
Relational to Graph: Your Guide to Graph Thinking
If you’ve ever worked with SQL, you’ve probably asked this question when seeing a graph database for the first time: “Where are the tables?”
This exact question kicked off our latest Memgraph Community Call, where Frank Blau, Principal Data Architect, walked through what it really takes to shift from thinking in tables to thinking in graphs.
In case you missed the session, you can watch the full recording here. Below are some highlights from the session to give you a taste of what you’ll learn.
Key Takeaway 1: Relational Mindset is Deeply Rooted
Most developers are introduced to databases through relational models:
- Tables represent entities.
- Relationships are modeled with foreign keys called JOINs.
- JOINs are the glue across tables.
- Schema changes require coordination and planning.
This approach works well for structured data. But it makes modeling relationships painful, especially when the relationships themselves carry meaning (like who influenced whom, or what happened when).
Frank reminded us that in relational systems, the relationship is barely first-class. You can showcase it, but it often requires extra tables and complex JOIN logic.
Key Takeaway 2: Graphs Speak a Different Language
Graphs model data the way we describe it in conversation:
"Alice knows Bob. Bob works with Charlie."
In graph databases:
- Nodes are entities (like people, products, or orders).
- Edges are relationships (directional and labeled).
- You can attach properties to both nodes and relationships.
- Schema is flexible and evolves with the data.
