How Query-Focused Summarization Works in Atomic GraphRAG’s Single Execution Layer
GraphRAG questions are not all shaped the same. Some questions ask for an exact value. Some ask for the right neighborhood around a node. Others ask for something broader: themes, gaps, blind spots, or patterns that only show up when you process a larger part of the graph together.
That last category is where Query-Focused Summarization fits.
This blog focuses on the global retrieval pattern in Atomic GraphRAG. It is the pattern you use when the answer is not sitting in one node, one edge, or even one local neighborhood. You need to process a broader subgraph, group what belongs together, find out what's missing, summarize what matters, and return an answer shaped around the user’s question.
Common GraphRAG Question Types
A useful way to think about GraphRAG is to group its retrieval patterns around variouse question types. The three common question types we are currently covering are:
- Analytical approach: the answer is an exact value, row, or table result
- Local approach: the answer depends on a focused neighborhood around a relevant node
- Global approach: the answer requires broader synthesis across a larger subgraph or corpus
Those categories matter because they change the retrieval logic.
Global questions are different from the start. You are not trying to fetch one record. You are not trying to inspect one neighborhood. You are trying to surface what keeps showing up, what is missing, what is underrepresented, or what only becomes obvious when you process many related nodes together.
That is why global questions need Query-Focused Summarization.
What Is Query-Focused Summarization in GraphRAG?
Query-Focused Summarization, or QFS, is the retrieval pattern used when you need a summary shaped around a specific question rather than a generic summary of the whole dataset.
That distinction matters.
A generic summary tells you what is broadly in the data. A query-focused summary tells you what matters for the question you actually asked.
In graph terms, the pattern usually looks like this:
- load the relevant subgraph or broader graph slice
