Single-Store Vector Index: Architecture and Memory Efficiency
Vector search at scale means millions of nodes and high-dimensional embeddings). At that point, memory quickly becomes the bottleneck. Memgraph’s vector index lives in the same storage layer as the graph. That implementation choice directly affects how many vectors you can fit in memory and how much you pay per node.
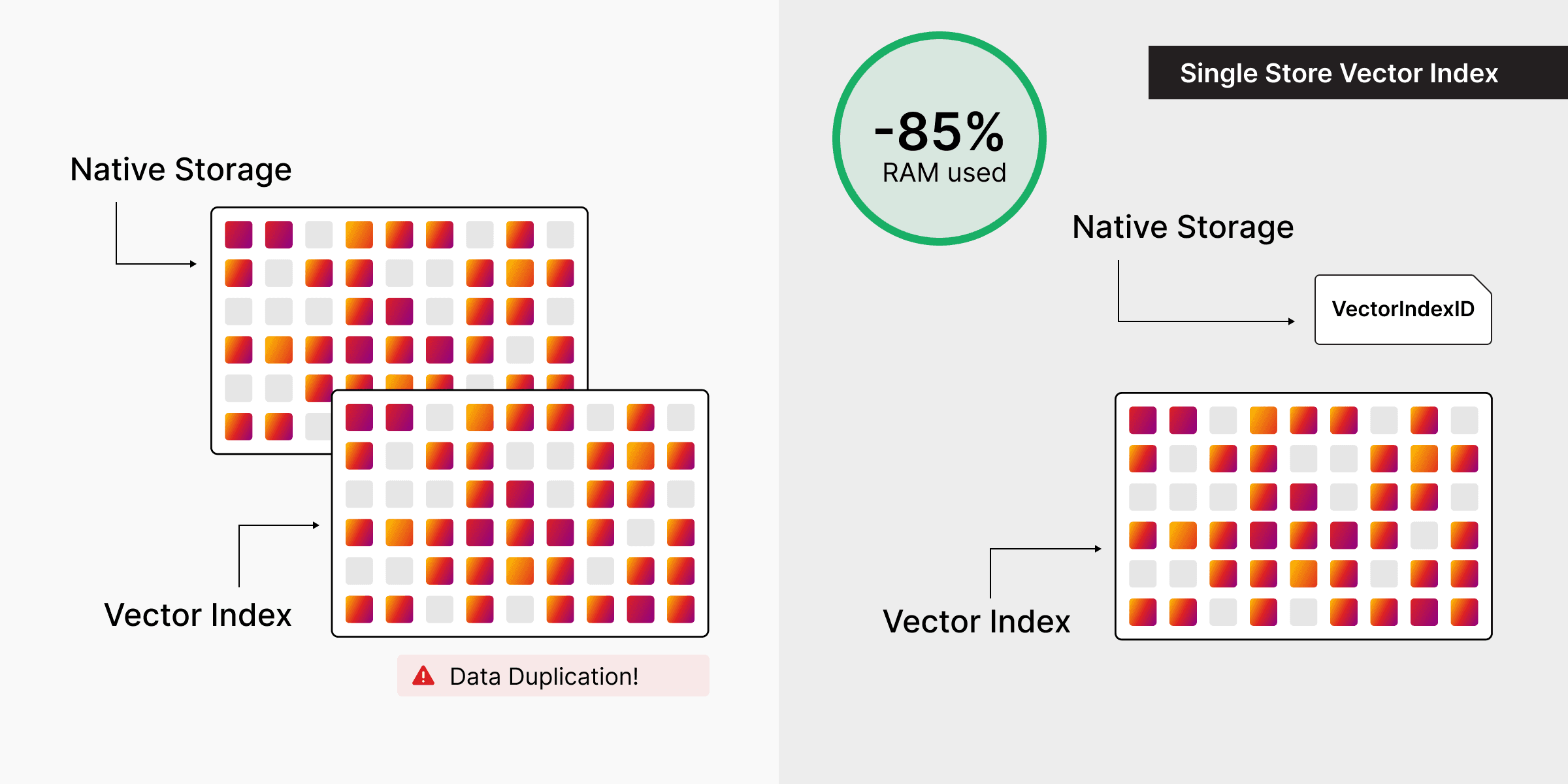
This articles reveals how the vector index is built, how it stays in sync with the graph without duplicating data, and why the latest version uses significantly less RAM for the same workload.
