
Text Search in Memgraph: Discovering Meaning Within Your Graph Data
Ever struggled to find a piece of information hidden deep inside your data? Maybe it was a user comment, a product review, or a line in documentation that you just couldn’t recall precisely.
That’s where text search steps in. It helps you retrieve meaning, not just matching words. And when you bring that power into a graph, the results get even more interesting.
But we are getting ahead of ourselves. Let’s first understand what is Text Search, why use it with graphs, and where does it come in handy.
What is Text Search?
traditional filters or exact-match queries can only take you so far. They are of not much use when you need to find information buried in a sea of text but can’t remember exactly how it was written.
They rely on precise wording rather than meaning. That means if you search for a topic, name, or phrase variant, you might miss valuable results simply because the text doesn’t match word for word.
Text search changes that. It locates relevant information by indexing and ranking text data based on frequency and context, not just equality. Instead of checking whether text fields match exactly, it looks at how often and where terms appear, returning results that are contextually significant.
For example:
- Searching through article titles or descriptions for specific topics.
- Finding users whose bios contain certain keywords.
- Locating product reviews that mention similar issues or features.
At its core, text search turns unstructured text into searchable, indexed data. By efficiently matching and ranking results, it helps you explore graph data more intuitively, revealing insights hidden in words as well as connections.
Why Combine Text Search with Graph Databases?
Text search helps you uncover what your data contains. Graph databases help you understand how your data is connected. When combined, they let you explore both the meaning and the relationships hidden within your data.
Here’s Why That Matters
- Graph context and textual relevance: Graphs capture relationships between entities, while text search finds relevant information within unstructured text. Together, they allow you to query both structure and content.
- Unified system: Instead of running separate tools for graph analytics and text indexing, Memgraph integrates both in one engine. This keeps your data consistent, instantly searchable, and easy to manage.
Text Search + Graph Data: When Does this Combination Shine?
- Recommendation systems: Connect users, items, and descriptions to deliver results based on both relationships and text relevance.
- Fraud detection: Search through transaction notes or communication logs while analyzing how entities are related.
- Knowledge graphs and GraphRAG: Combine text search with graph context so large language models can retrieve relevant documents along with their connected entities and relationships for more accurate and explainable answers.
But text alone doesn’t tell the whole story. Most data is interconnected, and that’s where Memgraph’s built-in text search becomes powerful.
Text Search Inside Memgraph
Recognizing the powerful synergy between text search and graph databases, Memgraph has integrated native text search capabilities directly into its core. It is powered by Tantivy, a high-performance Rust-based search engine that uses the BM25 ranking algorithm to efficiently score and retrieve relevant results.
Why Tantivy?
For some Memgraph workloads, robust text search is essential, but building a new search engine from scratch would fall outside Memgraph’s core value. We needed a solution that could integrate seamlessly with our C++ codebase, operate both in-memory and on-disk, support advanced features like regex, full-text and fuzzy search, and be production-ready.
After evaluating available options, we found that existing C++ libraries lacked production readiness and feature completeness. Tantivy met all our criteria and offered a rich set of capabilities. To integrate it into Memgraph, we use cxx, allowing us to bridge Rust and C++ efficiently while leveraging Tantivy’s performance and reliability.
Some Memgraph workloads depend on advanced text search. Building a new search engine from scratch would fall outside Memgraph’s core focus, so we needed a solution that:
- integrated seamlessly with our C++ codebase
- worked both in-memory and on-disk
- supported advanced features like regex, full-text, and fuzzy search
- was production-ready.
After evaluating available options, Tantivy met all our requirements. To integrate it into Memgraph, we used cxx, allowing us to bridge Rust and C++ efficiently while leveraging Tantivy’s performance and reliability.
How Did We Bring Rust into Memgraph’s C++ Core
Integrating Tantivy into Memgraph’s C++ codebase required safely bridging two programming languages with different memory management models, type systems, and build processes.
C++ relies on manual memory management and complex type system, while Rust uses ownership semantics and a different compilation model. We needed a solution that allowed seamless integration without compromising performance or maintainability.