- group related nodes or communities
- generate summaries over those groups
- map the summaries back to the query
- reduce them into a final answer
This is the right approach for questions that cannot be answered by finding something specific in the dataset, but instead require reasoning across the corpus to surface what is absent, emergent, or not well covered. For instance:
- What are the common complaints among power users in the electronics category?
- Which important risks does this company’s filing fail to address compared to peers?
- What important topics in this research area are still undercovered?
- What themes keep showing up across incident reports in this product area?
- Which communities in this issue graph reveal recurring product pain points?
The answer is not one fact. It is a synthesis. That is why QFS is the global retrieval pattern.
Where Atomic GraphRAG Fits In
Atomic GraphRAG is the execution model behind these retrieval patterns.
Instead of scattering all the building blocks across external code, the idea is to build the retrieval plan as a single execution layer inside Memgraph by chaining database-side primitives together. The Atomic GraphRAG pipelineis basically a set of Memgraph tools and primitives that enables building GraphRAG pipelines as single queries.
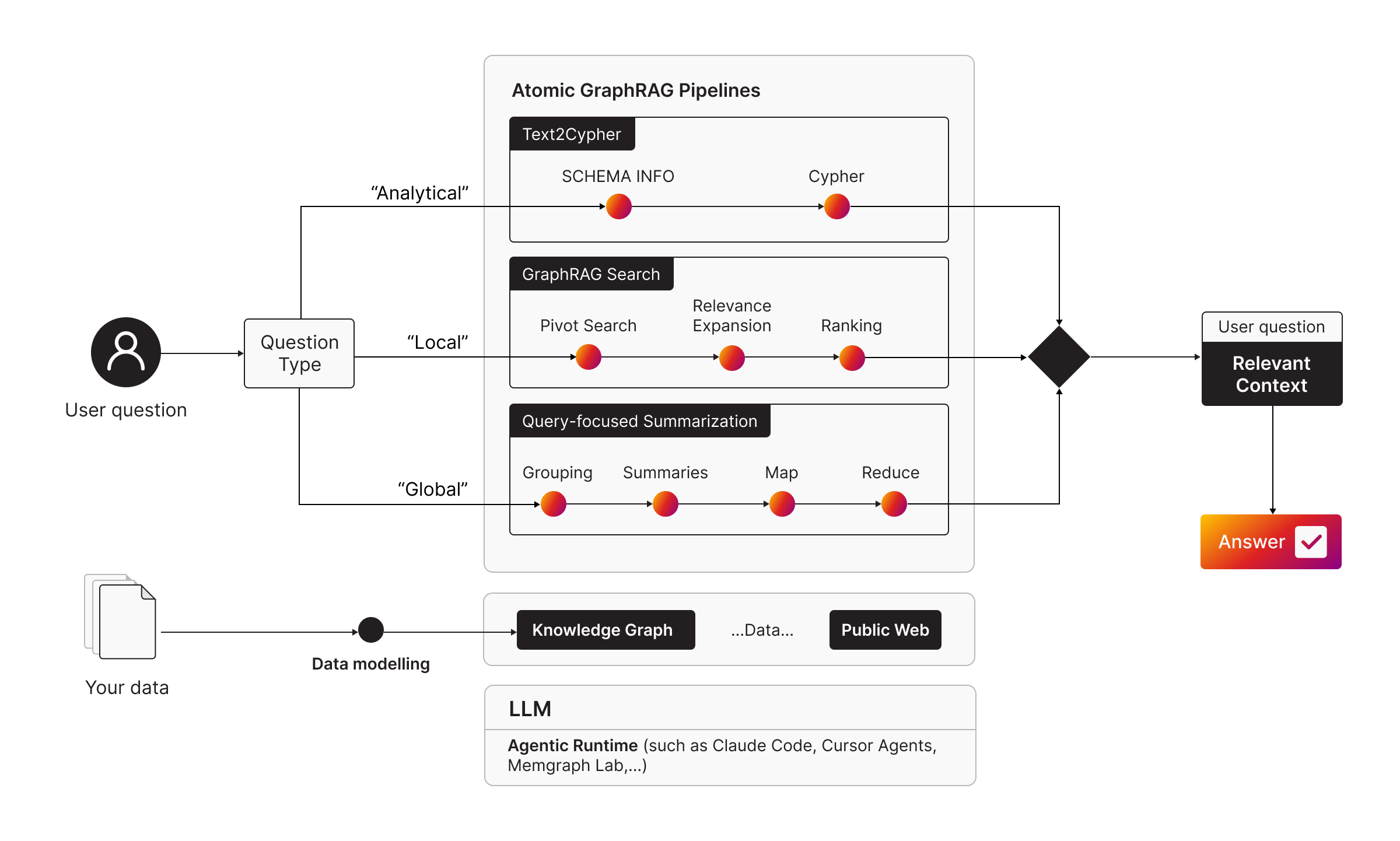
That matters even more for global questions than it does for simpler ones.
Why?
Because global retrieval usually involves more moving parts and more data. You may need to load a larger subgraph, run graph algorithms such as community detection or PageRank, generate summaries, and then compress that into a useful answer.
If that logic is spread across Python orchestration code, search services, and post-processing layers, the pipeline gets ugly fast.
Keeping it inside one query plan has a few practical benefits:
- less code to manage and review
- faster debugging and iteration
- smaller, more targeted context for the model
- less noise passed into the final answer step
In practice, that results in 10x less code to manage leading to lower hallucination risk, and faster, cheaper execution.