Single Store Vector Index
In Memgraph, the vector index is not a separate service or store. It is a first-class index type in the same storage engine that holds vertices, edges, and other indices (label, property, text).
That design has concrete implications:
- One durability and recovery story: Snapshots and write-ahead logs cover the graph and all indices. When you recover from a snapshot, vector indices are restored in the same pass as the rest of the schema and data, with no separate vector-store replay.
- One transactional boundary: Updates to the graph and to the vector index are coordinated by the same storage layer. Vector search uses READ_UNCOMMITTED for the vector index for performance (as covered in our previous blog: Simplify Data Retrieval with Memgraph’s Vector Search). All other operations and updates still use deltas, isolation levels, and the usual database machinery so the rest of the database remains consistent and correct. Abort, visibility rules, and durability all behave as expected.
- No cross-system sync: You never have to keep a graph database and a vector store in sync. The index is updated when labels or properties change, and the keys in the index are the same vertices that the query engine uses.
The trade-off is that the vector index must be as memory-efficient as possible, because it competes for RAM with the rest of the in-memory graph. The following sections describe how the index is implemented to achieve that. We will cover the USearch-backed structure, the key choice, how vectors avoid double storage, and the main memory lever: Scalar Kind.
Index Structure
The vector index is built on top of USearch, a C++ library that implements approximate nearest-neighbor search. Memgraph uses USearch’s dense index, which is a single index that holds vectors of fixed dimension with a chosen metric (e.g. L2 squared, cosine, inner product) and scalar type (the numeric type used to store each vector component).
The index structure is similar in spirit to HNSW (Hierarchical Navigable Small World). HNSW is a graph of vectors that allows fast approximate search without scanning every vector. USearch’s dense index uses an HNSW style graph over vector slots, which is why per node locking matters.
USearch fits the single store setup for several technical reasons:
- Thread safety: The library supports concurrent adds and concurrent searches, but it does not allocate or manage its own threads; it reuses the threads that call into it. Each add or search acquires a thread slot from a fixed-size pool (a ring of available thread IDs). That slot is used for per operation working memory. So, many threads can perform adds or searches in parallel without trampling each other's buffers, and Memgraph can drive parallel index build and parallel recovery by chunking the vertex set across worker threads and letting each thread call into the index. No extra synchronization is required around the index on Memgraph's side. Put plainly, Memgraph can parallelize build and recovery while keeping index side synchronization minimal.
- Fine-grained locking on the graph: The HNSW graph inside USearch is not protected by a single global mutex. Instead, each node (each vector slot) has its own lock. During search or add, a thread locks only the nodes it traverses or updates. So, different threads can traverse or modify different parts of the graph concurrently. The key-to-slot mapping and a few global fields use a shared mutex or short critical sections, but the hot path is per-node locking. That keeps contention low when many threads are doing parallel import or recovery. Basically, Memgraph uses fine grained locking so concurrent reads and writes touch only the nodes you need, not the whole graph.
- SIMD-accelerated distance computation: Computing a distance (L2, cosine, inner product, etc.) between two vectors is a tight loop over their dimensions: multiply, add, or compare components one by one. SIMD (Single Instruction, Multiple Data) lets the CPU do that work on several components at once (e.g. four or eight floats in a single instruction), so the same loop runs in fewer cycles and throughput goes up. USearch's metric layer uses the SimSIMD library when available to run distance kernels with SIMD (e.g. NEON on ARM, AVX on x86). If SimSIMD isn't available or doesn't have a kernel for the chosen metric and scalar type, the code falls back to auto-vectorization, where the compiler generates SIMD from the scalar loop using pragmas and layout. Either way, vector comparison stays fast and scales with the hardware. At a high level, Memgraph speeds up distance computation with SIMD, so similarity search runs faster on the same hardware.
A crucial design choice is what the index uses as the key for each vector. In Memgraph, the key is the vertex pointer (the in-memory address of the graph node). So the index does not store a separate identifier that you must later resolve to a vertex; it stores a mapping from vector → vertex directly.
When you run a similarity search, the index returns vertices (and distances). That avoids an extra indirection layer and keeps the index tightly coupled to the graph: every entry in the index corresponds to exactly one vertex that has the indexed label and property.
