) |
query_memory_tracked | Query execution memory |
vector_index_memory_tracked | Vector index memory |
tenant_memory_tracked | Current tracked memory for the database |
tenant_peak_memory_tracked | Peak memory tracked |
tenant_memory_limit | Limit from the tenant profile, or "unlimited" |
For the complete list of per-database fields (including name, database_uuid,
storage_mode, vertex_count, edge_count, average_degree,
unreleased_delta_objects, disk_usage, storage_isolation_level and health),
see Per-database storage information.
SHOW MEMORY INFO lists all databases with their profile and current usage:
| Field | Description |
|---|---|
name | Database name |
tenant_memory_tracked | Current tracked memory for the database |
profile | Tenant profile name, or null |
tenant_memory_limit | Configured limit, or "unlimited" |
Both per-database SHOW STORAGE INFO variants require the STATS privilege.
SHOW STORAGE INFO ON CURRENT DATABASE and SHOW STORAGE INFO ON DATABASE for
the default database work in all editions; targeting a non-default
database via ON DATABASE <name> requires the Memgraph Enterprise Edition.
SHOW MEMORY INFO requires no privilege beyond a valid Enterprise license and is
available only in the Memgraph Enterprise Edition.
How the memory fields relate
The global fields in SHOW STORAGE INFO and the per-database fields in
SHOW STORAGE INFO ON DATABASE form a hierarchy:
Per-database memory tracking flow (SHOW STORAGE INFO ON DATABASE columns)
tenant_memory_tracked ──────────────────────── total per-database
├── graph_memory_tracked (vertices, edges, properties)
├── query_memory_tracked (query runtime, not storage)
└── vector_index_memory_tracked (vector indices)
Per-database fields also include:
tenant_peak_memory_tracked highest value seen so far
tenant_memory_limit cap from tenant profile, or "unlimited"
Global relationship:
graph_memory_tracked (per-DB) ──┐
query_memory_tracked (per-DB) ──┴▶ query+graph_memory_tracked (global)
(the global graph arena tracks all default-new
allocations — both graph data and query heap)
vector_index_memory_tracked (per-DB) ──sum──▶ vector_index_memory_tracked (global)The per-database query_memory_tracked field tracks only runtime
memory — intermediate results, aggregations, and operator state during query
execution. It does not include storage allocations made by the query (those
are counted in graph_memory_tracked). This is different from the
QUERY MEMORY LIMIT clause, which caps both runtime and storage allocations
together.
Per-database memory limits are enforced via tenant profiles. When a limit is hit, any query that would allocate memory beyond the cap is rejected — read queries are not exempt.
Reduce memory usage
Here are several tips how you can reduce memory usage and increase scalability:
- Consider removing unused label indexes by executing
DROP INDEX ON :Label; - Consider removing unused label-property indexes by executing
DROP INDEX ON :Label(property); - If you don’t have properties on relationships, disable them in the
configuration file by setting the
--storage-properties-on-edgesflag tofalse. This can significantly reduce memory usage because effectivelyEdgeobjects will not be created, and all information will be inlined underVertexobjects. You can disable properties on relationships with a non-empty database, if the relationships are without properties. - If you do need properties on relationships, enable lightweight
edges by setting the
--storage-light-edgeflag totrueto save roughly 24B per edge. - Inspect query plans and optimize them
Lightweight edges
When you need properties on
relationships, each relationship is stored as
an Edge object inside a dedicated edge SkipList. That container adds roughly
24B of overhead per edge on top of the Edge object itself (see the
Edge memory layout section above).
Lightweight edges remove that dedicated container and pool-allocate the Edge
objects directly, saving ~24B per edge without changing the Edge object or
its Delta. To enable them, start Memgraph with:
--storage-light-edge=trueThis flag implies --storage-properties-on-edges=true: if you enable
lightweight edges without properties on edges, Memgraph logs a warning and turns
properties on edges on for you. If you don’t need properties on relationships at
all, disabling --storage-properties-on-edges (tip 3 above) saves even more,
because no Edge objects are created in the first place.
There is one tradeoff. The edge SkipList is the only structure that indexes
edges directly by their internal ID. With lightweight edges there is no such
container, so a direct edge lookup by ID (for example resolving an edge via
id()) can no longer be a direct lookup. Instead:
- With
--storage-enable-edges-metadata=true, the edge-metadata index locates the edge’s source vertex, and the lookup only scans that vertex’s edges — fast. - Without edge metadata, Memgraph falls back to scanning every vertex’s edges, which can be slow on large or high-degree graphs.
