
What is RAG? Why It Matters & Where It Falls Short
Large language models (LLMs) have changed how we interact with information. They can write, summarize, and analyze almost anything.
However, they have one critical flaw: they do not actually know things beyond their training data. Ask them about last week’s company memo, and they’re clueless.
That is where Retrieval Augmented Generation (RAG) comes in. Instead of relying solely on a static model, RAG teaches an LLM to look up information before answering.
RAG has become the go-to approach for connecting LLMs to external data. It is powerful, but it also has blind spots. Let us understand what exactly it is!
The Core Idea: Giving LLMs the Missing Context
LLMs operate within a limited context window. They can only handle so many tokens at once, and anything beyond that gets forgotten. If you feed them too much text, they lose the thread. If you feed them too little, they hallucinate.
Read more: LLM Limitations: Why Can’t You Query Your Enterprise Knowledge with Just an LLM?
Retrieval Augmented Generation (RAG) bridges this by storing external information and retrieving only what is relevant at query time. The LLM receives the right context on demand without needing retraining. This makes RAG:
- Dynamic: Can use fresh data without model updates.
- Efficient: No extensive fine-tuning costs.
- Explainable: You can trace which documents informed the answer.
What is RAG?
In RAG, both your data (documents, images, audio, etc.) and queries are converted into embeddings which are high-dimensional vectors encoding semantic meaning.
These embeddings live in a vector database (e.g. Pinecone, Weaviate, or Memgraph’s vector index)
When a user submits a query:
- The query is turned into an embedding
- We search the vector index for nearest neighbors (i.e. text chunks most semantically similar)
- Those top chunks are appended (or injected) into the prompt context
- The LLM generates a response based on both its pretrained knowledge and that retrieved context
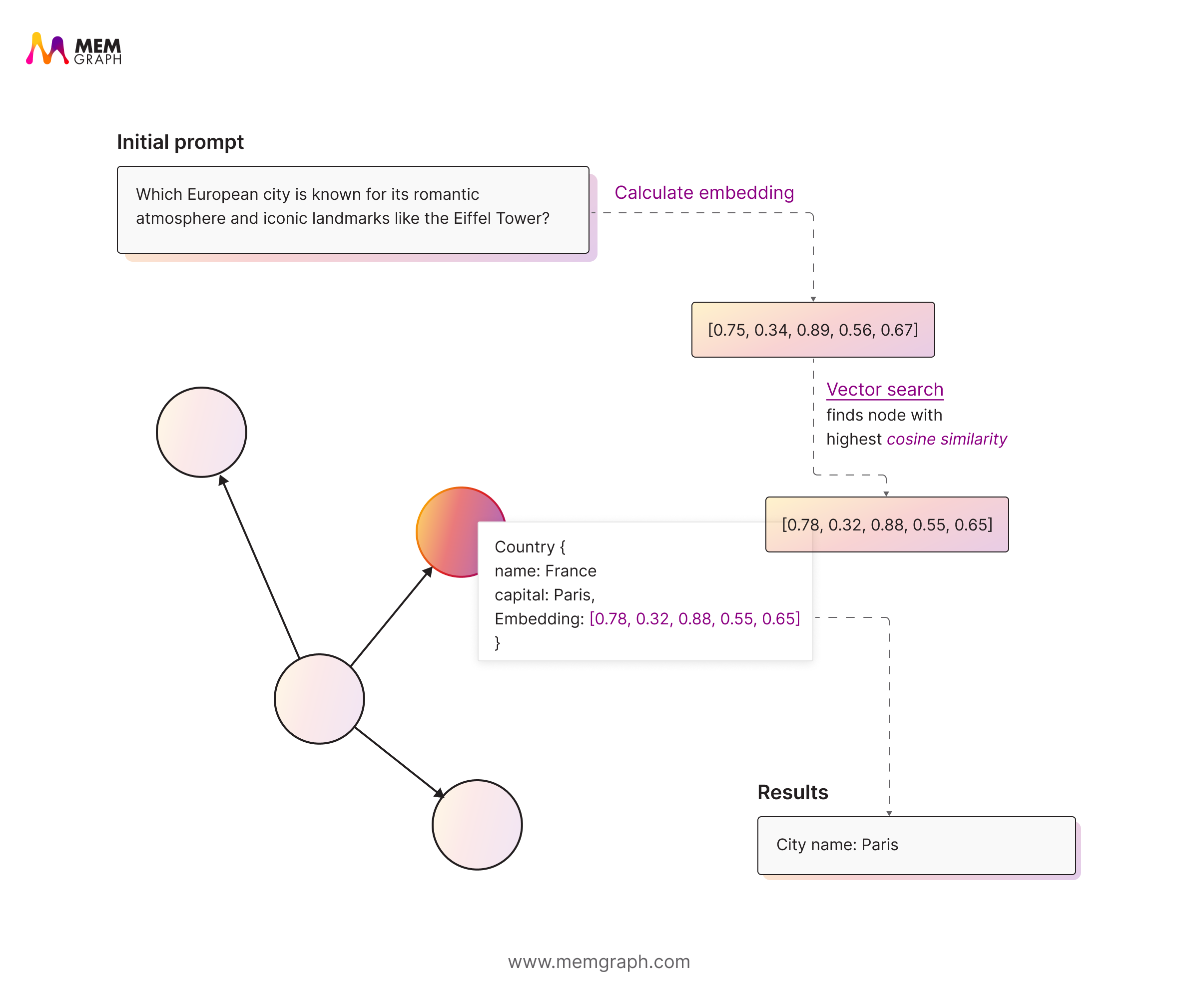
This allows matching based on similarity, not just exact keyword matches. So, it can recognize that phrases like “growth in earnings” and “revenue increase” mean the same thing even though they use different words.
Read more: Simplify Data Retrieval with Memgraph’s Vector Search and Decoding Vector Search: The Secret Sauce Behind Smarter Data Retrieval.
Why RAG Works & Why It Is Popular
RAG is powerful because it focuses on context and intent, not just surface-level word matching. By retrieving information based on conceptual similarity, it gives language models the right context to generate more accurate and grounded responses.
This makes it especially effective for unstructured data such as reports, articles, or chat logs, where meaning often depends on how ideas relate rather than on exact phrasing.
