
Atomic GraphRAG Explained: The Case for a Single-Query Pipeline
Atomic GraphRAG is the idea that a GraphRAG pipeline should be expressed as a single database query, not as a chain of application steps.
This article explains why that matters. First, the post will explain what exactly is GraphRAG. Then, it will dive into the three common question types GraphRAG systems face. Finally, the article will put forward the case for a single query execution layer.
What Is GraphRAG & Why It Matters
Since you are reading this post, I assume you are familiar with the RAG, retrieval augmented generation. Briefly, RAG allows LLMs to process data not present at the training time. In practice, it lets you extract information from enterprise and private data sources without fine tuning.
People often use GraphRAG to mean a very specific workflow of RAG. For the purposes of this blog post and from the perspective of Memgraph, GraphRAG is any advanced RAG powered by graphs. Graphs are a natural model for any data or process once you move beyond basic retrieval as that’s how people naturally make sense of the world around them.
GraphRAG is increasingly viewed as a necessary evolution for high-quality RAG systems because vector-based retrieval often fails to capture multi-hop relationships in large datasets. Basic RAG can surface semantically similar chunks, but it hits a "one-hop wall" where it cannot connect evidence across documents. By structuring information as entities and relationships, GraphRAG enables corpus-level retrieval and reasoning, helping the system answer complex queries and reducing the "dropped paragraph" problem that contributes to hallucinations.
Furthermore, GraphRAG significantly enhances the reliability and explainability by providing a transparent retrieval path that can be audited, unlike embedding-only similarity scoring. In practice, the strongest approach is hybrid: vectors for semantic recall, graphs for structured reasoning and grounded context.
However, everything has tradeoffs. While many internet sources report a higher quality of GraphRAG responses compared to other RAG techniques (higher accuracy, ability to answer global queries, fewer hallucinations, and higher explainability), the main challenge of using GraphRAG is, in general, the higher cost of the entire system. GraphRAG pipelines typically requires heavier preprocessing and more query-time work (such as traversals), which increases compute and operational complexity.
Context Graphs & Decision Traces
There is another layer that becomes important as soon as agents start doing real work. Agents do not only need facts. They need the record of how decisions were made in past cases.
A decision trace captures what happened in a specific case, what context was used, what rule was applied, what exception was approved, and who approved it. Over time, those traces form a context graph. It is not the model chain of thought. It is a queryable record of decisions stitched across entities and time.
This matters here because if retrieval and reasoning steps live inside one query plan, you can return both the context and the trace of how it was assembled.
Many different Flavors of GraphRAG
