
HybridRAG and Why Combine Vector Embeddings with Knowledge Graphs for RAG?
If you're building a RAG system on data with important entity relationships, vector search alone typically lacks the context you need. It helps you find semantically relevant content, but it does not explain how people, products, documents, or events connect. HybridRAG combines vector search with graph-based reasoning so you can retrieve relevant context and then trace the relationships that make the answer useful.
For Memgraph users, that matters when you need more than "find similar text." You also need to follow linked entities, support multi-hop reasoning, and ground answers in live graph context. This post breaks down where vector search fits, where graph modeling fits, and when a hybrid approach is worth the extra complexity.
What Are Vector Embeddings?
Vector embeddings transform text, images, or other data into vectors. Vectors are points in a multi-dimensional space that capture semantic meaning. This allows you to compare information based on similarity of meaning, not just exact matches.
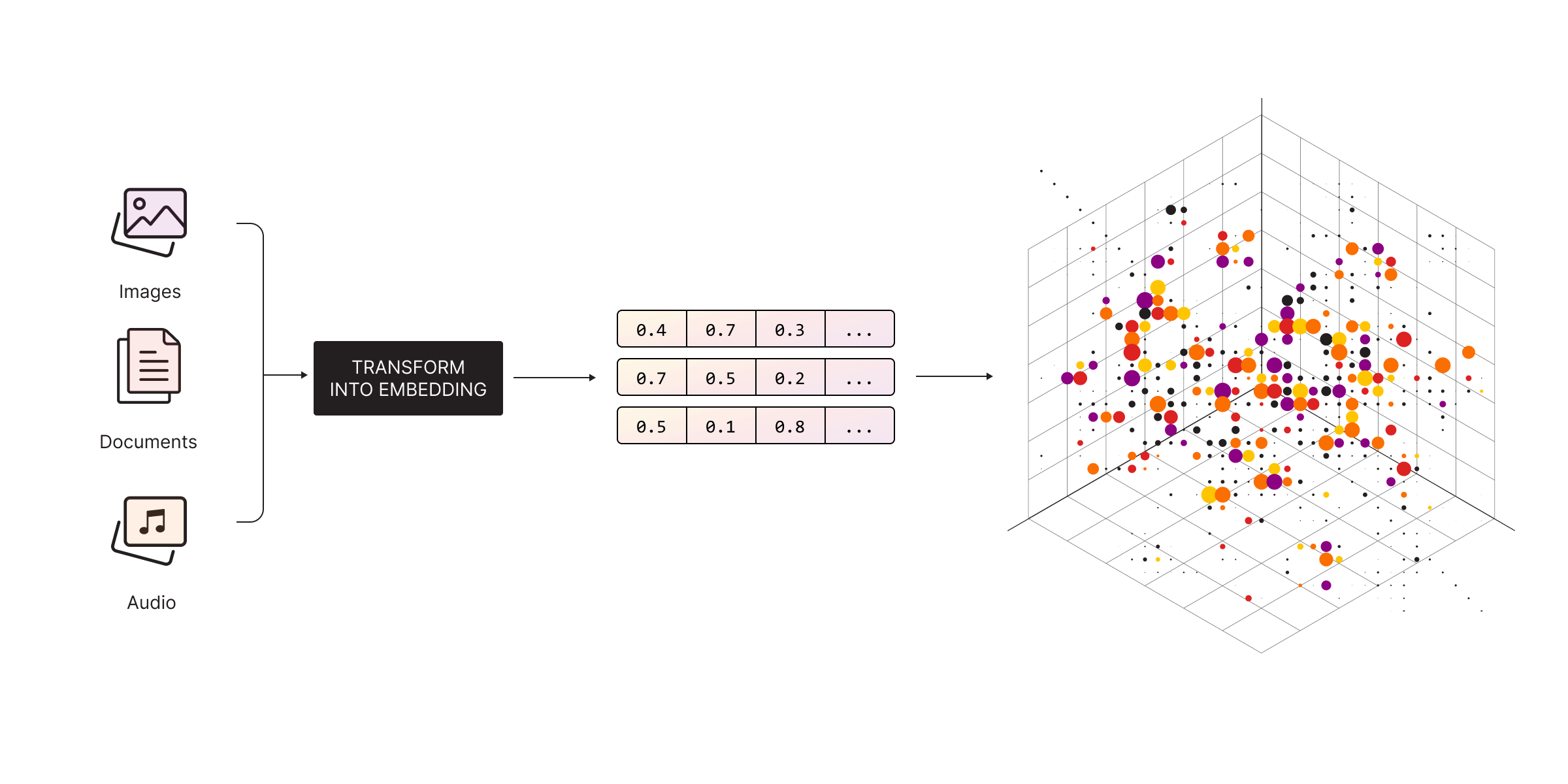
What Is Vector Search?
