How Local Graph Search Works in Atomic GraphRAG
GraphRAG starts to get interesting when the answer is not a single value. Sometimes the user is not asking for a count, a filter, or a direct lookup. They are asking for the context around something. That changes the retrieval job.
You are no longer trying to generate one exact query result. You are trying to find the right starting point in the graph, expand outward through the most relevant relationships, filter the noise, and return the surrounding context that will help answer the question. That is where local graph search fits.
This article focuses on the second common GraphRAG retrieval pattern: local graph search approach.
It is the classic GraphRAG workload because many real questions are neither purely analytical nor fully global. They sit in the middle. The user knows roughly what they are asking about, but the answer lives in the connected graph around it.
Common GraphRAG Question Types
A useful way to think about GraphRAG is to group its approaches based on different question types. Below are the three common question types:
- Analytical Approach: the answer exists as an exact value as a particular node or relationship.
- Local Approach: the answer depends on a focused subgraph around a relevant node.
- Global Approach: the answer requires synthesis across a broader part of the graph.
Those categories matter because they change the retrieval pattern.
Analytical questions fit Text2Cypher. Global questions call for broader query focused summarization. Local questions sit between those two.
They usually start with partial information, not a full identifier. You know the thing you care about, but you do not yet have the full surrounding context needed to answer well. That is why local graph search matters.
What Is Local Graph Search in GraphRAG?
