
What Is GraphRAG? A Guide to Connected Context
Have you ever asked a language model a simple question and gotten an answer that felt smart at first but fell apart on closer look? It happens all the time. The model remembers patterns but not meaning. It repeats what sounds right instead of truly understanding how things connect.
That’s because large language models don’t really know anything. They work within limits that make them forget context, miss relationships, and rely too much on surface-level text.
In this blog, we’ll break down those limits, explore how GraphRAG solves them, and look at what happens when context becomes connected.
Limitations of Large Language Models (LLMs)
Language models are text experts, not reasoning engines. They can summarize reports, write essays, and rephrase information beautifully. But when a question depends on linking facts or understanding relationships, things fall apart. Here’s why:
-
They don’t know your data
LLMs are trained on general information and cannot access your private or proprietary data. They can only guess, which leads to vague or inaccurate answers.
-
Their context window is small, in comparison to your data
LLMs can only handle a limited amount of information at a time. When your data exceeds that limit, the model loses important context.
-
They can’t reason like humans
LLMs connect words statistically, not logically. They cannot trace cause and effect or reason through multi-step problems.
-
Fine-tuning is expensive and impractical for dynamic data
Updating models with new information requires retraining, which is costly and time-consuming. For constantly changing data, it is simply not feasible.
That’s why you can get fluent, confident answers that still miss the point.
Read more: LLM Limitations: Why Can’t You Query Your Enterprise Knowledge with Just an LLM?
What Is GraphRAG?
GraphRAG adds structure to the chaos. In a GraphRAG, instead of treating text as disconnected chunks, information is stored as a Knowledge Graph, structured representations of entities (nodes) and their relationships (edges). Instead of treating knowledge like a stack of documents, GraphRAG connects information into a living network that models can explore.
It usually combines retrieval methods like semantic search or text search with graph reasoning so a model can see not only which facts matter but how they relate. A graph does not just know that “Teslaˮ and “Elon Muskˮ are related. It knows how they are related: Elon Musk → CEO of → Tesla
When a user asks a question, the system retrieves relevant text using vector similarity, then expands the search through relevant relational context in the knowledge graph. The result is context that’s complete, connected, and easier for the model to reason about.
This shift turns language models from pattern matchers into context-driven problem solvers.
How GraphRAG Works
GraphRAG combines two complementary methods: semantic retrieval and graph reasoning.
-
Retrieval
The query is first processed to find relevant entry points, known as pivots. This can involve a text search or a semantic search using embeddings, among other retrieval methods. These pivots identify nodes or documents that are most relevant to the question.
-
Graph Reasoning
From those results, GraphRAG traverses the knowledge graph to uncover connected entities and facts. This is called relevance expansion. It reveals deeper context that a simple vector search would miss.