Vector search captures meaning beyond exact terms. It finds relevant results even when queries include different phrasing, typos, slang, or vague language. That’s its biggest advantage: semantic matching.
You’d use vector search when:
- Queries are ambiguous or lack specificity.
- You need to handle synonyms or highly contextual language.
- You're retrieving context that doesn't exactly match the knowledge graph's structured nodes and relationships but shares conceptual similarity.
Read more: Simplify Data Retrieval with Memgraph’s Vector Search and Decoding Vector Search: The Secret Sauce Behind Smarter Data Retrieval.
How Vector Search Works
- Generate embeddings for your data and your query.
- Compare them within the same vector space using similarity calculations.
- The most common comparison method is cosine similarity, which effectively captures semantic relationships, especially in text-based tasks.
You can create and store embeddings in a vector database such as Pinecone or Weaviate, or use Memgraph when you want vector search and graph traversal in the same workflow.
What Is a Graph Data Model?
A graph data model organizes information as nodes (entities like customers, products, or patients) and edges (relationships between those entities). This model is designed to answer questions about how things are connected, which is exactly what many RAG systems need once retrieval moves beyond isolated text chunks.
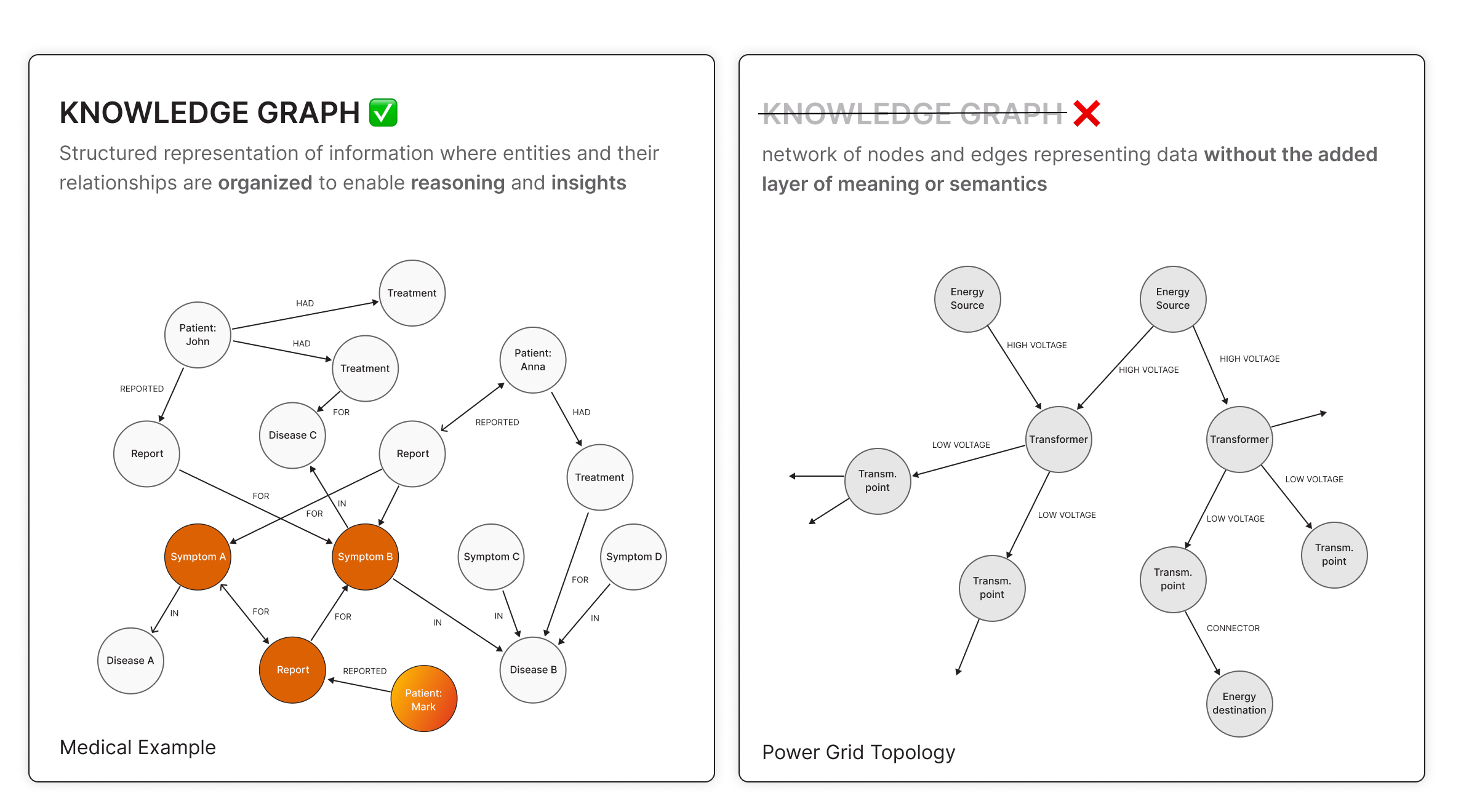
You’d use a graph model when:
- Relationships are core to your data.