Because the key is a vertex pointer, the index does not need to store a copy of the vertex ID or other graph metadata inside the index structure. The index holds:
- The vector components
- The HNSW-like graph for approximate search
- The mapping from internal slot to vertex pointer
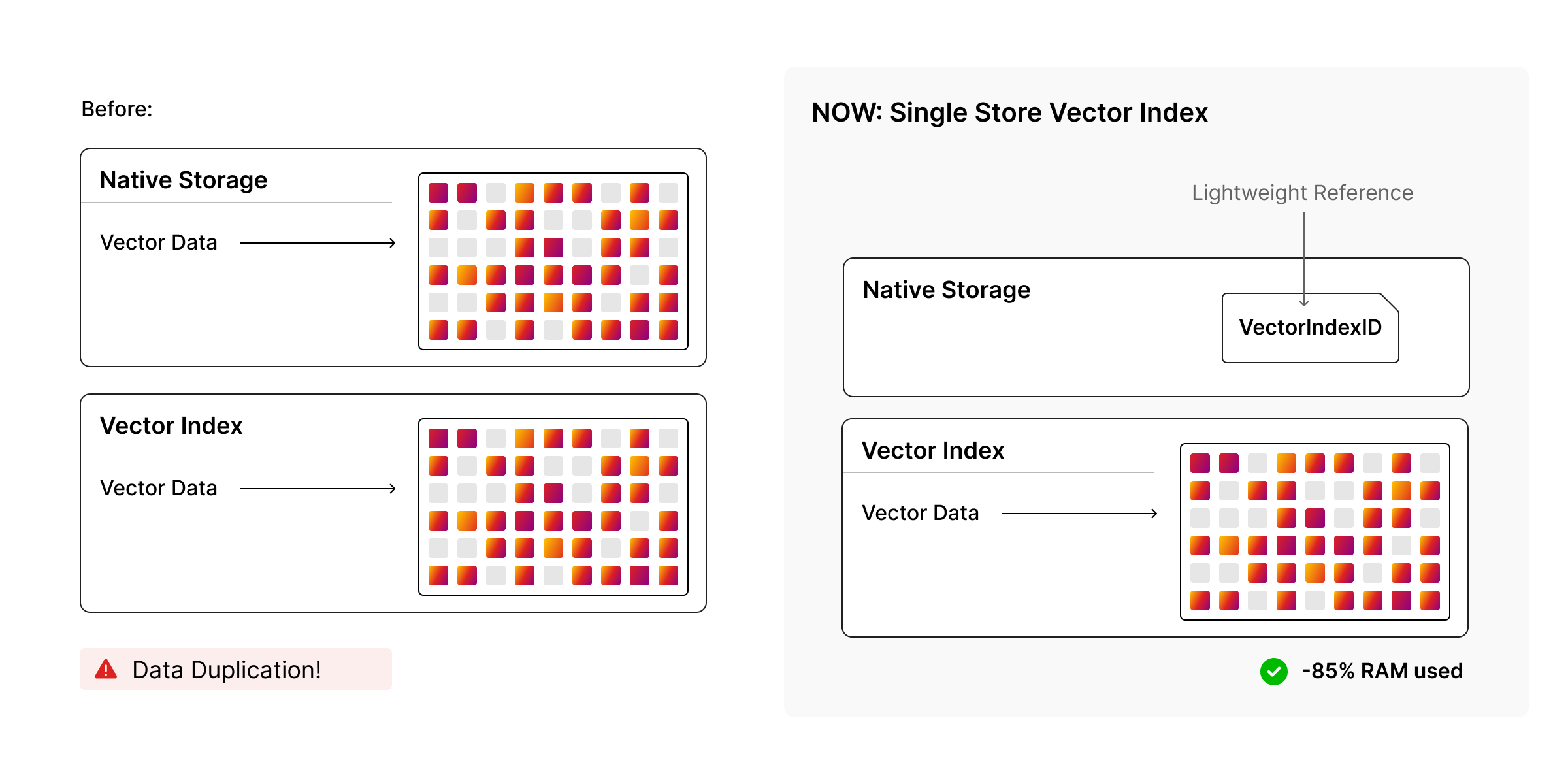
Avoiding Double Storage: The Index as the Single Copy
When a vertex has a property that is indexed by a vector index, the property store does not have to hold a full copy of the vector. Instead, it can hold a reference to the index (or indices) that contain this vertex's vector. You can create multiple vector indices (e.g. on different labels or properties); a vertex may participate in several of them, and in that case the property store holds multiple references, one per index the vertex belongs to. The canonical, single authoritative representation of the vector for search is the one inside the index. That way:
- The vector is stored once in the index, not once in the property store and again in the index.
