
Get Stronger Multi-tenancy, Enriched GraphRAG, and Stability for Production Workloads with Memgraph 3.10
As graph applications move closer to production, the hard problems shift from building the first workflow to keeping it reliable, secure, and manageable under real workloads.
Memgraph 3.10 focuses on that stage. The release strengthens high availability stability, enterprise multitenancy, GraphRAG workflows.
A large part of this release is about making Memgraph steadier under production pressure, from high availability coordination to memory behavior, garbage collection, storage resilience, and the engineering cleanup that keeps the system easier to maintain. On top of that foundation, Memgraph 3.10 puts more weight behind two areas that matter for modern graph applications: enterprise-grade multitenancy and GraphRAG.
Here are the most important changes and what they mean for production graph and AI workloads:
GraphRAG Enrichment
Memgraph 3.10 adds more flexibility for AI workloads that combine graph structure, vector search, text search, embeddings, graph machine learning, and schema context.
Bring Your Own Text Embedding Provider
GraphRAG systems often need different embedding providers depending on cost, latency, privacy, language coverage, or internal infrastructure requirements. Memgraph 3.10 makes that choice easier by allowing text embeddings to be computed through a remote embedding provider.
That means you no longer need to bundle an embedding model directly into the Memgraph image. Instead, teams can connect Memgraph to their preferred provider, whether that is OpenAI, Azure OpenAI, another supported provider, or an internal embedding service.
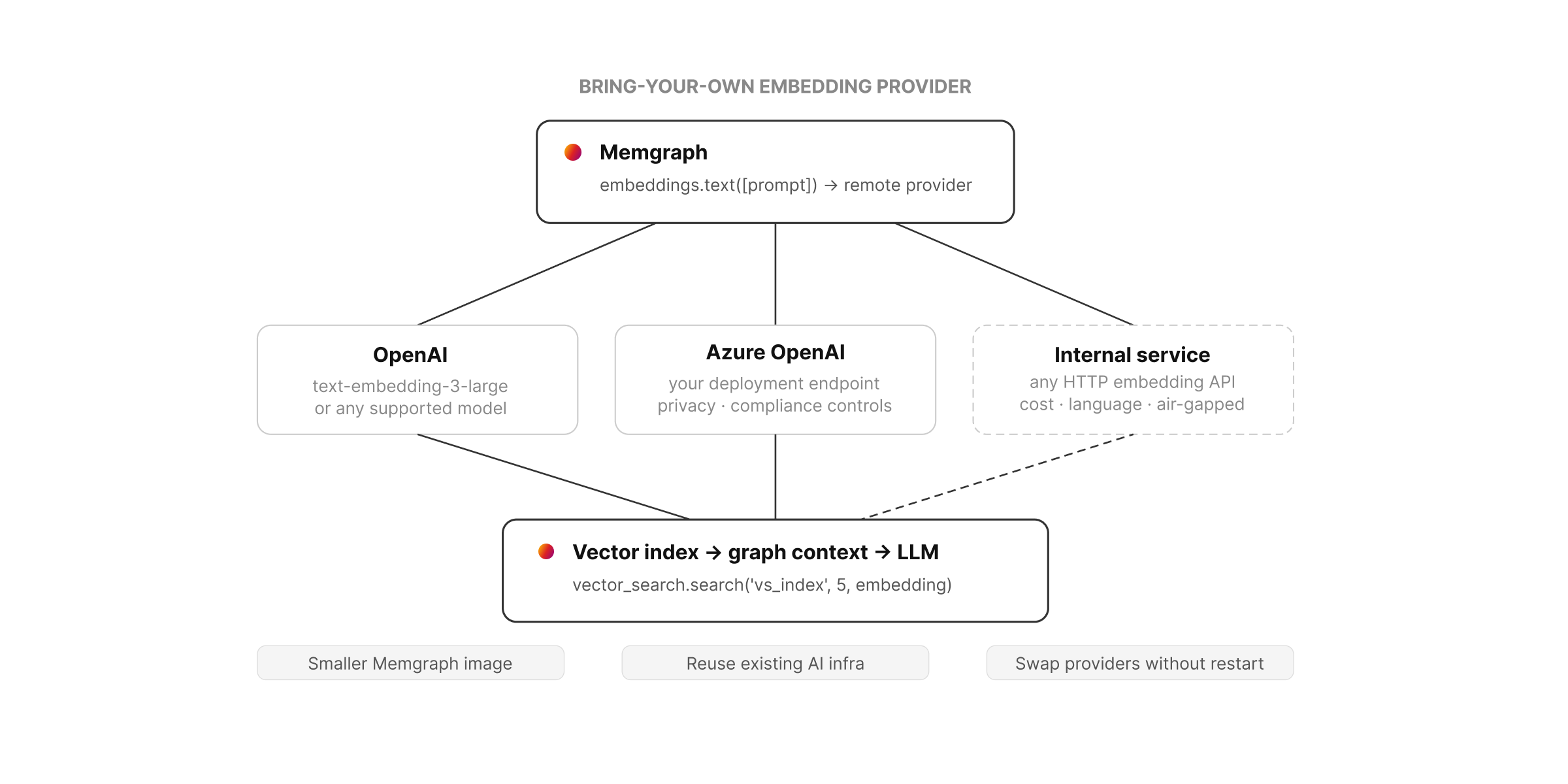
Why this matters:
- Teams can use their preferred embedding provider instead of shipping a model inside the Memgraph image.
