
Atomic GraphRAG Demo: A Single Query Execution
GraphRAG often breaks down for operational reasons. Not because retrieval is inherently difficult, but because the pipeline turns into a distributed system with too many handoffs. Similarity search runs in one place, traversal in another, and prompt assembly becomes a brittle set of conventions that is hard to validate and harder to maintain.
In this Community Call, Memgraph CTO Marko Budiselić makes a concrete claim. Express the end to end GraphRAG retrieval plan as a single Cypher query that executes inside Memgraph. Fewer round trips. Fewer moving parts. A tighter loop for iteration and debugging.
If you missed the live demo with Q&A session, you should watch the full Community Call recording here.
Here are the key takeaways from the discussion.
What Is Atomic GraphRAG
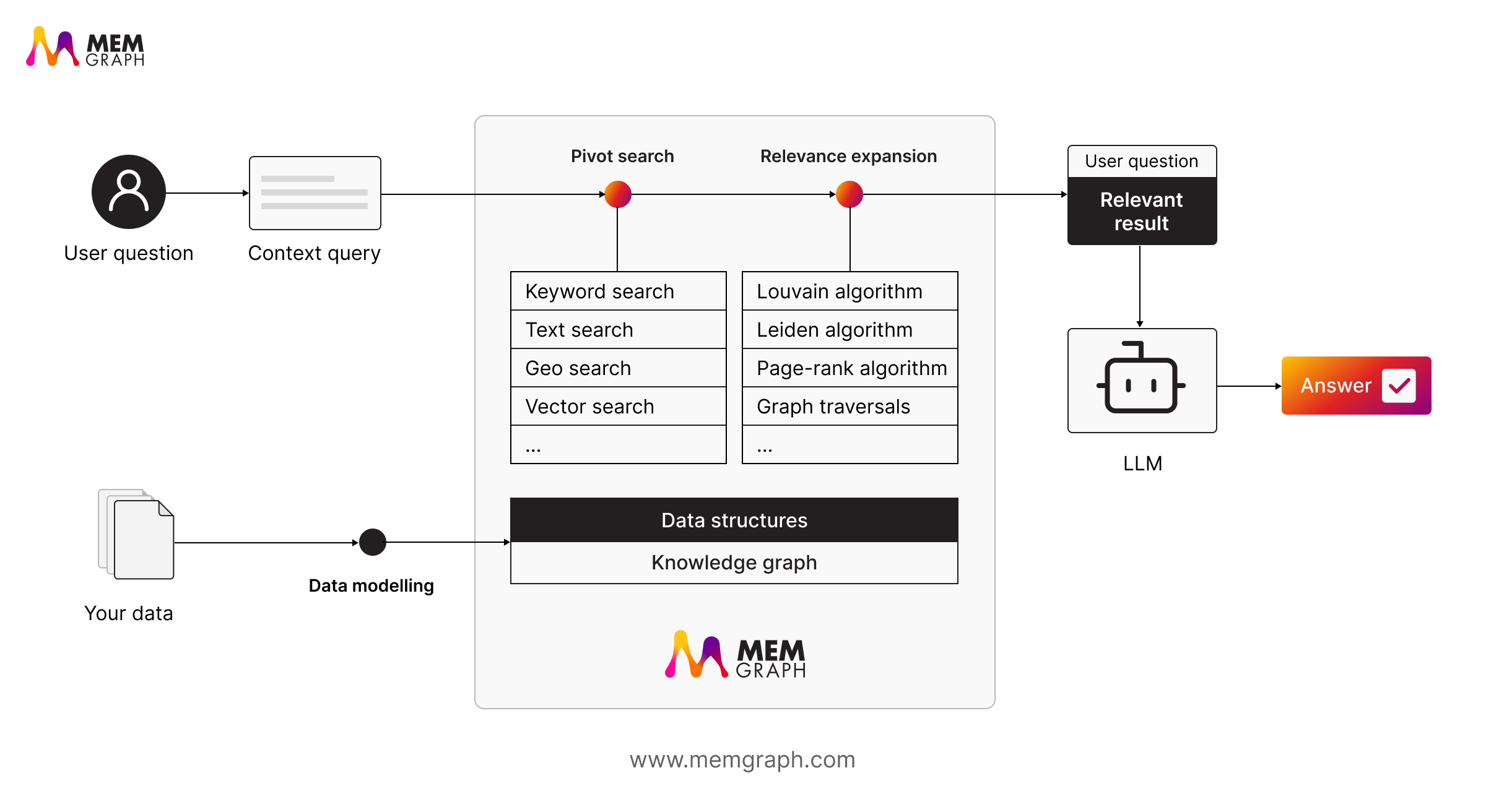
Atomic GraphRAG is an execution approach where pivot search, graph relevance expansion, ranking, and final prompt assembly are expressed as a single Cypher query, run in one place, and returned as a compact result. Fewer round trips. Fewer moving parts. A tighter loop for iteration and debugging.
