
From Raw to Graph: 3 Essential Steps to Load Your Data into Memgraph
Raw data is messy. Relationships aren’t always obvious. CSVs don’t magically become graphs. If you skip straight to importing, you’ll likely end up with a tangle of nodes and edges that doesn’t help anyone.
A better approach? Break it down into a 3-step process:
- Preprocess your raw data
- Model it as a graph
- Import it into Memgraph
Let’s walk through what each step involves.
Step 1: Preprocess Your Raw Data
Preprocessing is about turning unstructured chaos into something structured and predictable. It’s tempting to skip this step and go straight to modeling, but that’s where most problems begin.
You must organize and clean your raw, unstructured data so it’s graph-friendly:
- Make sure values follow consistent formats (e.g., all timestamps in the same format)
- Split compound fields (like "City, Country") into discrete fields
- Normalize names and IDs where possible. If the same person is listed as "Jon Smith" and "Jonathan Smith", now’s the time to fix that.
Good preprocessing also helps reveal the structure in your data. Are there recurring IDs or values? Those are likely candidates for nodes. Do certain entries always appear together? They might form a relationship.
For a production-ready system dealing with unstructured data requiring accuracy, it is recommended to create a custom pipeline of:
- Preprocessing to clean and organize raw data for analysis.
- Named Entity Recognition (NER) to identify and classify entities in the data.
- Relationship extraction to detect and define connections between entities.
- Contextual understanding and disambiguation to resolve ambiguities and ensure contextually accurate representations.
- Post-processing to refine and validate the structured data before graph creation.
This process is especially useful for getting your knowledge graph ready for GraphRAG use cases.
At this stage, the goal is to make your data predictable, not perfect. You’re setting yourself up for fewer surprises when modeling and importing.
Step 2: Model Your Data as a Graph
Now the fun part. Think about your data not as tables, but as entities and relationships.
Graph modeling isn’t just about creating nodes and edges, it’s about representing the real-world structure hidden in your data.
Ask three questions:
- What entities (things) exist in the data? These will become nodes.
- How do these entities interact or relate? Those are your relationships.
- What additional information do you need to attach to these? Those are properties.
Say you’ve got users reviewing products. Your raw data might look like this:
user_id, product_id, rating, review_text
Instead of stuffing everything into one node, structure them intuitively:
UsernodesProductnodes- A
REVIEWEDrelationship fromUsertoProduct, withratingandreview_textas properties
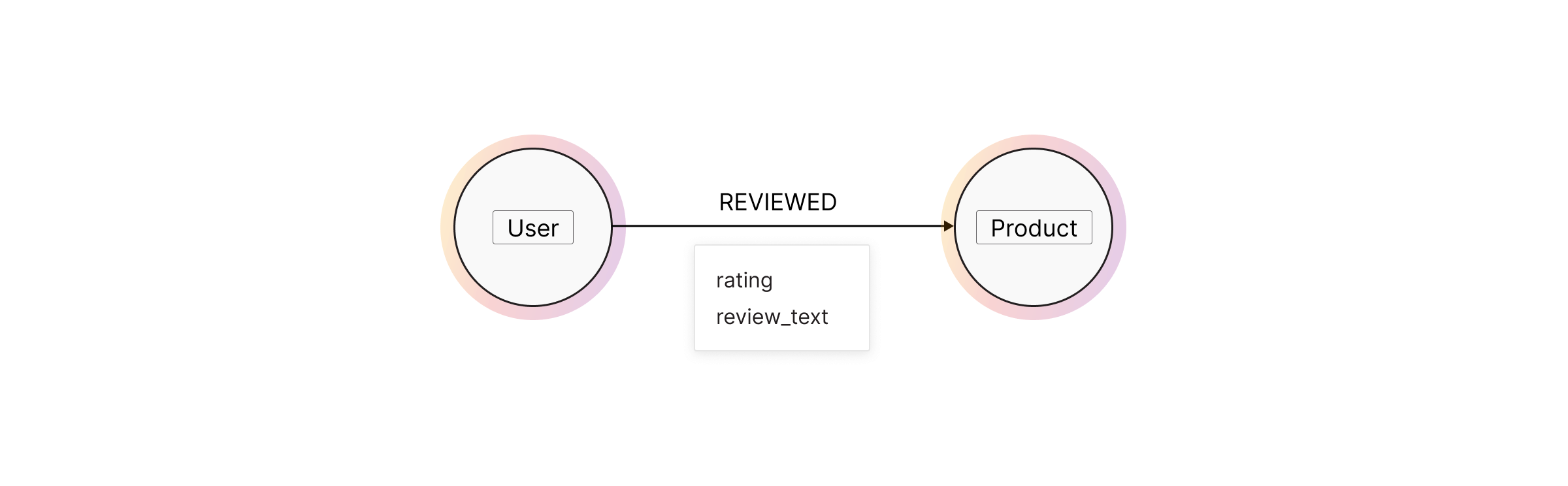
This not only keeps your graph clean, it lets you query across different dimensions. You can explore what products a user reviewed, or which users reviewed the same product.