- You need multi-hop reasoning (like tracing symptoms → patients → treatments).
- You're working with complex, highly connected data (such as healthcare records, fraud detection, or social networks).
Why Use a Hybrid Approach?
Vector search and graph search solve different retrieval problems. Using them together helps you cover both semantic similarity and relationship-aware reasoning.
1. You Need Both Similarity and Context
- What vector databases do well:
They find items that are semantically similar. For example, they can surface documents on the same topic even when the wording is different. - What vector databases struggle with:
Context and relationships. A vector index might show that two documents are similar, but it will not explain why or how they connect to the rest of your data. - What graph databases do well:
They capture context. Graphs let you traverse relationships, connect multiple entities, and perform multi-hop reasoning. - What graph databases struggle with:
Semantic similarity. A graph can model that two entities are related, but by itself it will not infer that a paragraph about "neural networks" is close in meaning to one about "machine learning."
How HybridRAG Works in Practice
HybridRAG starts with semantic retrieval and then adds relationship-aware exploration. First, you use vector search to find relevant entities, chunks, or documents. Then you use the graph to explore how those results connect and extract the surrounding context that matters.
For example, “Which patients have similar symptoms to Mark, and what treatments worked for them?”
With HybridRAG, you use vector search to find patients with similar symptom descriptions, then use the graph to trace relationships between those patients, their treatments, and outcomes.
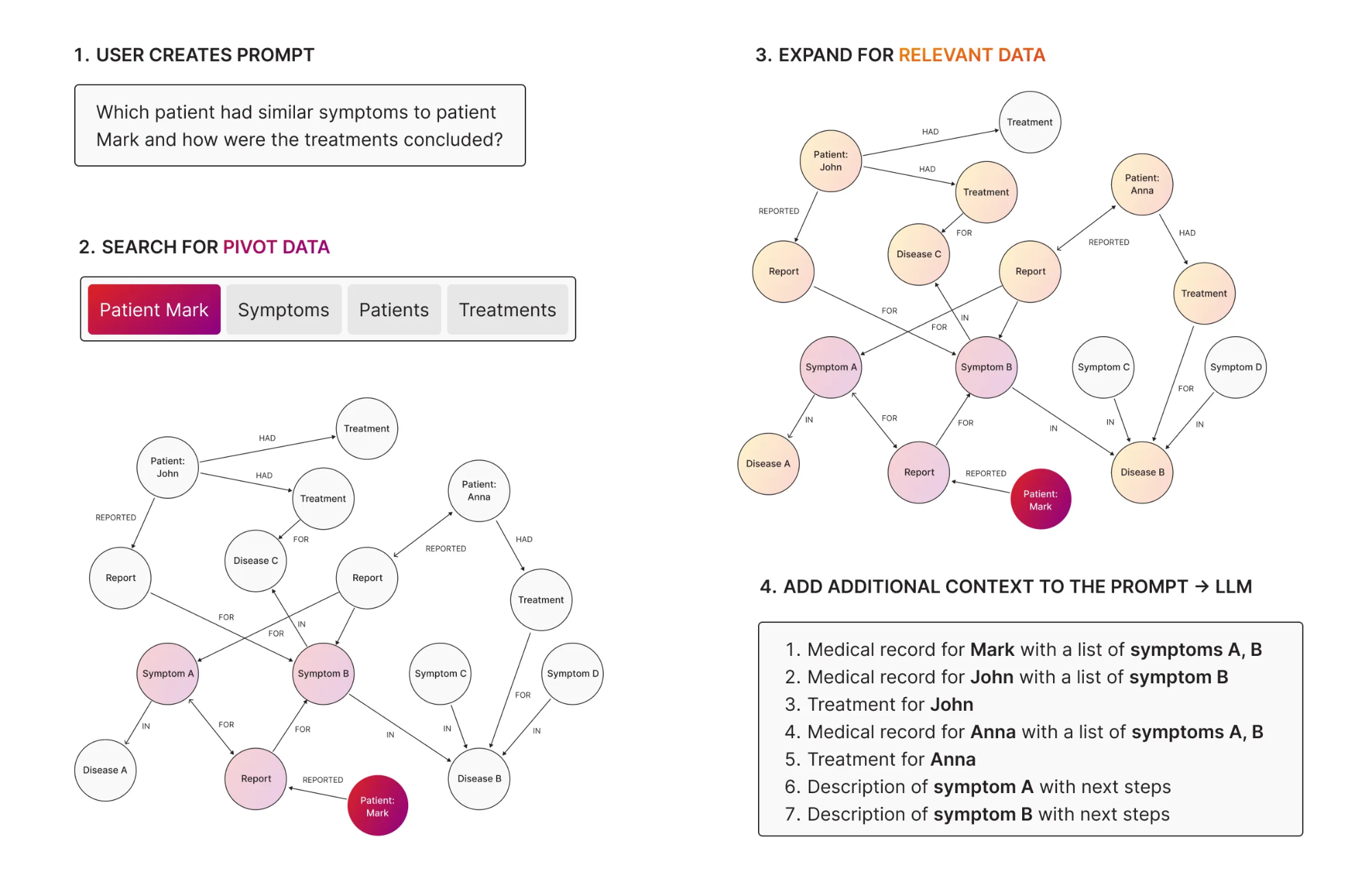
2. Efficient Data Retrieval at Scale
In real-world use cases, your data isn’t just big—it’s massive. HybridRAG makes retrieval efficient by splitting the workload. The vector database handles the unstructured or semi-structured data (e.g., embeddings of text or images).
On the other side, the graph database handles structured, relationship-heavy data.
Example use case:
Cedars-Sinai's Alzheimer's Disease Knowledge Base (AlzKB) uses a HybridRAG approach by combining Memgraph's graph database with a vector database to improve query accuracy and downstream machine learning results.
The graph database stores biomedical entities (e.g., genes, drugs, diseases) and their relationships, enabling multi-hop reasoning and dynamic updates, while the vector database enables semantic similarity searches to match natural language queries with relevant graph data. This integration powers tools like KRAGEN (Knowledge Graph-Enhanced RAG) and ESCARGOT (Dynamic Graph of Thoughts) to address complex compound queries, guide automated machine learning pipelines, and discover novel drug and gene targets for Alzheimer’s.