Key Takeaway 1: The Challenge of Pipeline Sprawl
Most teams start with a clean diagram and end with a mess.
A typical GraphRAG flow looks like this:
- Run similarity search in a vector store
- Send embeddings to a graph database for relevance expansion
- Apply filters and ranking in application code
- Assemble prompt context in application code
- Call the LLM
That pipeline can work. The problem is what it does to engineering reality.
The logic is split across systems, so you debug behavior by correlating logs, retries, timeouts, and serialization decisions. Each handoff adds latency because you keep moving intermediate results between services. The model gets blamed, but the failures usually come from the pipeline design.
Atomic GraphRAG is Memgraph’s answer to that. Put the plan inside the database. Let the runtime send one query. Return either structured results or a compact, ready to use context payload.
Key Takeaway 2: Why "Just Put It in One Query" Strategy Fails
“Just put it in one query” is not a strategy unless the database can execute heavy plans efficiently and keep ingestion stable. The session ties Atomic GraphRAG to the all new Memgraph 3.8 and calls out the engine-level work that makes the approach realistic.
Intra-Query Parallelization
Atomic queries tend to do several expensive things in one plan. A pivot search, then traversal, then aggregation and ranking. Memgraph 3.8 introduces intra-query parallelization so parts of a single Cypher query can run across multiple CPU cores.
This is the difference between a nice idea and something you can put into production workloads.
Concurrent Edge Writes on High Degree Nodes
Context graphs are living systems. If ingestion is fragile, your retrieval layer becomes stale quickly.
Memgraph 3.8 is presented as handling concurrent edge writes on supernodes without hitting serialization errors, while keeping ACID guarantees. The point is straightforward. You need reliable high throughput updates if the graph is meant to reflect what is true right now.
Single Store Vector Index
Vectors and embeddings are expensive at scale. Storing them twice is wasted memory.
Memgraph can now store vectors once in the index rather than duplicating them in property storage plus index. This has resulted in memory overhead reduction around 80 to 85 percent for some workloads. You do not need to obsess over the exact number to see why it matters. Lower overhead makes it easier to scale embeddings without turning your database into a memory tax.
Load Formats That Fit Real Workflows
Completion of LOAD CSV/JSONL/PARQUET from LOCAL/HTTPS/S3
The session also highlights practical ingestion and experimentation support: LOAD CSV, JSONL, and Parquet, including sources like HTTPS and S3. This is useful for on-demand analysis and ephemeral setups where you spin up an environment, pull a dataset, run the plan, and discard the instance.
Key Takeaway 3: Atomic GraphRAG Is a Set of Primitives
Atomic GraphRAG is not a single magic feature. It is a set of primitives you can stitch together in Cypher so the database becomes the execution layer for retrieval and reasoning steps.
The session highlights these building blocks:
- show schema info for schema aware query generation.
- Embedding procedures for text and nodes.
- Vector search and text search.
- Traversals plus algorithms for expansion and ranking.
- Community detection with Louvain for global grouping.
- llm.complete for generation inside the query.
- Server side parameters, mentioned as coming in 3.9.
The architectural shift is not subtle.
In a traditional setup, the application orchestrates the plan and the database returns partial results at each stage. In the atomic setup, the query plan orchestrates the stages and the runtime stays short.