It's a challenge to discuss GraphRAG because there are so many routes to take. The main challenge is that the answer depends on multiple factors:
- Source data type (unstructured vs. structured vs. semi-structured),
- Actual user intent behind the question and the question type itself,
- Evaluation objectives, and more.
Let me break things down into categories based on the prompt/query type and the required process to answer the question in a high-quality way. The three highest-level classifications are:
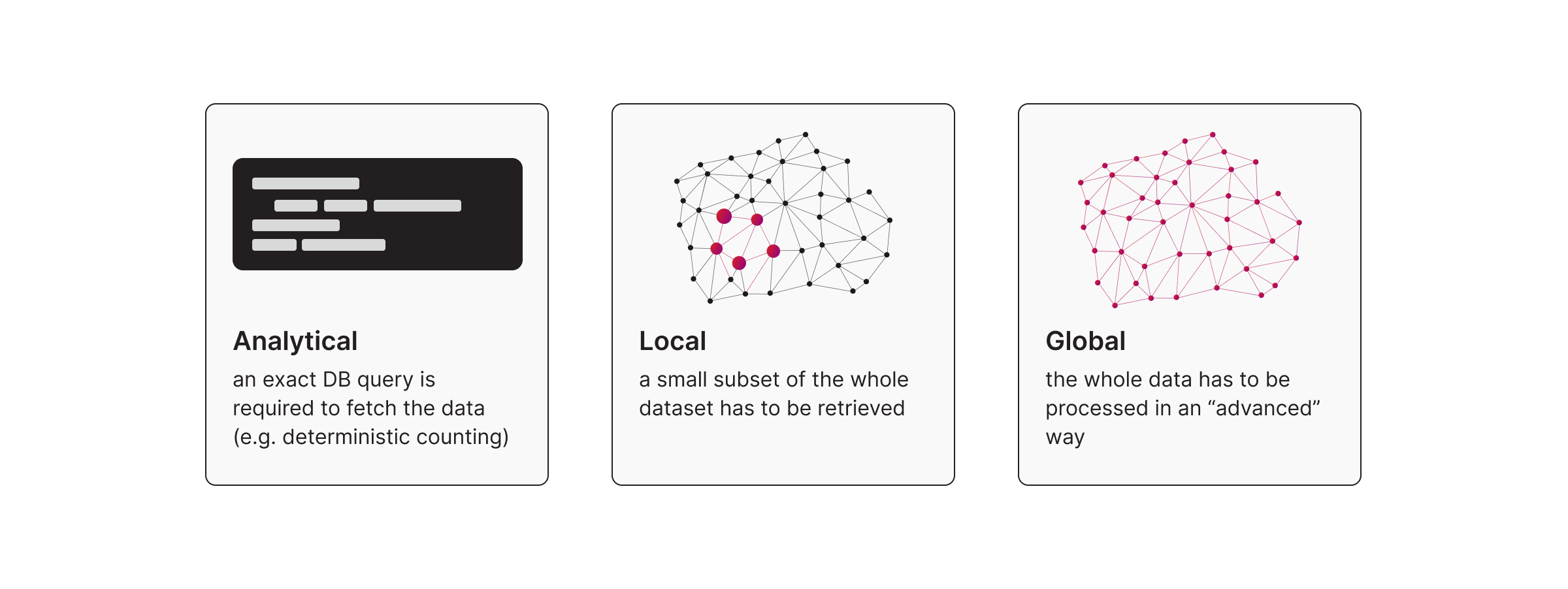
- Analytical Approach (Text-to-Cypher): addresses questions like counts, aggregates, filters, and groupings where the output is usually in tabular or scalar form. A typical example of the Analytical approach is:
- text2Cypher generates a single or a set of queries where the goal is to extract data from the dataset. It can behave like local retrieval when it targets a narrow slice of the graph, and it behaves like global when you use it for analytical aggregation over the dataset (some statistics from the dataset).
- Local Approach (Question Answering): addresses questions that target information within a small segment of the dataset; in contrast, the Global category. Typical examples of the Local approach are:
- Baseline, classic or basic RAG empowering techniques, such as chunking, embedding computations, vector indexing, and search
- All the components from the Classic RAG, plus graph elements such as Deep Path Traversals and various node ranking algorithms, including PageRank and Betweenness Centrality. Note, this is where GraphRAG comes into play.
- Instead of doing Vector or Semantic search, it's possible to do the regular text search techniques to find the most relevant entry points to find an answer for a given prompt.
- Global Approach (Query-Focused Summarization): addresses questions where the required input data spans the entire dataset. A typical example of the Global approach is:
- Microsoft's GraphRAG approach (AKA Query-based/focused Summarization) models a dataset as a graph, identifies distinct communities, and generates summaries for each. When a user submits a query, the system leverages these summaries to provide comprehensive answers regarding the entire dataset.
Common Preprocessing Work
Typically, all these approaches have some amount of work needed that can called preprocessing:
- chunking, embedding computations, vector indexing
- creating a text search index
- computing PageRank or Betweenness Centrality scores.
To get example on how to actually run all of the above GraphRAG types, please visit Memgraph’s GraphRAG documentation page.
The Real Problem is Pipeline Sprawl
Most teams start with a clean diagram and end with a distributed system.
A typical GraphRAG flow ends up looking like this.
First, you run similarity search in a vector store. Then you send results to a graph database for relevance expansion. Then you apply ranking and filters. Then you run another retrieval step. Then you assemble prompt context. Then you add retries, fallbacks, and timeouts.
That works for prototypes. It becomes painful in production because orchestration becomes the product.