Most importantly, relationships are explicit. You don’t need to infer them from matching foreign keys. They're part of the model, truly considered first-class citizens.
Key Takeaway 3: Some Use Cases Just Make More Sense in Graphs
Frank pointed out several areas where trying to model data relationally becomes a headache.
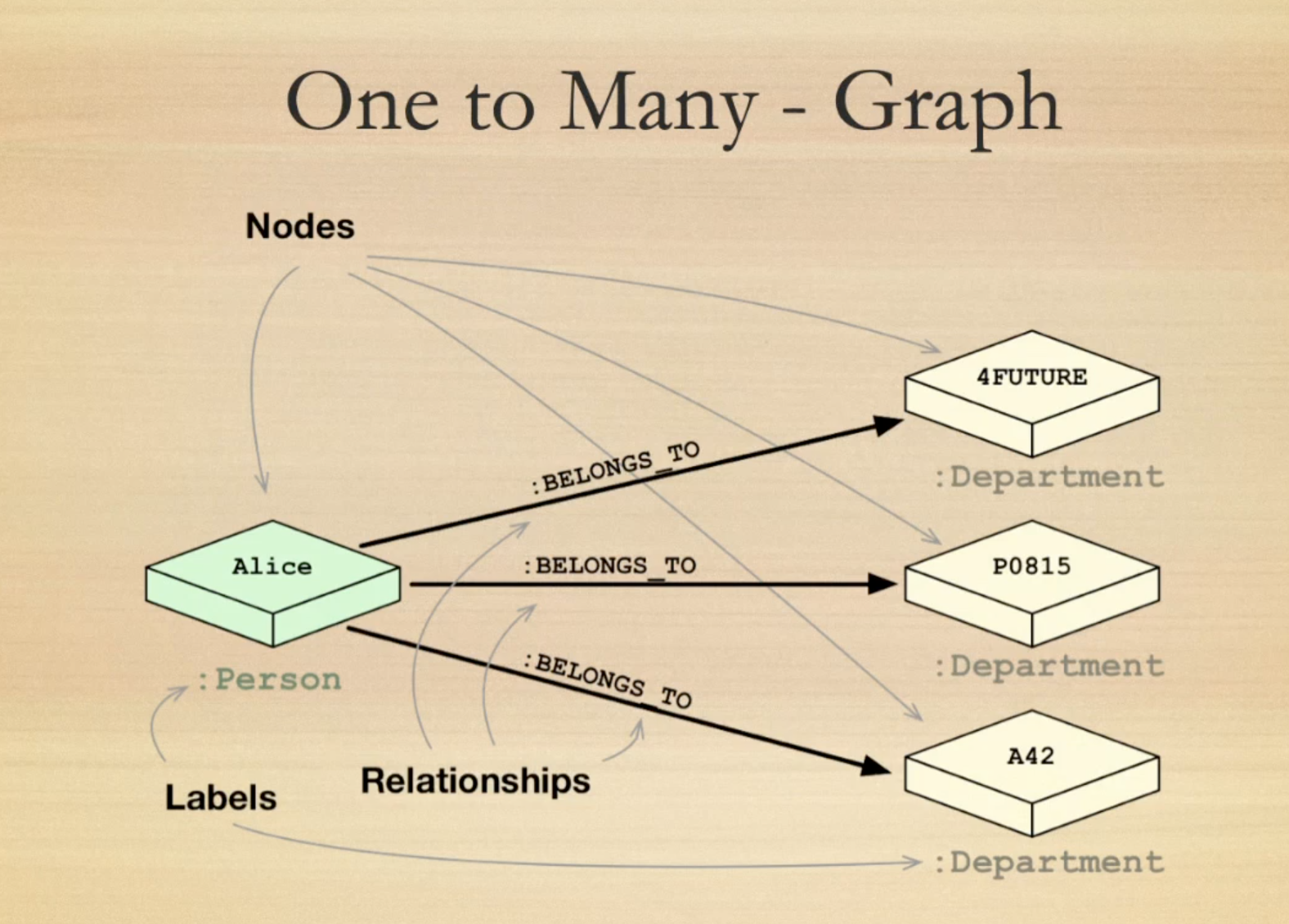
Consider a one-to-many relationship, like a customer having many orders in a relational database. It’s managed by putting a customer ID in the order table as a foreign key. Simple enough for basic understanding.
In a graph, a one-to-many relationship translates to direct relationships between nodes. For instance, an "Alice" node can have multiple "BELONGS_TO" relationships to various "Department" nodes, clearly showing her affiliations. It is semantically easy to read and understand.
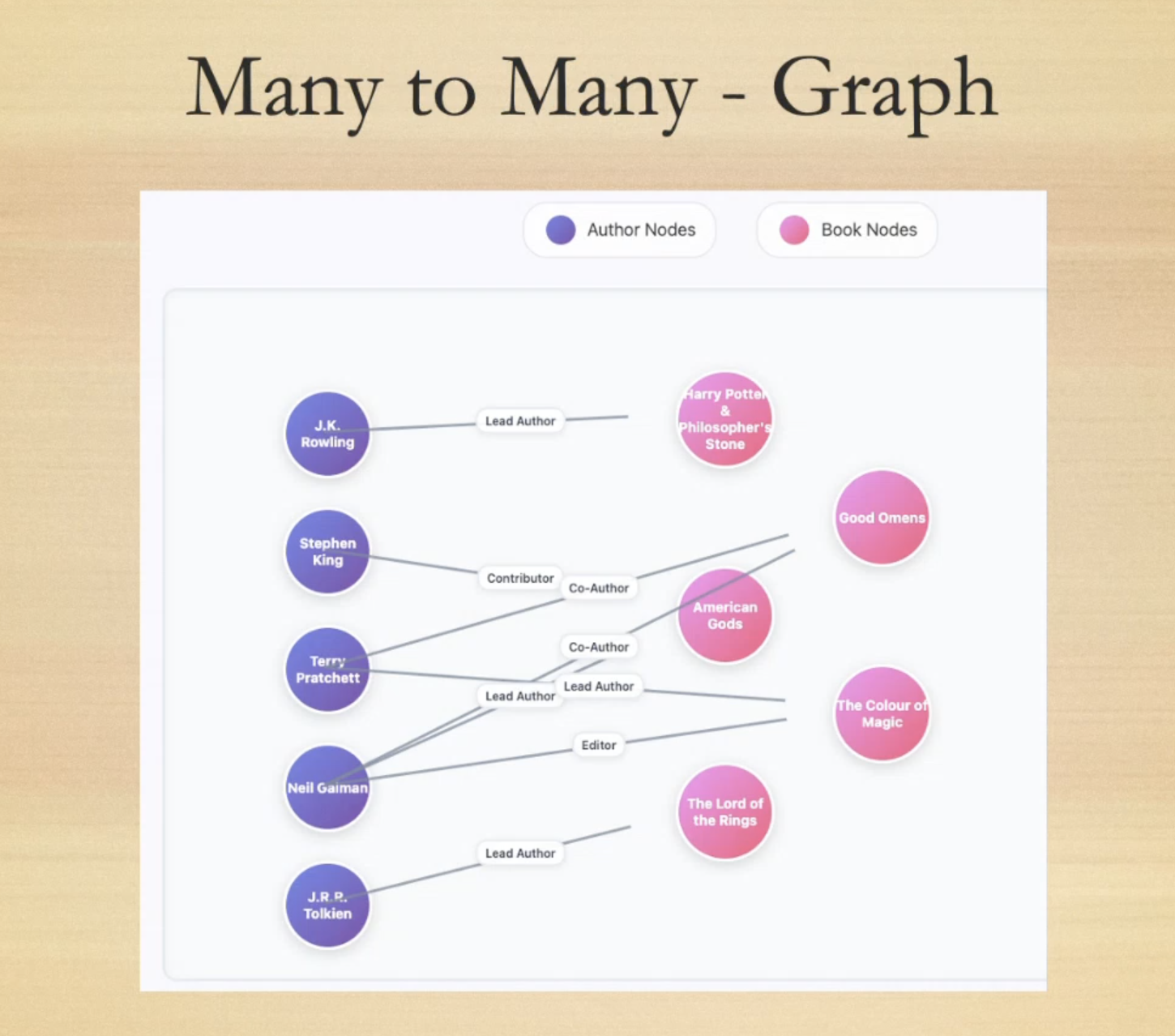
The real difference appears with many-to-many relationships.
In SQL, you'd typically need a resolver table (also known as a junction or link table) to manage connections, like authors to books. It gets the job done, but it adds complexity.

With graphs, many-to-many relationships are just more edges (the connections between nodes). An author can be a "Lead Author" for one book, a "Co-Author" for another, or even a "Contributor" to a different one. Each relationship type is explicit, adding a layer of semantic richness that's incredibly valuable for complex queries.
Key Takeaway 4: The "Slowly Changing Dimension" Challenge
