
Memgraph 3.8 is Out: Atomic GraphRAG + Vector Single Store With Major Performance Upgrades
Memgraph 3.8 is out and it’s a big one for anyone running in production.
If you run Memgraph on a high-core-count server, you should see those cores doing real work. If you use vector embeddings, you should not pay twice in memory. And if you build GraphRAG, you need flexible, cost effective context generation that can tailor retrieval to each prompt.
Memgraph 3.8 supports those three goals with:
- Atomic GraphRAG: for flexible, one-query context generation at scale.
- Single Store Vector Index: lower TCO by cutting vector memory overhead.
- Parallel Runtime: for multi-threaded query execution.
- Concurrent Edge WRITES on Supernodes: to speed up ingestion on high-degree vertices.
Let’s take a closer look at what each feature brings.
Atomic GraphRAG: One-Query Execution at Scale
GraphRAG is one of the most practical ways to ground LLM responses with relevant context. The challenge shows up when you go beyond simple vector search. It turns into extra steps, extra services, and extra code. At scale, that overhead gets expensive fast, especially when agents start calling it constantly.
Atomic GraphRAG is Memgraph’s answer to that pressure. The idea is to make GraphRAG highly flexible across use cases with fewer moving parts and less custom code to maintain. Instead of building a custom pipeline from various existing primitives, now you use a one-query pipeline.

You can compose a tailored retrieval strategy for each prompt using Cypher and graph primitives, and keep it as a single query that runs inside the database. Here’s an example to put it into practice:
CALL embeddings.text(['{prompt}']) YIELD embeddings, success
CALL vector_search.search('vs_index', 5, embeddings[0]) YIELD d, node, similarity
MATCH (node)-[r*bfs]-(dst:Chunk)
WITH DISTINCT dst, degree(dst) AS degree ORDER BY degree DESC
RETURN collect(dst) AS prompt_context LIMIT 10;Why this matters:
- Tailors retrieval to the intent of each prompt instead of forcing one fixed pipeline.
- Express a full GraphRAG pipeline in a few lines of Cypher instead of hundreds of lines of Python for a shorter feedback and iteration cycle.