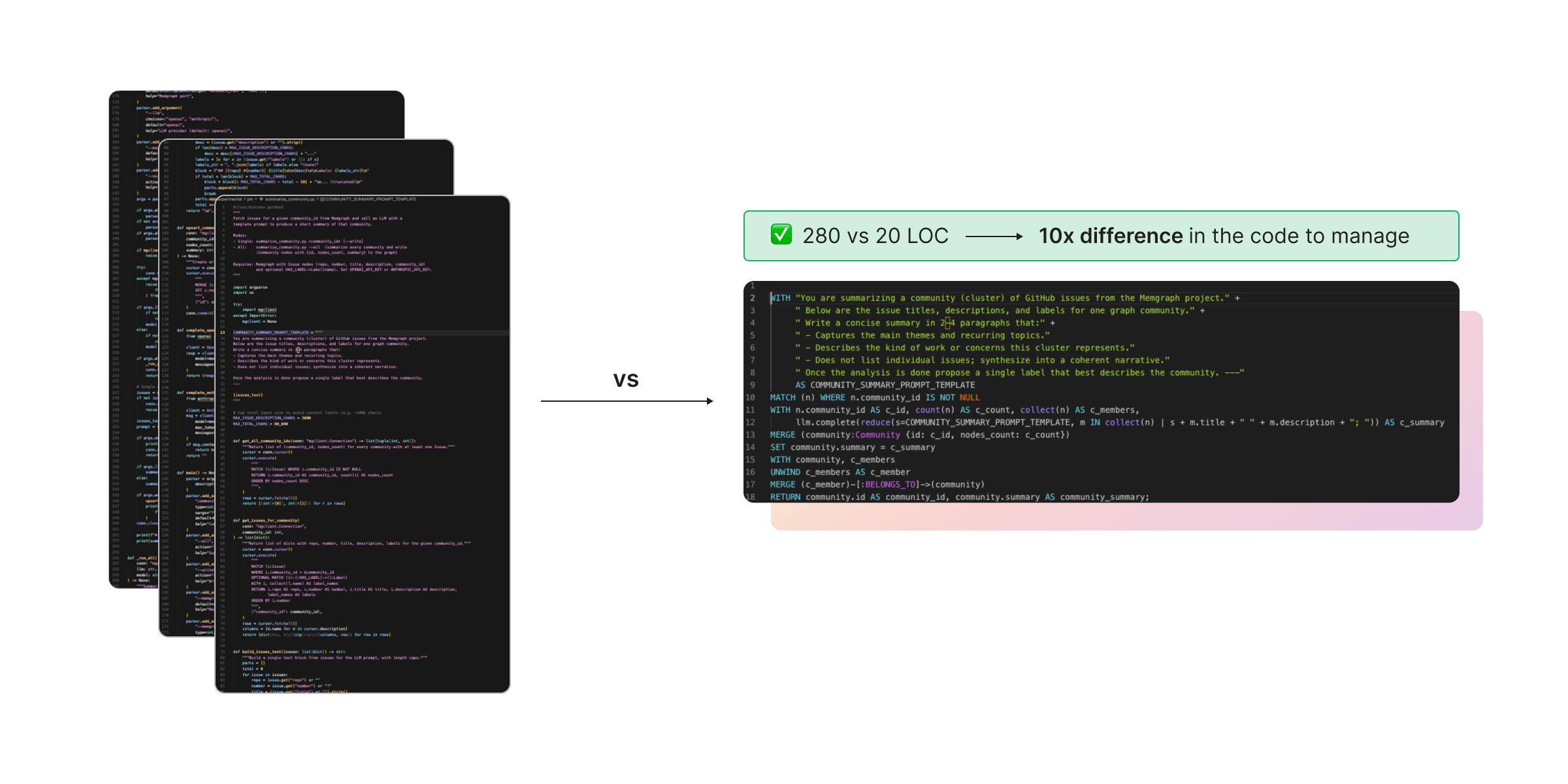
That is not just cleaner architecture. It is a practical way to make larger graph retrieval pipelines easier to build and trust.
Global Approach Example 1: Amazon Reviews Knowledge Graph
A strong global example comes from the Amazon Reviews knowledge graph.
This graph connects users, reviews, products, and parent products through explicit relationships. The demo instance is massive with about 10 million nodes, 16 million edges, and 10 GB of data.
Scenario
You do not want one product review. You want broader feedback patterns from a user segment.
This is where global retrieval starts to matter. Instead of looking up one node or one neighborhood, you want to process a broader subgraph and summarize what the group is collectively saying.
User Question
Can you calculate the PageRank on the subgraph of the
AGLQQCIS5V6EGUCS5SSNHWZHQM6Q(a user ID node) from 2 hops?