Local graph search is the retrieval pattern used when you need a focused, context-rich subset of the graph. The goal is not to search the whole corpus and it is not to summarize the entire dataset. The goal is to retrieve the right neighborhood.
At a high level, the pattern looks like this:
- find a relevant starting point with pivot search (text or vector search)
- expand through neighboring nodes and relationships
- rank and filter what matters
- return a compact context set
That is the core local pattern. The important shift is this: Retrieval is not only about matching text. It is also about following the graph structure.
A keyword or embedding match may help you find the first node. The graph then does the rest of the useful work by showing what is connected, what is likely relevant, and what should be included in the final context.
Where Atomic GraphRAG Fits In
Atomic GraphRAG is Memgraph's single, unified execution model behind these retrieval patterns. Instead of scattering the pipeline across application code, search services, ranking logic, and post-processing steps, the idea is to build the retrieval plan as a single query by chaining database-side primitives together.
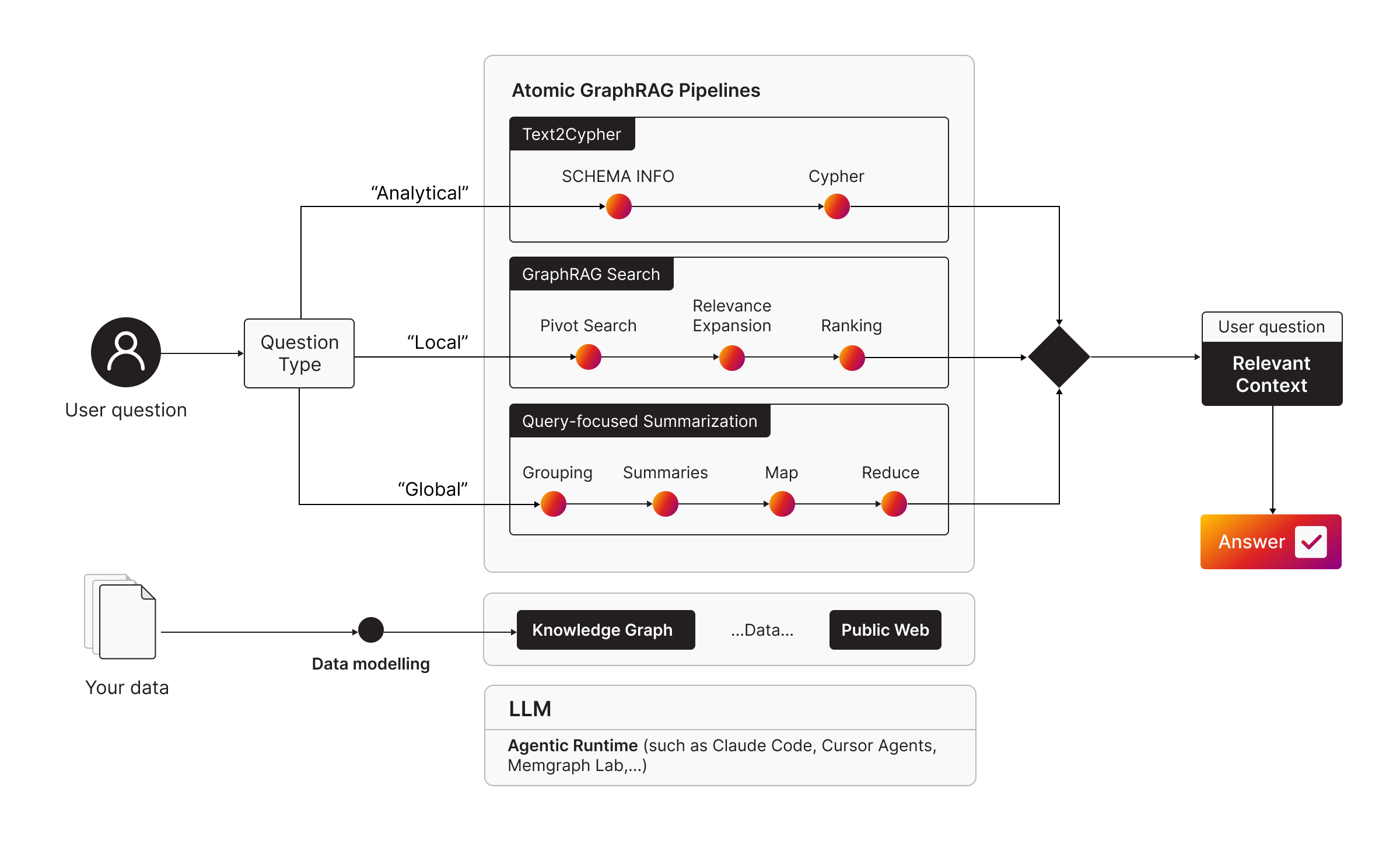
That matters a lot for local questions because local retrieval usually involves multiple moving parts. Keeping that logic inside one query plan has a few practical benefits.
First, it can cut orchestration code dramatically. That matters because humans have less code to review, which speeds up feedback, debugging, and iteration.
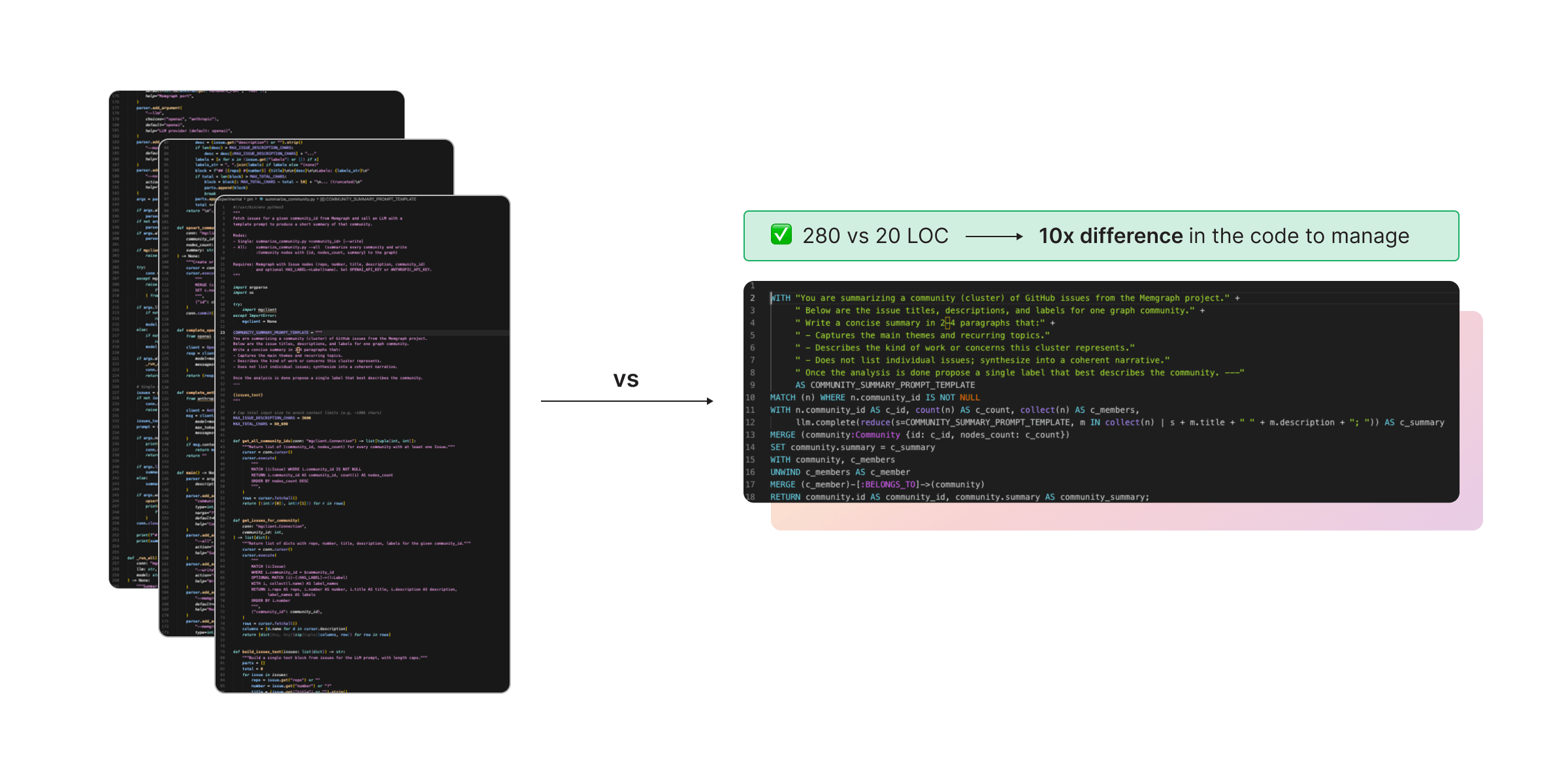
Second, Atomic GraphRAG makes it easier to connect agent workflows to the database because agents can iterate across many steps without adding or rewriting large amounts of code.
Third, the final context passed to the model stays much smaller and more targeted. That matters because smaller context windows are usually easier for LLMs and agents to use well. Less irrelevant context means less confusion, lower hallucination risk, better accuracy, and faster, cheaper execution.