- Memgraph images can stay smaller and easier to manage.
- Existing AI infrastructure can connect more easily to Memgraph workflows.
- GraphRAG pipelines become easier to test across different embedding providers.
Vector and Text Index Performance Improvements
GraphRAG retrieval depends on fast search across text, vectors, and graph context. Memgraph 3.10 improves both text and vector search paths.
Text search now takes a shorter path through the system, and the underlying Tantivy engine has been upgraded. Vector edge indexes now use the same single-store pattern as the rest of the vector index system, which reduces memory overhead and keeps the implementation simpler to maintain.
Dropping a large vector index is also safer under memory pressure. Memgraph 3.10 also expands mgbench coverage for vector node, vector edge, text, and text edge indexes, giving teams a clearer way to compare index performance across releases.
Why this matters:
- Text and vector search get a stronger performance foundation.
- Vector edge indexes use less memory and follow the same storage pattern as other vector indexes.
- Dropping large vector indexes is safer for production systems.
- Expanded mgbench coverage makes release-over-release performance easier to compare.
GNN Import and Export Through MAGE
Memgraph 3.10 adds a dedicated GNN import/export module to MAGE, making it easier to move trained graph neural network models in and out of Memgraph. This is especially useful for workflows like link prediction, node classification, fraud pattern detection, and recommendation systems where graph structure is part of the model signal.
Memgraph 3.10 also fixes a link_prediction module issue where ROC-AUC scores could be misleading when all labels belonged to one class. The module now reports the correct neutral score for that case instead of giving you an unreliable metric.
Why this matters:
- Trained GNN models can move in and out of Memgraph more easily.
- External ML workflows can stay connected to operational graph data.
- Predictions can be written back and queried with Cypher.
- Link prediction evaluation is more reliable in single-class edge cases.
Server-Side Descriptions
Memgraph 3.10 gives drivers and clients richer result metadata from the server. Instead of having tooling inspect individual rows to understand what a query returned, clients can now receive more complete descriptions of the result shape, including details such as column names and types. This makes it easier for tools, applications, and query interfaces to display result schemas directly.
For GraphRAG and AI workflows, this matters because applications often need to understand query outputs before passing them into retrieval, ranking, or response-generation steps. Better result descriptions make that handoff cleaner and less dependent on row-by-row inspection.
Why this matters:
- Tools can show result schemas without scanning returned rows.
- Drivers and clients get clearer metadata directly from the server.
- Applications can handle query outputs with less custom parsing.
- GraphRAG pipelines get cleaner context for downstream steps.
Dedicated AI Platform License Tier
Memgraph 3.10 introduces a dedicated AI Platform license tier for customers running GraphRAG and agentic AI workloads.
The goal is simply to keep licensing aligned with how AI workloads are actually used. As embedding-heavy workloads grow, Memgraph keeps its promise - you pay for the usage that matters. With the AI Platform license, embeddings stored in vector indexes do not count toward the license memory allocation, while graph memory remains governed by the license.
Vector index memory is still constrained by the system --memory-limit, so operational limits still apply. The difference is that embedding-heavy GraphRAG workloads now have a licensing model that better matches their usage pattern.
To upgrade and find out more, contact us.
Multitenancy Robustness for Enterprise Deployments
Memgraph 3.10 strengthens the controls needed to run multiple teams, workloads, and databases in the same environment. In a multi-tenant deployment, the difficult problems are usually isolation, predictable resource usage, access control, and operational safety. Memgraph 3.10 addresses those problems directly.