The complexity also increases when you need to preserve temporal or spatial information from your dataset. This shows up with streaming data where time is essential. It also shows up when you process unstructured data sources such as books or PDFs where the surrounding paragraphs often matter.
What people call Agentic Memory has both temporal and spatial characteristics. If you ignore that, your system will look fine in demos and fail in real workflows. Each handoff adds latency and failure modes. Debugging turns into correlating logs across services. The model gets blamed, but the failures usually come from pipeline design.
So to meet the demand for flexible and cost-effective context generation, Atomic GraphRAG is Memgraph’s answer. It delivers a tailored retrieval strategy for each prompt while minimizing operational costs for both people and agents at massive scale.
The Atomic GraphRAG
Atomic GraphRAG is an execution approach where primitives like pivot search, graph relevance expansion, ranking are expressed as a single Cypher query, executed inside the database, and returned as a compact result.
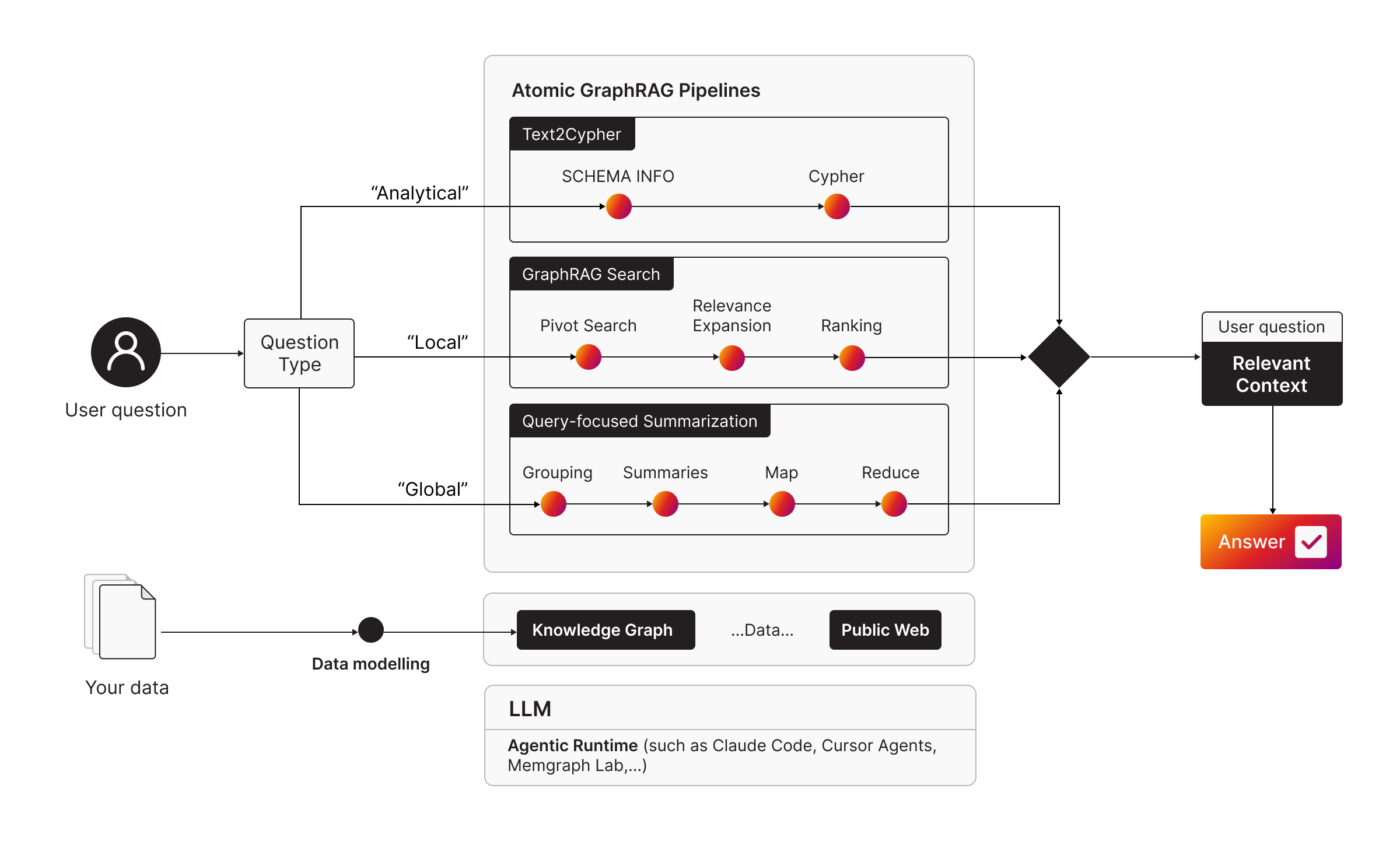
The name is intentional. If you treat the pipeline as one database operation, you reduce the number of moving parts you own in application code. You also get the standard database guarantees around execution.