Cypher Query
MATCH (u:User {id: 'AGLQQCISSVGEGUCSSSSNHWZHOM6Q'})
MATCH p=(u)-[*1..2]-(x)
WITH project(p) AS g
CALL pagerank.get(g) YIELD node, rank
RETURN labels(node) AS labels,
node.id AS id,
rank
ORDER BY rank DESC, id
LIMIT 50;Results
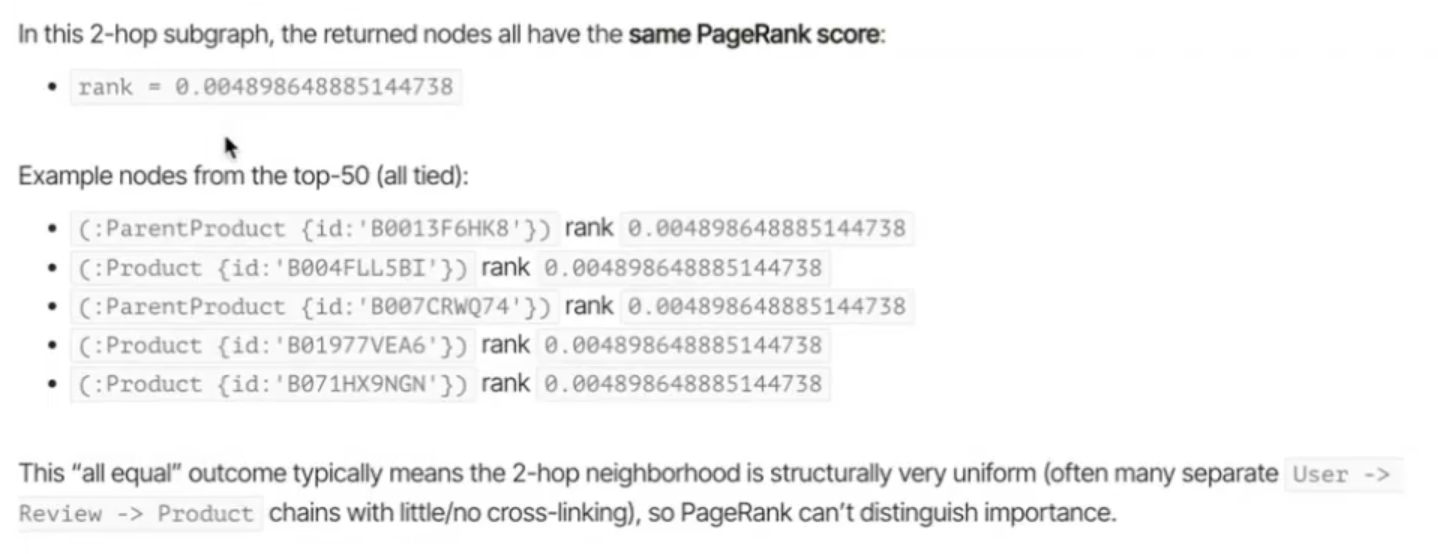
For full walkthrough, watch the full Amazon Reviews demo!
Global Approach Example 2: Memgraph GitHub Issues Knowledge Graph
A second global example comes from a graph built over Memgraph’s GitHub issues.
In that graph, issues are connected through labels, RelatedTo edges derived from entity extraction, computed Communitygroupings, and summaries over those communities.
User Question
Where are Memgraph’s blind spots?
Cypher Query
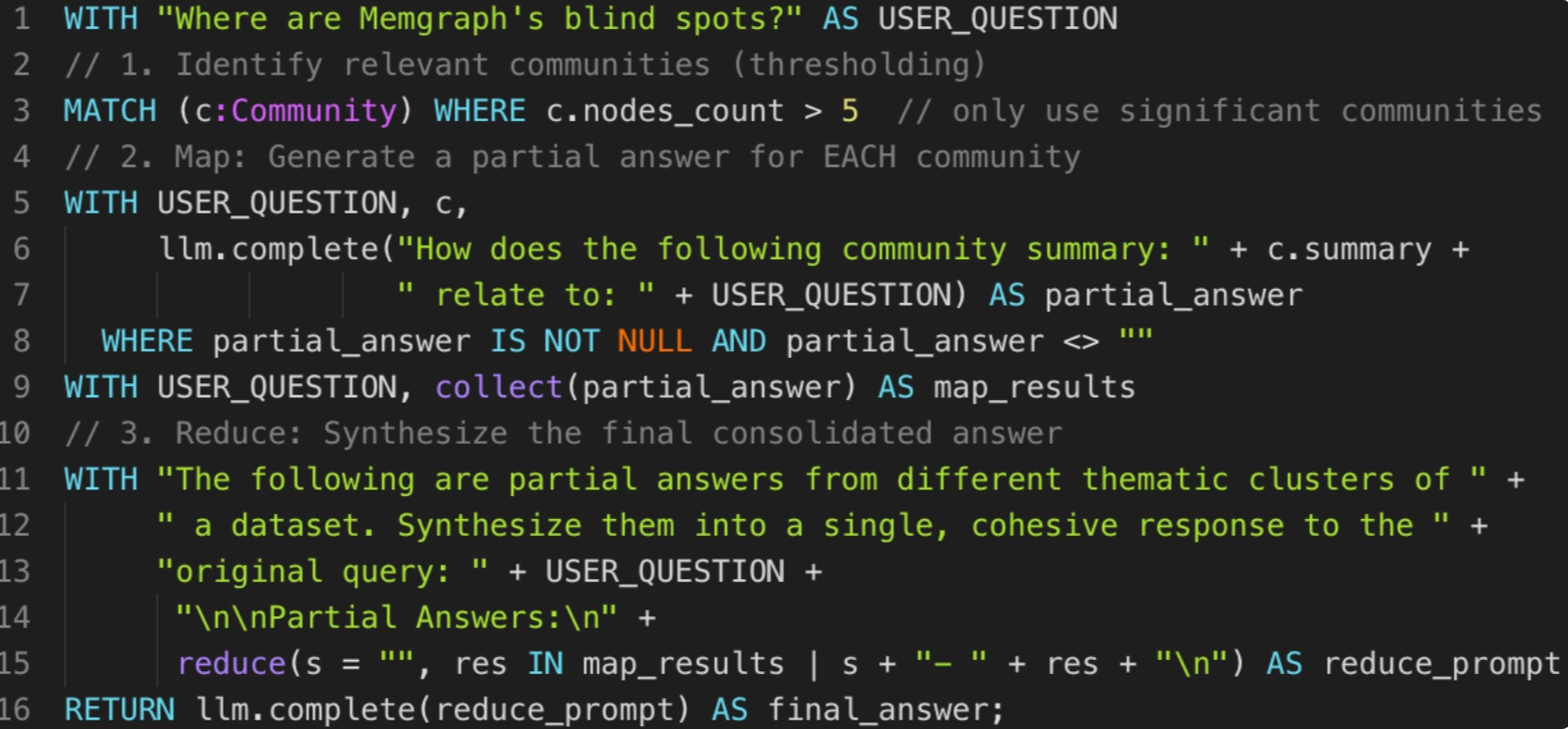
Results
The overall answer was bigger but the most important part of were the following recommendations:

For full walkthrough, watch the full GitHub Issues demo!
When Not to Use Query-Focused Summarization
QFS is not the right fit for every GraphRAG question.
If the user is asking for an exact count, a direct lookup, or a filtered list, QFS is overkill. Text2Cypher is more appropriate.
If the user only needs the immediate neighborhood around a node, QFS is too broad. Local Graph Search will suffice.
For example, QFS is not the best fit for questions like these:
- Is there a node with this identifier in the dataset?
- How many issues are tagged as feature requests?