Per-Database Memory Tracking and Tenant Profiles
Memgraph 3.10 adds per-database memory tracking, so operators can identify which database is using memory instead of relying only on instance-level numbers. Memory is tracked across graph storage, vector index embeddings, and query execution
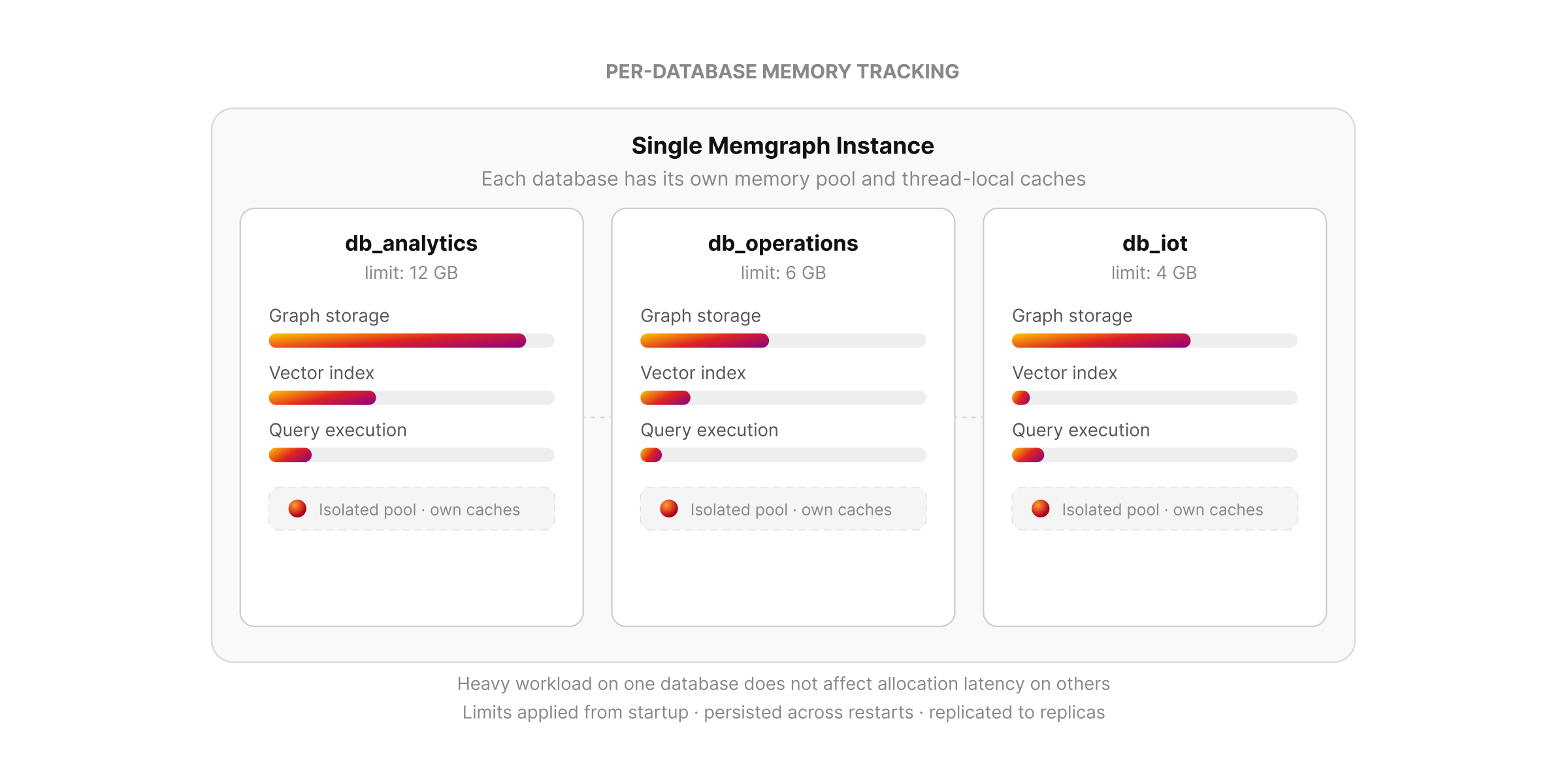
Each database now has its own memory pool and thread-local caches. That makes a heavy workload on one database less likely to affect allocation latency on another database in the same Memgraph instance.
Tenant Profiles can also be created with memory limits, attached to databases, and managed over time. Those limits are applied from the moment a database starts and are persisted across restarts and replicated to replicas.
Why this matters:
- Operators can identify which database is using memory without guessing.
- Heavy workloads are better isolated from other databases in the same instance.
- Memory limits are applied consistently across the database lifecycle.
- Multi-database deployments become easier to monitor and plan.
LBAC and RBAC Fixes
With this release, access control are more precise for multi-tenant deployments. Admins can now control read and write access at the level of individual node labels and relationship types.
The release also improves role handling across databases. Role assignments now stay scoped to the database where they were granted, which fixes cases where roles could previously leak across databases in multi-tenant setups.
Memgraph 3.10 also adds built-in default roles such as admin, readonly, and readwrite, so teams do not always need to design every role from scratch before getting started.
Why this matters:
- Admins get finer control over label and edge-type access.
- Role assignments stay scoped to the correct database.
- Default roles make enterprise setup easier.
- Multi-tenant deployments get safer access boundaries.