That is the bigger point behind Atomic GraphRAG.
It is not only about making the pipeline look cleaner. It is about making more data usable. Once retrieval, filtering, and context assembly are handled more efficiently, both humans and LLM-based systems can work with larger connected datasets without drowning in unnecessary code or unnecessary context.
What Kinds of Questions Fit Local Graph Search?
Local graph search is a good fit for questions like these:
- A user searched for Cristiano Ronaldo. Which players should be recommended next based on the graph of co-viewing, follows, and engagement patterns?
- A fraud alert was triggered on this account. Which connected accounts, devices, merchants, and recent transactions should be reviewed first?
- This GitHub issue was reopened after a bug fix. Which related issues, pull requests, and affected community members are most closely connected to it?
- A shopper is looking at this product. Which reviews, related products, and parent product links provide the most useful surrounding context?
- This research paper is central to the query. Which authors, citations, methods, and follow-up papers are most closely connected to it?
The common thread is simple. The answer is not stored as one value in one node. You need a focused slice of the graph around something relevant.
That is why local graph search is often the most natural GraphRAG pattern in practice.
Why Pivot Search Comes First
A lot of local questions begin with incomplete information. The user may not provide the exact node identifier. They may use a shortened product name, an issue number without all the context, or a vague reference that needs to be resolved first.
That is where pivot search comes in.
The job of pivot search is to identify the most relevant starting node for the query.