- One-query execution keeps context generation consistent and reliable with ACID guarantees.
- Captures context graphs of your company's implicit knowledge or decision traces for review and governance.
If you are building assistants or agent systems at scale, Atomic GraphRAG is about keeping context generation flexible and affordable, without sacrificing control. It is also a step toward making Memgraph an AI-native graph database, where complex RAG pipelines become simpler to ship, easier to customize, and lighter to operate.
Join Marko Budiselic (CTO, Memgraph) for a Community Call introducing Atomic GraphRAG on February 17th to learn how you can execute an end-to-end GraphRAG retrieval pipeline as a single Cypher query inside Memgraph.
Explore: Memgraph AI Toolkit
Lower TCO with Single Store Vector Index
Storing embeddings at scale gets expensive fast. The worst part is when you pay for the same data twice. Once in native storage as a property and again inside the vector index to make it searchable.
Memgraph 3.8 introduces Single Store Vector Index, which stores vectors once in the index and keeps a lightweight reference in native storage.
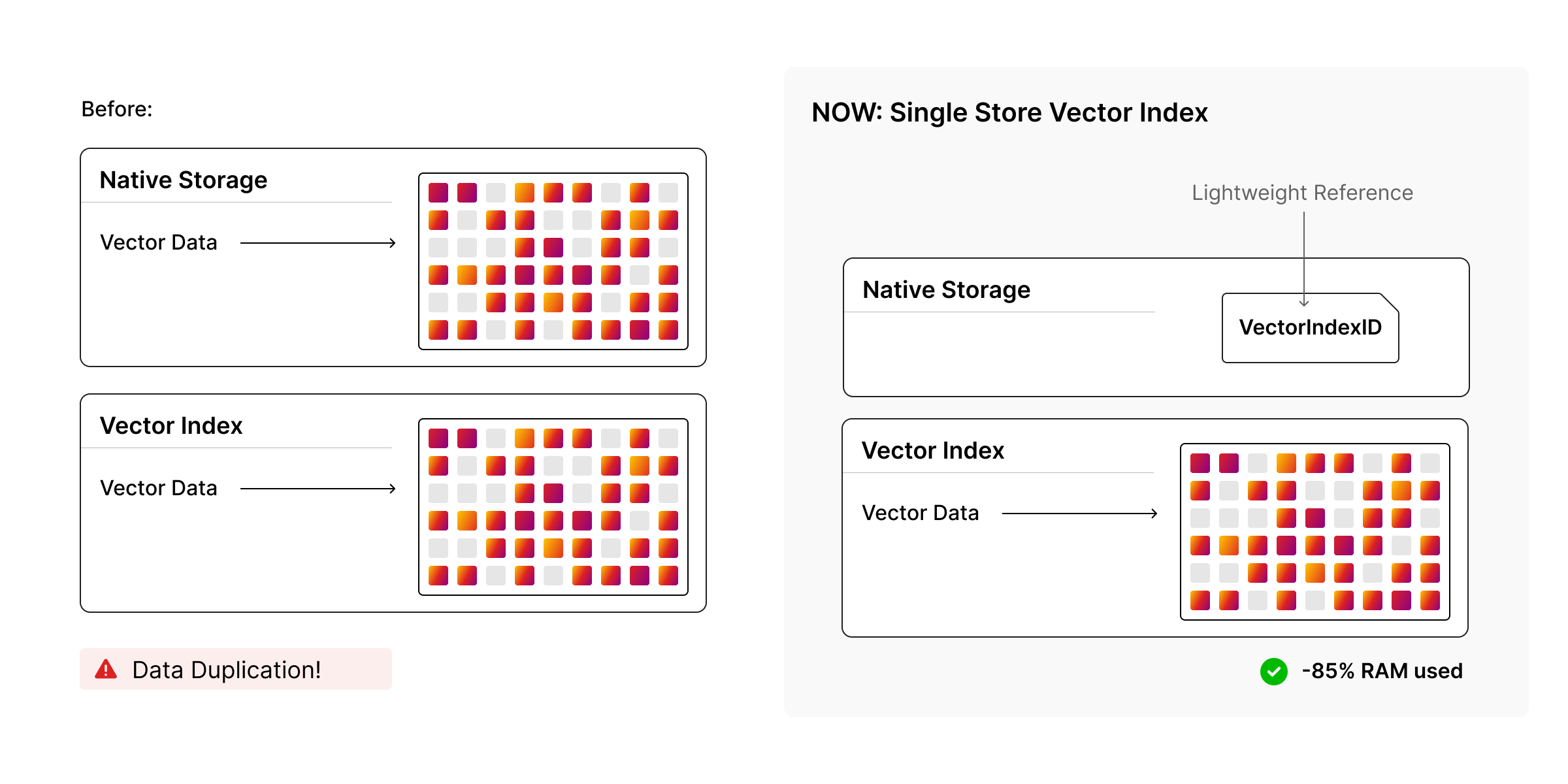
When a vector property is later accessed, for example RETURN n.embedding, Memgraph detects the reference (VectorIndexId) type and fetches the actual vector from the index on demand.
Why this matters:
- Vector memory overhead can drop by around 85%, which directly lowers total cost of ownership.
- More vectors stored on the same hardware before hitting memory limits.
- Lightening-fast vector search, without the extra overhead.
If your roadmap includes larger embedding models, more entities, or richer chunking strategies, this change reduces the TCO and gets you going easier.
Parallel Runtime for Faster Query Execution
Modern servers are built for parallel work. Until now, a single complex Cypher query could still behave like a single lane road, even on a machine with dozens of cores. That is not just frustrating, it forces teams into premature workarounds like splitting work across multiple queries or adding more machines earlier than they should.