Kerberos SSO Authentication
Memgraph 3.10 adds Kerberos SSO authentication, allowing you to authenticate through existing enterprise identity infrastructure instead of relying on Memgraph-local credentials.
This matters for organizations that already standardize access through systems such as Active Directory or MIT Kerberos. In those environments, standalone database credentials can be a blocker because they add another identity path to manage, audit, and secure.
With Kerberos SSO, Memgraph can fit more naturally into enterprise authentication workflows while keeping role mapping connected to existing identity structures.
Why this matters:
- You can authenticate through existing enterprise identity systems.
- Teams can reduce reliance on separate Memgraph-local credentials.
- Organizations with strict credential policies have a clearer path to adopting Memgraph.
High Availability Stability and Operational Hardening
Memgraph 3.10 is not introducing a new high availability capability. It is doing something less flashy and more important for production teams. It is making HA behavior more reliable when clusters run under real operational pressure.
A large part of this work focuses on coordinator hardening, memory and garbage-collection behavior, cleaner shutdown paths, and the build, CI, and security cleanup that keeps future releases easier to ship and maintain.
Coordinator Hardening and Reconciliation
Memgraph 3.10 strengthens how coordinators manage the cluster and recover from failure modes. Operators can now change failover timeouts and health-check frequency at runtime instead of redeploying configuration. Coordinators can also run system inspection commands directly.

This makes coordinators more useful during troubleshooting because operators can inspect cluster state without jumping between separate data-instance sessions. The release also improves the reconciliation loop that helps the cluster recover when something goes wrong.
Plus, coordinators have been tightened into a cleaner orchestration role. Since coordinators do not store user data, snapshots and startup data-loading flags such as --init-file and --init-data-file are no longer accepted on coordinators. Those workflows belong on data instances instead.
Why this matters:
- Cluster recovery requires less manual intervention.
- Runtime configuration changes become easier to apply.
- Coordinators are more useful for inspection and troubleshooting.
- Coordinator and data-instance responsibilities are better separated.
Memory Management and Garbage Collection Improvements
Memgraph 3.10 improves memory reclamation and garbage collection behavior across several important paths.
FREE MEMORY now reclaims skiplist nodes and stale index entries that were previously left behind. Aborted writes are also cleaned up more completely, so tentative index and constraint entries are removed instead of lingering as unused entries.
Garbage collection also scales better with supernodes and long-running workloads. This gives write-heavy systems more headroom before background cleanup falls behind.
Why this matters:
FREE MEMORYbecomes more useful after large workloads.- Aborted writes leave fewer stale internal entries behind.
- Write-heavy systems get more headroom before background cleanup falls behind.
- Supernodes are less likely to create garbage-collection bottlenecks.
Memgraph 3.10 also includes several smaller stability fixes across storage handling, shutdown paths, runtime behavior, and Python embedding. These changes reduce the chance that transient infrastructure issues or edge-case environments cause avoidable failures in long-running deployments.
Build, CI, and Security Cleanup
Memgraph 3.10 also includes build, CI, security, and packaging work. The release includes dependency updates for known CVEs, refreshed versions of security-sensitive packages, and vulnerability scanning improvements in CI.
It also includes build modernization, faster unit-test builds, packaging improvements, Jepsen compatibility work, and the mgconsole 1.5.2 bump. The result is a stronger release foundation, faster fixes, and more stable future releases.
Several smaller operational fixes also landed across replication, Bolt SSL reload, startup misconfiguration checks, and lower-overhead monitoring. Together, these changes make day-to-day operations less brittle.
Memgraph Lab 3.10 Release
Memgraph Lab 3.10 adds schema descriptions with query result applications. You can now add descriptions for labels, edge types, and properties in Lab. This makes schema exploration more useful because the graph structure can include human-readable context alongside detected labels, relationships, and properties.
Why this matters:
- Graph schemas become easier to document inside Lab.
- Labels, edge types, and properties can include business or domain context.
- Query result applications get clearer schema grounding.
- Teams can move from visual inspection to query design with less guesswork.
Wrapping Up
Memgraph 3.10 is a production-focused release. It improves HA stability, strengthens multi-tenant controls, adds a dedicated AI Platform license tier, expands GraphRAG workflows, and brings schema descriptions into Memgraph Lab.
The release is especially relevant for teams running Memgraph in enterprise, AI, or long-running production environments where reliability, isolation, and clearer operational behavior matter.
Before upgrading, review the upgrade notes in the LBAC/RBAC and AI Platform license sections.
Further Reading
- Docs: Memgraph 3.10 Release Notes
- Docs: Upgrade Memgraph
- Docs: Multi-Tenancy in Memgraph
- Docs: Authentication and Authorization
- Docs: GraphRAG with Memgraph
- Docs: Vector Search in Memgraph
- Docs: Graph Schema in Memgraph Lab