Depending on the graph and the data shape, it might use text search, vector search, or both. Once the pivot is found, traversal expands outward to gather the local neighborhood around it.
This is a crucial difference from flat retrieval. Without the knowledge graph, you can only retrieve similar records. With the knowledge graph, you can retrieve the relationships that make those records meaningful.
Example 1: GitHub Issues Knowledge Graph
One strong local graph search example comes from a knowledge graph built over Memgraph’s GitHub issues. In that graph, issues are connected not only through labels, but also through RelatedTo edges derived from entity extraction over issue titles and descriptions.
Scenario
A pull request fixes a bug, but the surrounding issue graph may still contain related issues that were never linked to that PR, never updated, or never closed. Some community members may also need to be informed because they were involved in the earlier reports or discussions.
User Question
Under PR 3103,
memgraph/memgraphserialization errors during concurrent edge write don't happen any more, what are the related GitHub issues that should be updated or closed, do we have to communicate change to the specific community members?
Reasoning / Agentic Runtime Steps
-
… pulling data from Github (from the link) …
-
called queries via MCP:
CALL embeddings.text( ['serialization errors during concurrent edge writes on supernodes']) YIELD embeddings, success CALL vector_search.search('vs_index', 10, embeddings[0]) … relevance expansion … //////// SHOW SCHEMA INFO; //////// … other “regular” memgraph queries … -
… pulling data from Github (author missing under local data) …
Results
The value of this example is not that it returns a single matched issue. It returns the surrounding context that actually matters for the decision.

This is exactly what local graph search is built for. It helps you recover the part of the graph around a relevant change and turn that neighborhood into actionable context.
For full walkthrough, watch the full GitHub Issues demo!
Example 2: Amazon Reviews Knowledge Graph
A second local graph search example comes from the Amazon Reviews knowledge graph.
In that graph, users, reviews, products, and parent products are connected through explicit relationships. That structure makes it possible to ask not only whether a user node exists, but also what is around that user in the graph.
Scenario
You have a user identifier and want to inspect the surrounding graph structure.
The goal is not just to confirm that the user exists. The goal is to retrieve the related nodes around that user so you can understand what local context is immediately available for retrieval.
User Question
Are there related nodes that contains node AGLQQCI (User ID)?
Cypher Query
MATCH (u:User {id: 'AGLOOCISSVGEGUCSSSSNHWZHOM60'})
OPTIONAL MATCH (u)-[r1]-(n1)
WITH u, collect(DISTINCT {rel:type(r1), dir: CASE WHEN startNode(r1) = u THEN 'out'
ELSE 'in' END, labels: labels(n1), id:n1.id}) AS hop1
OPTIONAL MATCH (u)-[*2]-(n2)
WITH u, hop1, collect(DISTINCT {labels: labels(n2), id:n2.id}) AS hop2
RETURN u.id AS userId,
size(hop1) AS hop1_count,
hop1[0..20] AS hop1_sample,
size(hop2) AS hop2_count,
hop2[0..20] AS hop2_sample;Results
The result shows that the user is not isolated. There are many related nodes around that :User node.