Together, this system delivers context-rich retrieval and has already identified two FDA-approved drugs (Temazepam and Ibuprofen) as potential candidates for Alzheimer's treatment.
Read more: Using Memgraph for Knowledge-Driven AutoML in Alzheimer’s Research at Cedars-Sinai
3. Dynamic and Adaptive Queries
Sometimes, you don’t know exactly what you’re looking for. A hybrid system adapts dynamically:
- Start broad with a vector search to find semantically relevant data.
- Then narrow down with a graph search to analyze relationships or clusters of related items.
Example use case:
A financial application identifies similar companies using a vector database (e.g., based on earnings reports) and then uses a graph database to uncover relationships like partnerships or shared investors.
4. Enhanced Relevance with Multi-Hop Reasoning
Vector databases are good at finding what is similar, but they don’t understand connections between entities. HybridRAG brings graph-powered multi-hop reasoning into the mix:
After finding similar items in the vector database, use the graph database to explore multi-step relationships and generate deeper insights.
5. Real-Time Updates and Historical Context
Graph databases can reflect the latest connections or events in real time. Vector indexes provide semantic retrieval over embedded content.
This combination ensures your system is both fresh (real-time) and insightful (context-rich).
Example use case:
Precina Health uses both a graph database (Memgraph) and a vector database (Qdrant) in their system to manage and optimize Type 2 diabetes care.
Memgraph is the backbone of their knowledge graph, storing and managing relationships between patient data, behavioral insights, and medical information. It enables multi-hop reasoning, connecting complex relationships like how social and behavioral factors impact medical outcomes.
On the other side, they use a vector database, Qdrant. It supports fast semantic searches, retrieving relevant nodes and documents based on contextual similarity to a query. It helps identify initial relevant data points before relational reasoning occurs in the graph database.
Wrapping Up
Use vector search alone when your main goal is to find text, products, or records that are semantically similar. Add a graph when the answer depends on connected entities, path-based reasoning, or live operational context. Choose HybridRAG when you need both: broad semantic retrieval up front and graph-backed explanation or traversal after that.
If you're building that kind of workflow, Memgraph is a practical next step because it lets you combine vector search with graph traversal and multi-hop reasoning in one system.