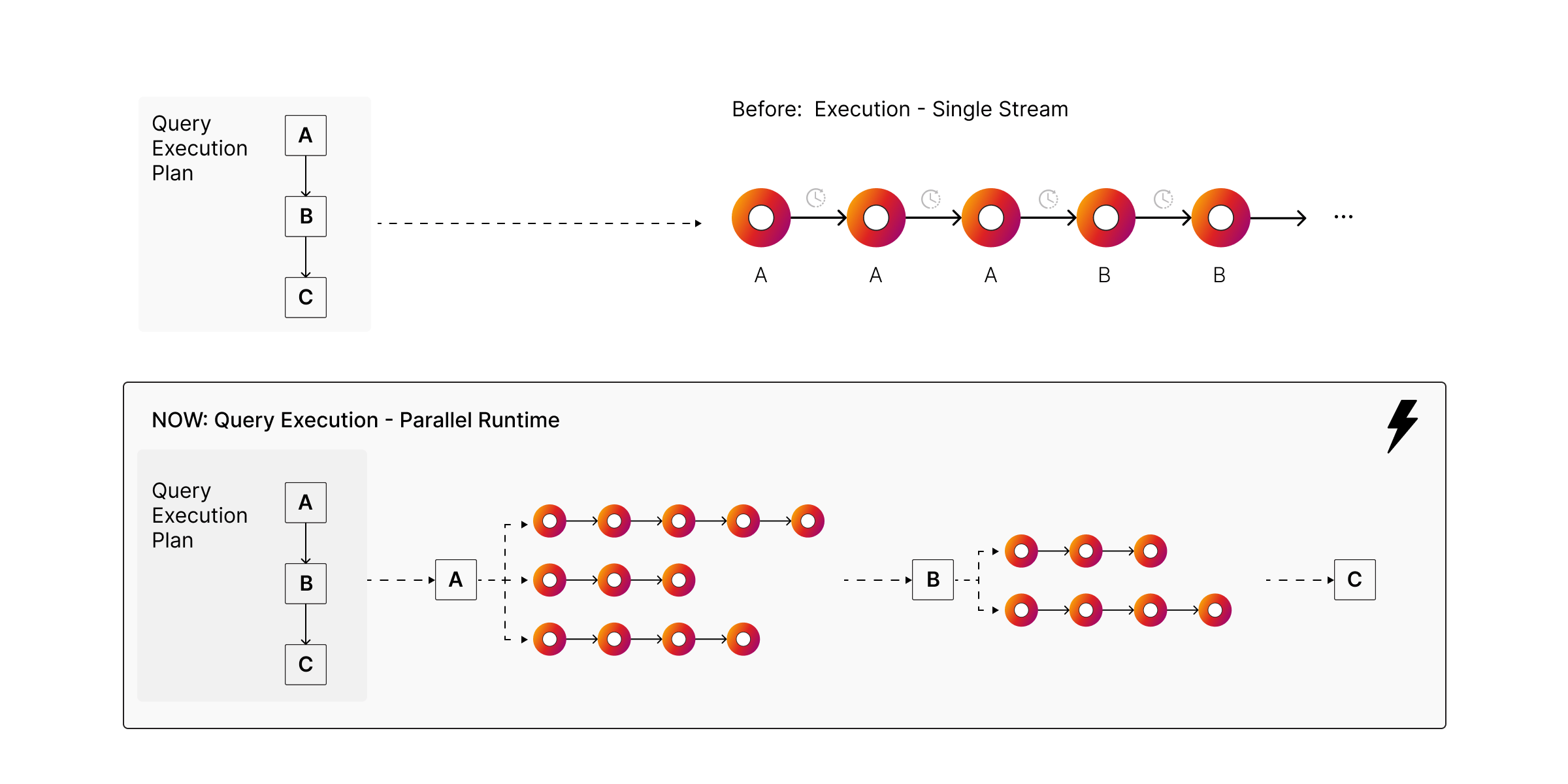
Memgraph 3.8 introduces Parallel Runtime, which allows Memgraph to execute eligible parts of a query plan across multiple worker threads. The result is faster completion for heavy analytical queries and better throughput with lower latency under load.
A simple example is counting all nodes in a large graph.
USING PARALLEL EXECUTION 4
MATCH (n)
RETURN count(n);
Parallel Runtime can split this work across worker threads and merge the partial counts.
Why this matters:
- You get more value extracted from the high-core-count servers you already pay for.
- Avoid scaling out just to compensate for single threaded query execution.
- Keep performance steadier under load even when large scans and aggregations show up.
This is especially relevant for graph wide analytics, reporting, and investigation workloads that touch large portions of the graph. Think traversal heavy questions, large aggregations, and queries that previously felt slower than your hardware budget suggested they should.
Docs: Parallel Runtime
Concurrent WRITES on Supernodes for Higher Throughput Ingestion
Ingestion pipelines can hit a bottleneck on high-degree vertices. When many transactions try to create edges on the same supernode at the same time, the database may treat it as a serialization conflict, which triggers aborts and retries.
In Memgraph 3.8, concurrent edge writes on supernodes is no longer treated as a serialization error.