- Which issues, labels, and entities are most closely connected to this issue?
Those questions belong to other retrieval patterns. The strength of QFS is broad synthesis, not exact querying and not local neighborhood retrieval.
Final Takeaways
Query-Focused Summarization is well-suited for the global retrieval pattern in GraphRAG. That makes it a strong fit for questions about themes, blind spots, recurring complaints, and other corpus-level patterns.
It also shows clearly why Atomic GraphRAG matters. Once grouping, graph algorithms, summarization, and context assembly all stay inside one query plan, the graph starts acting like a single execution layer for global retrieval.
If you are building GraphRAG systems and your questions keep drifting from “what is this?” toward “what keeps showing up here?” or “what is missing across this corpus?”, this is the pattern to study next.
If you build GraphRAG systems and you are tired of pipeline sprawl, explore Memgraph’s AI Ecosystem and our AI Toolkit.
Further Reading
- Blog: Atomic GraphRAG Explained: The Case for a Single-Query Pipeline
- Blog: Atomic GraphRAG Demo: A Single Query Execution
- Docs: Atomic GraphRAG Pipelines
- Blog: Memgraph 3.8 is Out: Atomic GraphRAG + Vector Single Store With Major Performance Upgrades
- Docs: GraphRAG in Memgraph
- GitHub: Memgraph AI Toolkit
- Blog: From JSON to GraphRAG: Building the Amazon Reviews Knowledge Graph