Here’s an example to put it into practice:
CALL embeddings.text(['{prompt}']) YIELD embeddings, success
CALL vector_search.search('vs_index', 5, embeddings[0]) YIELD d, node, similarity
MATCH (node)-[r*bfs]-(dst:Chunk)
WITH DISTINCT dst, degree(dst) AS degree ORDER BY degree DESC
RETURN collect(dst) AS prompt_context LIMIT 10;To learn more on how to put the Atomic GraphRAG into practice, visit the Atomic GraphRAG Pipelines documentation page.
Why a Single Query Matters
If you compare Atomic GraphRAG with orchestrating a GraphRAG pipeline in application code, often Python, the reasons to push complexity into the database become straightforward.
- Cypher and GQL offer a perfect combination of primitives to implement personalized RAG pipelines for any application or agent.
- It is easier for LLMs to generate the pipeline because the code is mostly declarative. There are imperative capabilities too, which are crucial for graph workloads, but building a custom pipeline is primarily about composing existing primitives into a single query GraphRAG pipeline.
- Alternatively, writing pipelines in an application language such as Python introduces significant overhead because composing building blocks requires additional care. For example, error handling is explicit, whereas in Atomic GraphRAG it is implicit.
- Atomic GraphRAG also offers the standard database guarantees such as ACID and others.
These reasons translate into very practical wins:
- There is much less code to write and review. In many systems, a single query approach can reduce the amount of custom code by 10x. That matters because humans review less code and the feedback loop becomes faster.