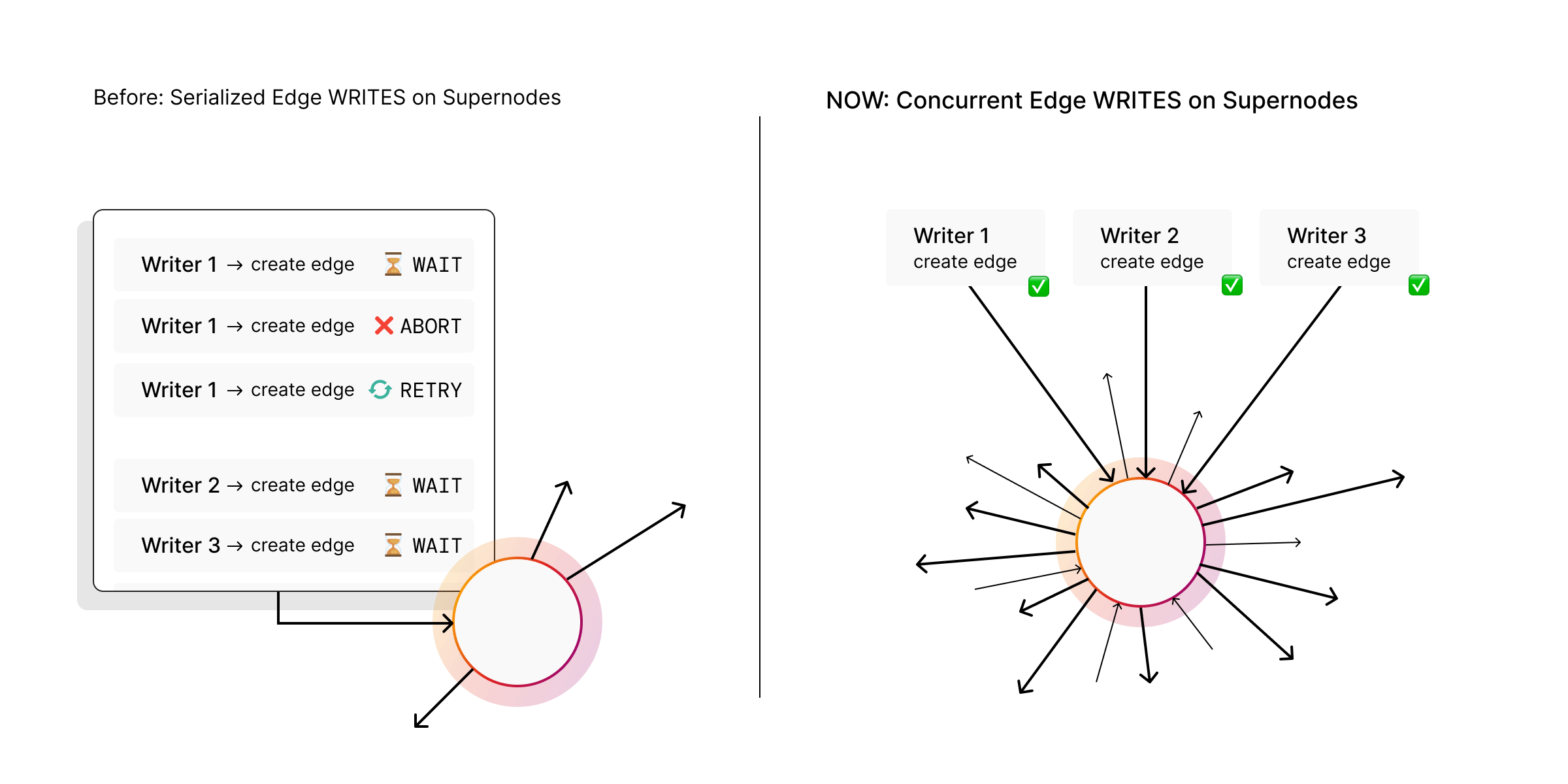
This enables truly concurrent edge-heavy batch imports and improves import speeds for high-degree vertices by reducing transaction aborts and retries.
Why this matters:
- Fewer transaction aborts and retries during edge-heavy imports, which improves end-to-end ingestion throughput.
- Better performance when many writers are creating edges around the same high-degree vertex.
- Bulk import performance is more stable in datasets with high-degree vertices.
Ultimate result is a faster ingestion pipelines for edge-heavy workloads.
Wrapping Up
Memgraph 3.8 is a performance and cost release with direct production payoff.
Parallel Runtime helps large analytical queries use the hardware you already have. Faster concurrent edge writes improve ingestion throughput when many edges are created around high-degree vertices. Atomic GraphRAG makes context generation flexible and cost effective, with one-query pipelines that can adapt to each prompt. Single Store Vector Index helps you scale embeddings without doubling your memory bill.
Upgrade to 3.8, run your real workloads, and tell us what you want to see next in parallel execution and GraphRAG building blocks.
BTW we are organizing a Community Call introducing Atomic GraphRAG to learn how you can execute an end-to-end GraphRAG retrieval pipeline as a single Cypher query inside Memgraph. Join us!