Keep your graph clean and efficient by following these key graph modeling best practices:
- Not everything needs to be a node. If it doesn’t need a relationship, it might just be a property.
- Define simple, direct and descriptive relationship types (e.g.,
PURCHASED,RATED,CONNECTED_TO). - Minimize duplication of information across nodes (e.g., don’t store a user’s location in both a
Usernode and everyREVIEWEDrelationship). - Choose the right property data types to significantly reduce resource consumption and improve performance.
- Add labels and label-property indexes and constraints now, as they’ll help during import and improve query performance later.
- Avoid indexing every property unless it’s absolutely necessary as over-indexing can hurt write performance.
The goal is to design a schema that’s easy to reason about, easy to query, and easy to scale.
Step 3: Import Your Data Into Memgraph
You’ve got clean data and a solid graph model. Now it’s time to bring it to life inside Memgraph.
The fastest and most reliable way to do that? Use a CSV file and the
LOAD CSVclause.
Whether you’re migrating from a relational database or another graph system, CSV gives you a straightforward path. Here are the simple steps to follow:
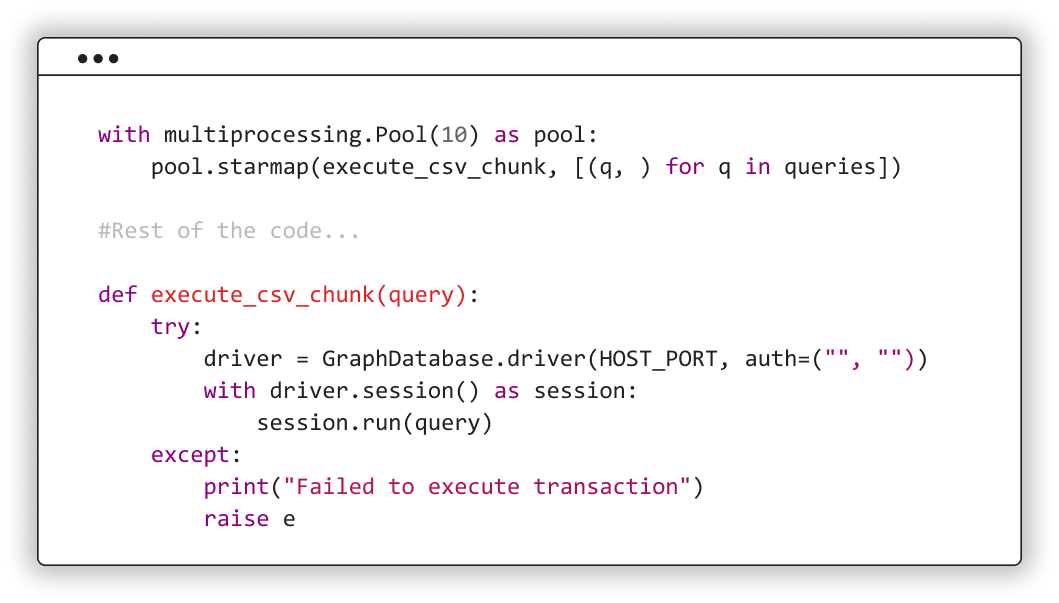
- Split nodes and relationships CSV files into smaller CSV files
- Copy the CSV files into the container where Memgraph is running
- Generate LOAD CSV queries

-
Start the concurrent query execution using multiprocessing
But Memgraph supports more than just CSV. Here are your main options:
- CSV:
LOAD CSVclause or Memgraph Lab’s CSV Import Tool - JSON: Use
json_util()from the MAGE library - CYPHERL: Run Cypher scripts via
mgconsoleor Memgraph Lab - Streaming sources: Kafka, RedPanda, and Pulsar for real-time pipelines
Read more: How We Integrated 15+ Data Sources with Memgraph in a Day Using ChatGPT
Once you’ve picked your import method, optimize for performance:
- Use IN_MEMORY_ANALYTICAL storage mode if you're bulk loading. It disables delta objects, reduces memory overhead, and speeds up import. (Note: ACID properties are not guaranteed so switch back to the in-memory transactional mode for operations that require write access and depend on ACID properties for consistency.)
- Split large files and run imports in parallel using multiprocessing. Programmatic imports shine in this setup.
- Batch your writes. Avoid massive single transactions.
- Test with a sample. It’ll help you catch modeling or syntax issues before you scale up.
Bottom line: importing isn’t just about getting data in. It’s about doing it in a way that sets you up for fast queries and reliable graph operations.
Conclusion
Moving from raw data to a clean, expressive graph in Memgraph isn’t a one-click process which is a good thing. Each step gives you more insight into your data and more control over how it’s structured.
So: clean it. Model it. Import it. That’s how you go from raw to graph, the Memgraph way!
Further Reading
- Docs: Model a Knowledge Graph
- Docs: Data Modeling Best Practices
- Docs: Data Migration Best Practices
- Memgraph Academy: Mastering Data Modeling
- Blog: How to Import 1 Million Nodes and Edges per Second Into Memgraph
- Blog: Memgraph as a Graph Analytics Engine
- Blog: Memgraph Storage Modes Explained