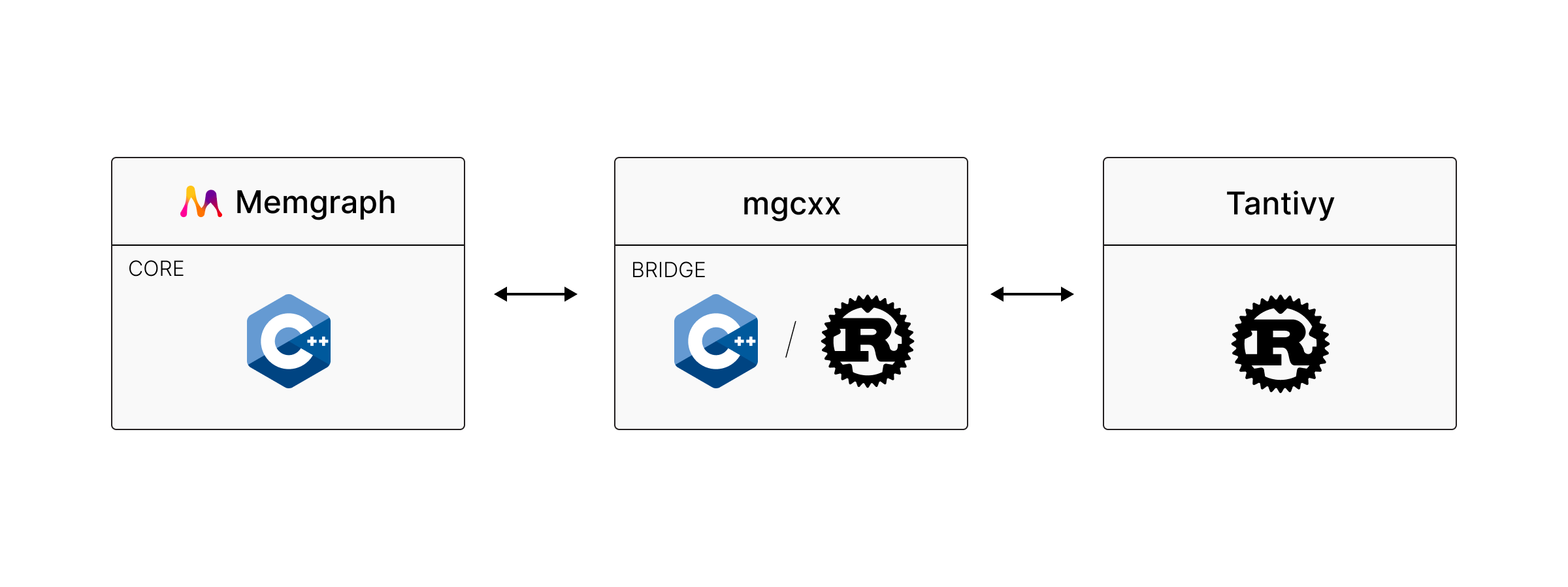
The Solution: mgcxx and cxx
We created mgcxx (Memgraph C++ extensions), a collection of C++ wrappers around non-C++ libraries. To bridge the languages, we used cxx, a safe interoperability layer between C++ and Rust. It provides type-safe bindings, zero-cost abstractions, memory safety guarantees, and seamless integration with both Cargo and CMake.
The architecture follows a clean three-layer pattern:
Memgraph’s C++ core communicates with mgcxx’s C++/Rust bridge, which then interfaces with the Tantivy Rust library.
The magic happens in the #[cxx::bridge] module. The bridge defines shared data structures and function signatures that both languages understand, automatically generating headers, implementation files, and Rust bindings to ensure type safety.
This design adds minimal overhead through zero-copy data transfer for simple types and efficient JSON serialization for complex structures. It’s also extensible, allowing future Rust libraries to be integrated in the same way so Memgraph can benefit from the growing Rust ecosystem without compromising its C++ foundation.
The Challenges
Adding text search wasn’t just about integrating a library, it required tackling key challenges to maintain durability, replication, multi-tenancy, and transactional integrity.
Transactional Challenge
The first major hurdle was ensuring that the new capability respected Memgraph’s ACID transaction model. Unlike traditional search engines that operate independently, text search in Memgraph needed to be transactional. This meant that the search results had to reflect the exact state of the database when a transaction began.
Tantivy stores pending (uncommitted) entries in an in-memory buffer and works at snapshot isolation. To make new nodes searchable, these entries must be committed to the index and flushed to disk. We optimized performance by committing changes only at the end of a transaction. This approach avoids frequent disk writes and batches modifications, making index updates faster and more efficient.
A change-tracking system records every node or edge created, modified, or deleted within a transaction. These changes were collected in memory using specialized collectors that recorded which nodes and edges needed to be added or removed from each text index. Only when the transaction successfully committed were these changes applied to the Tantivy indices and then flushed to disk. This ensures that search results always reflected the committed state of the database.
Because of this model, users must populate the index before performing searches. Searching within the same transaction isn’t possible since the index doesn’t yet reflect the changes. Memgraph remains the source of truth, ensuring that search results are always consistent with the correct isolation level regardless of the state of the text index.
Ensuring Durability, Replication, and Multi-Tenancy
Making text search durable and reliable presented some other unique challenges as well. Like graph data, text indices must survive restarts, support incremental updates, and stay consistent across replicas. Memgraph stores each text index as a complete Tantivy index on disk, managed alongside its durability system. During recovery, missing indices can be rebuilt by re-indexing relevant nodes and edges.
Text search integrates with Memgraph’s replication system too. Index creation, updates, and deletions are treated as replication events, keeping replicas synchronized and maintaining transactional guarantees even during lag or network delays. In multi-tenant environments, text search works like other indices, supporting multiple users or applications without interference.
How To Use Text Search with Memgraph
To get started, enable and configure text search, create text indices on desired node or edge properties, and query them to find relevant results.
Detailed instructions and examples are available in the Memgraph documentation for Text Search.
Bringing It All Together
Text Search in Memgraph brings the power of full-text retrieval into your graph queries, helping you explore not just how your data is connected but what it actually means. Whether you’re building recommendation systems, fraud detection pipelines, or GraphRAG workflows, Memgraph’s native text search combines precision and context in one engine.
Try it today to explore how text search helps you uncover the meaning within your graph data.