-
Context-Augmented LLM Prompt
The retrieved and related data is added to enhance the model’s prompt. The model then generates an answer that reflects both meaning and structure.
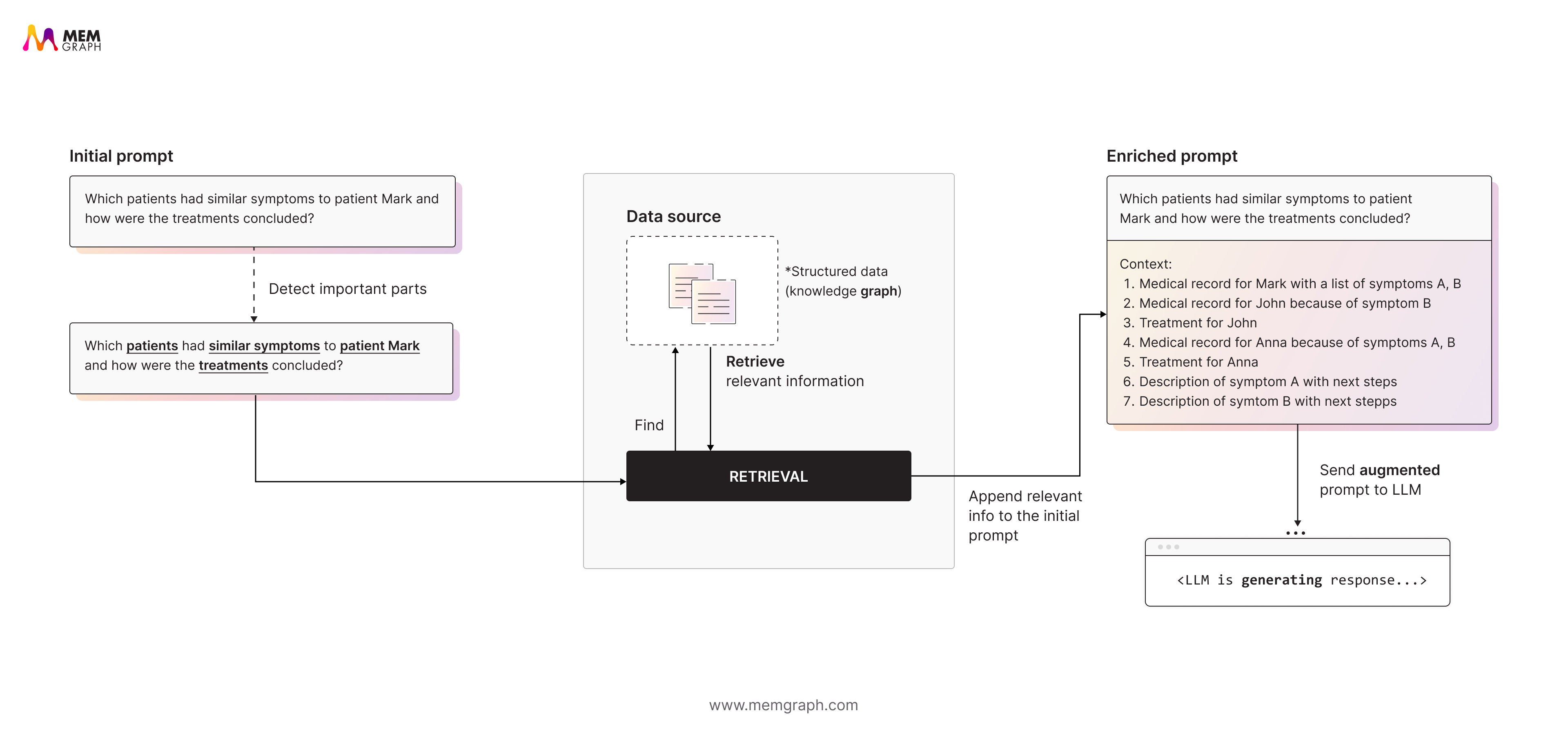
This process helps the system move beyond keyword matches toward real relational understanding.
GraphRAG in Action: Precina Health’s Real-Time Diabetes Care
Managing Type 2 diabetes involves more than monitoring blood sugar levels. It requires connecting medical records, lifestyle data, and social context in real time to understand each patient’s health journey. Precina Health’s existing systems weren’t designed to manage this level of complexity. Data lived in silos, making it difficult to deliver truly personalized and proactive care.
To solve this, Precina Health adopted a GraphRAG-powered system built on Memgraph’s in-memory graph database. This setup enables real-time processing and multi-hop reasoning across patient data. It linked lab results, treatment plans, and behavioral factors to uncover deeper insights about care outcomes.
By connecting these dimensions, Precina’s team can now detect trends faster, identify high-risk patients earlier, and deliver care that adapts to changing circumstances. The same framework supports continuous learning from new data, ensuring that the system evolves with every interaction rather than staying static.
GraphRAG has become a practical tool for Precina’s clinicians, turning fragmented information into a connected understanding of health. It goes beyond traditional analytics and supports data-driven, personalized treatment decisions.
Full success story: Memgraph and GraphRAG: Transforming Diabetes Management in Healthcare
Why GraphRAG Matters
GraphRAG bridges the gap between semantic similarity and structural reasoning. It enables:
- Multi-hop reasoning: Tracing relationships across multiple entities, such as following links from a supplier to a manufacturer to a distributor to uncover a full supply chain path.
- Context precision: Retrieving only what is structurally connected, so answers come from directly related data rather than loosely similar content.
- Hierarchical context: Understanding cause, dependency, and sequence, for instance identifying how one event leads to another or how decisions depend on earlier outcomes.
In short, GraphRAG gives LLMs context that makes sense. It connects meaning with structure so responses are both accurate and explainable.
Graphs also evolve naturally. You can add new nodes and relationships over time, allowing the system to keep learning without retraining embeddings. This makes them ideal for domains where information constantly changes, such as finance, logistics, or research.
That flexibility requires care. Building knowledge graphs from raw text requires accurate entity and relationship extraction, which can be complex and resource intensive. The process often demands careful data preprocessing to ensure that the extracted connections reflect real-world meaning rather than noise.
Memgraphʼs GraphRAG Approach
Memgraph makes the GraphRAG approach practical. It supports pivot search, where you can choose the best search strategy for the question at hand. Whether it’s a text query, a semantic search, or a graph algorithm like PageRank, Memgraph lets you mix and match approaches to extract the most relevant context.