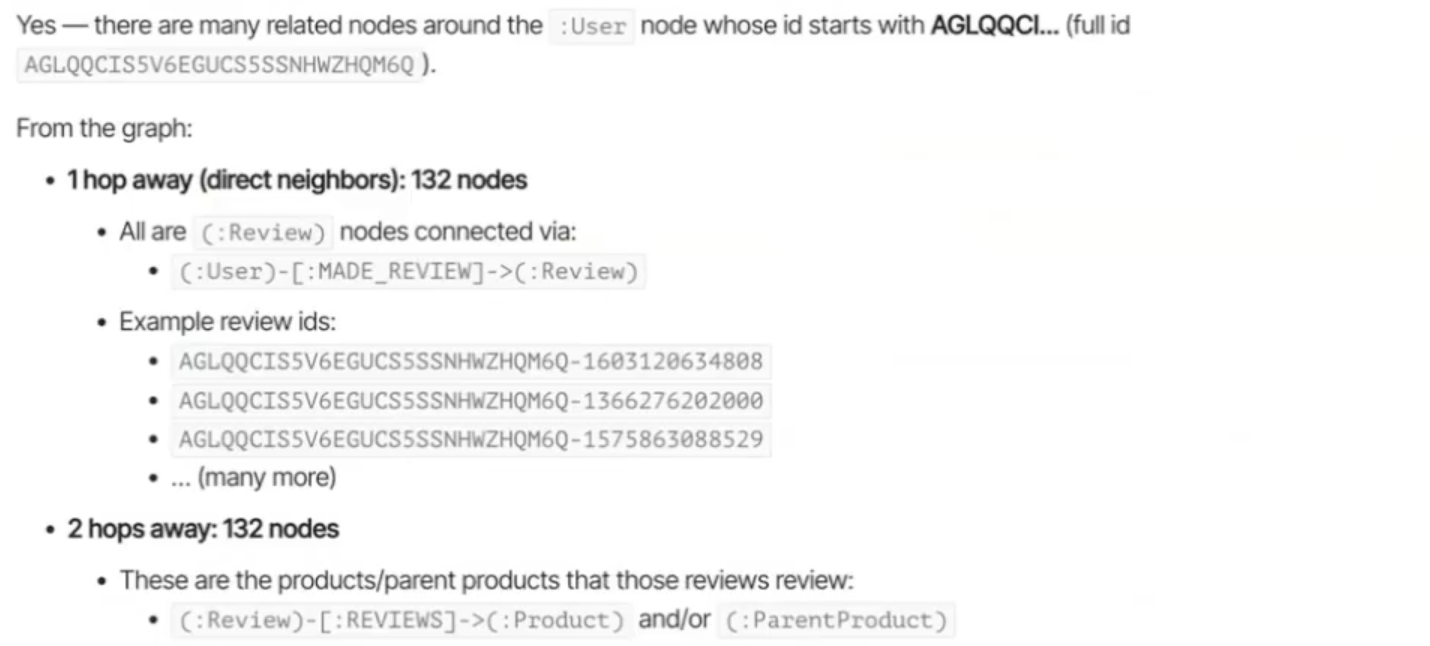
Once that neighborhood is retrieved, it becomes the context set for deeper reasoning.
For full walkthrough, Watch the full Amazon Reviews demo!
When Not to Use Local Graph Search
Local graph search is not the right fit for every question.
- If the user is asking for a direct count, grouped output, or exact property lookup, Text2Cypher is usually the cleaner choice.
- If the user is asking for broad themes, major gaps, or a summarization across large parts of the graph, global approach is required.
For example, local graph search is not the best fit for questions like these:
- How many open invoices are tied to this customer?
- Which products have an ROI above 30 percent?
- What are the main blind spots across the whole dataset?
- What themes keep showing up across negative reviews?
Those questions belong to different retrieval patterns.
The strength of local graph search is focused context around a relevant node, not exact scalar retrieval and not full dataset synthesis.
Wrapping Up
Local graph search is the GraphRAG retrieval pattern for questions that need the right neighborhood, not just the right match.
It starts from something relevant, expands outward through graph structure, ranks what matters, and returns a compact context set.
That makes it a strong fit for questions where the answer depends on connected entities, surrounding relationships, and focused context rather than one exact value.
Atomic GraphRAG speeds it up manifold. Once search, traversal, ranking, and filtering all belong to the same retrieval plan, the graph stops being a passive store and starts acting like the execution layer for context retrieval.
If you are building GraphRAG systems, this is the pattern to study when plain semantic search starts feeling too shallow.
Further Reading
- Blog: Atomic GraphRAG Explained: The Case for a Single-Query Pipeline
- Blog: Atomic GraphRAG Demo: A Single Query Execution
- Docs: Atomic GraphRAG Pipelines
- Blog: Memgraph 3.8 is Out: Atomic GraphRAG + Vector Single Store With Major Performance Upgrades
- Docs: GraphRAG in Memgraph
- GitHub: Memgraph AI Toolkit
- Blog: From JSON to GraphRAG: Building the Amazon Reviews Knowledge Graph