One of the more complex concepts in data warehousing is the slowly changing dimension (SCD). This is about tracking changes to data over time, like a customer changing their name or address, while still retaining historical information.
Implementing SCDs in relational databases often requires sophisticated SQL to manage multiple records or versions of data. It can be a real headache.
In a graph database, handling these changes is much more straightforward. You can model temporal properties directly on relationships, such as valid_from or valid_to dates. This allows you to easily track the evolution of entities and relationships without the need for complex joins or surrogate keys.
You can even support bi-temporal tracking, capturing both when data was true and when it was recorded. It's a cleaner, more intuitive way to manage historical data.
Key Takeaway 5: Recursive Logic: Finding Mutual Friends
Recursive logic is another critical use case where the differences between relational and graph databases become very clear. Consider a common scenario: finding mutual friends in a social network.
SQL (Relational):
SELECT DISTINCT u. name FROM users u
WHERE [u.id](http://u.id/) IN (
SELECT friend id FROM friendships WHERE user id = 1
INTERSECT
SELECT friend id FROM friendships WHERE user id =
2.In SQL, this typically involves multiple self-joins or recursive Common Table Expressions (CTEs).
The database must scan data multiple times to extract user connections, then sort, hash, and deduplicate intermediate result sets. Set operations add significant computational cost. Subqueries materialize multiple user sets and compare their intersections.