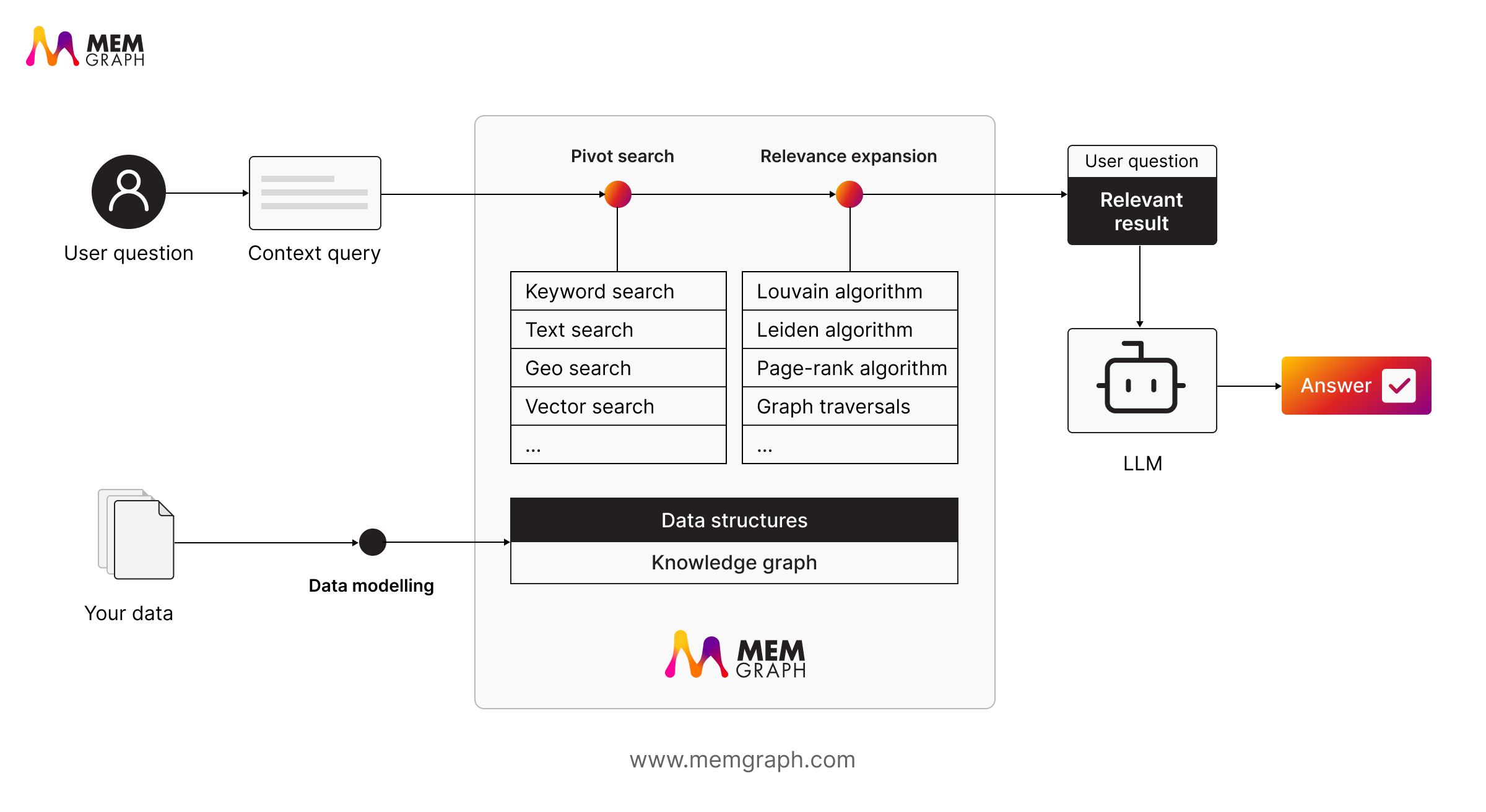
With Memgraph, you can:
- Structure and model data. Represent entities and relationships in a graph to support reasoning, retrieval, and analytics.
- Run text or semantic searches inside your graph. Memgraph supports both keyword-based text search and vector-based similarity search using its built-in indexes.
- Apply graph analytics. Use algorithms such as PageRank, centrality, or community detection to identify key nodes, clusters, or influence patterns that improve context retrieval.
- Retrieve and expand relevant information. Once you identify pivot points, traverse their neighbors, explore multi-hop relationships, and extract connected context for LLMs or other AI workflows.
- Enable real-time performance. Dynamically update knowledge graphs in production to reflect new information.
- Enhance AI applications. Provide LLMs with context-rich, precise data for better answers and recommendations.
- Use GraphChat in Memgraph Lab to query your graph data in plain English.
Memgraph stands apart by integrating graph reasoning and analytics directly into the retrieval process. The system doesn’t just find information. It understands it.
Wrapping Up
GraphRAG gives language models what they’ve always needed: context that connects.
It transforms retrieval into reasoning and information into knowledge. In domains where accuracy and relationships matter, it helps systems generate responses that make sense, every time.
GraphRAG gives large language models what they’ve always lacked: connected context. It moves retrieval from simple similarity search to reasoning across relationships, turning fragmented data into meaningful knowledge.
For organizations, this means more than faster queries. It means systems that can understand how information fits together, adapt to changing data, and support real decision-making. Whether the goal is analyzing financial risks, improving patient care, or optimizing logistics, GraphRAG provides a framework that scales with complexity rather than breaking under it.
With platforms like Memgraph, GraphRAG is not theoretical. It’s already helping teams like Precina Health connect insights in real time and transform how knowledge flows through organizations.
As data grows more connected, so should the systems that understand it. That’s exactly what GraphRAG delivers!
Further Reading:
- Blog: 4 Real-World Success Stories Where GraphRAG Beats Standard RAG
- Webinar: **From Data to Knowledge Graphs: Building Self-Improving AI Memory Systems**
- Docs: GraphRAG with Memgraph
- Blog: RAG and Why Do You Need a Graph Database in Your Stack?
- Blog: Why Knowledge Graphs Are the Ideal Structure for LLM Personalization