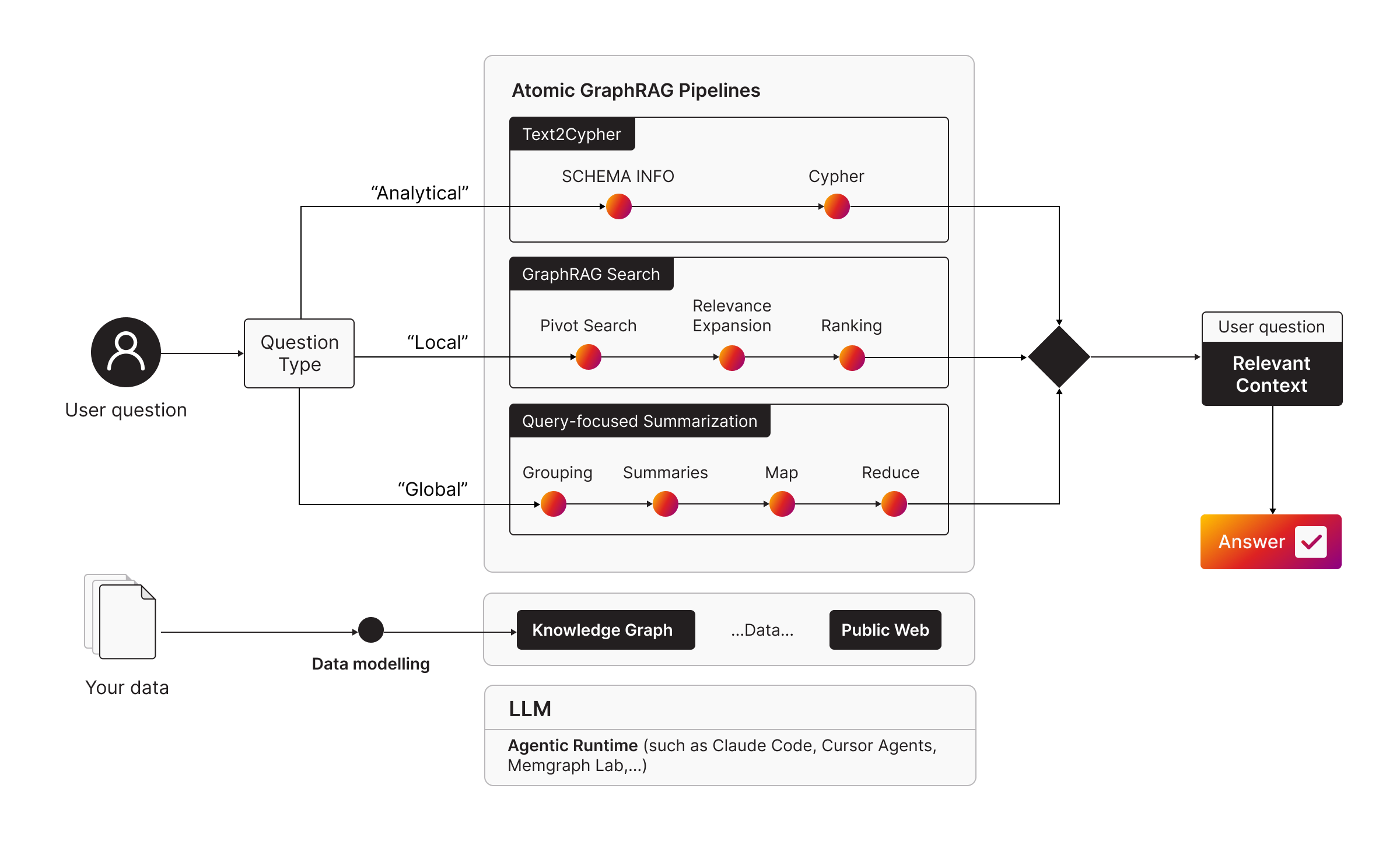
Key Takeaway 4: Three Common Retrieval Patterns
Atomic GraphRAG is not presented as one rigid pipeline. It is a unified execution layer that supports different retrieval patterns, depending on the question. Here are 3 common question types:
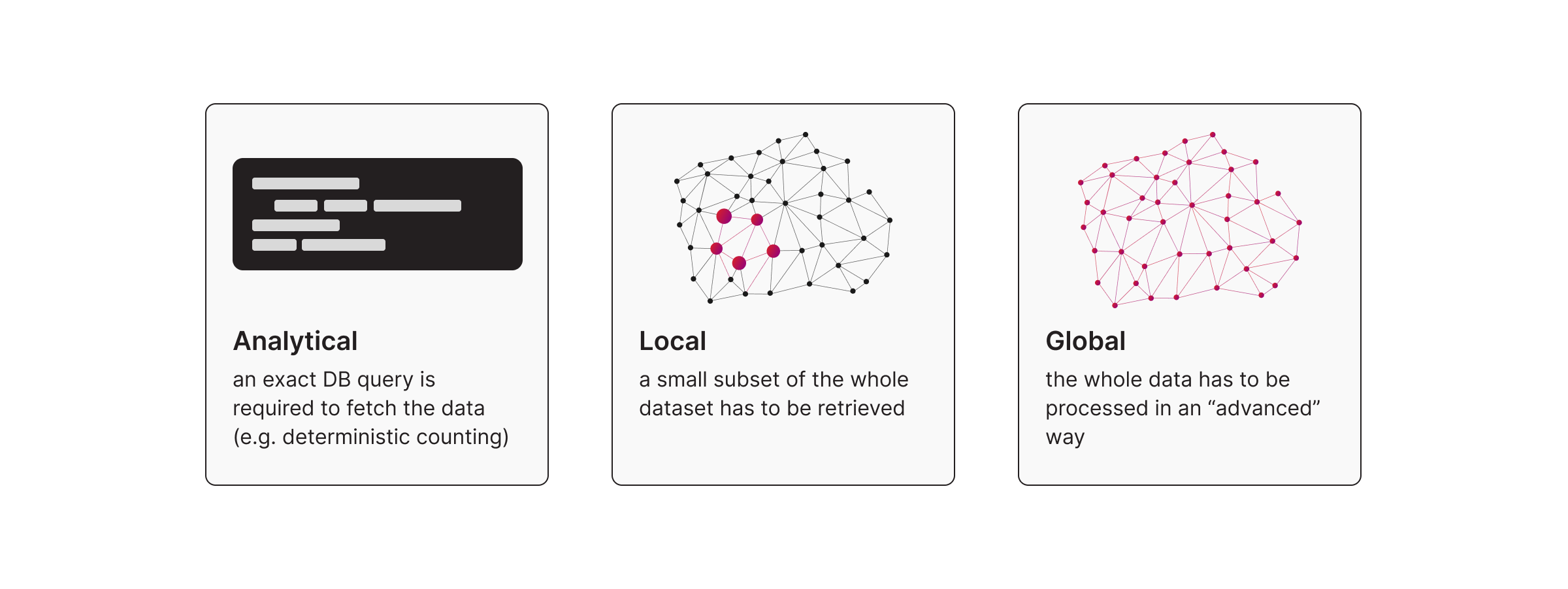
Pattern 1: Text-to-Cypher for Analytical Questions
Use text-to-Cypher for analytical questions like counts, averages, grouping, and filtering. The basic flow is schema first, then generate the query, then execute and return a table result.
Pattern 2: GraphRAG Search for Local Context
This is the classic GraphRAG workload for the local questions. You start from something relevant, then expand the neighborhood to capture the surrounding story.
The atomic pattern:
- Pivot search using vector search or text search
- Expand neighbors with traversal
- Rank and filter
- Return a compact context payload
Remember, ranking is part of retrieval. If ranking lives outside the database, you are back to pipeline sprawl. There are several ranking options, including simple heuristics like degree, PageRank, and even LLM-based ranking (which on the more expensive side).
Pattern 3: Query-Focused Summarization for Global Questions
Some questions are not local. They are about themes and coverage.
What are the key themes. Where are the blind spots. What keeps showing up across the graph.
These are global questions requiring query-focused summarization session focused on community detection plus summarization:
- Compute communities with Louvain.
- Summarize each community.
- Evaluate each community summary against the question.
- Synthesize the final response.
The exact procedures and data shape depend on your graph. The point is that grouping, summarization, and evaluation can be executed as part of one-query plan.
Key Takeaway 5: Skills & MCP Support Quick Adoption
Atomic queries are powerful, but they are not beginner-friendly if every engineer starts from a blank page. For faster and smoother adoption, skills and a standard protocol are extremely useful across teams.
Skills
Agent Skills were developed by Anthropic and published as an open standard. In practice, a skill is packaged as a folder, with a SKILL.md file that defines the skill metadata and instructions. Skills can include query patterns, operational steps, and examples.
They are framed as role-aligned. AI engineers need retrieval and ranking patterns. Data analysts need analytical templates. Product teams need triage workflows.
The practical goal is not more prompts. It is more repeatable workflows.
MCP
MCP is presented as the interface that keeps tool surfaces small and consistent. For the database, the core action is effectively run query.
That matters because large tool catalogs can bloat the runtime context and distract the model. If your database can execute the plan, the runtime does not need a sprawling tool schema.