- Updates to the property are applied to the index: the index entry is updated or replaced, and the property store can keep the lightweight reference.
So the memory cost of "this node has an embedding" is primarily the cost of the entry in the vector index, plus a small reference in the property store, rather than two copies of the vector.
When a vertex is no longer part of a vector index (because a label was removed from the vertex or the index was dropped), the vector is moved back from the index into the property store so the data is not lost. That restores the full vector on the vertex, which can increase memory usage (you now hold the vector in the property store again). Use this behavior with caution when dropping indices or removing labels from vertices that have large embeddings. Deleting the property itself removes the vector from both the index and the property store, as expected.
Scalar Kind: Controlling Memory at the Component Level
Each vector index is created with a fixed dimension, metric, and scalar kind. The scalar kind is the numeric type used to store each component of the vector inside the index (e.g. 32-bit float, 16-bit float, 8-bit float). This is one of the main levers for memory:
- f32 (32-bit float): Full precision per dimension; typical for many embedding pipelines. Highest fidelity, highest memory.
- f16 (16-bit float): Half precision; often sufficient for similarity search and recommendation. Roughly halves the raw vector memory compared to f32.
- bf16, f8: Even more compact; useful when your embeddings or workload can tolerate lower precision.
The index is built once with a chosen scalar kind. All vectors in that index are stored in that format. So you can trade precision for memory per index: use f16 (or lower) when appropriate, and f32 when you need full precision. The latest Memgraph version optimizes how this scalar storage and the surrounding index layout are organized in memory, which is where the large savings in our benchmarks come from.
What This Enables: Single Store Without Bloating RAM
Taken together, vertex as key, configurable scalar kind, index as the single copy of vector data, shared-mutex concurrency, and integrated durability: the design keeps the vector index inside the same engine as the graph while giving you levers to control memory. The latest version reduces how much RAM the index uses for a given number of vectors and dimension (better layout and representation), so you can run larger graphs with vector search on the same hardware or the same graph with less RAM.
Benchmarks: Memory and Load at Scale
To quantify the improvement, we ran benchmarks with one million nodes and 1024-dimensional embeddings in an in-memory analytical setup. We compared memory use and index load time across the following scenarios:
- Baseline: Nodes with IDs only (no vector index), to isolate the cost of the index.
- f32 (32-bit float) vectors: Full precision.
- f16 (16-bit float) vectors: Half precision.
We measured baseline RAM (before loading vectors) and post-load RAM (after the vector index is built).
Baseline: Index Overhead Only
With no vector index, both the previous and current versions use about 660 to 700 MB at baseline and 775 MB after loading the same million nodes. So the core graph storage and ID handling are stable; the gains are entirely in the vector index.
Memory: Before and After
| Scenario | Previous (3.7.2) | Current (3.8.0) | Change |
|---|---|---|---|
| f32, 1024 dims | 14.43 GB post-load | 4.85 GB post-load | ~66% less |
| f16, 1024 dims | 12.52 GB post-load | 3.00 GB post-load | ~76% less |
The vector index uses significantly less memory in the current version for this workload. Index load times remain the same across versions, so the savings come from how the index stores and organizes vectors, not from trading off load performance.
Summary
Memgraph's single store vector index is a first-class index in the same storage engine as the graph. It is USearch-backed, vertex-keyed, with configurable metric and scalar kind, and with the index as the single copy of vector data to avoid double storage.
Concurrency and durability are built in. The index scales with the graph and recovers with it. The latest version uses ~66–76% less RAM for the same workload (1M nodes × 1024 dimensions in our benchmarks). So, you can run larger workloads on the same hardware or the same workload on smaller instances.
This design is will now help you scale vector search inside Memgraph without paying the RAM cost of duplicate vector storage.
Further Reading
- For configuration and usage: Vector Search Docs