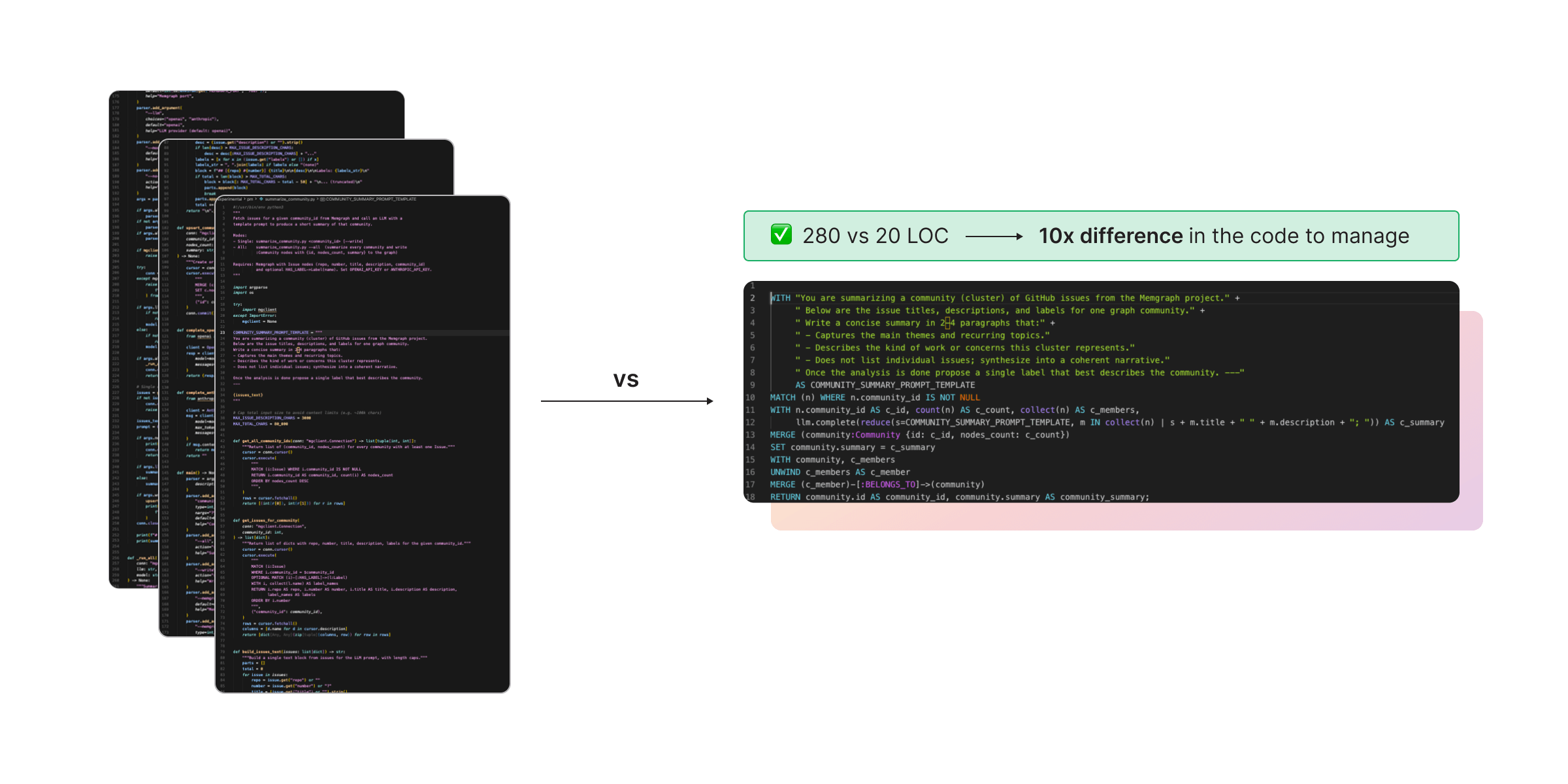
- Helps make the context smaller for LLMs and agents. Instead of shipping intermediate results between services, you return only the final payload. That reduces prompt bloat, cuts cost and latency, and usually improves accuracy because there is less room for hallucination.
- Traces you can persist for governance. A single query can return not only the final context, but also which nodes were selected, which edges were followed, and which signals drove ranking. If you store those traces per run, you can review how context was assembled and build the input data for context graphs.
Overall, combining LLM agents with Atomic GraphRAG enables any role or task to be done more effectively, because it lets people process far more data.
Agentic GraphRAG: Automating Pipeline Selection
Atomic GraphRAG solves how a given pipeline is manually executed. The next question is what pipeline you should run for a given prompt. That is where Agentic GraphRAG comes in.
In practice, you rarely know upfront which retrieval strategy will work best for a user prompt. Sometimes the right answer is a straightforward analytical query. Sometimes you need local graph search with pivot search and relevance expansion. Sometimes you need global query-focused summarization over communities.
Agentic GraphRAG uses an agent to figure out on its own the right set of primitives to get the job done (answer a question or perform a task).
