Memgraph Lab
Memgraph Lab is a powerful visualization and management tool designed to help users interact with Memgraph database efficiently. Whether you’re just getting started, executing complex queries, or leveraging advanced features, this documentation provides the guidance you need to navigate and optimize your workflow.

Quick start
Run Memgraph MAGE and Memgraph Lab
Depending on your operating system, execute the appropriate command in the console:
curl https://install.memgraph.com | shThe above command will start Memgraph MAGE in a Docker container on the host
machine and expose port 7687 for Bolt connection and port 7444 for logs. The
command will also start Memgraph Lab in a Docker container and you can access it
on localhost:3000.

For other installation types, read the installation and deployment documentation.
Connect to Memgraph
Access Memgraph Lab on localhost:3000 in the browser. You will see the Quick
connect screen. To connect to Memgraph, click on Connect now button.

Run queries
Now, you can execute Cypher queries in Memgraph. Open the Query execution tab, located in the left sidebar, copy the following query and press the Run query button:
CREATE (u:User {name: "Alice"})-[:Likes]->(m:Software {name: "Memgraph"});The query above will create 2 nodes in the database, one labeled User with
name Alice and the other labeled Software with name Memgraph. It will also
create a relationship that Alice likes Memgraph.
To find created nodes and relationships, execute the following query:
MATCH p=()-[]->() RETURN p;You should get the following result:
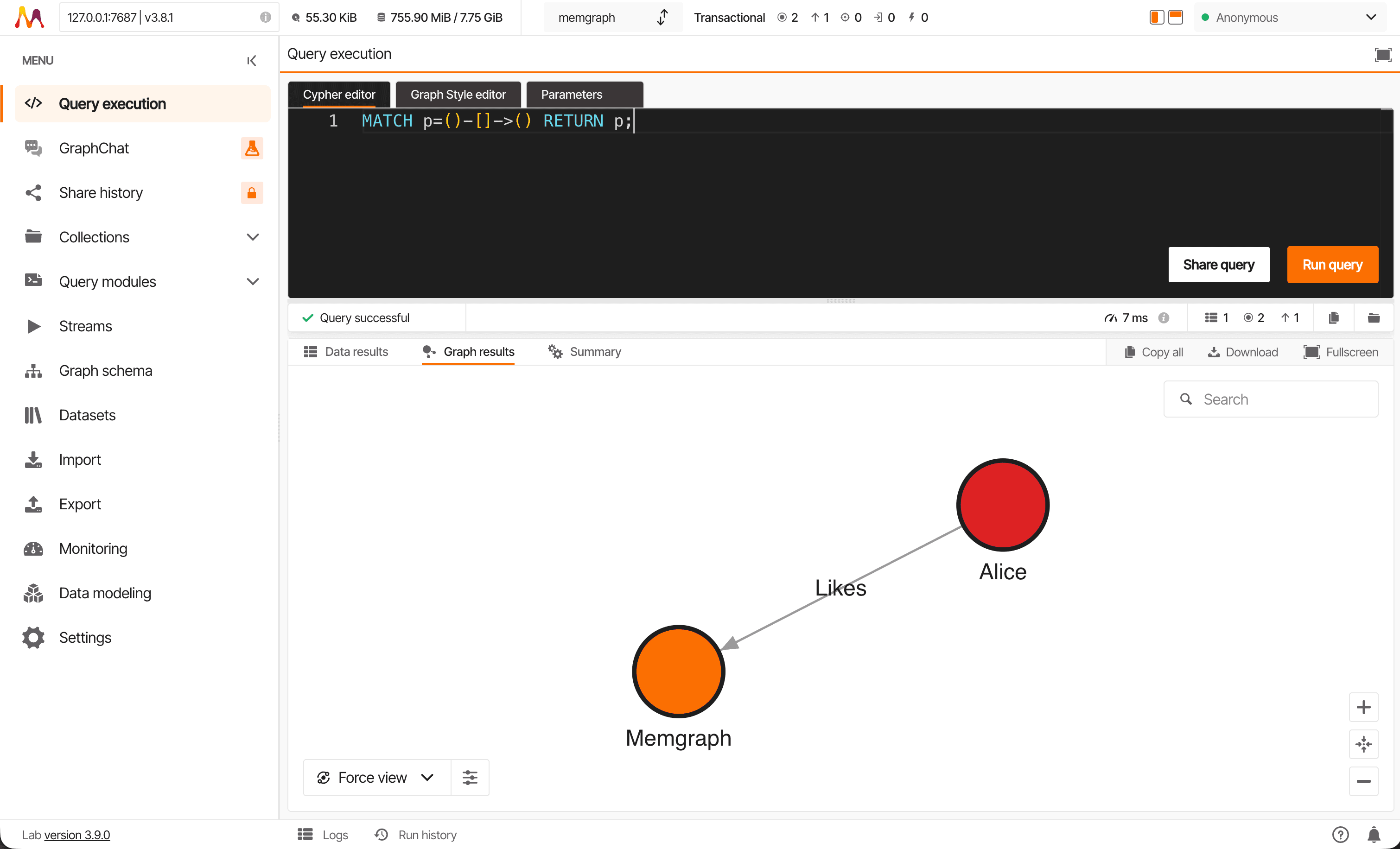
Features
Memgraph Lab provides a powerful and intuitive interface for working with graph data, offering a range of features to streamline data import, visualization, query execution, and collaboration.
Here is a list of advanced Memgraph Lab Enterprise features:
- Monitoring - A feature that tracks resource usage, database size, query activity, transaction flow, and active sessions, providing real-time insights into database performance.
- Sharing features - Query sharing allows users to share selected queries from the query execution or previously run queries from the history. Graph Style Script (GSS) sharing allows users to share styling scripts among team members.
- Single sign-on - Provides authorization and authentification to your database. Supports two types of SSO methods - OpenID Connect (OIDC + OAuth 2.0) and SAML, and two identity providers - Microsoft Azure (Entra ID) and Okta.
Some of the Enterprise features are not supported on the desktop version of Memgraph Lab. All Enterprise features are supported in the Docker environment.
For the full list of features, refer to the Features documentation.
Overview
To get familiar with Memgraph Lab, explore the following sections in this documentation:
Learn the Memgraph Lab installation and deployment best practices.
Discover how to execute Cypher queries, explore query results, and optimize performance.
Explore features such as GraphChat, monitoring, sharing features, and more.
Learn how to configure Memgraph Lab in Docker environment using environment variables.