The Stack Presented
- Agentic runtime
- Skills
- MCP
- Atomic GraphRAG
Here’s what the higher level architecture looks like:
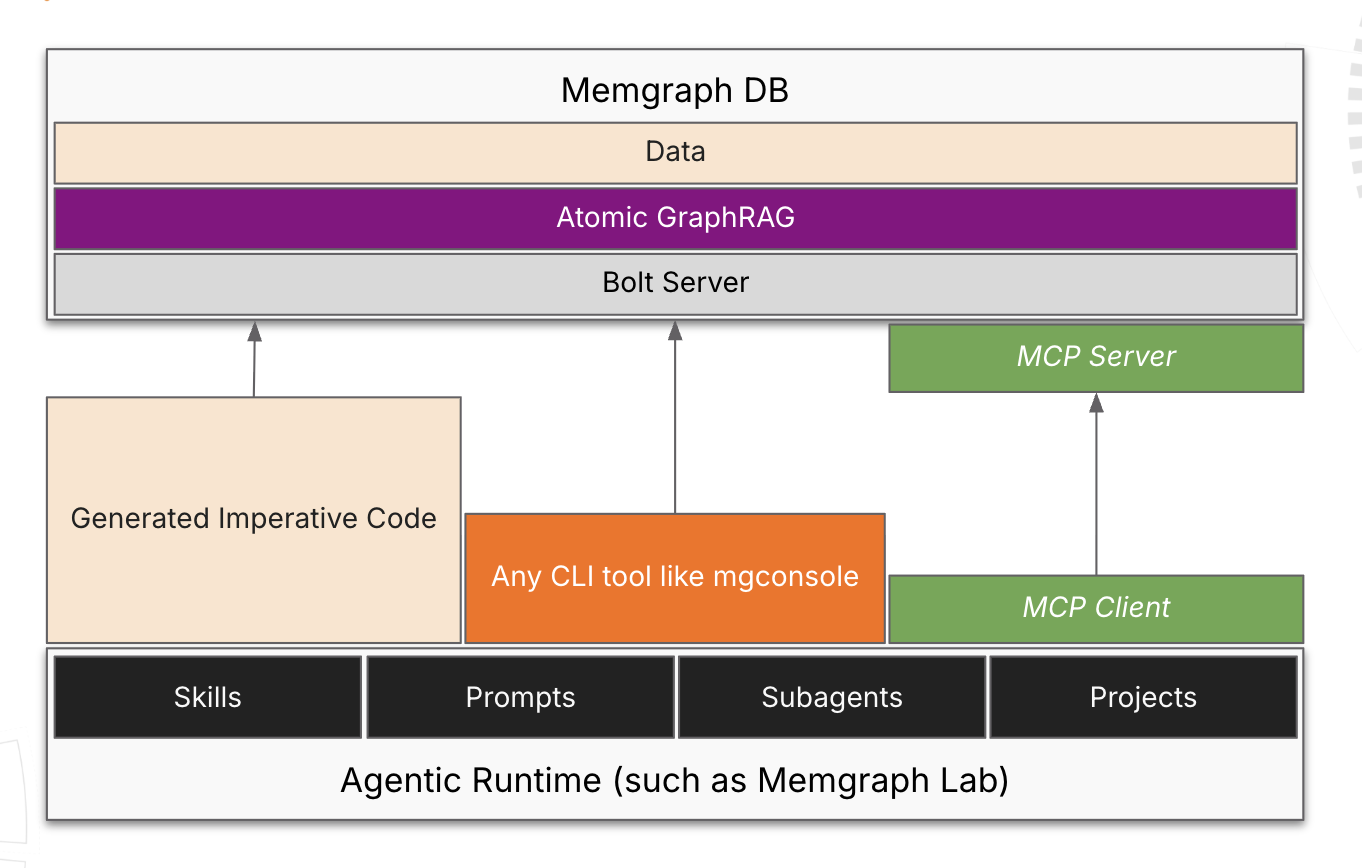
Key Takeaway 4: Agentic GraphRAG: Automating Pipeline Selection
Agentic GraphRAG is the combination of Atomic GraphRAG with Skills, MCP and Agentic Runtime. This tech stacks automates your pipeline selection and will help you quickly get started.