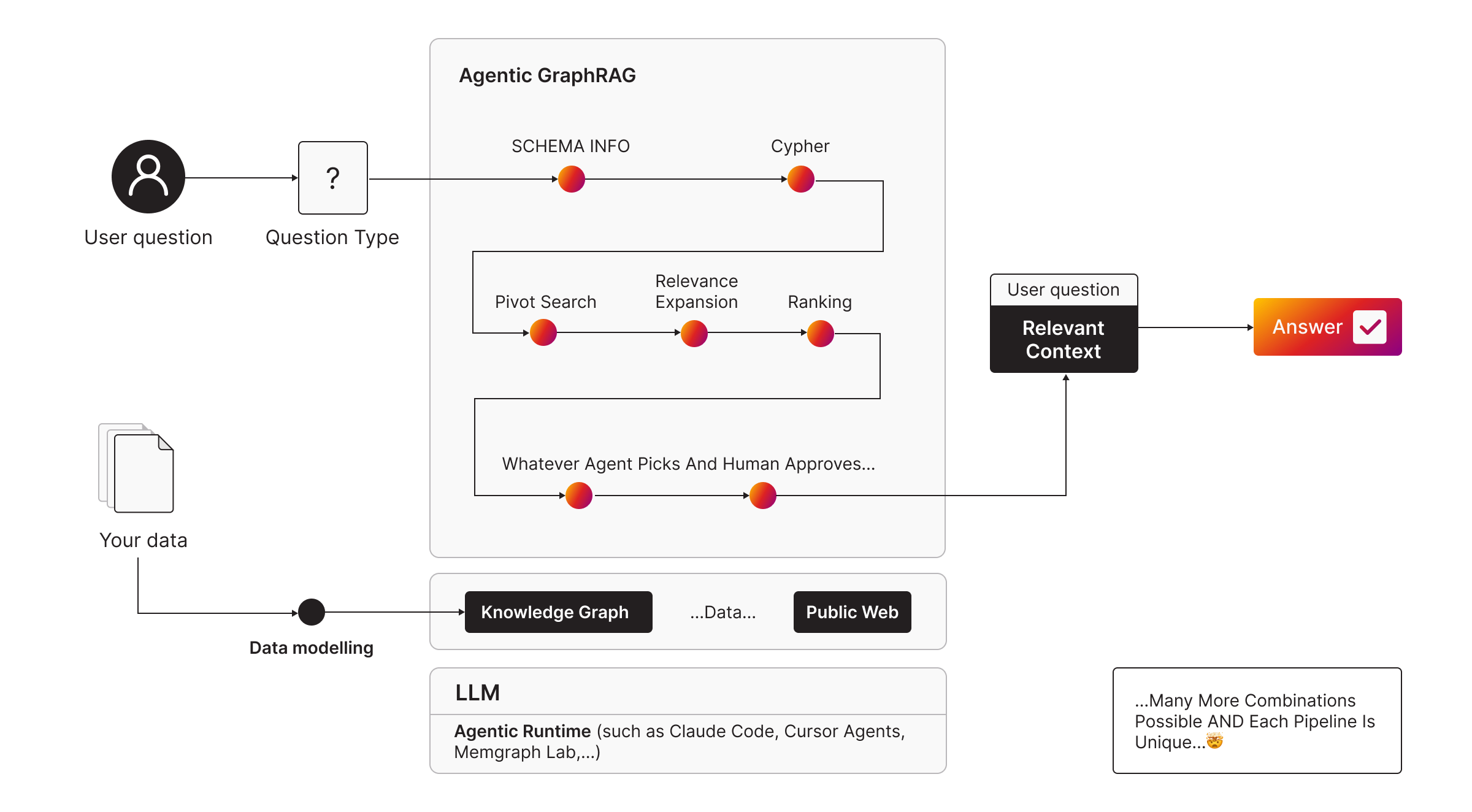
This makes the system more robust because you do not hard code one pipeline and force it onto every prompt. You let the agent choose between atomic pipelines based on the question type and the reasoning model.
To learn more, see the Agentic GraphRAG documentation page.
Building Context Graphs from Atomic GraphRAG Primitives
Atomic GraphRAG primitives also enable a practical way to build reasoning or decision traces, sometimes called context graphs. Once the pipeline is a query, you can treat its intermediate outputs as first class results.
That means you can return not only the final context but also the path of how that context was selected. Which nodes were pivots. Which edges were followed. Which filters were applied. Which signals drove ranking. Which exceptions were taken.
Those traces are the raw material for context graphs. Over time, they become searchable precedent for how decisions were made across entities and time. That is the difference between retrieval that answers one question and a system that accumulates institutional memory.
Wrapping Up
To sum it up, Atomic GraphRAG is essentially giving you bigger “retrieval leverage”. If you combine the tools right, you will be able to effectively extract all the relevant insights from your data.
I’ll leave you with the following as food for thought:

To retrieve the knowledge, but also make the right decisions for the future, it’s critical to have the right tools in place. Probably the best place to continue the journey is the Agentic GraphRAG documentation page. Happy GraphRAGing!