If your workload does edge lookups by ID, run
--storage-enable-edges-metadata=true together with --storage-light-edge=true.
Traversals, expansions, and pattern matches over relationships are not
affected — they use vertex adjacency lists, which are unchanged.
Lightweight edges work with the in-memory storage modes
(IN_MEMORY_TRANSACTIONAL and IN_MEMORY_ANALYTICAL), and are fully supported
with durability (snapshots and WAL) and
replication. The on-disk snapshot and WAL formats are
unchanged, so you can enable or disable the flag across a restart and recover the
same data either way.
Property compression
Another way to reduce memory usage is through property compression. This feature compresses the entire PropertyStore object, meaning it compresses all compressible properties in the database.
When property store compression is enabled, it checks if the PropertyStore of a vertex can be compressed, and if it can, it compresses it using the well-known compression library zlib.
To enable compression, set the --storage-property-store-compression-enabled flag to true. The default value of this flag is false.
Additionally, users can control the compression level with the --storage-property-store-compression-level flag. The default value is mid, but two other values, low and high, are also available.
The low setting compresses properties minimally, reducing memory usage slightly, while the high setting compresses properties the most, trying to maximize memory savings. However, there’s a tradeoff to consider:
higher compression levels can reduce performance. Therefore, users focused on maintaining optimal performance may prefer not to set it to high.
Keep in mind that even though it can reduce memory usage, compression can impact query performance.
Floating-point resolution
For workloads with many DOUBLE properties, you can reduce their storage size by lowering the floating-point precision via the --storage-floating-point-resolution-bits flag. The allowed values are 64 (default), 32, and 16, corresponding to double, float, and half precision respectively.
To enable 32-bit float precision, start Memgraph with:
--storage-floating-point-resolution-bits=32With this flag set, storing 3.14159265358979 will be retrieved as approximately 3.1415927 (float precision). Example:
CREATE (:Node {value: 3.14159265358979});
MATCH (n:Node) RETURN n.value;
// Returns: 3.1415927 (with --storage-floating-point-resolution-bits=32)
// Returns: 3.14159265358979 (with --storage-floating-point-resolution-bits=64)| Value | Precision | Bytes per value | Savings vs default |
|---|---|---|---|
64 | double (full) | 8B | — |
32 | float | 4B | 4B per double |
16 | half | 2B | 6B per double |
WAL files and snapshots always serialize DOUBLE values as full 64-bit IEEE 754, so the durability format itself is resolution-independent.
However, precision is baked in at write time: WAL and snapshot entries store the value that GetProperty() returns, which is already truncated to the active resolution. This has two consequences when the flag changes across a restart:
- Lowering the resolution (e.g. 64 → 32): doubles recovered from WAL/snapshot are re-encoded into PropertyStore at the new lower precision, causing additional truncation.
- Raising the resolution (e.g. 32 → 64): no further truncation occurs, but precision already lost in previous sessions cannot be recovered from WAL/snapshot alone.
If exact round-trip fidelity is required, set the resolution before loading data and do not change it afterwards.
Deallocating memory
Memgraph has a garbage collector that deallocates unused objects, thus freeing
the memory. The rate of the garbage collection in seconds can be specified in
the configuration file by setting the
--storage-gc-cycle-sec.
You can free up memory by using the following query:
FREE MEMORY;This query tries to clean up as much unused memory as possible without affecting currently running transactions.
Virtual memory
Memgraph uses a jemalloc allocator to handle all
allocations and to track allocations happening in the system.
The default operating system limits on mmap counts are likely to be too low,
which may result in out-of-memory exceptions.
To find out the current mmap count of a running Memgraph process use the
following command, where $PID is the process ID of the running Memgraph
process:
wc -l /proc/$PID/mapsOn Linux, you can increase the limits by running the following command as
root:
sysctl -w vm.max_map_count=524288To increase this value permanently, update the vm.max_map_count setting in
/etc/sysctl.conf. To verify, reboot the system and run sysctl vm.max_map_count.
The RPM and Debian packages will configure this setting automatically so you don’t need to do any more configurations.