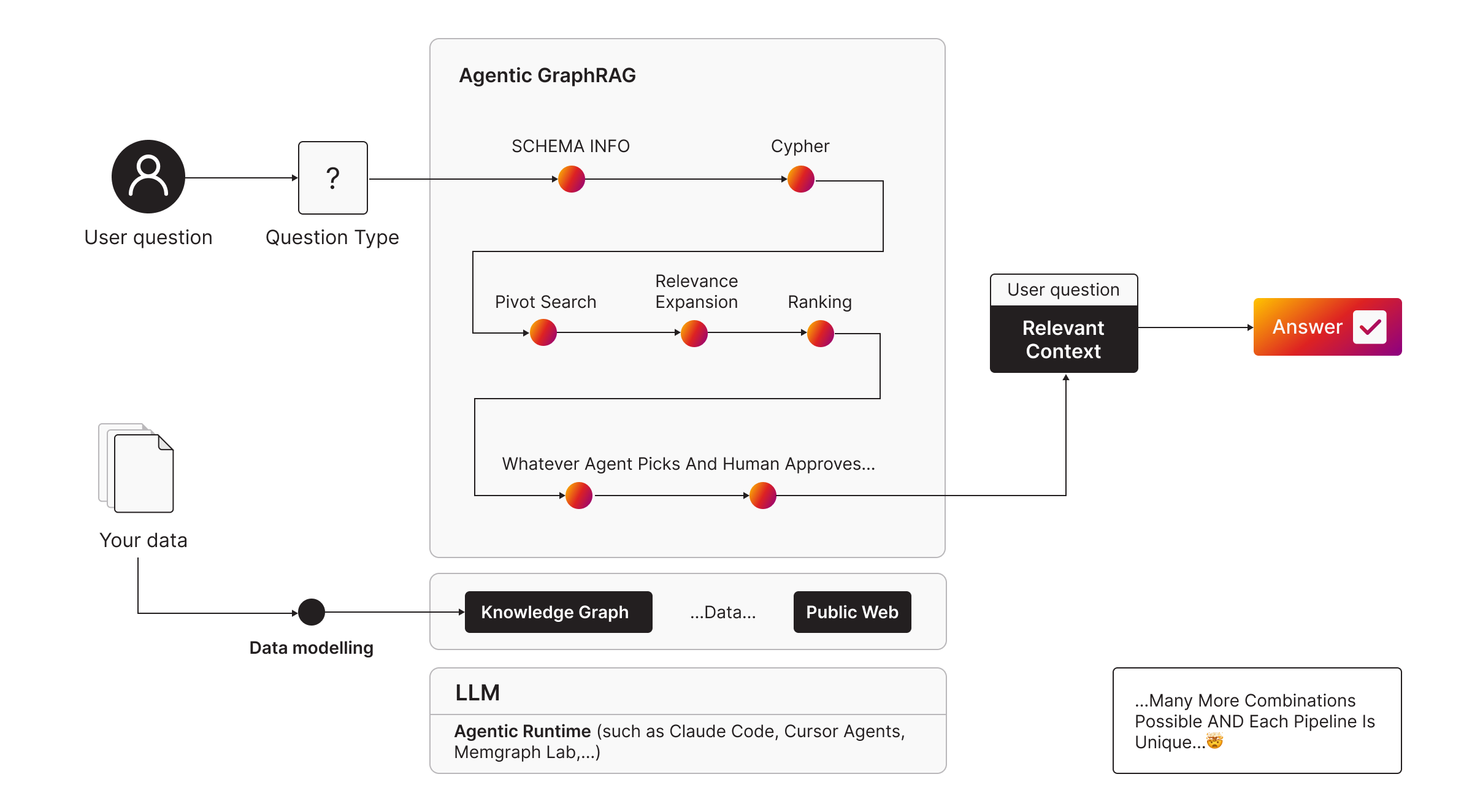
By replacing rigid, hard-coded workflows with agent-led selection of atomic pipelines, the system becomes significantly more robust. The agent dynamically chooses the retrieval approach based on the specific question type and reasoning logic.
Learn more: Agentic GraphRAG
Key Takeaway 6: Practical Demo: The GitHub Issues
Marko showcased a demo of the approach on Memgraph’s own GitHub issues.
He imported 500+ issues, then connected them not only by labels but by RelatedTo edges derived from entity extraction over titles and descriptions using unstructure2graph RAG tool.
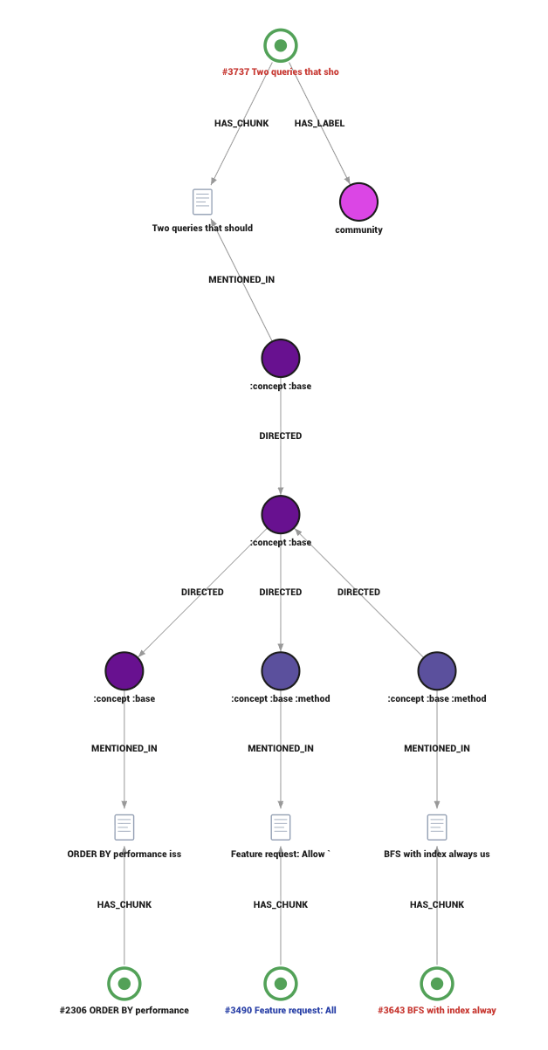
This is the difference between a taxonomy and a context graph. Labels help you group issues. Relationship edges let you traverse and discover what is actually connected.