This approach can have high time complexity with increased "hops" or layers of relationships, and it often struggles with scalability in dense networks, usually falling apart beyond 3-4 depth layers.
Cypher (Graph):
MATCH (a)-[:FRIEND]->(b)-[:FRIEND]->(c)
WHERE a.name = "Alice" AND c.name = "Charlie"
RETURN b
With Cypher, you use a graph-native pattern matching syntax.
Instead of joining keys, you traverse actual relationships. Traversals operate directly over edges, not via costly lookups. This makes Cypher highly efficient for deep network traversals, pathfinding, finding mutual connections, or any hops-based logic.
Cypher queries remain short and expressive even at 3+ hops, letting you "draw your query with code." It's a much more intuitive and performant way to handle highly connected data.
Frank showcases the difference live as a demo in the community call.
Key Takeaway 6: When to Use Graphs (and When Not To)
Graphs aren't a silver bullet, but they are incredibly powerful for certain scenarios. They excel in use cases where relationships are central to your data, such as:
- Relationship-heavy data: Social networks, recommendation engines
- Hierarchical structures: Organizational charts, product taxonomies
- Complex traversals: Fraud detection, network analysis
- Dynamic schemas: Evolving entity relationships
However, if your data is mostly flat, highly structured, or your primary need is aggregation-heavy reporting (think dashboards and KPIs), a relational database might still be your best bet. Graphs might not be the right fit for simple batch ETL or environments where schemas rarely change.
Key Takeaway 7: Hybrid Models Work (and Work Well)
You don’t necessarily need to get rid of your existing relational systems to adopt graph thinking. In some scenarios, using both together makes more sense, such as:
- Using SQL for facts and dimensions (customers, products, sales).
- Using graph for relationships, lineage, and traversal-heavy logic.
- Using tools to push and pull data between both systems.
This hybrid approach lets you explore graph use cases without changing your entire architecture.
Key Takeaway 8: Developer Mindset is the Real Barrier
Shifting to graph is less about tech and more about thinking:
- Stop looking for tables.
- Think in terms of nodes, edges, and patterns.
- Use visual tools (like Memgraph Lab) to explore your graph.
- Model relationships first, not as an afterthought.
Frank's advice? Start small. Pick one use case with complex joins or evolving relationships. Rebuild it in a graph and compare the experience.
Q&A
Here’s a compiled list of the questions and answers from the community call Q&A session.
Note that these are paraphrased slightly for brevity. For complete details, watch the full community call recording.
-
Is there any limitation for the amount of data a Graph DB can handle?
- While there are limitations, the scalability of graph databases is significantly higher compared to relational databases for certain types of datasets. Graph databases can even handle millions of nodes. The key is not just the volume of data, but how it is structured to extract meaningful insights. Sites like LinkedIn and Facebook use graphs to handle billions of nodes and quickly find relationships for applications like fraud detection.
-
Relational Databases have evolved over the last 40+ years and have maturity in terms of mission critical applications. Are Graph Databases there in term of volumes, availability, scalability, concurrency, security and performance?
- I would say absolutely. I think part of the problem is graph databases don't get a lot of the attention that sometimes relational databases get, but they're all there. It's not like the world isn't using them in the same way and they can still be deployed using containers. They can do all the same security type things. It's a slightly different mindset though. It's a slightly more creative mindset, but all features that are needed for deployment in the real world exists in graph. Also, it's not like they're comparable to something like Jupyter Notebook on the desktop. It's a much more hardened environment in that space of real deployments because people are using them. Pharmaceutical companies, for example, are using them for document generation use case, scaling to millions and millions of nodes and relationships in a highly secure environment and using highly secure multi-tenancy. So, the kinds of things that we take into account like DevOps in the deployment world of relational databases, also exist in graph world. It is definitely possible to run mission critical stuff on it.