It’s also become the preferred approach for enterprise chatbots, document Q&A systems, and support assistants. It retrieves relevant content quickly, adapts to different types of queries, and scales smoothly as datasets grow.
You’d reach for RAG when:
- You need semantic search that captures meaning rather than keywords.
- Your knowledge base is unstructured or text-heavy.
- You want fast and flexible retrieval that feels natural for users.
- Queries are ambiguous or rely on synonyms.
- You need to find conceptually related information in an unstructured dataset.
At its core, RAG helps systems understand what users mean, not just what they say.
The Limitations of RAG
While RAG adds meaning to search, it misses the connections between concepts in the process. The embeddings do not capture how one thing relates to another, only how similar they are.
In complex domains like finance, this weakness becomes clear as information is not just about meaning; it is about relationships, such as who did what, when, and how those actions affect others. RAG struggles with:
- Loss of Hierarchical Structure: Chunking text breaks logical connections between sections. Context gets fragmented.
- Over-Retrieval: Similar-sounding but irrelevant chunks can appear. Semantic closeness does not guarantee factual relevance.
- Shallow Reasoning: Embeddings lack the ability to reason across multiple related facts, for instance, “A owns B, B merged with C so A owns part of C”.
- Domain Sensitivity: Jargon-heavy or multi-format documents like financial statements often confuse embedding models trained on general text.
RAG finds what sounds right, not necessarily what is right. This limitation becomes more noticeable as tasks demand deeper reasoning or an understanding of relationships between facts.
Wrapping Up
RAG is one of the most effective ways to connect large language models with real-world data. It bridges what models know with what they can learn on demand, making retrieval faster and more meaningful.
It excels at semantic search, finding information by meaning rather than keywords, and works best for unstructured data like reports or chat logs. For most production systems, it’s the backbone of reliable RAG pipelines.
Still, RAG has limits. It can lose context, retrieve irrelevant chunks, or miss logical connections between facts. Knowing these gaps helps you design smarter retrieval pipelines.
With Memgraph, you can use vector search to run semantic similarity queries and apply relevance expansion to explore related entities for deeper insight and better context.
RAG isn’t just a tool. It’s the foundation for retrieval systems that help LLMs turn data into understanding.
Further Reading
- Webinar: From Data to Knowledge Graphs: Building Self-Improving AI Memory Systems
- Docs: Vector Search
- Blog: RAG and Why Do You Need a Graph Database in Your Stack?
- Blog: Why Knowledge Graphs Are the Ideal Structure for LLM Personalization
- Blog: 4 Real-World Success Stories Where GraphRAG Beats Standard RAG