The session then showcased 3 patterns:
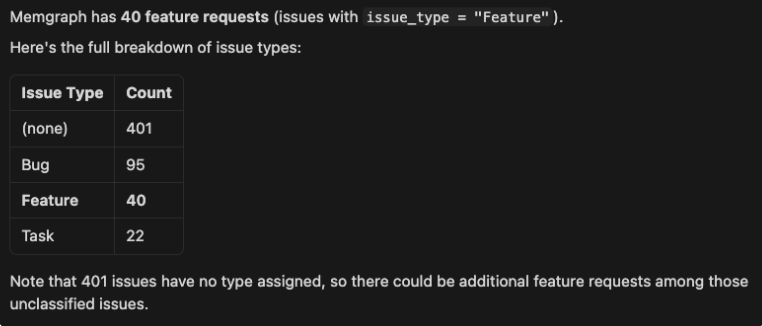
Pattern 1: Analytical
Question:
Using the @experimental/pm/skills/memgraph-product-manager/SKILL.md, how many feature requests Memgraph has?
Reasoning / Agentic Runtime Steps:
SHOW SCHEMA INFO;
MATCH (i:Issue)
RETURN i.issue_type AS issue_type,
count(*) AS count
ORDER BY count DESC;
Output:
Pattern 2: Local
Question:
Using the @experimental/pm/skills/memgraph-product-manager/SKILL.md answer the following question: under PR 3103: memgraph/memgraph serialization errors during concurrent edge write don't happen any more, what are the related github issues that should be updated or closed, do we have to communicate change to the specific community members?
This is where the workflow becomes concrete. The PR data was not present in the dataset, so the runtime pulled missing PR data from GitHub, then combined text search, embeddings and vector search, traversal for expansion, and schema introspection where needed.
For full reasoning / agentic runtime steps, watch full session recording here.
The outcome surfaced older community issues likely impacted by the fix, including issues that were never linked to the PR and never closed. This is exactly the kind of work that gets stuck in backlog limbo because the search surface is terrible.
Pattern 3: Global
Question:
Where are Memgraph’s blind spots?
Reasoning / Agentic Runtime Steps:
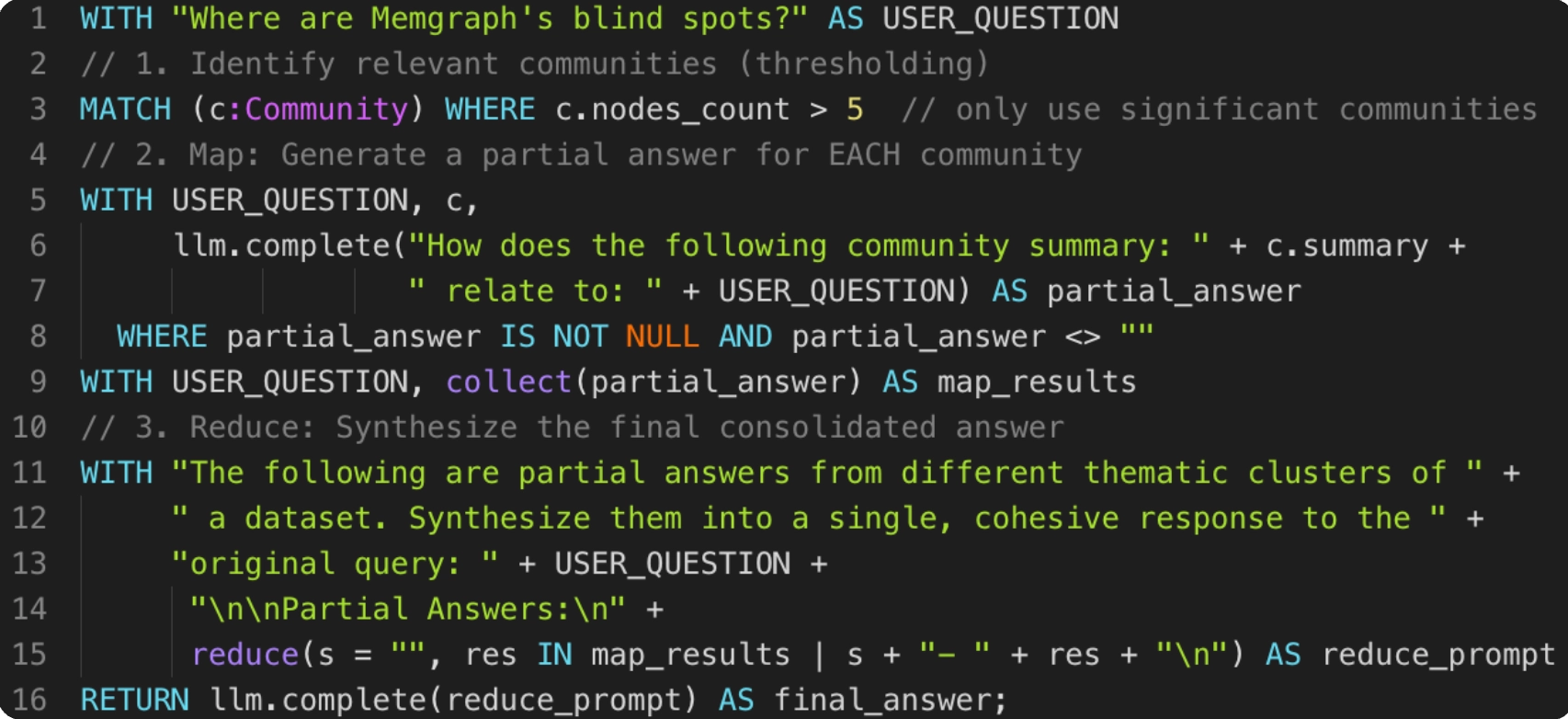
For this, he computed communities and summarized them, evaluated them against the question, then synthesizes a final answer.
Themes that showed up included correctness and crash risk, planner inefficiencies, memory safety, and observability.
Atomic GraphRAG Future Roadmap
The session closed with a quick look at what is coming next:
- Server side parameters in 3.9 for centralized configuration
- Better default embeddings
- Composable show schema info so schema does not overflow the prompt
- GNN support as a direction, including PyTorch Geometric and TensorFlow GNN
- Deeper skills integration into Memgraph Lab
Wrapping Up
If you only skim a recap, you miss the mechanics. Watch the full session here!
In the recording, pay attention to how the query pattern changes between analytical, local, and global questions. Watch where schema introspection is used and why. Notice what the runtime returns to the model and what it refuses to return.
If you build GraphRAG systems and you are tired of pipeline sprawl, explore Memgraph’s AI Ecosystem and our AI Toolkit. For those interested in Skills, here’s Memgraph’s Skills Repo.
Q&A
Here’s a compiled list of the questions and answers from the community call Q&A session.
Note that these are paraphrased slightly for brevity. For complete details, watch the full community call recording.
- I've had issues with Text2Cypher hallucinations, where the model makes up nodes or relationships that don't exist. Have you tried using constrained decoding to force the model to stay within the actual database schema?
- Constraint decoding was not tried. However, you can make
Show Schema Infocomposable so schema can be filtered when it is too large. Or you can narrow down the relevant parts of the schema, potentially by running GraphRAG over the schema graph, then instruct the model to only use what exists in the schema. Plus, composable schema output would likely help the agentic runtime.
- Constraint decoding was not tried. However, you can make
- How are the credentials managed? For instance, If there are multiple environment variables, how do you compare data integrity across environments for QA use cases?
- Fewer components makes security easier to control. MCP has a security stack, and you can enforce access control at the database layer using label based or clause based access control so query execution controls who can see which parts of the graph.
- What about the GLiNER 2 model for entity extraction, JSON schema building, and formatting in one pass. Would it be interesting to use with Memgraph.
- It was not tested. However experiments with multiple approaches in Unstructured2Graph were conducted, including classical NLP tooling and LLM based extraction, and concluded that large LLMs performed best for complex domains such as legal and accounting text. There is definitely a tradeoff between accuracy, cost, and speed. On schema, you cannot fully define the schema upfront for an entity graph because you do not know the entities before extraction. You build first, then reconcile later. That reconciliation can be human reviewed or handled in an agentic loop.